NLP
1.[논문리뷰] Long Short-Term Memory Recurrent Neural Network Architectures for Large Scale Acoustic Modeling
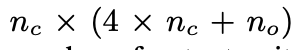
Abstract 1. LSTM은 RNN 계열의 모델중 하나로 기존 RNN보다 temporal sequences, long-range dependecies에서 성능을 개선했다. temporal sequences: 시간에 따라 변하는 데이터의 순서 ex) 음성신호,
2.[논문리뷰]Deep contextualized word representations(ELMo)
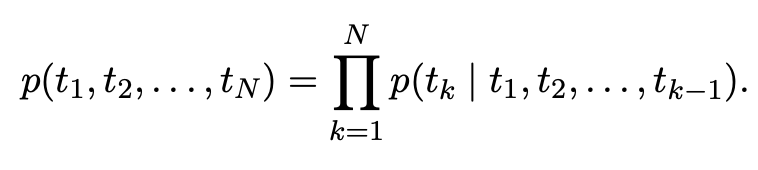
단어의 복잡한 특성언어학적인 문맥 상에서 다르게 사용될 때 각 문맥에서의 맞는 representation이 필요하다(Ex 다의어)전체 문장을 input으로 받아 word representations을 만든다bidrectional LSTM을 활용하여 language mo
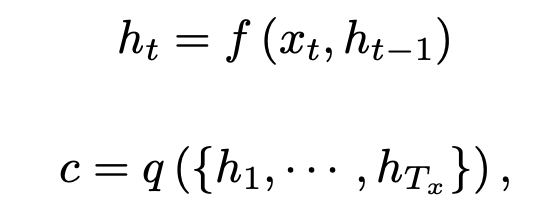
4.[논문리뷰] Language Models are Unsupervised Multitask Learners
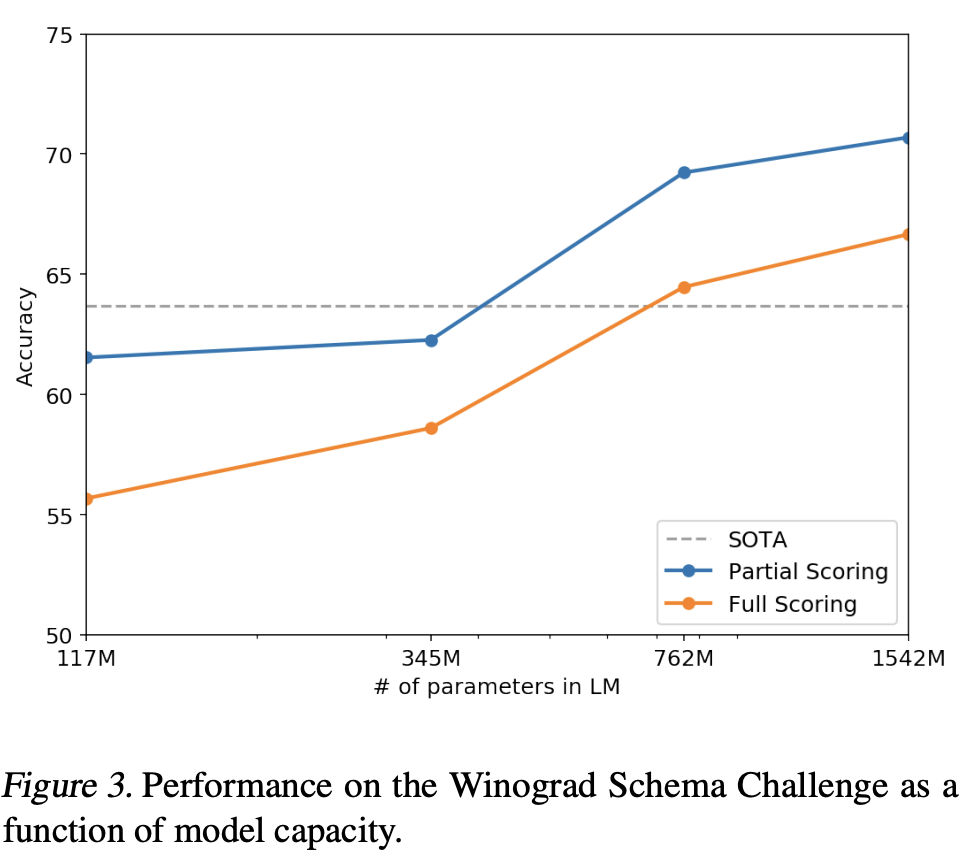
