1. Introduction
해당 연구 당시 많은 NLP연구가 단어를 atomic units으로 여겼다.(단어간 유사성 개념이 없음)
이런 방법은 복잡한 모델로 작은 양의 데이터를 학습시키는 것보다 간단한 모델로 많은 양의 데이터를 학습시키는 것이 성능이 더 좋다는 것과, 간단하며, 일반화 성능이 좋다는 장점등이 있었다. 이러한 방법의 예시로는 대표적으로 N-gram 모델이 있다.
하지만 이러한 방법은 다양한 task에 한계가 존재한다. 예를들어 automatic speech recognition이나 machine translation의 경우 말뭉치나 전사된 음성에서의 단어의 수가 많지 않다.
따라서 단순 scaling up 하는 것이 큰 진전을 가져다주지 않는다. 해당 논문에서는 이런 문제에 따라 더 발전된 기술이 필요하다는 것에 초점을 맞춘다.
1.1 Goals of the Paper
해당 논문의 목표는 큰 데이터로부터 높은 퀄리티의 word vector를 배우는 기술을 도입하는 것이다.
저자들은 비슷한 단어들이 서로 가까이 있는지 뿐만 아니라 단어들이 가지고 있는 여러 정도의 유사성을 잘 표현하였는지에 대한 것을 측정한다.
예를들어 명사는 여러개의 어미를 가질 수 있다. 잘 표현된 vector space에서는 유사한 어미를 추출해낼 수 있다.
단순 구문적인 제약을 넘어서 벡터의 대수연산으로 단어를 표현할 수 있다.
과 같이 표현이 가능하다.
해당 논문에서는 이러한 벡터 연산의 정확도를 극대화하기 위해 단어간의 선형 규칙성을 보존하는 모델을 만들고자 한다.
구문 및 의미 규칙성을 모두 측정하기 위한 새로운 test set를 설계하고 이러한 많은 규칙성을 을 높은 정확도로 학습할 수 있음을 보여준다. 또한, 학습 시간과 정확도가 단어 벡터의 차원과 양에 따라 어떻게 달라지는지 단어 벡터의 차원과 학습 데이터의 양에 따라 어떻게 달라지는지 보여준다.
1.2 Previous Work
NNLM -> linear projection + hidden layer를 이용하여 word vector representation과 statistical language model을 배운다
→ 벡터 표현(projection 하는 과정에서의 weight 벡터), 앞 단어를 이용하여 다음 단어 원 핫 벡터 예측(statistical language model -> softmax)
2. Model Architectures
과거 연속적인 벡터를 표현하기 위해 많은 방법론들이 소개되었다. ex)LSA, LDA
해당 논문에서는 Neural Network를 통해 연속적인 벡터(단어간의 의미 차이를 고려할 수 있는)를 표현하는 것에 집중한다. 해당 방법은 기존의 방법론들보다 단어 사이의 선형성을 잘 보존할 수 있다고 저자들은 주장한다.
모델을 fully trained 시키기 위해 필요한 파라미터 수를 정의한 후 accuracy를 최대화하면서 computational complexity는 최소화 하는 방향으로 연구를 진행했다.
그 결과 모델의 training complexity는 아래와 같다.
: number of the training epochs
: number of the words in the training set
: defined further for each model architecture
일반적으로 는 10억개 이상이다.
모든 모델은 SGD를 통해 역전파가 된다.
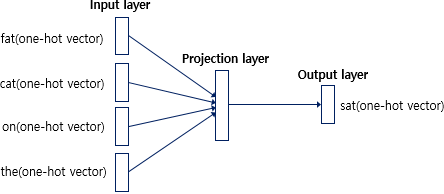
2.1 Feedforward Neural Net Language Model (NNLM)
확률적 순전파는 input, projection layer, hidden layer, ouput layer로 구성되어 있다.
input layer에서는 N개의 이전 단어가 1-of- 코드로 인코딩되어 표현된다. (는 Volcabulary의 크기) 그리고 input layer는 Projection layer(의 차원)로 projected 된다. 해당 Projection layer는 공유된다.
NNLM은 Projection layer -> hidden layer로 사이의 계산이 복잡하다는 단점이 있다. 인 경우에 Projection layer의 크기는 500~2000이 되며 hidden layer의 크기는 500~1000이 된다. 게다가 hidden layer -> output layer에서 Vocabulary안의 모든 단어에 대한 확률 값을 계산해야된다. 따라서 계산 복잡도는 아래와 같이 된다.
