1. Introduction
당시 SOTA representation learning 방법은 일종의 denoising autoencoder 방법이다. 입력 시퀀스의 토큰중 대략 15%를 마스킹하여 복원하는 모델링을 MLM(masked language modeling)이라고 한다. MLM은 양방향으로 representations을 학습하기 때문에 기존 language-model보다 효과적이긴 하지만 sequence 하나당 15%의 token만 학습하기 때문에 학습 비용이 많이 든다.
따라서 해당 논문에서는 대체된 token을 찾는 방법(RTD)을 제시한다. 해당 방법은 주어진 sequnece의 일부 token을 다른 token으로 대체하여 대체된 token이 real input tokens인지 replaced tokens인지 판별하도록 학습한다. replaced token은 Generator를 통해 plausible 하게 생성된다. 그리고 replaced token이 진짜인지 아닌지를 Discriminator가 판별한다.
이런 discriminative한 task의 이점은 모델이 모든 input tokens으로 부터 학습함으로써 computationally efficient하게 만든다.
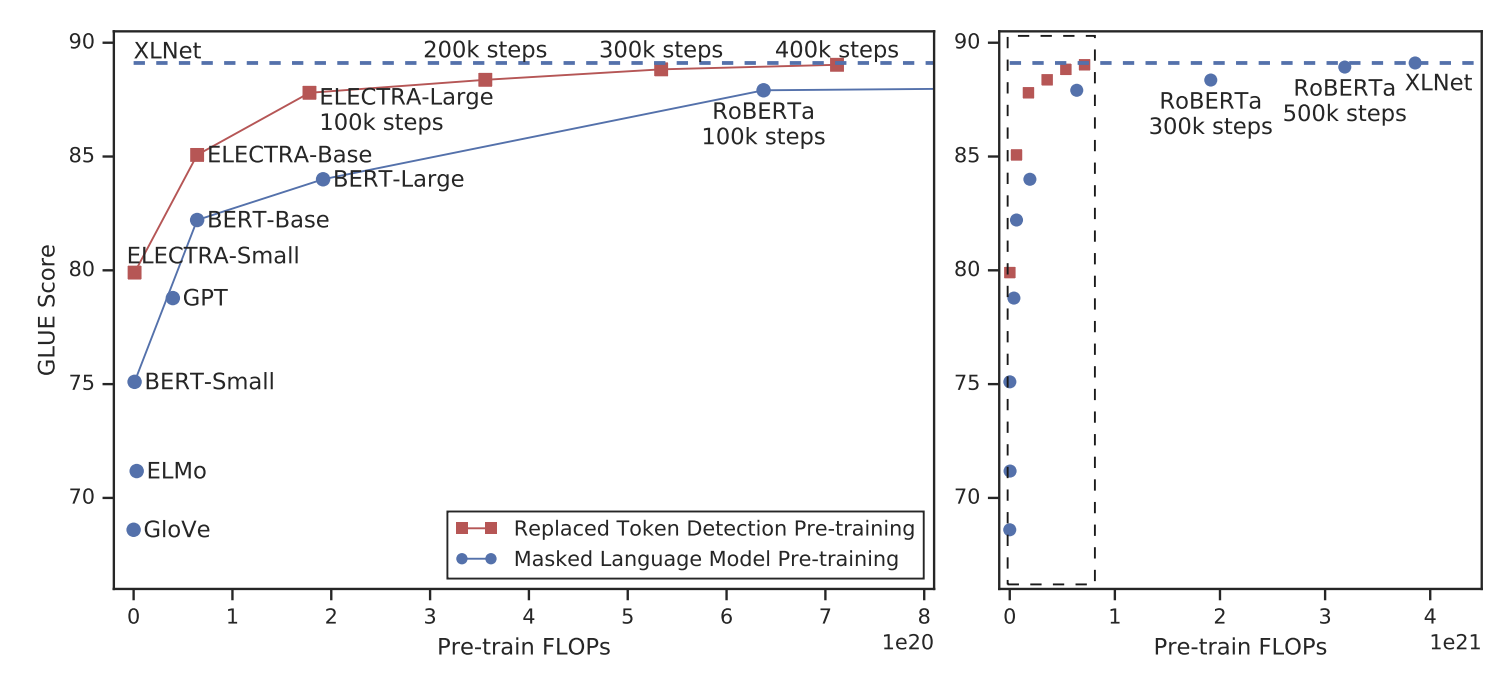
RTD 방식은 BERT보다 학습 속도가 빨랐고 downstream task에 대해 더 높은 정확도를 달성했다.
BERT,XLNet과 같은 MLM-based 방법들과 같은 model size를 가졌을 때 MLM 방법들의 성능을 능가했다.
