Introduction
- Pre-trained word representations는 neural language understanding에서 핵심.
- High quality representation은 2가지를 잘 modeling 해야함
-
단어의 복잡한 특성
-
언어학적인 문맥 상에서 다르게 사용될 때 각 문맥에서의 맞는 representation이 필요하다(Ex 다의어)
-> 기존 word embedding은 contextual representation을 잘 학습하지 못 하였다.
ELMo: Embeddings from Language Models
- 전체 문장을 input으로 받아 word representations을 만든다
- bidrectional LSTM을 활용하여 language model을 학습시킴
language model: 이전 단어의 squence를 통해서 다음 단어를 예측하는 모델
3.1 Bidrectional language models
Mathematical demonstration
forward language model
N개 토큰의 squence가 주어졌을 때 foward language model은 토큰 의 확률은 에서 까지 고려하여 계산한다.
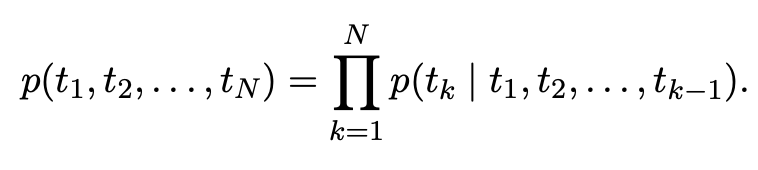
- 은 context independent한 token representation으로 기존의 token embedding이나 chracter level의 CNN통해 만든다.
-> 만들어진 을 L개의 layer을 가진 forward LSTM을 통과시킨다. - 은 k번째 token이 j번째 layer에서 가진 hidden token이다.
->ELMo에서의 hidden token은 context dependent하다. - 제일 마지막 층 LSTM 이 를 예측하는데 사용된다.
backward language model
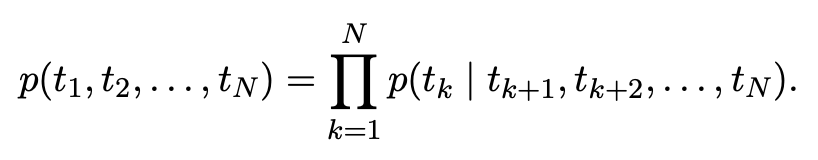
- backward language model은 forward language의 역방향으로 진행한다.
likelihood
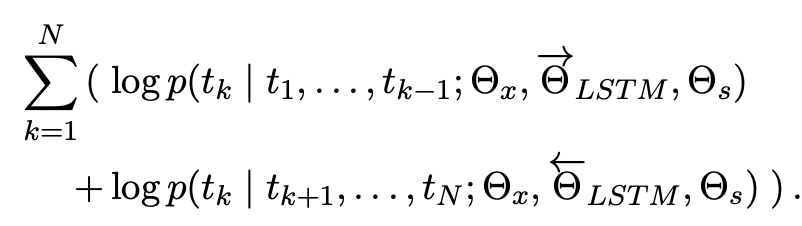
- forward language model의 likelihood와 backward language model의 likelihood를 최대화 해야한다.
ELMo representation

- 총 2L + 1개의 representation을 학습한다.
-> forward 은닉층 L개, backward 은닉층 L개, 1개로 총 2L+1개를 학습한다.
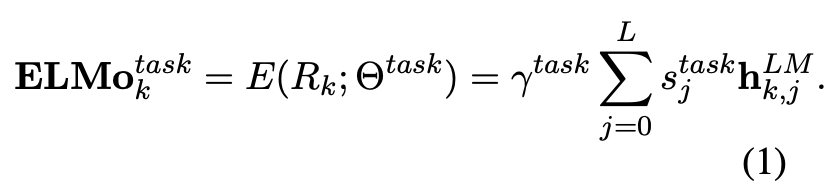
는 softmax-normalized weights로 모든 가중치는 0~1이며 합 했을 때 1이된다.
는 전체 ELMo vector에 대해 scaling해주는 부분이다. - 총 학습된 2L+1개의 representation을 가중합 하여 하나의 임베딩 벡터로 표현한다.
