Background
Deep convolutional neural networks는 층이 깊어질 수록 feature의 추상화 정도?가 올라감
→ 즉 층이 깊어질 수록 다양한 이미지 표현가능
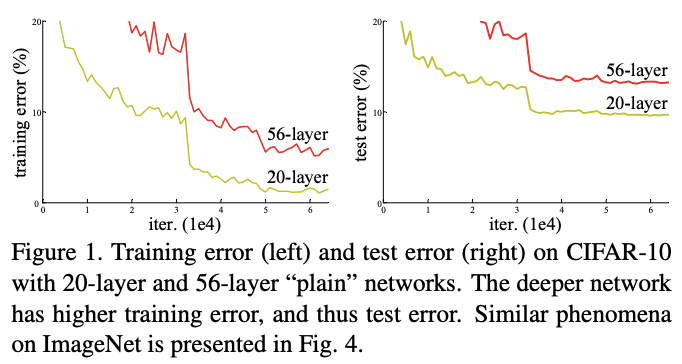
기존의 vgg-net을 이용해서 층을 깊게 쌓았을 때의 figure
층을 깊게 쌓았을 때 성능 저하가 발생하는 데 figure를 봤을 때 overfitting 문제가 아니라, 수렴이 하지 않는 문제로 판단.
! 층을 깊게 쌓았을 때 성능 저하 없이 수렴시킬 수 없나..?!
Key Idea
Is learning better networks as easy as stacking more layers?
를 아주 얕은 layer를 거쳐 나온 결과라고 생각해보자.
를 근사 시키는 것은 어려울 수 있다 라고 생각하고 를 학습 시키는 것은 잔차만 학습하면 되므로 비교적 쉽게 학습 가능하다.
따라서 해당 논문은 를 학습 시키는 것을 목적으로 한다.
→ 이런 아이디어는 어떻게 나왔나?! deeper network가 shallow한 network보다 training error가 높은 것을 보고 identity mapping이 있으면 training error를 줄일 수 있겠는데?! 라는 가설을 세움