그 예시로 ELECTRA-Smalldms 1개의 GPU로 4일동안 학습하여 small BERT의 성능을 능가했다.
또한 ELECTRA-Large는 RoBERTa나 XLNet보다 적은 파라미터, 1/4의 계산량으로 비슷한 성능을 보이고, ALBERT를 능가하였다.
즉, ELECTRA는 기존의 language representation learning 기법들보다 compute-efficient하고 paramter-efficient하다.
아래는 위에서 말한 성능 비교 Figure이다.
2. Method
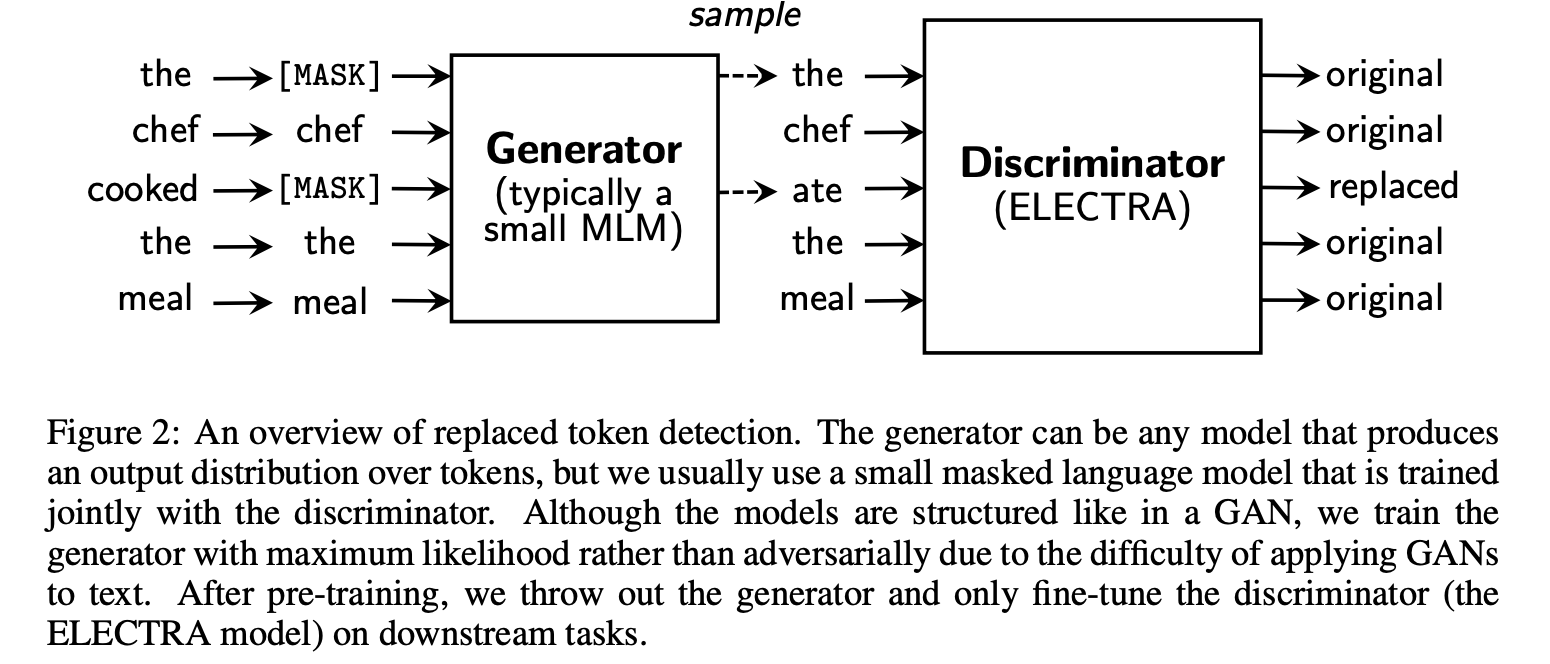
해당 논문에서는 generator G와 discriminator D두 개의 networks를 학습시킨다. G와 D는 모두 Transformer encoder로 구성되어있다.
generator G는 기존 MLM과 똑같이 학습된다.
input 이 주어지면 input에서 랜덤으로 마스크할 부분을 뽑아 [MASK] token으로 대체한다. [MASK] token으로 대체한 것을 로 표기한다.
generator는 masked된 token의 실제 input을 예측하도록 token을 생성한다. 이렇게 생성된 token을 로 표기하고 discirminator의 input으로 들어간다.