(가중치는 downstream task에 따라 달라진다)
biLM(요약)
forward language model + backward language model
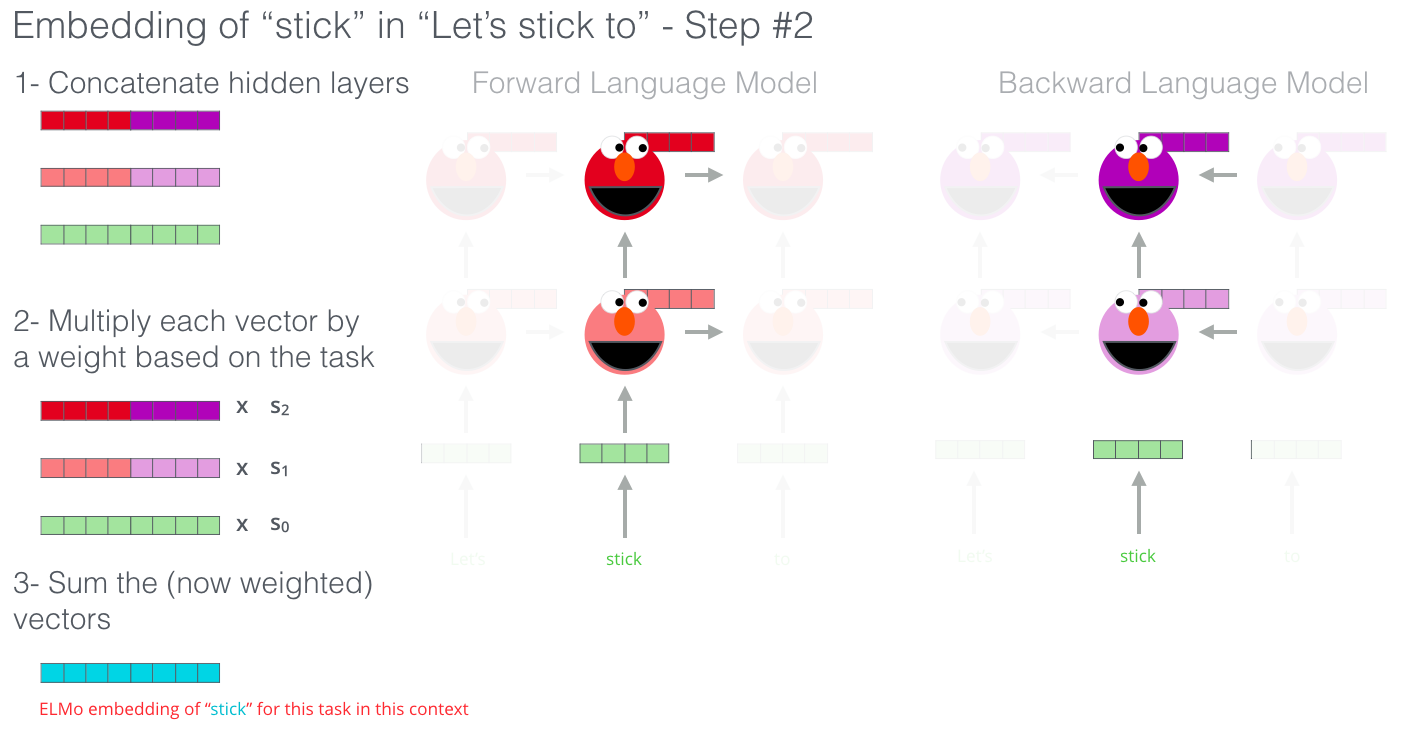
- 각 layer의 hidden vector를 concat한다
- concat한 각 hidden vector에 가중치를 곱한다
-> 가중치를 곱하는 이유는 각 층마다 학습하는 것이 다르다.
lower LSTM layer는 기본적인 syntax와 같은 것을 학습하고 higher LSTM layer는 조금 더 복잡한 문맥과 같은 것을 학습한다. - 구해진 해당 벡터들을 합하여 최종 embedding vector로 사용한다.
Evaluation
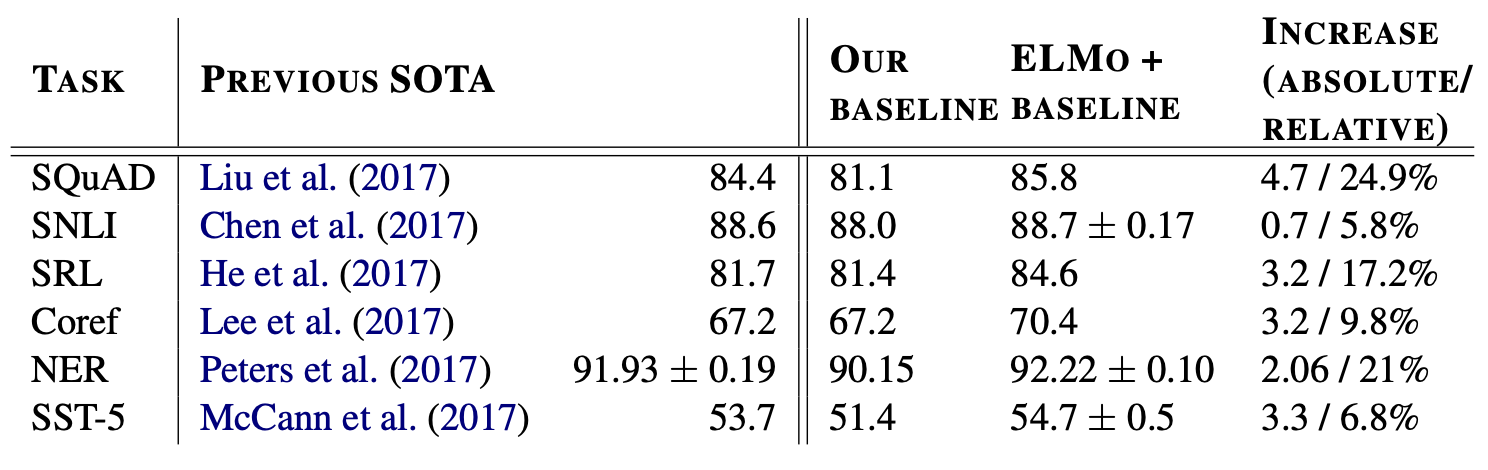
- 다양한 downstream task에 대해 모두 성능 향상을 보였다.
