Abstract
1. LSTM은 RNN 계열의 모델중 하나로 기존 RNN보다 temporal sequences, long-range depedency에서 성능을 개선했다.
- temporal sequences: 시간에 따라 변하는 데이터의 순서
ex) 음성신호, 동영상 프레임, 주식 가격 등등 시간적 순서를 가진 데이터 - long-range dependecies: 데이터 포인트간의 시간적으로 멀리 떨어져 있는 관계
2. ASGD(Asynchronous Stochastic Gradient descent)를 이용한 분산학습 사용
3. 2개 이상의 깊은 LSTM층에서 linear recurrent projection layer를 추가하여, 파라미터 상에서 연산량을 줄일 수 있다.
해당 논문은 acoustic speech recognition을 위해 모델링 하였다.
1. Introduction
1. speech는 복잡한 시간 단위마다 다른 상관관계가 있는 복잡한 데이터이다.
- 예를 들어 "안녕하세요, 오늘 날씨가 정말 좋네요. 어떻게 지내셨어요?"라는 대화에서는 처음 인사와 날씨 소개는 비교적 짧은 시간 동안 이뤄지지만, 전체적인 대화의 맥락은 더 긴 시간 동안 이뤄진다. 처음 안녕하세요를 말하는 시간이 1초 총 문장을 말하는 시간이 3초라고 하면 1초보다 작거나 같은 시간동안엔 큰 의미를 가지지 않는 음소의 나열이다. 하지만 총 3초의 스케일동안 이를 관찰해보면 이 대화가 어떤 의미를 가지고 있는지 알 수 있다. 이처럼 음성은 각각 다른 시간 스케일에서 정보를 전달한다.
2. 기존 DNN 모델이 speech에서 높은 성능을 보였는데, 실제론 이런 speech 데이터를 올바르게 모델링하는데 한계가 있다.
- DNN 모델은 고정된 window를 받으므로 speech의 time scale을 모두 커버하긴 어렵다.
- DNN 모델은 input 값들이 독립적으로 들어오기 때문에 이전 time step의 정보를 고려하기가 어렵다.
3. RNN 계열의 모델들은 이전 time step 내부 state에 저장되어 현 time step에도 영향을 주기 때문에 이전 정보들을 고려한다. 특히 LSTM은 일반 RNN의 long-range dependency 문제를 장기 기억 cell state를 통해 일부 완화한다.
2. LSTM Network Architectures
2.1 Conventional LSTM
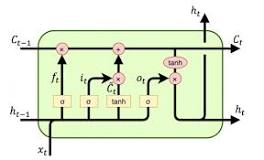
- Cell state 추가
-> 과거의 정보들을 가지고 있는 기억장치라고 생각하면 편하다 - Input gate, Forget gate 등을 통해 Cell state를 관리한다
→ Input gate는 이전 output값과 이번 step의 input값에 각각 가중치곱 후 시그모이드 함수를 통과시켜 이전 output값의 정보를 얼마나 cell state에 넣을지 결정한다
→ Forget gate는 이전 output값과 이번 step의 input값에 각각 가중치곱 후 시그모이드 함수를 통과시켜 이전의 cell state 값을 얼마나 잊을지 결정한다