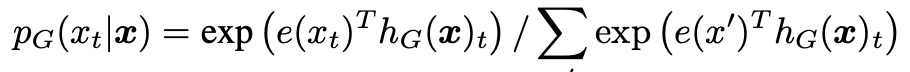
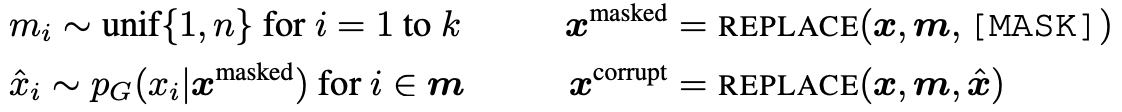
discriminator D는 generator가 생성한 token sequence에 대해 각 토큰이 original인지 replaced인지 이진분류를 진행한다.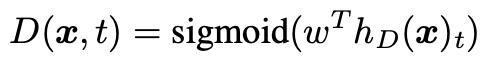
Loss function
MLM(generator) loss와 discriminator loss의 합이 최소화되도록 학습시킨다. G의 샘플링 과정이 있어 D의 loss는 G로 역전파되지 않는다.
이렇게 pre-training을 시킨 후 fine-tuning에서는 G는 버리고 D만 fine-tuning한다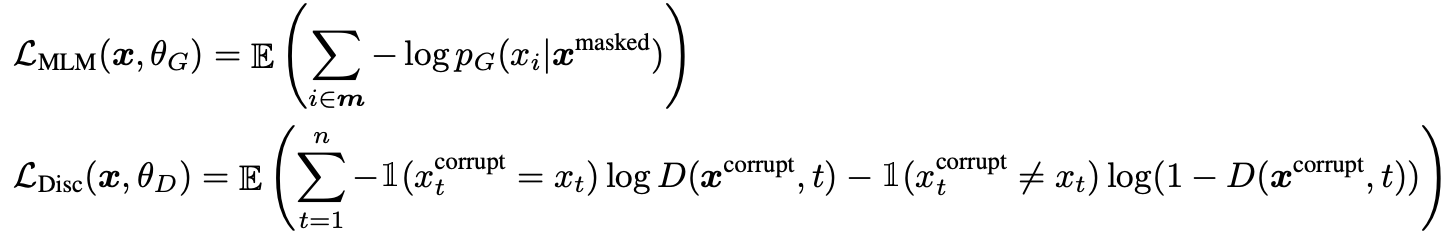
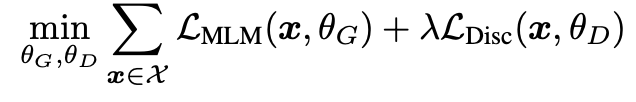
D만 fine-tuning하는 이유는 MLM은 기존 MLM과 같이 다양한 representation이 학습되어있는 상태이다. 하지만 D는 단순 text가 진짜인지 가짜인지만을 판별하는 것으로 학습되어서 특정 task를 수행하기 위해서는 fine-tuning을 진행한다.
참고링크
3. Experiments
3.1 EXPERIMENTAL SETUP
General Language Understanding Evaluation (GLUE) 벤치마크와 Stanford Question Answering (SQuAD) 데이터셋에서 모델을 평가한다.
대부분의 실험에서는 BERT와 동일한 데이터를 pre-training한다. BERT의 데이터는 Wikipedia 및 BooksCorpus에서 33억 토큰으로 구성되지만 해당 논문의 경우, XLNet을 위한 데이터로 pre-training을 수행한다. 이 데이터는 BERT 데이터에 ClueWeb, CommonCrawl 및 Gigaword 데이터를 포함하여 330억 토큰을 확장한 것이다.
모든 사전 훈련 및 평가는 영어 데이터에서 수행하며 모델 아키텍처 및 대부분의 하이퍼파라미터는 BERT와 동일하다.
GLUE에서 미세 조정을 위해 ELECTRA 위에 간단한 선형 분류기를 추가한다.
SQuAD의 경우, ELECTRA 위에 XLNet의 질문-답변 모듈을 추가한다.
