포르투갈의 은행 정기예금 가입을 위한 marketing 데이터를 가지고 ELI5 분석을 진행해보자.
(DATASET 출처 : https://www.kaggle.com/datasets/yufengsui/portuguese-bank-marketing-data-set )
Dataset 불러오기
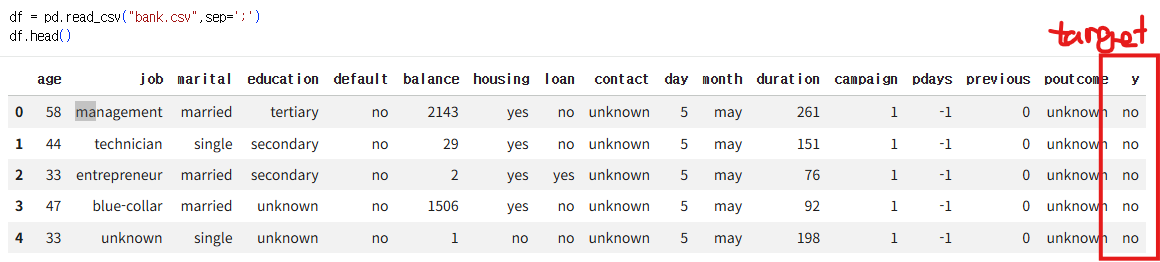
target 데이터에 해당하는 y가 no의 비율이 8배로 확인되어 불균형한 것을 확인할 수 있다. (층화 추출 고려)
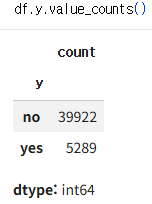
Data Preprocessing
1. Labeling Target (y)
target 데이터가 문자열이라 숫자로 레이블 인코딩 진행
2. Seperating Target Variable from feature matrix
object 형 변수는 Encoding (여기서는 원핫 인코딩 진행)
int 형 변수는 숫자이므로 그대로 사용한다.
이때, 우리는 설명가능한 모델을 개발해야 하므로 원핫인코딩 직후 각 범주명을 다음과 같은 규칙으로 변환한다.
[ 기존 범주명 ]_[ 기존 값 ]
ohe_categories = preprocessor.named_transformers_["categorical"].categories_
print(ohe_categories)
new_ohe_features = [f"{col}__{val}" for col, vals in zip(cat_features, ohe_categories) for val in vals]
print(new_ohe_features)
all_features = num_features + new_ohe_featuresPreprocessing Result

Train & Test
5개의 모델을 학습하고, 성능을 확인한다.
lr_model = LogisticRegression(class_weight="balanced", solver="liblinear", random_state=42)
dt_model = DecisionTreeClassifier(class_weight="balanced",max_depth=10, min_samples_split= 0.05)
rf_model = RandomForestClassifier(class_weight="balanced",max_depth=10, min_samples_split= 0.01, n_jobs=-1)
lgb_model = LGBMClassifier(class_weight="balanced",max_depth=12, min_child_samples=60,n_estimators=50, n_jobs=-1)
xgb_model = XGBClassifier(class_weight="balanced",max_depth=10, min_samples_split= 0.05,verbosity=0)결과는 다음과 같았다.
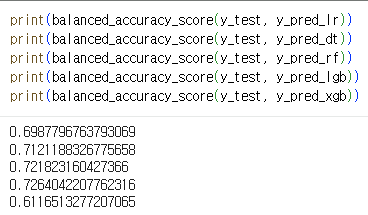
또한, 로지스틱 모형을 구축해 회귀계수를 보면 특성 변수의 중요도를 확인할 수 있다.

ELI5
ELI5를 설치하여 모델별 특성 변수 중요도를 살펴보자
Logistic Regression
eli5.show_weights(lr_model, feature_names=all_features)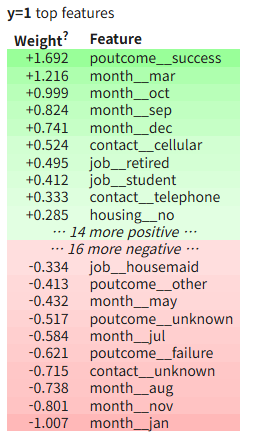
유리박스 모형인 로지스틱 회귀모형은 local explainer추출도 가능하다.
i = 4
X_test.iloc[[i]]
y_test.iloc[i]
eli5.show_prediction(lr_model, X_test.iloc[i],
feature_names=all_features, show_feature_values=True)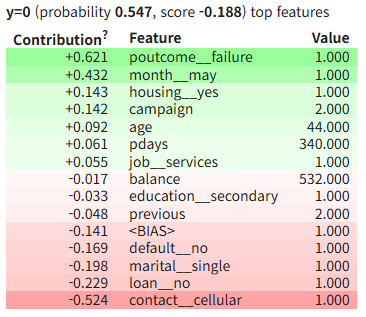
- local explainer는 관측된 특성변수 * 회귀계수로 평가
- 위 이미지를 해석하면 다음과 같이 해석가능
범주가 0인 다섯번째 표본은 확률 0.547로 범주 0으로 예측되었고, month_nov가 이 표본의 예측치에 가장 크게 기여
Decision Tree
eli5.show_weights(dt_model, feature_names=all_features)의사결정나무를 기반으로 하는 모든 아상블러닝 모형은 information gain으로 특성변수 중요도를 정의
즉, 나무를 분할할때 줄이는 손실값에 가중치를 곱하여 중요도를 계산한다.
