
The objective of a decision-making agent
- Agent의 목표는 에피소드나 특정 task를 수행하는 동안 return을 최대화하는 sequence of actions을 찾는 것.
- return =
- 할인율 가 적용된 return
→ recursive로 표현
Policy
정책은 에이전트의 행동전략이다.
정책의 종류로는 stochastic와 deteministic이 있다.
정책 평가
- state-value function: What to expect from here?

- state-value-function은 V로 표기하며 어떤 state의 가치를 표현한다.(지금부터 기대되는 return)
- 는 정책 일때의 상태에서 얻어지는 return의 기댓값이다.
- 현재 state에서 모든 행동을 다 해보고 얻어지는 기댓값 → Discounted Factor 를 적용한 Reward 총합 기댓값
- Action-value function: What should I expect from here if I do this?
- state 에서 라는 action을 취했을 때 얻게되는 value(지금 행동으로부터 기대되는 return)
- 로 표기한다.
- function은 동적인 환경에서 잘 작동할 수 있고, MDP 없이도 정책을 개선할 수 있다. → 상호작용하는 환경을 통해서 q function을 만들고 q function을 통해 정책을 개선한다.

-
Action-advantage function: How much better if I do that?
특정 액션을 취하는 것이 다른 액션을 취하는 것보다 얼마나 좋은가?
- 현재 상태 s에서 a의 액션을 취했을 때 얻는 기댓값 - 현재 상태에서 모든 액션에 대한 기댓값의 평균

현재 정책을 평가할 수 있는 function들이다. 현재 상태에서 모든 상황을 고려한 기댓값(V-function), 특정 행동을 선택했을 때의 기댓값(Q-function), 특정 행동이 다른 행동보다 얼마나 좋은지에 대한 평가(active-advatage function)
Planning optimal sequence of actions
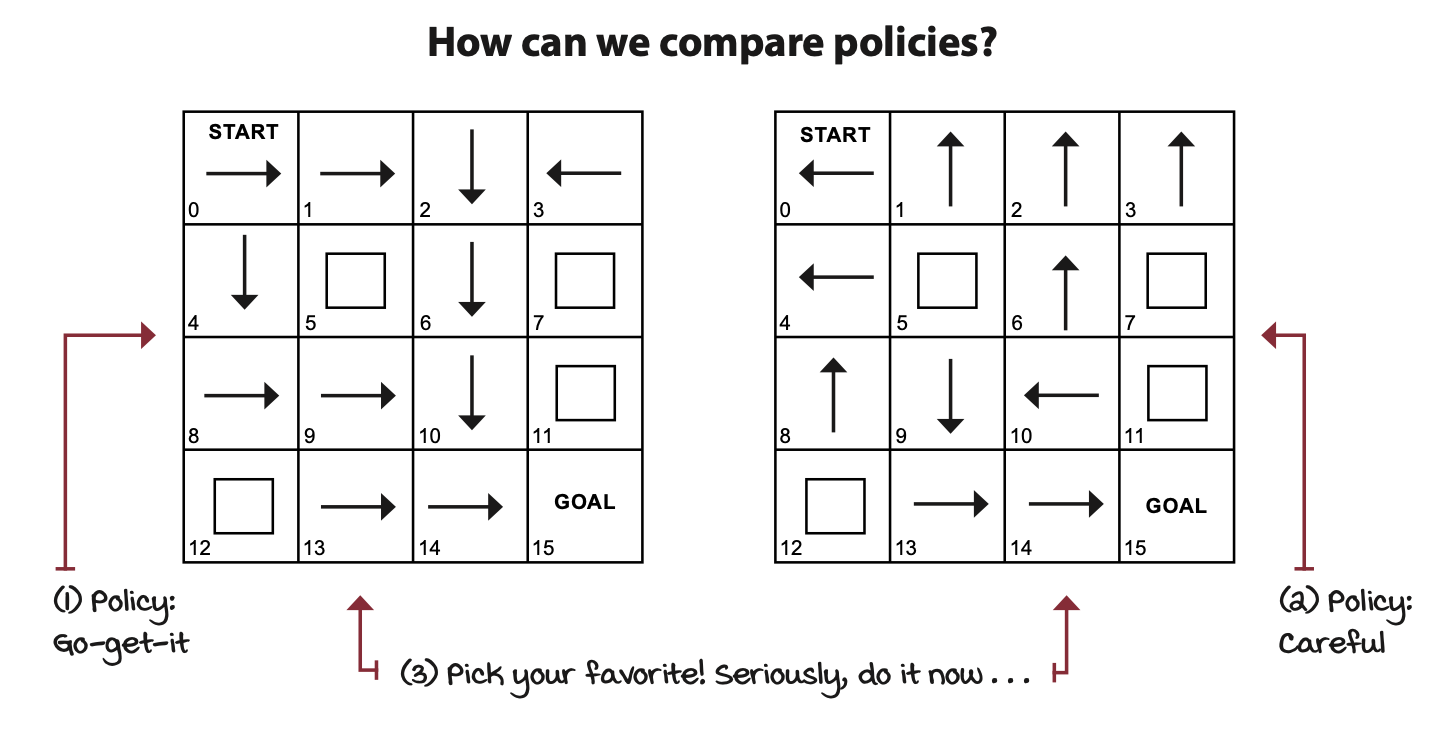
Policy evaluation: Rating policies
- 모든 state에 대해서 Value-function을 반복 적용
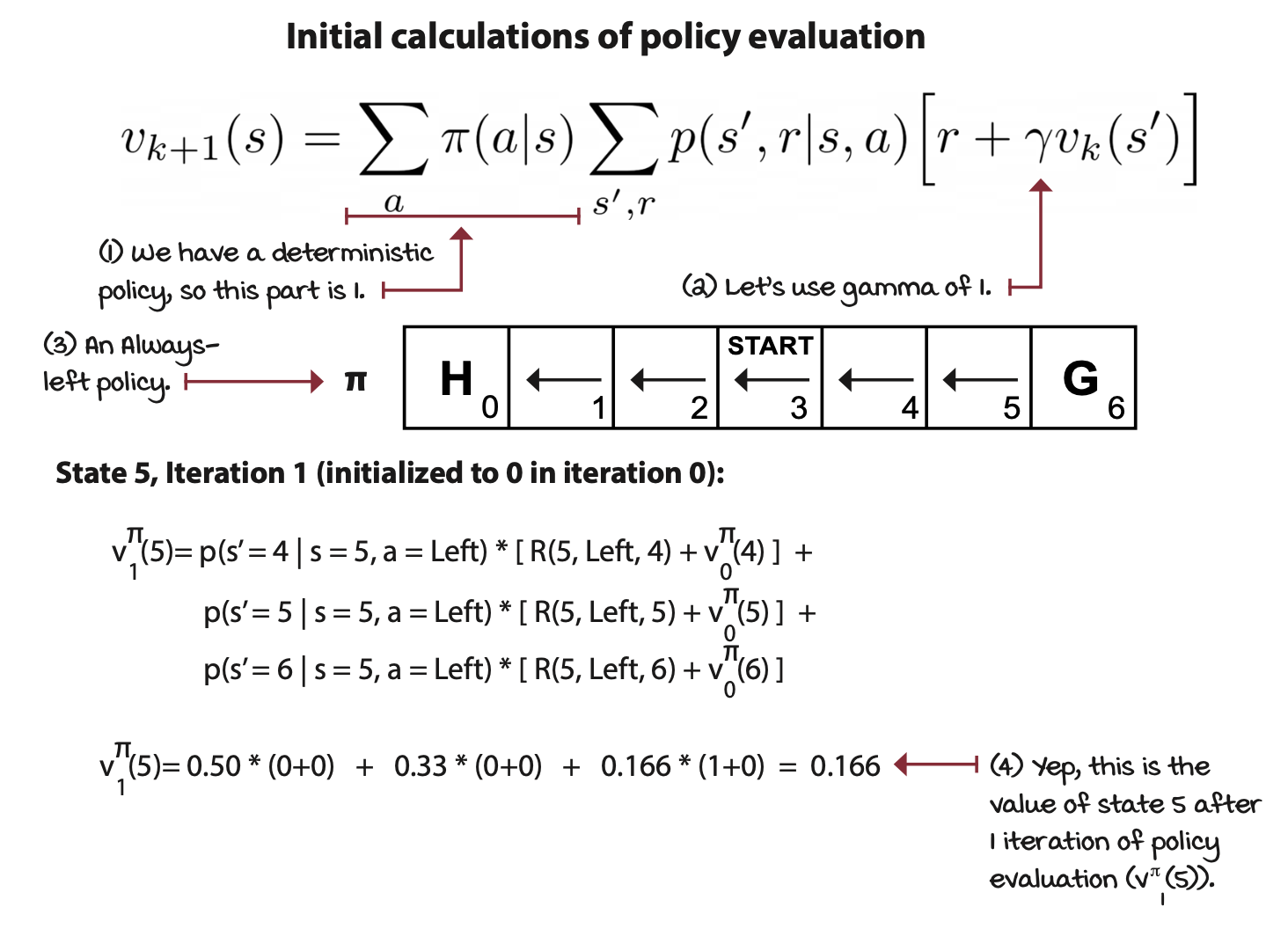
해당 상황에서는 액션을 취했을 때 성공할 확률 50% 머무를 확률 33프로 반대로 갈 확률 0.1666으로 환경을 알고 있는 상황이다.
