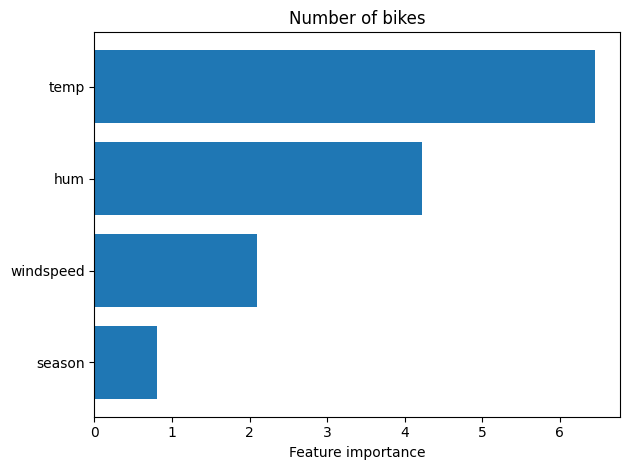
Permutation Importance
1) 정의
- 데이터를 망가뜨렸을때 모델의 성능 (에러율) 이 얼마나 나빠지는가
2) 목표
- 모델이 실제 정답을 맞히기 위해 해당 피처에 얼마나 의존하고 있는지 확인하고자 함
Partial Dependence (부분 의존성)
1) 정의
- 다른 모든 조건 (피처)가 동일할 때, 오직 특정 피처 하나만 값이 변하면 모델의 예측값 (평균)이 어떻게 변하는가를 보여주는 기법
- 예를 들어, 집값을 예측하는 모델 (회귀)에서 방의 개수에 대한 부분 의존성을 본다면 방이 1개에서 5개로 늘어날때 집값 예측치가 평균적으로 어떻게 우상향하는지 선 그래프로 보여줌
2) pd_variance (부분 의존성 분산)
- 부분 의존성 그래프 (선)가 위아래로 얼마나 심하게 요동치는지를 측정한 값
- 피처 중요도의 지표로 사용
- 분산이 크다 : 그래프의 기울기가 가파르거나 굴곡이 심함 (해당 피처의 값을 조금만 바꿔도 모델의 예측값이 휙휙 변함 = 영향을 많이 미치는 중요한 피처)