[Modern LSTM]
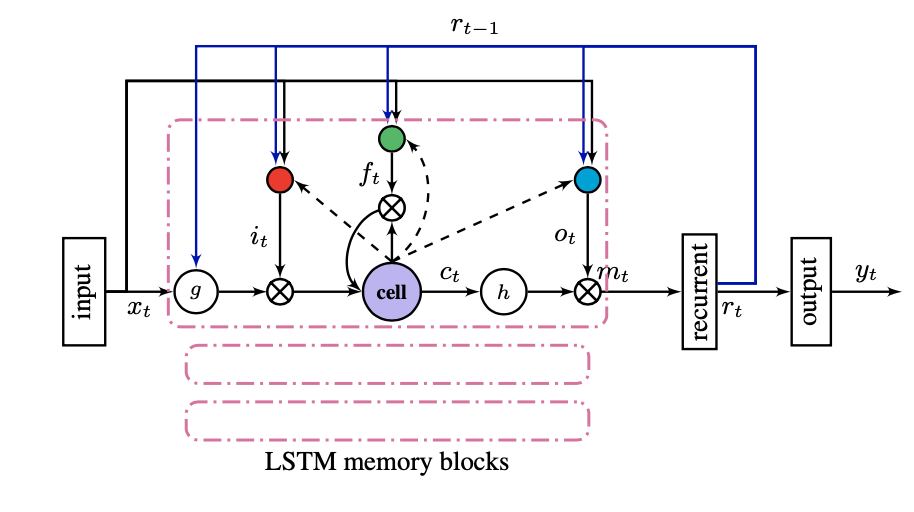
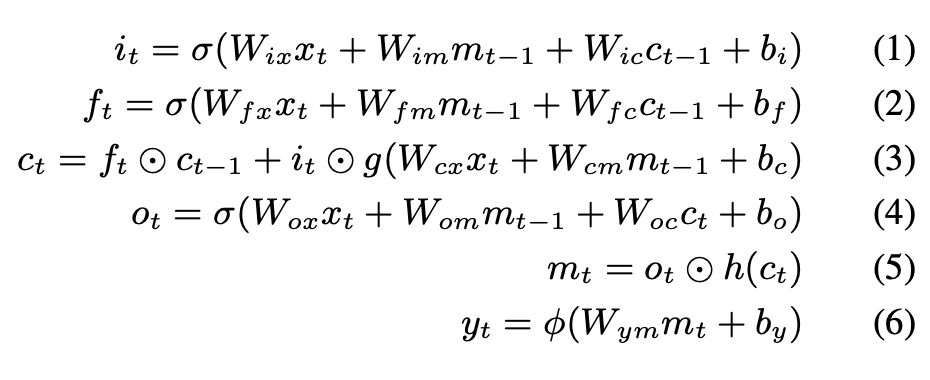
- 요즘의 LSTM은 Peephole Connections을 도입한다.
→ Peephole Connections는 LSTM memory block의 각 셀에서 gate로 향하는 연결을 의미한다.
기존 LSTM은 gate에서 output, 현재의 input만을 입력으로 받았다. 하지만 Peephole Connection은 이전 Cell state를 gate에 사용함으로써 더 많은 맥락을 고려할 수 있게 해주었다.
2.2 Deep LSTM
기존의 LSTM 또한 같은 파라미터를 공유하는 feed-forward 신경망으로 간주할 수 있지만 해당 논문에서는 부가적인 의미를 갖는다.
-
다양한 Time scales에서의 학습이 가능하다.
→ 각 레이어는 입력 시퀀스의 정보를 처리하여, 레이어가 깊어질수록 다양한 시간에서 패턴이나 종속성을 파악할 수 있다 -
파라미터 효율 및 분포
→ 심층 구조에서는 파라미터가 여러 레이어에 분산되어 있으며, 각 레이어는 특정 특징이나 표현을 학습한다.
-> 단일 구조의 LSTM에서는 output을 출력할 때만 비선형 함수를 통과한다. 하지만 레이어가 여러 층으로 쌓일 경우 비선형성이 증가하여 더 다양한 표현을 학습가능하다.
ex) 음성 처리에서 하위 층은 단순한 음향 특징을 학습하고, 상위 층은 이러한 특징들을 조합하여 단어나 문맥을 이해한다 -
단일 레이어 LSTM: 한 명의 학생이 모든 음악 정보를 한 번에 다 이해하고 처리. 아주 단조로운 음악이라면 가능할 수도 있겠지만 일반적인 음악에서 모든 정보를 파악하기는 쉽지 않다.
-
깊은 레이어 LSTM: 여러 학생들이 각자 분야를 맡아서 합작한다. 예를 들어 한 명은 음악의 구조를 이해하고, 다른 한 명은 음향적인 부분을 이해하고 여러 분야로 나눠 이해한다.
→ 각 레이어가 특정 측면을 담당하기 때문에, 전체적으로 파라미터를 더 효율적으로 사용할 수 있다.
2.3 LSTMP-LSTM with Recurrent Projection Layer
1. 기존 LSTM 구조는 층을 여러개 쌓았을 때 computationally complexity가 높아진다.
->각 층은 독립적인 weight 및 bias를 가지고 있다. 따라서 층을 쌓을수록 가중치 및 편향의 수가 기하급수적으로 증가하게 된다.
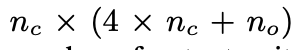
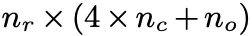
2. 계산 복잡도를 완화하기 위해 해당 논문에서는 recurrent projection layer를 LSTM layer의 input 앞에 배치한다.
→ 일종의 작은 임베딩 차원의 수를 한번에 많이 줄임으로써 계산 복잡도를 줄임
ex) 기존에 임베딩 후 input에 넣는 값이 1000차원이었다면, 임베딩 후 projection layer를 넣어줌으로써 1000보다 더 작은 차원으로 줄임.