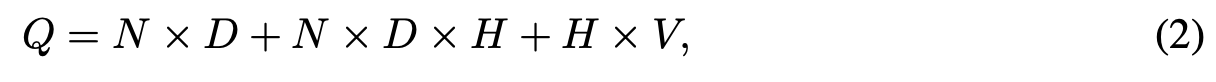
의 계산 복잡도를 피하기 위해 몇가지 방법을 사용하곤 한다. 계층적 softmax를 사용하거나 training동안 nomalized를 진행하지 않으면서 해당 계산 복잡도를 피하는 방법이 있다. 또한 binary tree를 이용하여 를 로그 스케일로 줄인다.
이렇게 되면 대부분의 계산 복잡도는 에서 발생한다.
해당 논문에서는 Huffman binary tree를 이용하여 계층적인 softmax를 사용한다. Huffman binary tree는 짧은 이진 코드로 단어의 빈도수를 표현 할 수 있고, Output layer의 수를 줄 일 수 있다. 그럼에도 불구하고 N x H x D의 복잡성은 해결되지 않는다. 따라서 저자들은 Hidden layer를 갖지 않은 모델은 모델을 제안한다.
2.2 Recurrent Neural Net Language Model (RNNLM)
RNNLM은 NNLM의 고정된 input 한계를 해결하고자 하였다. RNN은 이론적으로 얕은 neural network보다 복잡한 패턴을 표현할 수 있다. 그리고 RNN 모델은 Projection layer를 가지지 않는다.
RNNLM의 Training complexity는 아래와 같다.
2.3 Parallel Training of Neural Networks
대규모 데이터 세트에 대한 모델 훈련을 위해, 대규모 분산 프레임워크 위에 여러 모델을 구현했다.
피드포워드 NNLM과 이 백서에서 제안한 새로운 모델들을 포함한 모델을 포함하여 여러 모델을 구현했다. 해당 프레임워크를 사용하면 동일한 모델의 여러 복제본을 병렬로 실행할 수 있다.
3. New Log-linear Models
computational complexity를 최소화 하는 두 가지 방법을 소개한다. 위에서 살펴본 결과 computational complexity는 non-linear hidden layer에서 발생한다. 효율적인 훈련이 가능한 모델에 대한 연구가 필요.
3.1 Continuous Bag-of-Words Model
첫번째로 제안한 Model archietecture는 hidden layer를 삭제하고 projection layer의 가중치를 모든 단어에 대해 공유한다. 그리고 4개의 이전 단어와 4개의 이후의 단어들을 projection layer에 project 시키고 projected된 벡터들을 평균하여 ouput layer에 전달한다. 계산 복잡도는 아래와 같다.
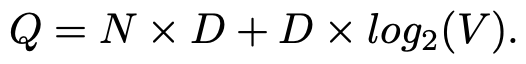
3.2 Continuous Skip-gram Model
또 다른 architecture는 현재 단어를 가지고 같은 sentence에 있는 다른 단어를 예측한다. 현재 단어기준으로 특정 범위 내에 있는 다른 단어를 예측하는 방향으로 학습이 진행된다. 먼 단어일 수록 현재 단어와의 연관성이 줄어들기 때문에 범위를 늘릴수록 word vector의 퀄리티는 증가하지만 계산 복잡도가 커진다. 작은 weight를 거리에 따라 조절하여 학습한다.
Skip-gram의 계산 복잡도는 아래와 같다.
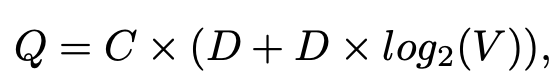
C는 단어간 거리의 최댓값이다. 해당 논문에서는 5로 설정.
두 모델 구조 차이
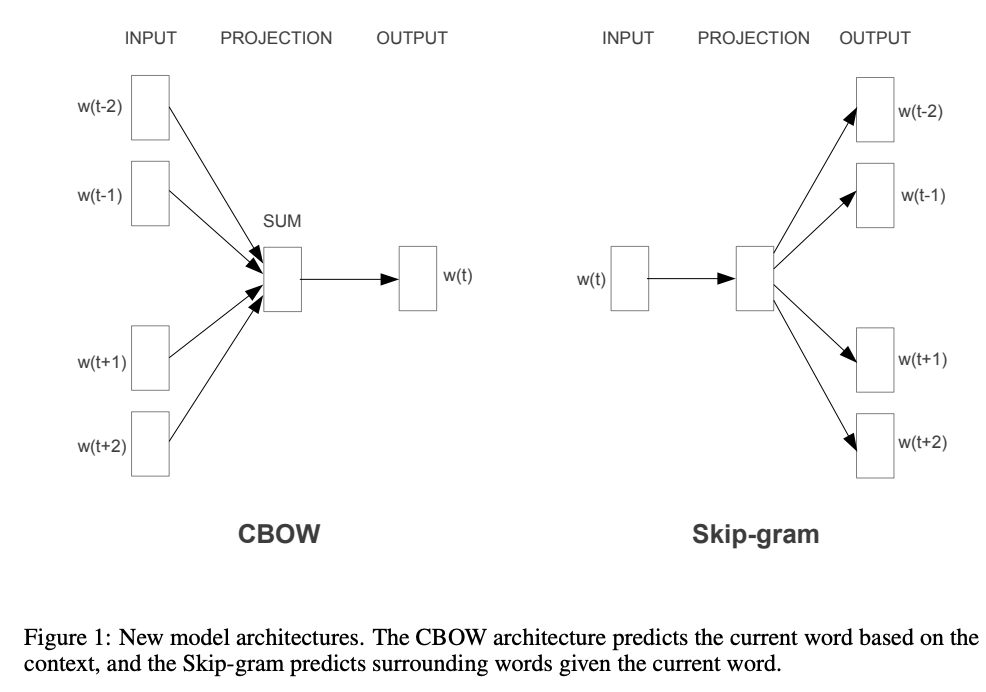
4. Results
이전 연구들에서는 word vector의 quality를 비교할 때 직관적으로 이해가 되는 가장 비슷한 단어를 테이블로 보여줬다.
