1. Introduction
기존 기계번역에서는 encoder-decoder 형식의 인공신경망을 사용하였다. Encoder는 input을 받아 고정된 길이의 context vector를 만들고 Decoder는 context vector를 이용하여 output을 만들어낸다.
해당 논문에서는 고정된 길의의 vector에 많은 정보량을 담는 것이 긴 문장을 번역하는 것에 어려움이 있다고 말한다.
따라서 해당 논문에서는 decoder에서 하나의 ouput을 출력할 때마다 입력 문장을 순차적으로 탐색해서 현재 생성하려는 부분과 가장 관련있는 영역을 집중하여 output을 출력하는 모델을 제시한다.
2. BACKGROUND: NEURAL MACHINE TRANSLATIONBACKGROUND: NEURAL MACHINE TRANSLATION
확률론적인 관점에서 NMT(Neural Machine Translation)을 보자면 입력문장 가 주어졌을 때 를 최대화하는 문장 를 찾는 것이다.
2.1 RNN ENCODER–DECODER
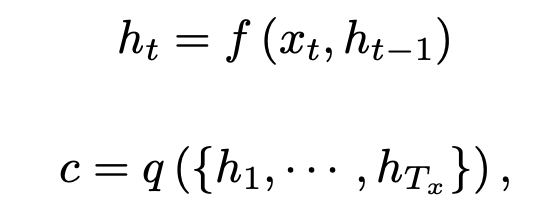
RNN을 사용한 인코더에서는 input sentence 를 입력으로 받아 고정된 길이의 로 변환한다.
위 식에서 는 time t에서의 hidden state이다.
의 hidden state는 해당 시점의 입력과 시점의 hidden state를 통해 업데이트한다.
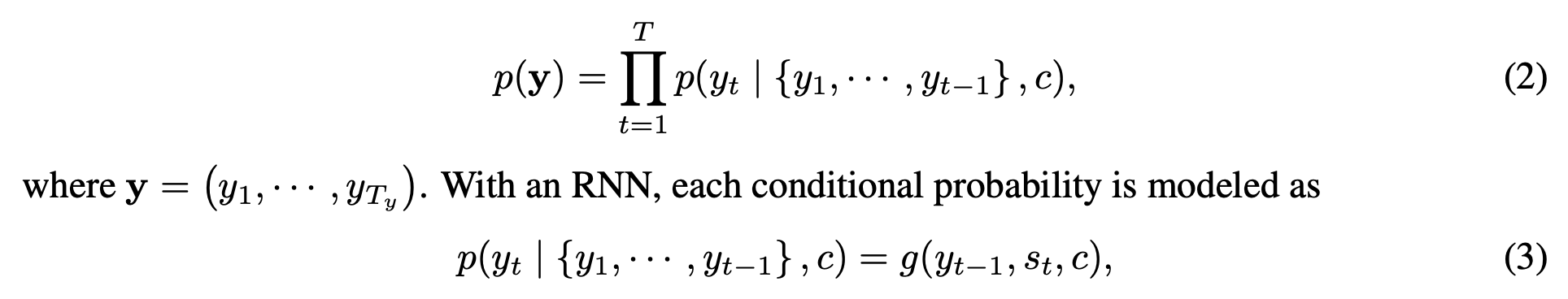
디코더에서는 context vector c를 인코더에서 받은 후 이전의 ouput들을 고려하여 를 예측한다.
해당 내용을 식으로 표현하면 위와 같다.
3. LEARNING TO ALIGN AND TRANSLATE
해당 논문에서는 기존의 bidrectional RNN 인코더 디코더 구조를 바꿔 새로운 model archietecture를 제안한다.