2.4 Deep LSTMP
→ LSTM을 여러층으로 쌓은 것과 같이 LSTMP를 여러층으로 쌓은 것이다
3. DistributedTraining:Scalingupto Large Models with Parallelization
- 다중 CPU환경에서 구현됐음. 학습에는 truncated backpropagation through time(BPTT) learning algorithm를 사용하여 계산하고 고정시간(T)에 대해 activation을 forward propagate 하였음
- 각 말(utterance)에 대한 마지막 subsequence는 T보다 짧을 수 있지만, full length로 채워 학습한다.
4. Experiments
5.Result
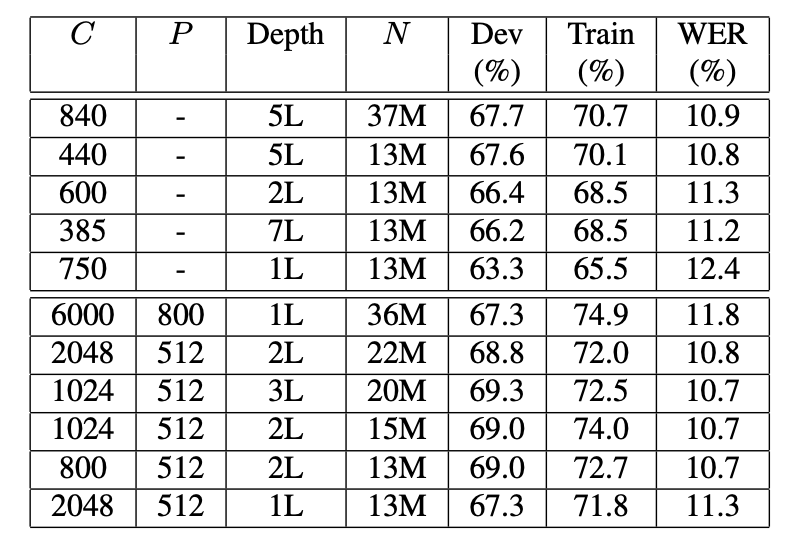
1. 성능 비교 (Table 1):
- 단일 층의 일반적인 LSTM RNN은 대규모 음향 모델링 작업에서 성능이 좋지 않음.
- 두 층의 LSTM RNN으로 성능 향상, 그러나 여전히 제한적.
- 다섯 층의 LSTM RNN은 최고 성능에 가까워짐.
- 일곱 층의 LSTM RNN 훈련이 어려움, 수렴에 시간이 많이 걸림.
- 단일 층 및 많은 메모리 셀을 가진 LSTMP RNN은 훈련 데이터에 오버피팅되는 경향이 있음.
- 더 많은 층을 사용하는 LSTMP RNN은 메모리화 문제를 완화하고 테스트 데이터에 더 좋은 일반화를 보임.
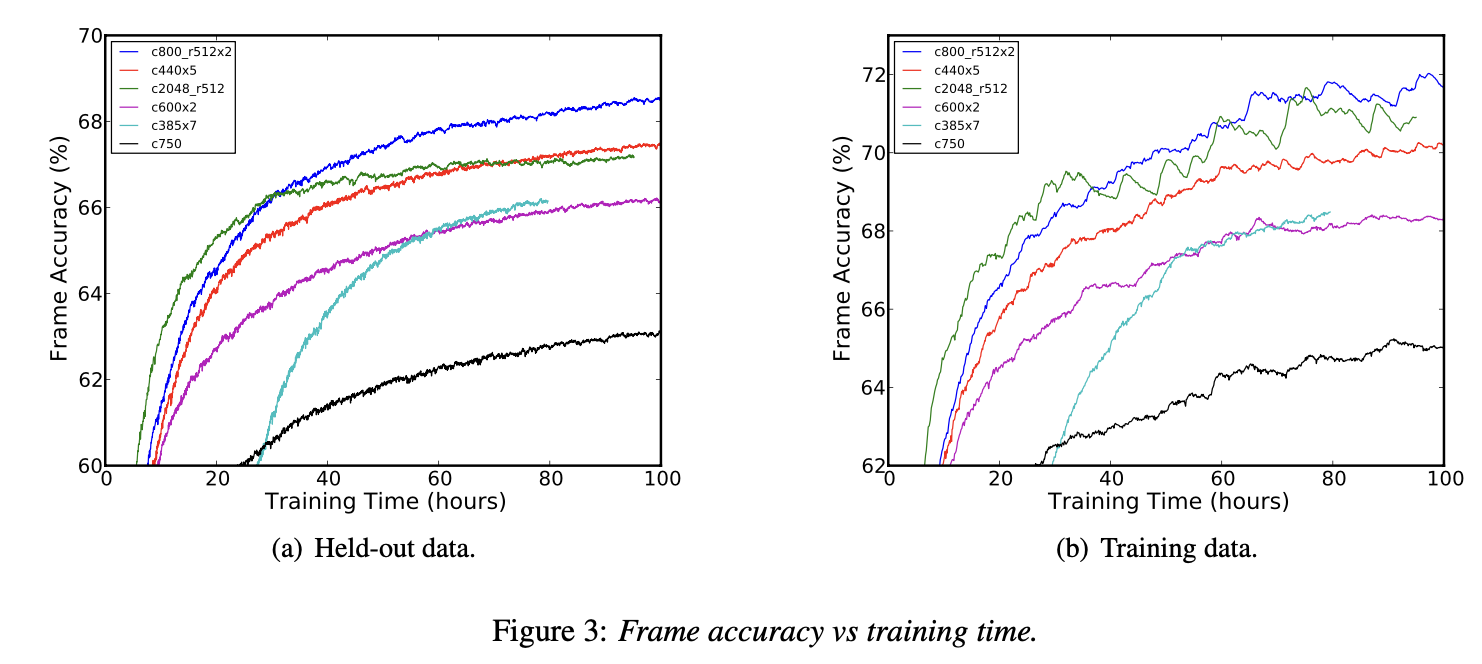
- LSTMP RNN 모델은 5층의 LSTM RNN 모델보다 성능이 조금 더 우수.프레임 정확도 비교 (Figure 3):