이런 방식은 Italy와 France가 유사하다는 것을 보여주는 것은 어렵지 않지만 다른 나라들과도 유사하다는 것을 보여주는 것은 또 다른 문제이다.
즉 단어 사이에는 더 많은 유사성을 가지고 있다는 것을 알고 있다. 예를들어 big은 small-smaller와 같이 bigger과 비슷하다.
이러한 것들을 해당 논문에서는 간단한 벡터 연산으로 계산할 수 있다.
4.1 Task Description
word vector의 quality를 측정하기 위하여, 5개의 type의 의미적인 질의로 구성된 comprehensive test를 정의하였다. 두개의 type에 대한 예시는 아래 테이블에서 확인 할 수 있다. 8869개의 의미적인 질의와 10675개의 문법적인 질의로 이루어져있다.
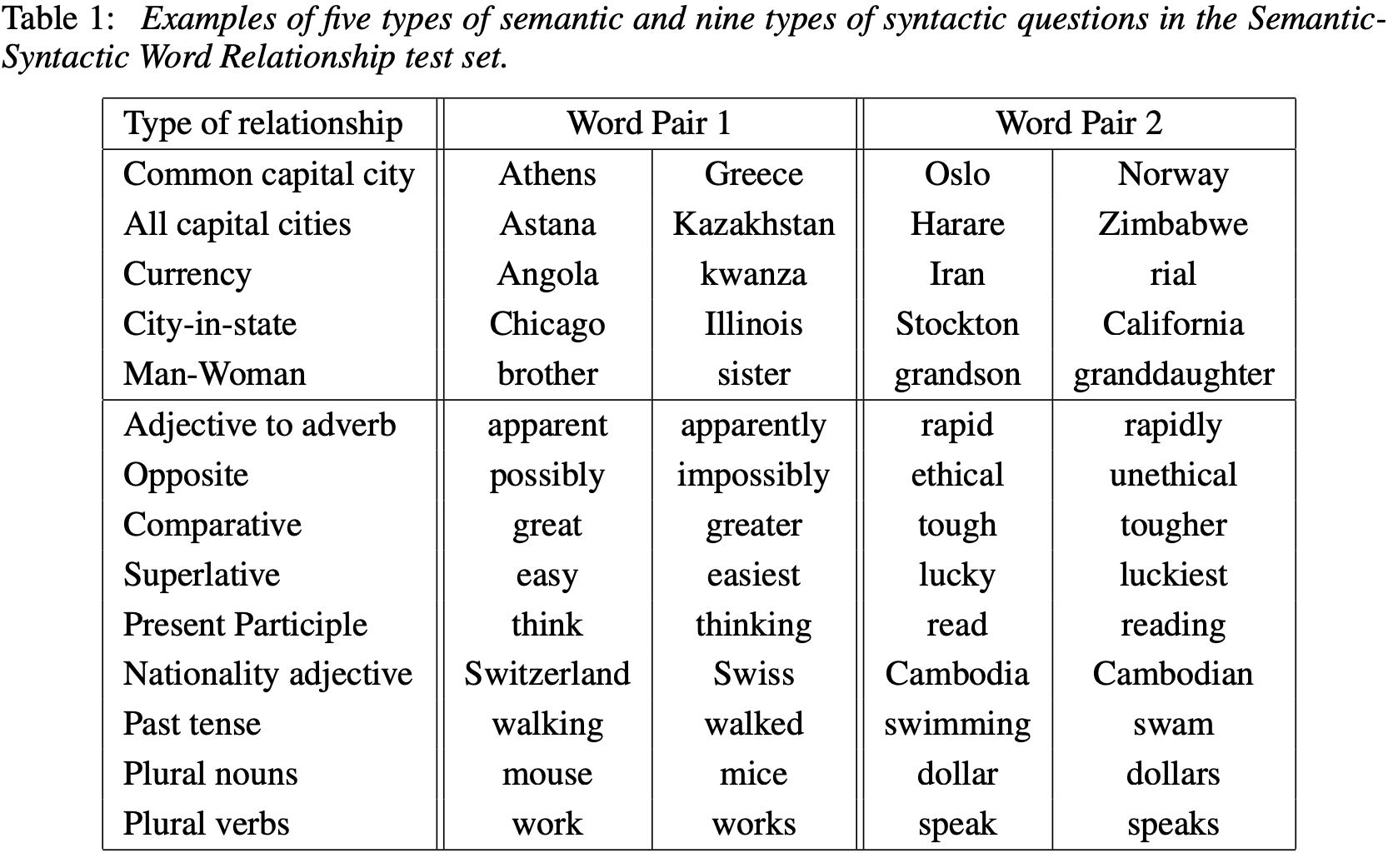
각 카테고리의 질문은 두 단계에 걸쳐 생성됐다. 먼저 유사한 단어 쌍의 목록을 수동으로 생성한다. 그런 다음 두 단어 쌍을 연결하여 큰 질문 목록을 만들었다. 예를 들어, 미국의 68개 대도시와 그 도시가 속한 주의 목록을 만들고, 무작위로 두 단어 쌍을 선택했다. 테스트 세트에는 단일 토큰 단어만 포함시켰기 때문에 여러 단어로 구성된 엔티티(예: 뉴욕)는 포함되지 않았다.