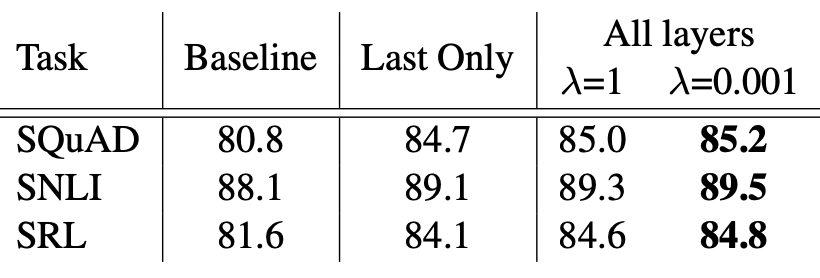
- 의 값을 작게 하는 것이 성능이 좋았다
Analysis
Alternate layer weighting schemes
layer를 어떻게 가중합을 하면 좋을까?
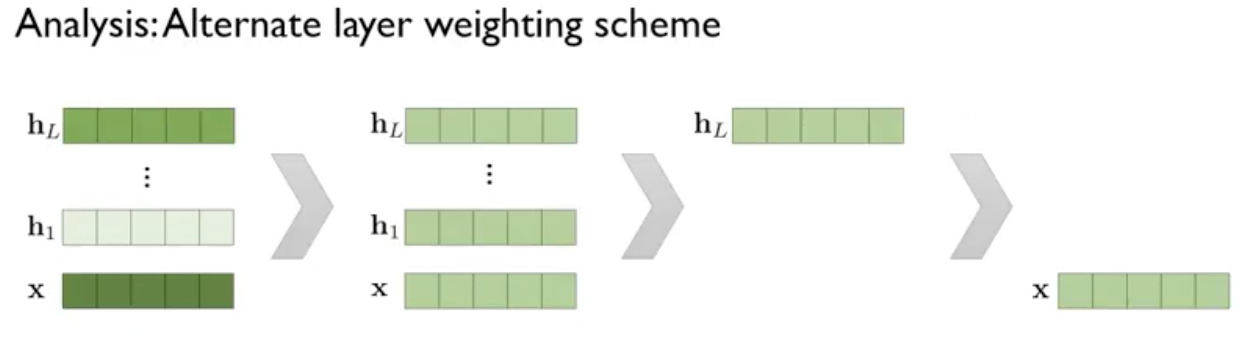
순위
1. task에 맞게 가중합을 하는 것
2. 단순 평균 내는 것
3. LSTM 최종 layer의 hidden vector을 쓰는 것
4. input으로 들어가는 word embedding을 쓰는 것
where to include ELMo?
downstream task에 대해서 ELMo를 어디에 쓸 것인가?