- 분산이 작다 : 그래프가 평평한 수평선에 가까움. 이 피처의 값을 아무리 바꿔봐야 모델의 예측값은 미동도 하지 않음 = 모델 예측에 쓸모없는 피처
3) 목표
- 모델이 정답을 맞히는지, 틀리는지 관심없음. 모델의 출력이 해당 피처의 변화에 얼마나 민감하게 반응하는지 확인
4) 코드
exp = explainer.explain(X=X_train,features=features,kind='both')
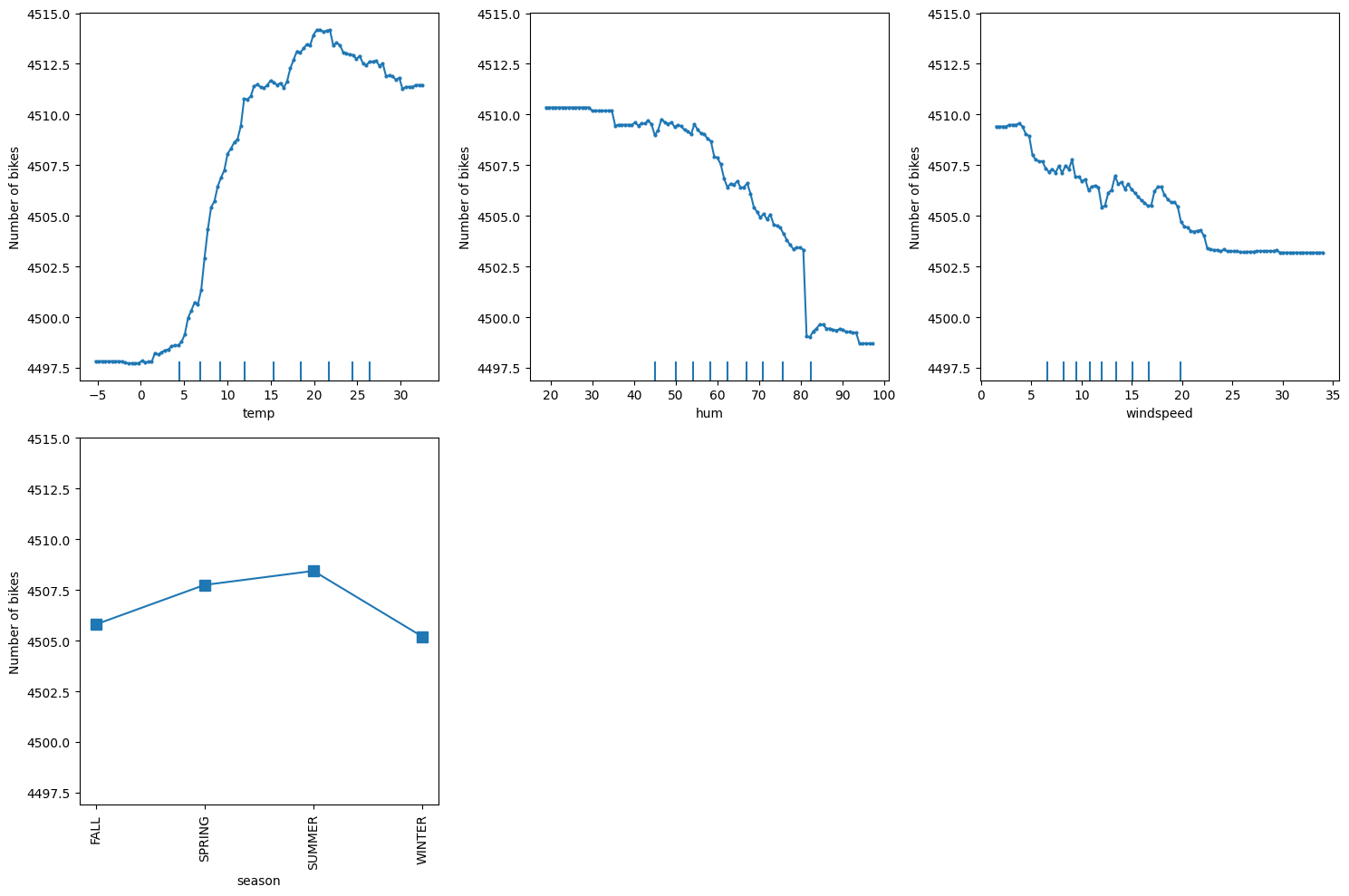
-
kind='average' (부분 의존성, PDP): 1,000명의 사람이 있다면 그 1,000명의 반응을 뭉뚱그려서 평균을 낸 굵은 선 딱 1개만 보여줌 (반 평균 성적)
-
kind='individual' (개별 조건부 기대치, ICE): 평균을 내지 않고, 1,000명 각각이 온도가 변할 때 대여를 어떻게 할지 얇은 선 1,000개를 모조리 그려줌 (학생 개개인의 성적표)
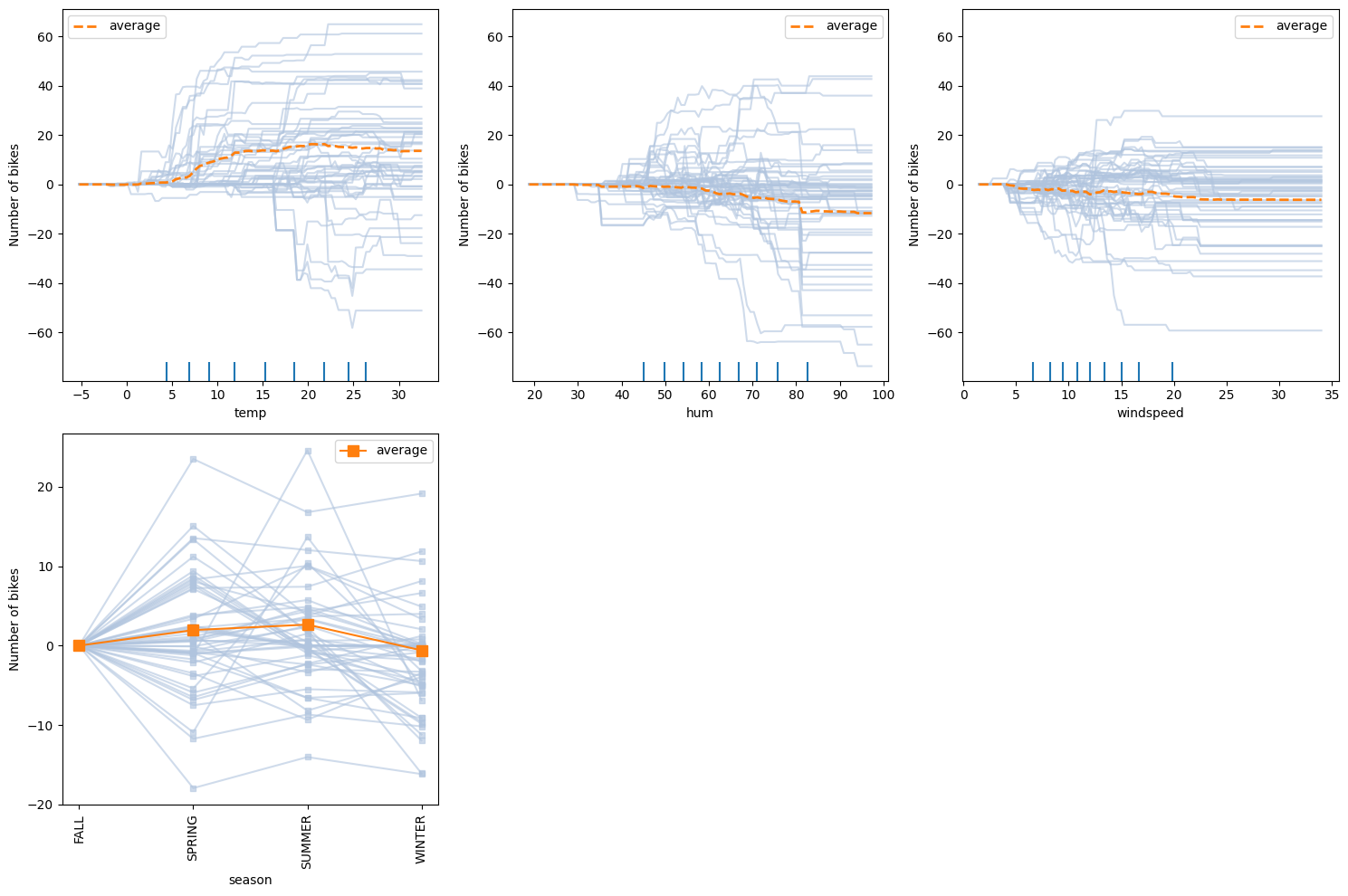
- kind='both' (PDP + ICE): 위의 두 가지를 한 번에 다 계산. 배경에는 1,000개의 얇은 선(개별 반응)을 쫙 깔아두고, 그 위에 굵고 진한 선(전체 평균)을 얹어서 함께 보여줄 준비를 마친 것