모든 문제 유형에 대해 전반적인 정확도를 평가하고 각 문제 유형에 대해 개별적으로(의미론적, 구문론적) 평가한다. 위의 방법으로 계산된 벡터에 가장 가까운 단어가 문제(코사인 유사도)의 정답 단어와 정확히 일치하는 경우에만 정답으로 간주되므로 동의어는 틀린 것으로 계산된다.
4.2 Maximization of Accuracy
word vector를 학습하기 위해 Google 뉴스 말뭉치를 사용했다. 이 말뭉치에는 약 6억 개의 토큰. 어휘의 크기는 가장 빈번한 단어 100만 개로 제한했다. 더 높은 차원의 word vector를 사용하면 정확도가 향상될 것으로 예상한다.
좋은 모델 아키텍처를 찾기 위해 먼저 training set의 sub set에 대해 학습을 진행했다. sub set은 가장 빈번한 30만개의 단어로 모델을 평가했다. word vector 차원을 다르게 선택하고 훈련 데이터의 양을 늘린 CBOW 아키텍처를 사용한 결과는 아래 표와 같다.
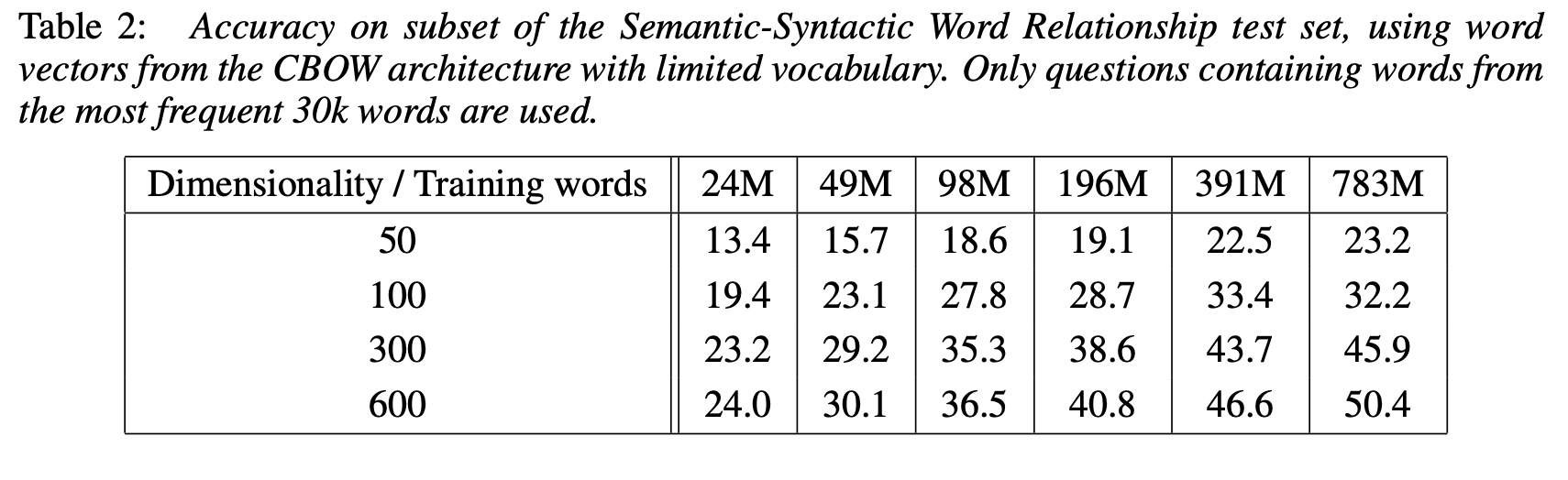
어느 시점이 지나면 단순히 차원만을 늘리거나 학습데이터만을 늘리는 것은 개선 효과가 줄어든다는 것을 볼 수 있다. 따라서 벡터 차원과 학습 데이터의 양을 모두 늘려야 한다. 여기서 주목해야 할 점은 현재 비교적 많은 양의 데이터로 단어 벡터를 훈련하는 것이 널리 사용되고 있지만, 그 크기가 충분하지 않을 수도 있다는 것을 말한다.