- LSTMP RNN 아키텍처의 메모리 셀 수가 많을수록 훈련 데이터에 대한 오버피팅 문제가 뚜렷하게 나타남.
- LSTMP RNN 아키텍처는 LSTM RNN 아키텍처보다 빠르게 수렴함.
- 더 많은 층을 가지는 것이 일반화에 도움이 되지만 훈련이 어려워지고 수렴이 더 느려짐.깊은 LSTMP RNN 아키텍처 성능 (Table 2):
- 13M보다 많은 파라미터를 가진 LSTMP RNN 아키텍처는 성능 향상이 없음.
- 파라미터 수를 크게 줄여도 성능에 큰 영향을 미치지 않음.
- 2층으로 구성된 깊은 LSTMP RNN 아키텍처는 48시간 안에 대부분 수렴하며 독립적인 테스트 세트에서 10.9%의 WER을 제공. 100시간 훈련으로 WER을 10.7%로 개선하고, 200시간 훈련으로 10.5%로 개선.
- 85M 파라미터를 가진 DNN 모델은 11.3%의 WER을 제공하지만, 같은 빔에서 훈련은 몇 주 걸림.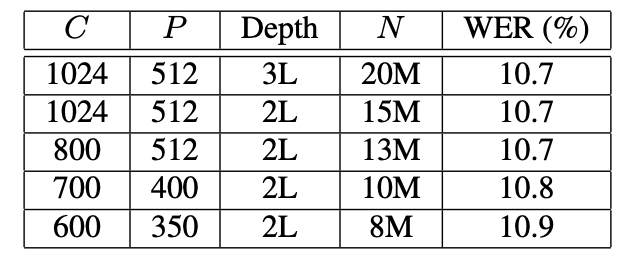
4. Conclusion
- Deep LSTM RNN 아키텍처의 우수성:
- 깊은 LSTM RNN 아키텍처가 대규모 음향 모델링 작업에서 최고 수준의 성능을 달성함을 보여줌.
- Deep LSTMP RNN 아키텍처의 향상된 성능:
- 제안된 깊은 LSTMP RNN 아키텍처가 표준 LSTM 네트워크 및 DNN보다 우수한 성능을 보임.
- 모델 파라미터를 더 효과적으로 사용하여 대규모 네트워크를 훈련하기 위한 계산 효율성에 대응함.
- ASGD 분산 훈련의 빠른 LSTM RNN 모델 학습:
- ASGD (Asynchronous Stochastic Gradient Descent) 분산 훈련을 사용하여 LSTM RNN 모델을 빠르게 훈련할 수 있음을 처음으로 보여줌.