3.1 DECODER: GENERAL DESCRIPTION
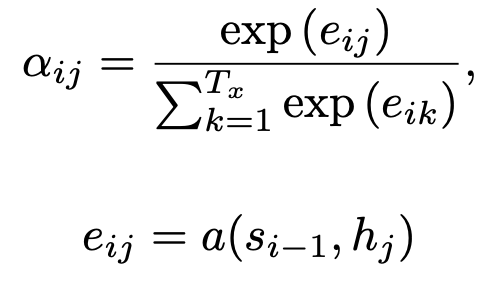
Time i에서 decoder의 hidden state를 이라고 한다. Alignment model에서는 decoder의 time i 에서의 정보다. 그리고 이는 encoder의 각각의 time 에서의 정보와 얼마나 연관성이 있는지 score를 계산한다.
Score는 decoder 의 바로 전 time에서의 hidden state 과 encoder의 time j 에서의 hidden state 를 이용하여 계산한다. 이 때 는 feedforward neural network이다.
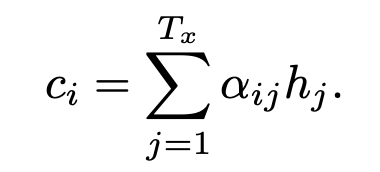
위에서 구한 score를 이용하여 Attention 수치인 를 계산한다. 구한 Attention 값을 이용하여 context vector를 만든다.
즉 각 hidden state에 얼마나 집중을 할 것인가?에 대한 값 를 모든 시점의 hidden state에 곱한 후 합하여 context vector로 사용한다.
이렇게 사용하였을 때 기존 RNN의 단점을 보완할 수 있다. 기존 RNN은 제한된 길이의 context vector에 많은 정보를 담아야함으로써 정보의 손실이 컸고, 입력이 길어지면 context vector가 최신의 정보만 많이 담고있었다. 하지만 모든 hidden state에 집중 정도(attention)을 weighted sum을 하여 사용함으로 써 context vector에 필요한 정보만 넣을 수 있게 됐다.