Table2와 Table4에 보고된 실험에서는 SGD 및 역전파를 사용한 세 가지 훈련 epoch를 사용했다. 시작 학습률은 0.025를 선택하고 선형적으로 감소시켜 마지막 훈련 시점이 끝날 때 0에 가까워지도록 하였다.
4.3 Comparison of Model Architectures
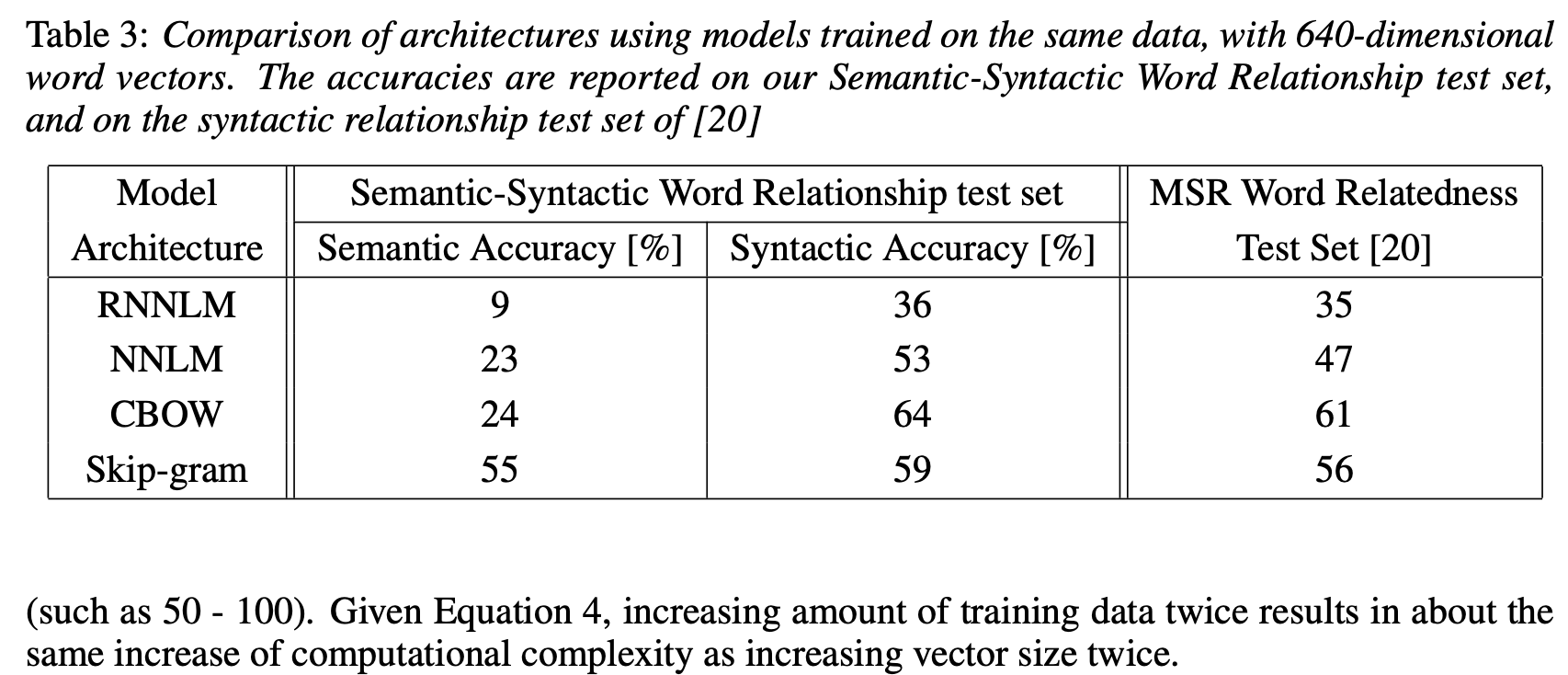