→ 층이 깊어지면 exploding/vanishing 문제가 발생했기 때문
왜 잔차를 학습하는 것이 더 좋을까?
layer를 거쳐 나온 값이 input값에서 급변하지 않는다!
Architecture
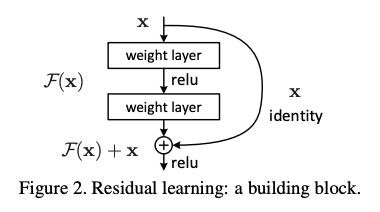
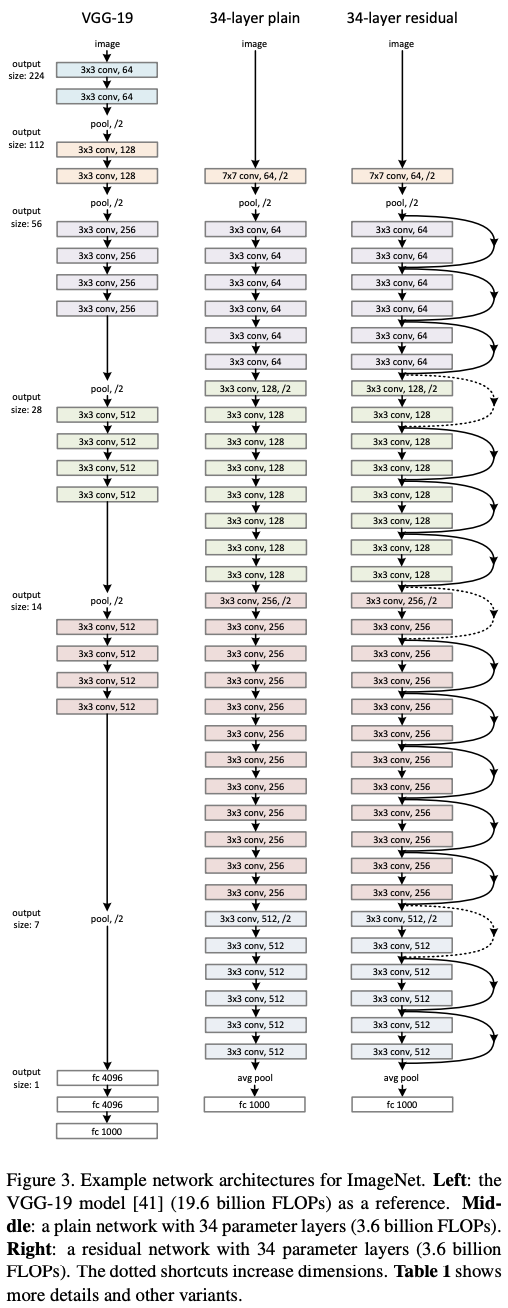
Experiment
ImageNet 2012 classification dataset으로 실험 진행
train set: 1.28million
validation set: 50k
test set: 100k
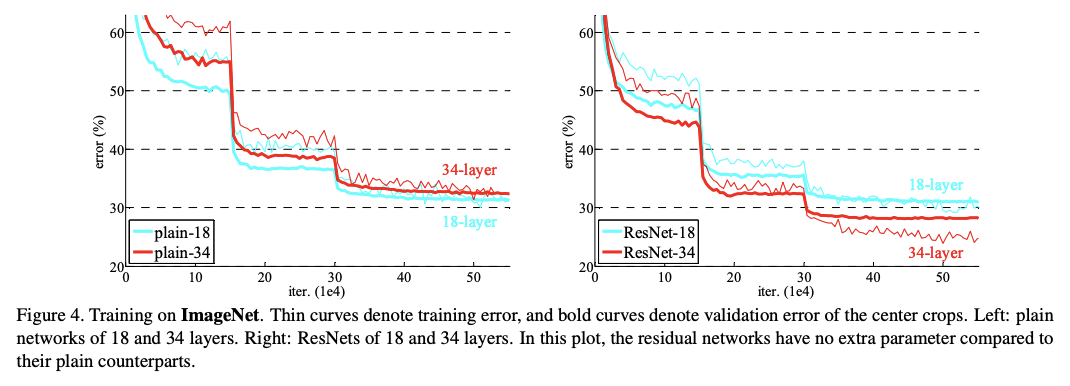
- resnet이 plain보다 수렴 속도도 더 빠름
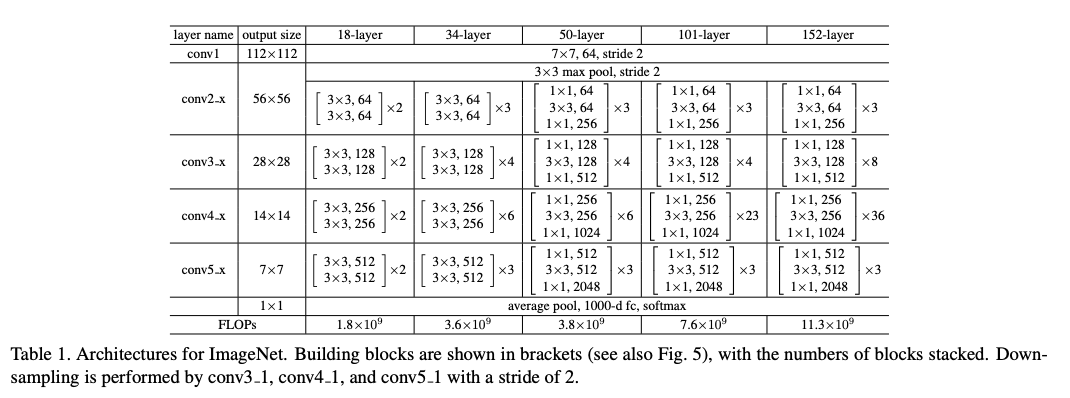
- 34layer까지는 residual block을 2개의 layer를 합친 반면에 50 layer부터는 3개의 layer를 합침(bottleneck design)
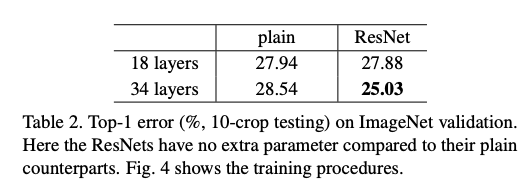
- 층이 깊어질 수록 error가 줄어드는 것 확인 가능