- state 5를 예시로 봤을 때 해당 state에서는 다음 state로 4,5,6을 가질 수 있다. 다음 state들의 value를 이용해 현재 state를 갱신한다. → 처음 모든 state의 value를 0으로 둔 상태에서 반복적으로 state value를 갱신하는 것이기 때문에 state 6을 제외한 나머지 state value들은 모두 0이다.
- 각 state의 value가 수렴할 때까지 반복한다.
아래 사진은 반복적으로 적용하였을 때이다.
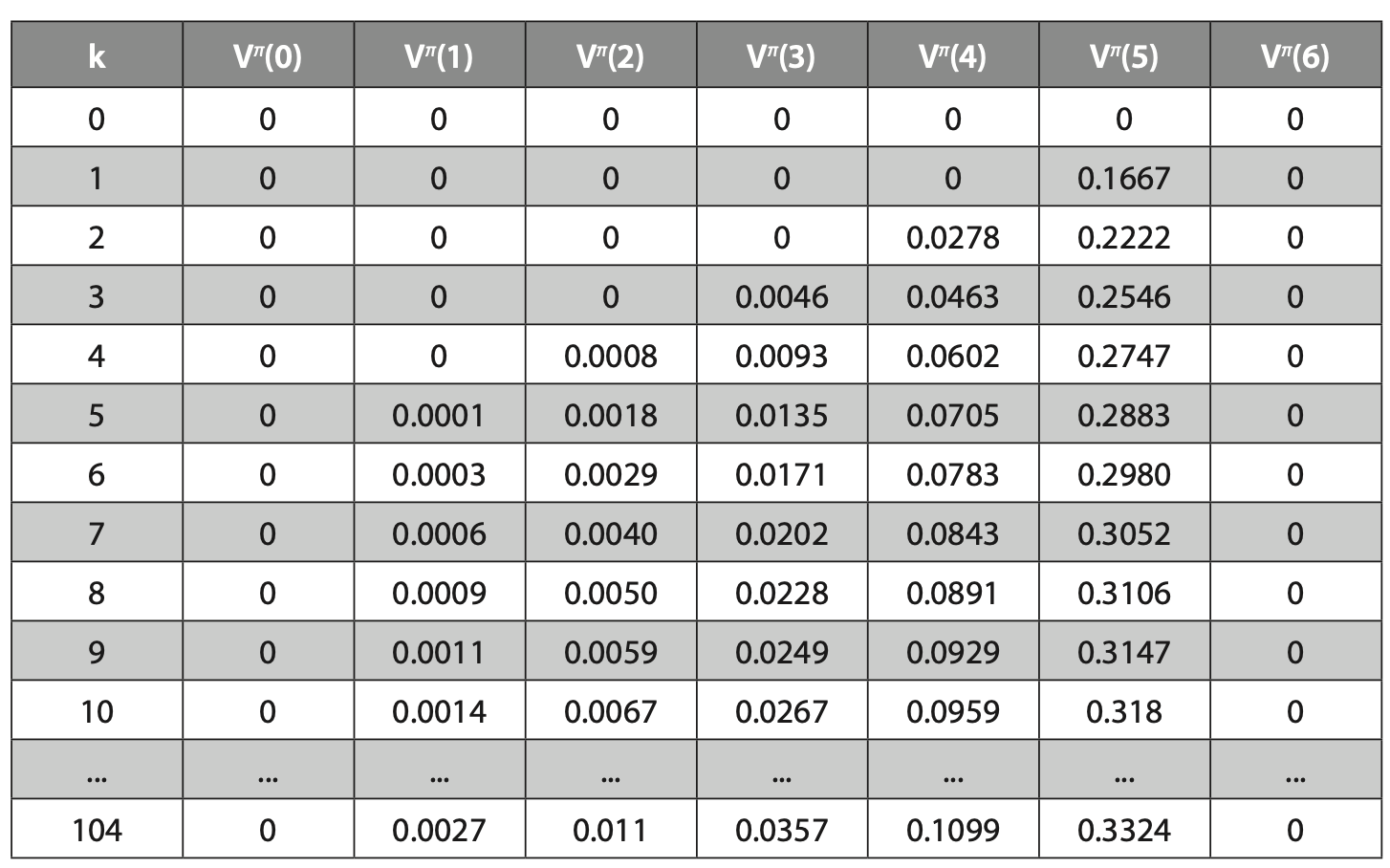

좋은 건 당연히 좋은거다