아래 사진은 1개의 CPU로 실험
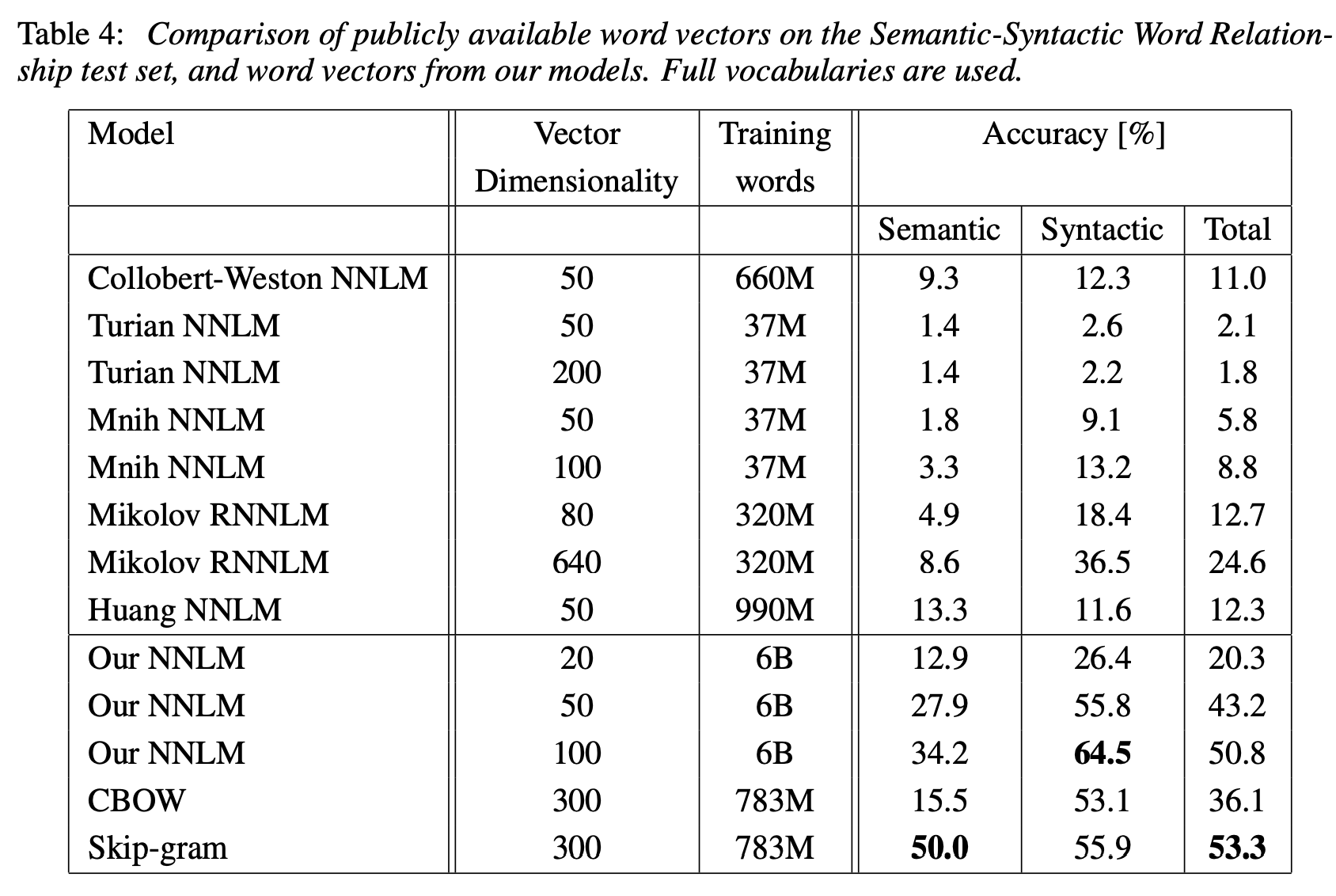

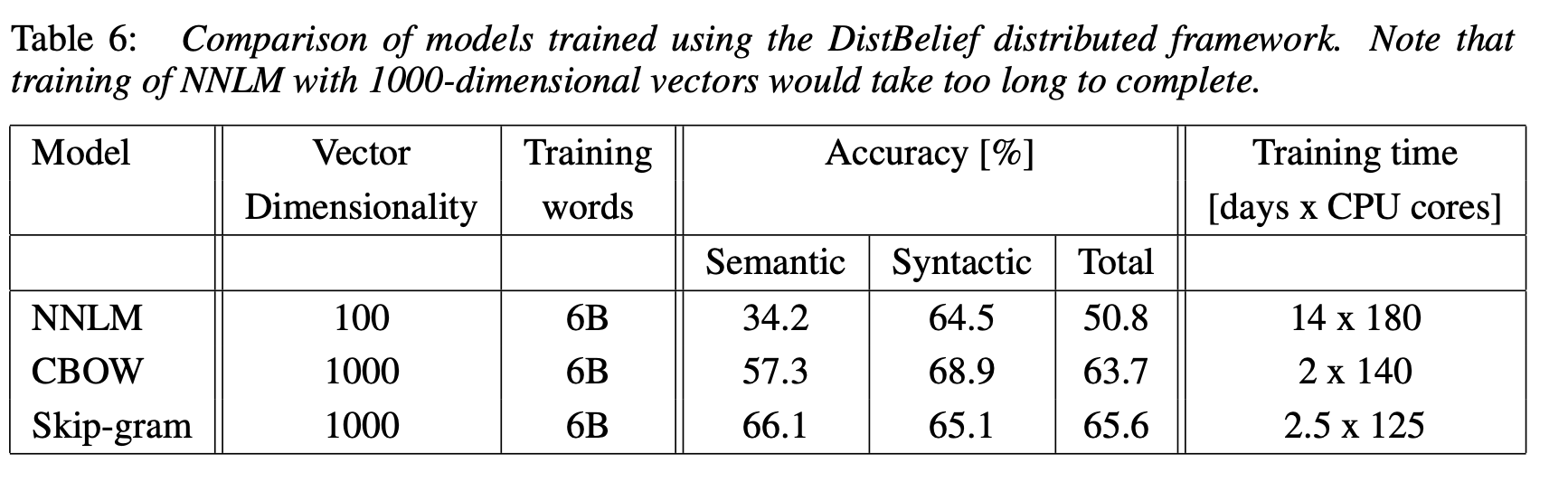
4.4 Large Scale Parallel Training of Models
분산연산 framework를 사용하여 학습
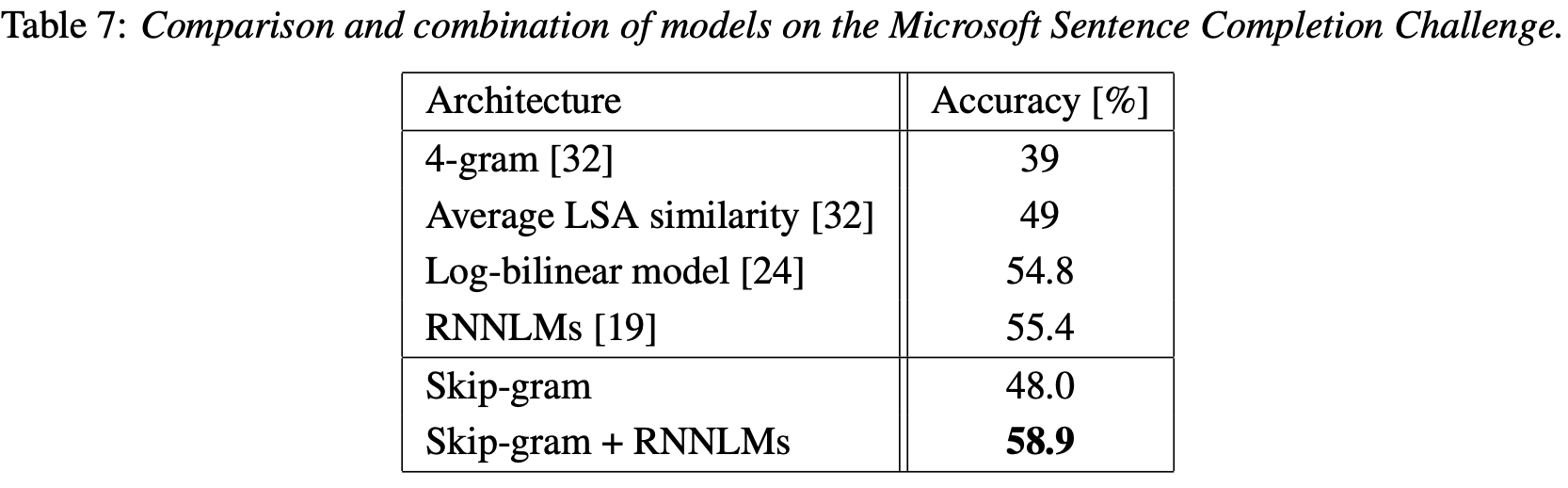
4.5 Microsoft Research Sentence Completion Challenge
Microsoft Sentence Completion Challenge는 최근에 소개된 advancing LM과 다른 NLP 기술에 대한 task이다. 해당 task는 1040개의 문장으로 구성되어 있으며 문장은 하나의 단어가 빠져있고 목표는 가장 일관성있는 단어를 선택하는 것이다.