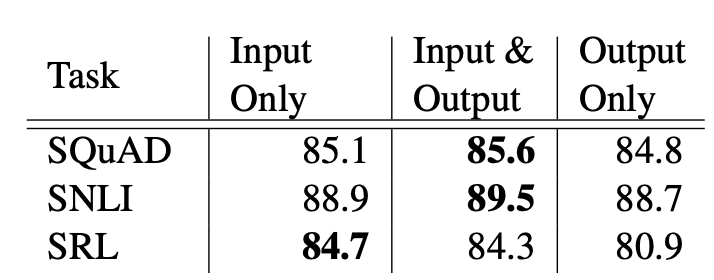
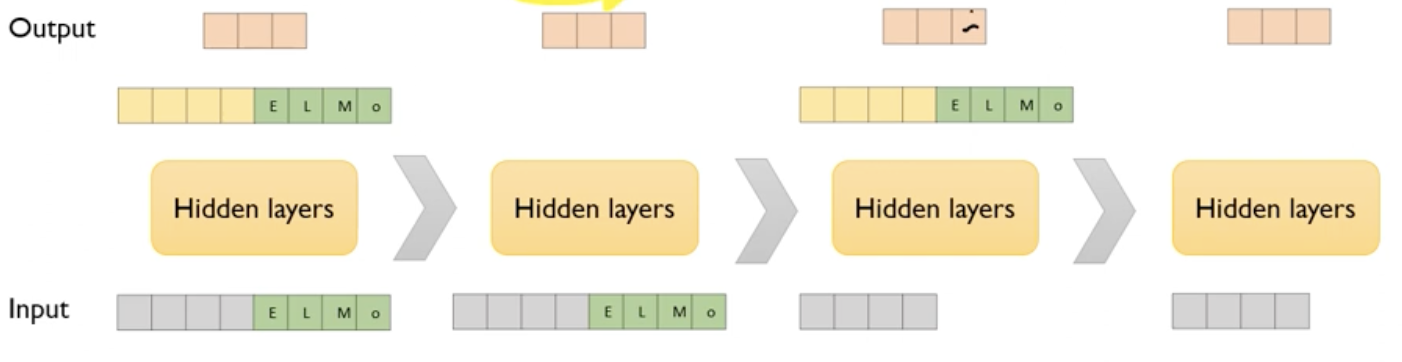
일반적인 성능 비교
1. Input에 ELMo를 결합하고, hidden layer을 통과한 결과값에 ELMo를 결합하여 output을 출력하는게 가장 성능이 좋았다.
2. Input에 ELMo를 결합하고 hidden layer을 통과 후 바로 ouput을 출력하는 것이 성능이 좋았다.
3. Input을 hidden layer을 통과 시키고 나온 결과에 ELMo를 결합한 것이 성능이 좋았다
4. ELMo를 붙이지 않은 것이 가장 성능이 안 좋았다.
위 실험을 보면 task에 따라 input에만 붙이는 것이 성능이 더 좋은 경우도 있었다.
출처:https://www.youtube.com/watch?v=zV8kIUwH32M&t=504s
Sample efficiency
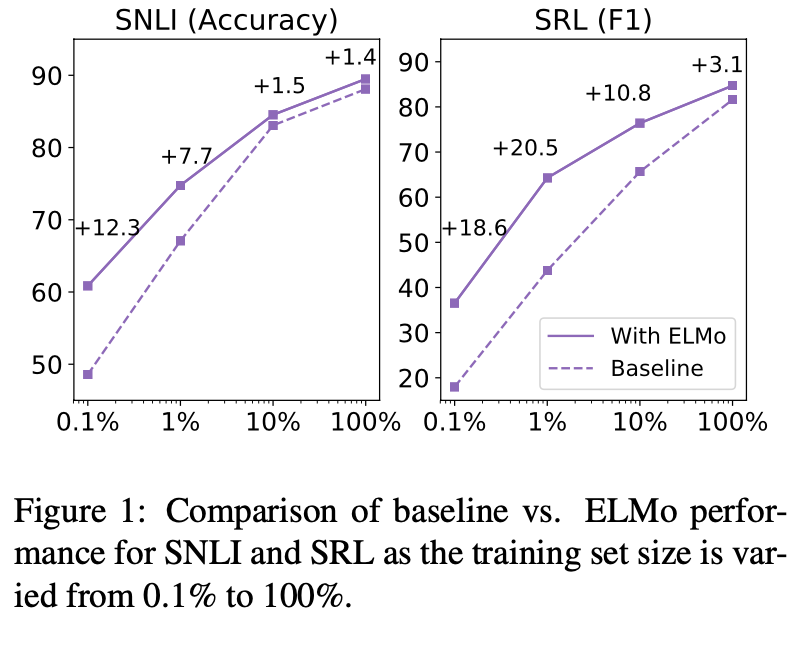
- ELMo를 사용하는 것이 학습속도가 빨랐다.
- 적은 데이터 셋에 대해 효율적으로 학습한다.
Conclusion
- 깊은 문맥의존 representations 학습하는 일반적인 방법을 제시하였다.
- 다양한 NLP task에 성능 향상을 만들었다.
- biLM 계층이 문맥 내 단어들에 대한 다른 유형의 구문 및 의미 정보를 효율적으로 인코딩하고, 모든 계층 사용 시 전반적인 작업 향상을 보였다.

좋은 건 당연히 좋은거다