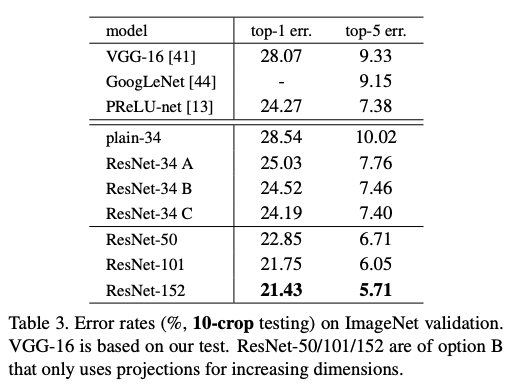
- A는 shortcut을 하기 위해 zero pedding을 해서 더해줌
- B는 projection + identity
- C는 전부 projection
- 모두 projection 한 후 더해주는 것이 좋음 but projection을 위한 parameter가 늘어나기 때문에 잘 고려해야함
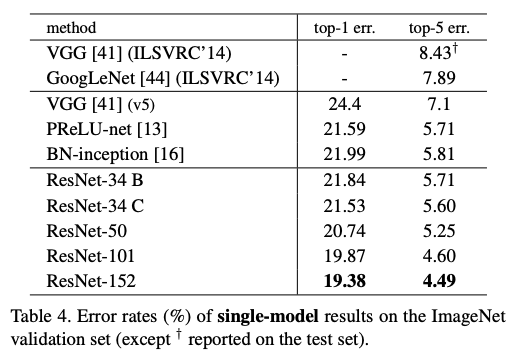
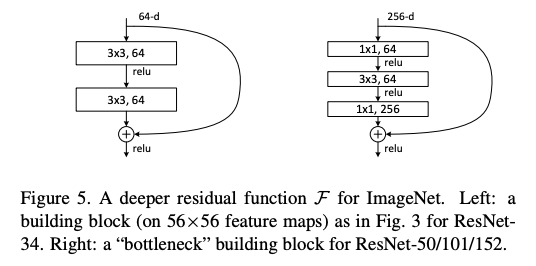
- Conv를 위 아래로 넣어줌으로써 computational cost를 줄임
- layer를 늘림으로써 non-linearity 증가
CIFAR10
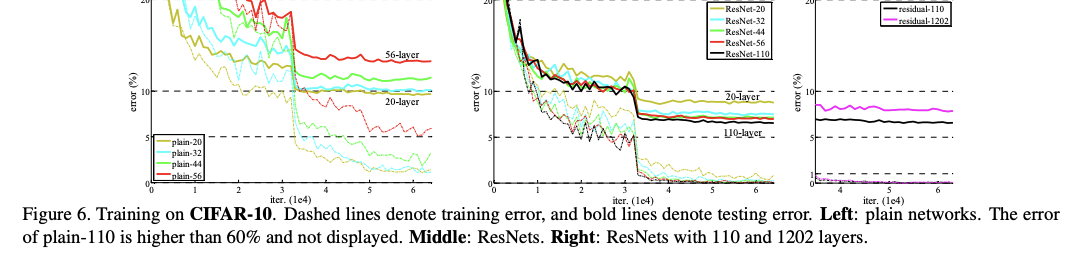
-
층이 너무 깊어지면 error 증가
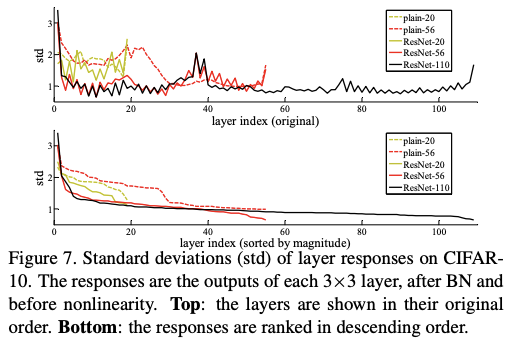
-
3x3 layer BN을 거친 후 layer response
→ std가 굉장히 적음 → BN을 거친 후이므로 0근처에 분포해있음 → plain보다 최적화에 용이하다. -
깊은 resnet은 더 적은 std를 보여줌 → 층이 깊어질수록 아주 미세하게 바뀜