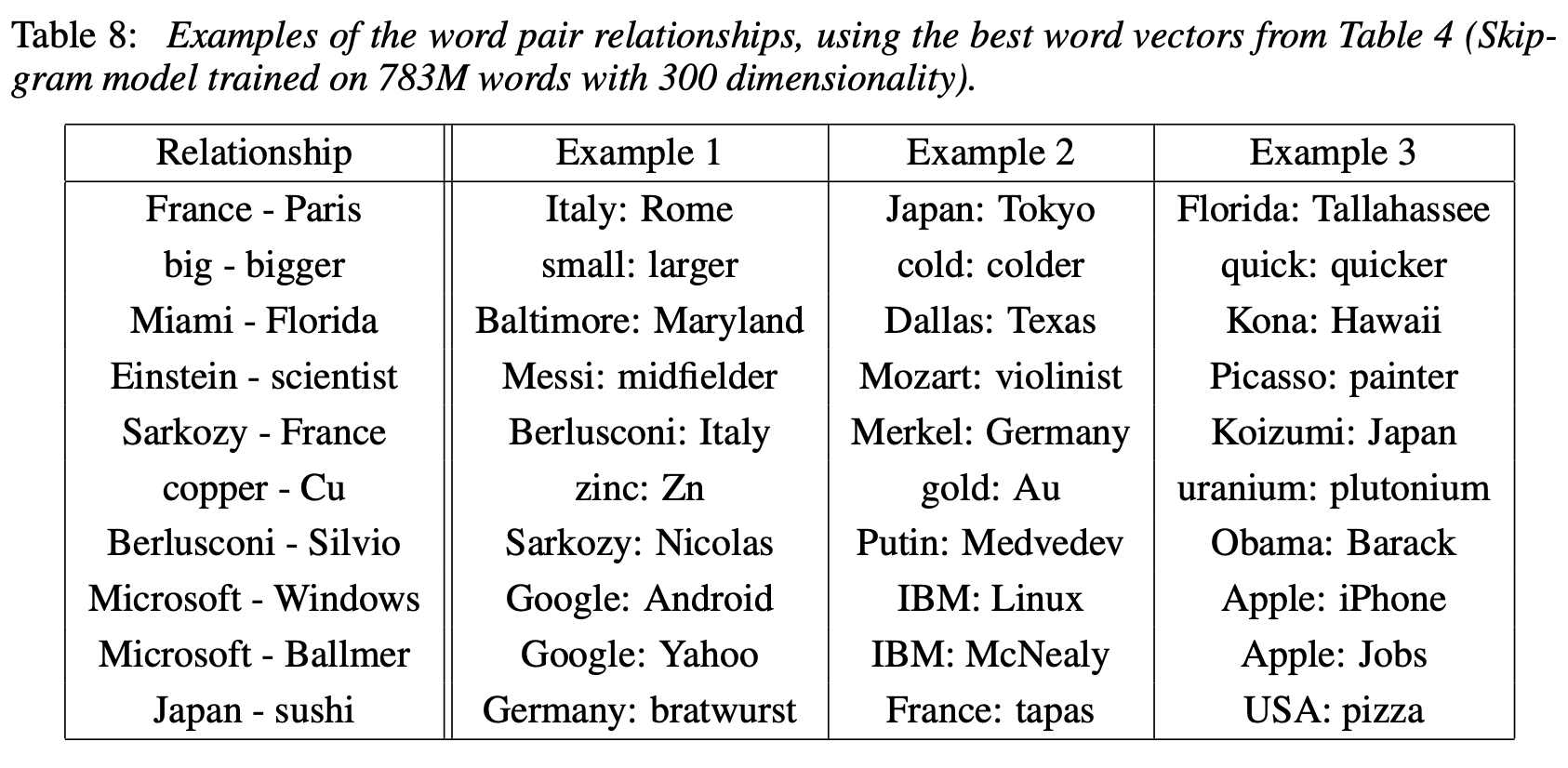
5. Examples of the Learned Relationships
6.Conclusion
초초 간단한 architecture를 이용하여 word vector를 학습시킴
-> 여러 유사성을 간단하게 판단 가능