가중치는 특정 특성변수가 분할될 때의 관측치 수를 의미
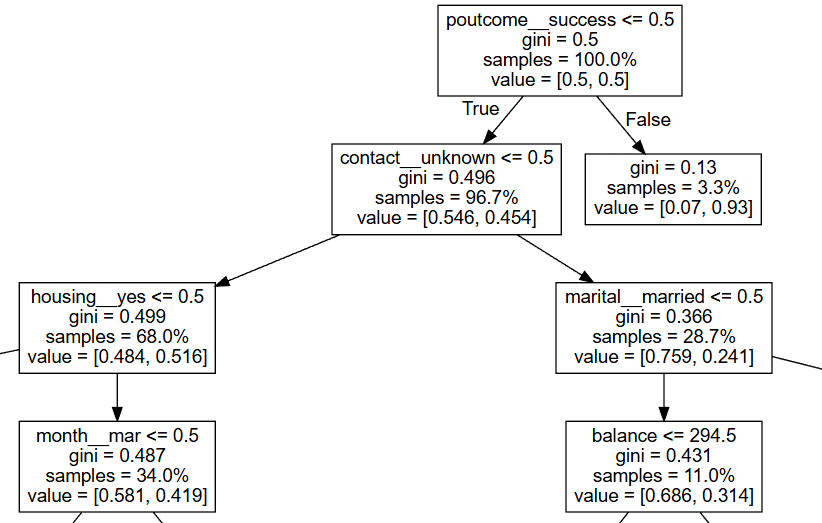
의사결정나무의 local explainer를 살펴보자.
eli5.show_prediction(dt_model, X_test.iloc[i],
feature_names=all_features, show_feature_values=True)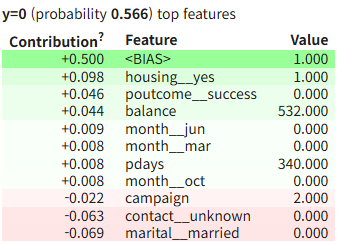
앞서 살펴본 로지스틱의 local결과와 비교해보았을 때, 많이 다름을 확인할 수 있다.
이는 로지스틱은 선형모델이고, 의사결정나무는 비선형모델이기 때문이다.
다음으로 의사결정나무의 permutation importance (PI) 를 구해보자.
permutation importance (PI) : global 특성 변수 중요도
from eli5.sklearn import PermutationImportance
perm_dt = PermutationImportance(dt_model, scoring="balanced_accuracy")
perm_dt.fit(X_test, y_test)
eli5.show_weights(perm_dt, feature_names=all_features)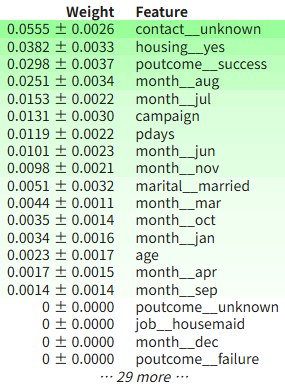
scoring="balanced_accuracy"를 부여하여 원래 데이터의 balanced_accuracy와 shuffling 한 데이터의 balanced_accuracy의 차이가 global 특성 변수 중요도가 된다.
Random Forest
각 의사결정나무의 특성변수별 information gain을 구한후, 평균을 구해 global explainer인 특성 변수 중요도를 산출
- 랜덤 포레스트는 2개 이상의 boostrap 데이터를 사용
- 배깅 방식 : 여러명의 의견을 동시에 들어보는 투표
- boostrap data : 원본 데이터 하나를 가지고 마치 여러 개의 다른 데이터셋이 있는 것처럼 흉내 내는 기술 (신뢰, 성능 안정화)
eli5.show_weights(rf_model, feature_names=all_features)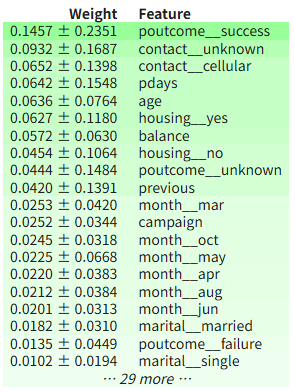
- 2개 이상의 boostrap data라 표준편차까지 출력 가능
LightGBM
2개이상의 의사결정나무를 더해서 예측모형을 만드는 boosting 모형이므로 랜포와는 달리 하나의 예측치만 존재
- 부스팅 방식 : 여러개의 약한 모델을 순차적으로 연결해 개선해나가는 방식 (오답노트풀이에 비유 가능)
eli5.show_weights(lgb_model, feature_names=all_features)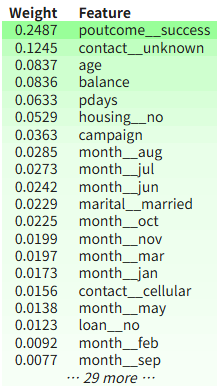
XGBoost
- 부스팅 방식 : 여러개의 약한 모델을 순차적으로 연결해 개선해나가는 방식 (오답노트풀이에 비유 가능)
eli5.show_weights(xgb_model, feature_names=all_features)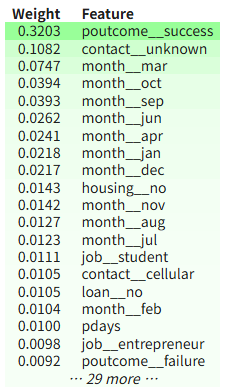
summary
ELI5에 의한 선형모형의 특성 변수 중요도는 회귀계수다.
그러나 회귀계수는 특성 변수의 측정 단위에 의존하므로 표준화되어있지 않으면 해석에 주의가 필요하다.
의사결정나무에서의 특성변수중요도는 특성 변수의 증감이 예측치에 미치는 영향을 측정할 수 없다.
WHY ?
특성 중요도는 "불순도 감소량의 총합"이기 때문
비선형성: 상황에 따라 영향이 다르기 때문 (비선형성이라는 것은 일관된 규칙이 없다는 것을 의미)
따라서 추가적인 분석도구가 필요하다.