1. Introduction 각 task마다 라벨링하는 작업 수고 없이 많은 task에서 잘 수행하는 general 모델을 만들고자 함 2. Approach GPT-2의 핵심 접근법은 language modeling이다. language modeling은 입력 $$
5.[논문리뷰] ELECTRA: PRE-TRAINING TEXT ENCODERS AS DISCRIMINATORS RATHER THAN GENERATORS
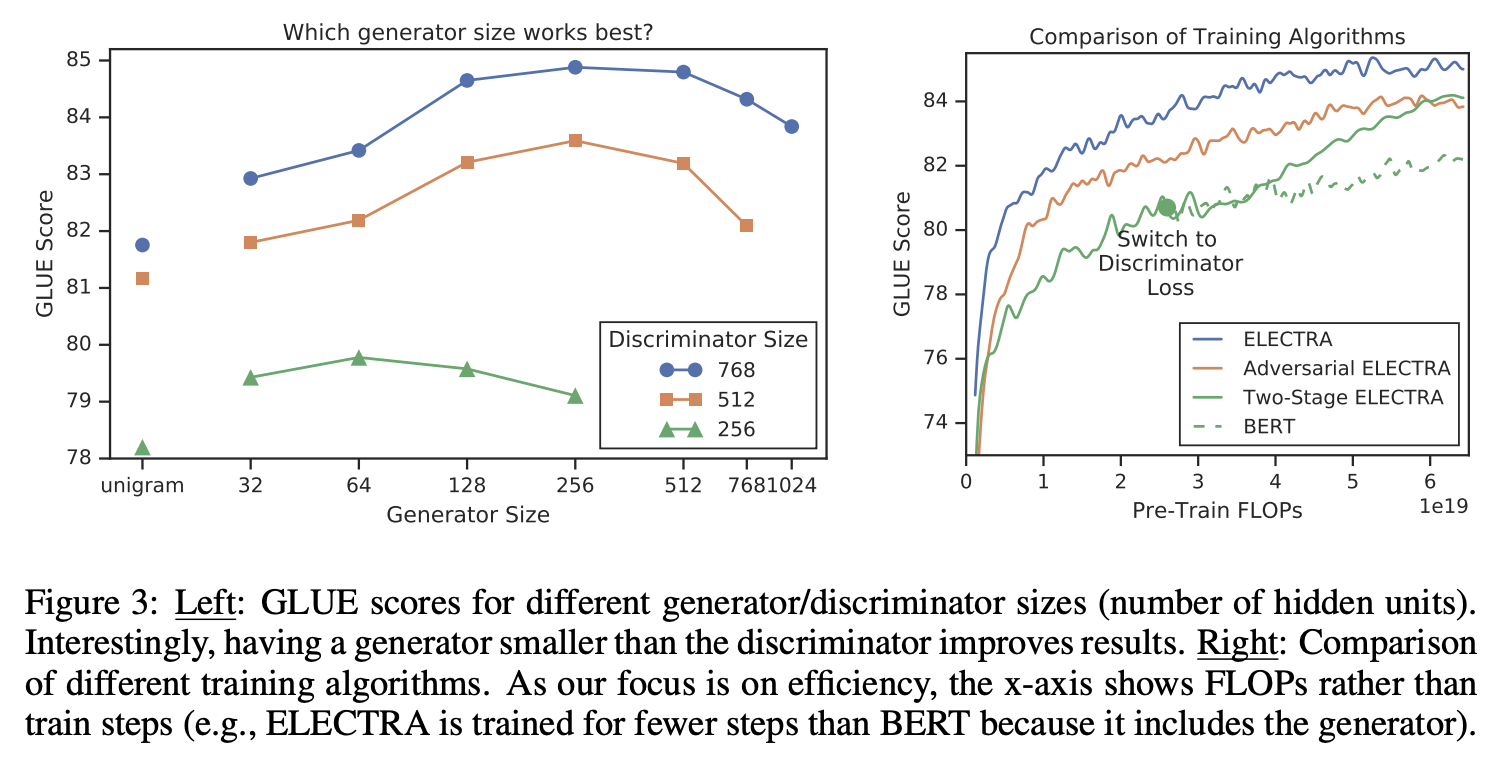
1. Introduction 당시 SOTA representation learning 방법은 일종의 denoising autoencoder 방법이다. 입력 시퀀스의 토큰중 대략 15%를 마스킹하여 복원하는 모델링을 MLM(masked language modeling)이
6.[논문리뷰]Efficient Estimation of Word Representations in Vector Space

1. Introduction 해당 연구 당시 많은 NLP연구가 단어를 atomic units으로 여겼다.(단어간 유사성 개념이 없음) 이런 방법은 복잡한 모델로 작은 양의 데이터를 학습시키는 것보다 간단한 모델로 많은 양의 데이터를 학습시키는 것이 성능이 더 좋다는 것