both가 주는 인사이트 : 피처에 따라 극단적으로 다르게 반응하는 그룹이 있는지 살펴볼수있음 (피처간 상호작용가능)
(feature_names.index('temp'), feature_names.index('windspeed')),
(feature_names.index('mnth'), feature_names.index('weather')),
(feature_names.index('season'), feature_names.index('temp'))
]
# compute explanations
exp = explainer.explain(X=X_train,
features=feature_interaction,
kind='average',
grid_resolution=25)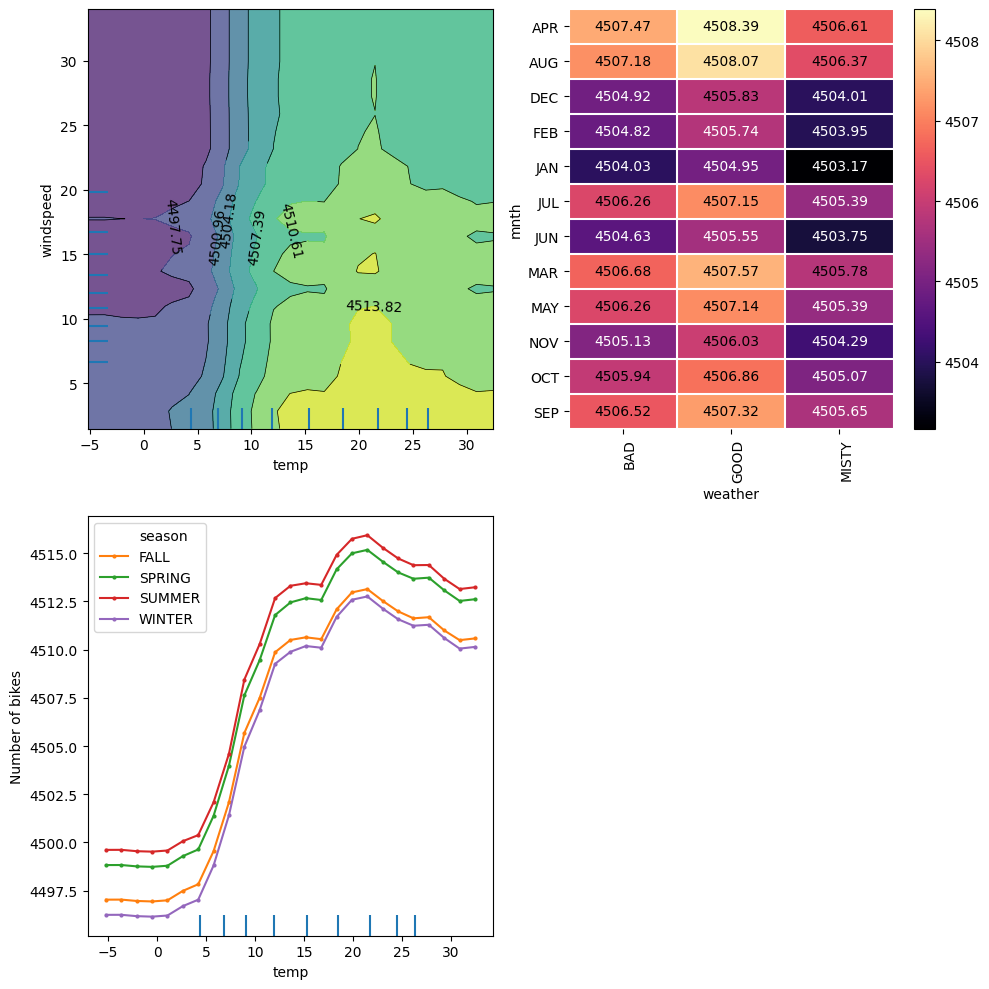
- 두 피처를 짝지어서 넣어서 두개의 피처가 서로 어떻게 상호작용하며 예측값에 영향을 미치는지 분석
from alibi.explainers import plot_pd_variance
plot_pd_variance(exp=exp_importance)