3.2 ENCODER: BIDIRECTIONAL RNN FOR ANNOTATING SEQUENCES
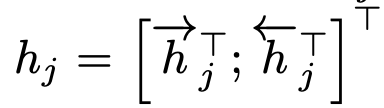
BiRNN을 이용하여 hidden state를 생성한다. forward RNN은 처음부터 순차적으로 읽어 hidden state를 생성한다. backward RNN은 역순으로 읽어 hidden state를 생성한다. 최종 hidden state는 forward와 backward를 거쳐서 나온 hidden state를 concat하여 사용한다.
이렇게 hidden state를 만들게 되면 hidden state에 앞으로 올 단어와 이전 단어들의 정보가 모두 들어가게 된다.
4. EXPERIMENT
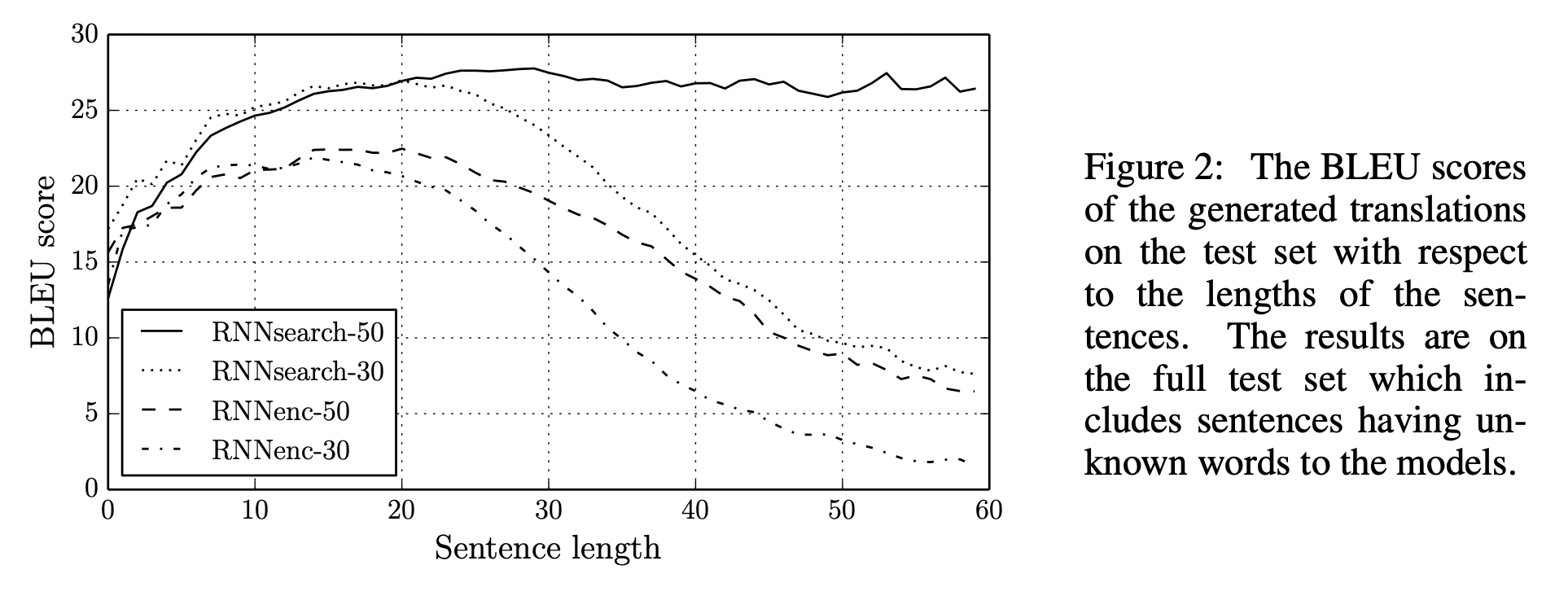
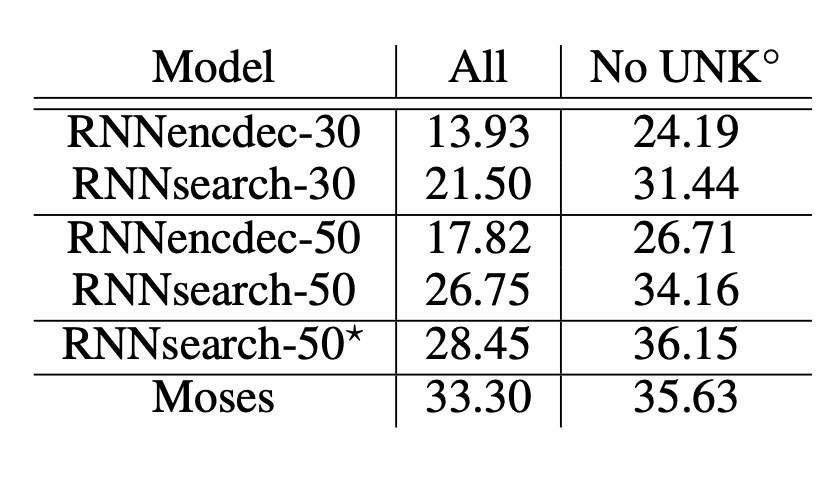
긴 sentence에 대해 기존의 RNN encoder decoder모델보다 훨씬 좋은 성능을 나타냄을 볼 수 있다.
Conclusion
기본 인코더-디코더를 확장하여 각 타겟 단어를 생성할 때 모델이 입력 단어 집합 또는 인코더가 계산한 해당 단어들의 context vector를 찾도록 함으로써, 전체 소스 문장을 고정 길이 벡터로 인코딩하지 않아도 되게 하였으며, 또한 모델이 다음 타겟 단어 생성에 관련된 정보에만 집중할 수 있게 했다. 이는 기계 번역 시스템이 긴 문장에서도 좋은 결과를 산출할 수 있도록 하는데 주요한 영향을 미쳤다.