3.2 MODEL EXTENSIONS
Weight Sharing
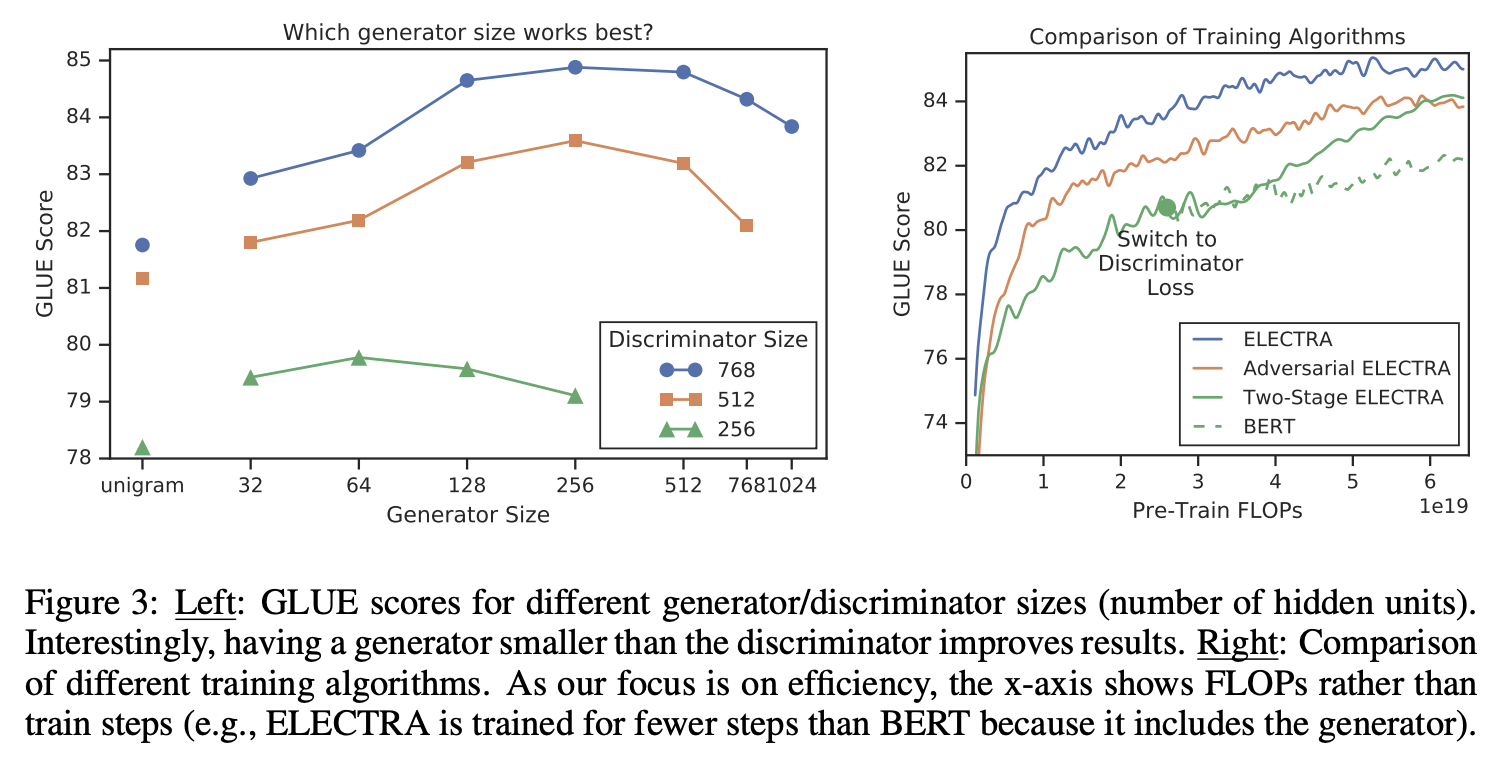
pre-training 효율성을 높이기 위해 generator와 discirminator의 weight를 공유한다. 만약 generator와 discriminator의 모델 size가 같으면 모든 weight를 공유할 수 있지만 실험에서 generator의 size가 discriminator의 size보다 작을 때 efficient 하다는 것을 발견하였기 때문에 임베딩 weight만 공유한다.(token and position embedding)
아래는 D의 크기에 따른 G별 성능이다
Smaller Generators
만약 generator와 discriminatord의 크기가 동일하다면 기존 MLM보다 두 배의 계산이 들어간다. 따라서 저자는 smaller generator를 사용하여 계산량을 줄이고자 하였다. smaller generator는 layer size는 줄이면서 hyperparameter는 일정하게 유지하였다. 실험 결과 discriminator 크기의 1/4-1/2일 때 가장 좋은 성능을 보였다.
저자가 말하는 이유는 generator의 size가 커지면 discriminator의 판별 문제가 훨씬 더 challenging 해져서 그렇다고 한다.
-> discriminator가 실제 데이터의 분포를 모델링 하는 것보다 generator를 모델링하는데 더 많은 파라미터가 쓰인다고 한다
Training Algorithms
- generator만 n steps 학습 시킨다
- 학습된 generator의 가중치로 discriminator의 가중치를 초기화하고, generator의 가중치는 고정한 후, discriminator만 n steps 학습 시킨다
3.3 SMALL MODELS
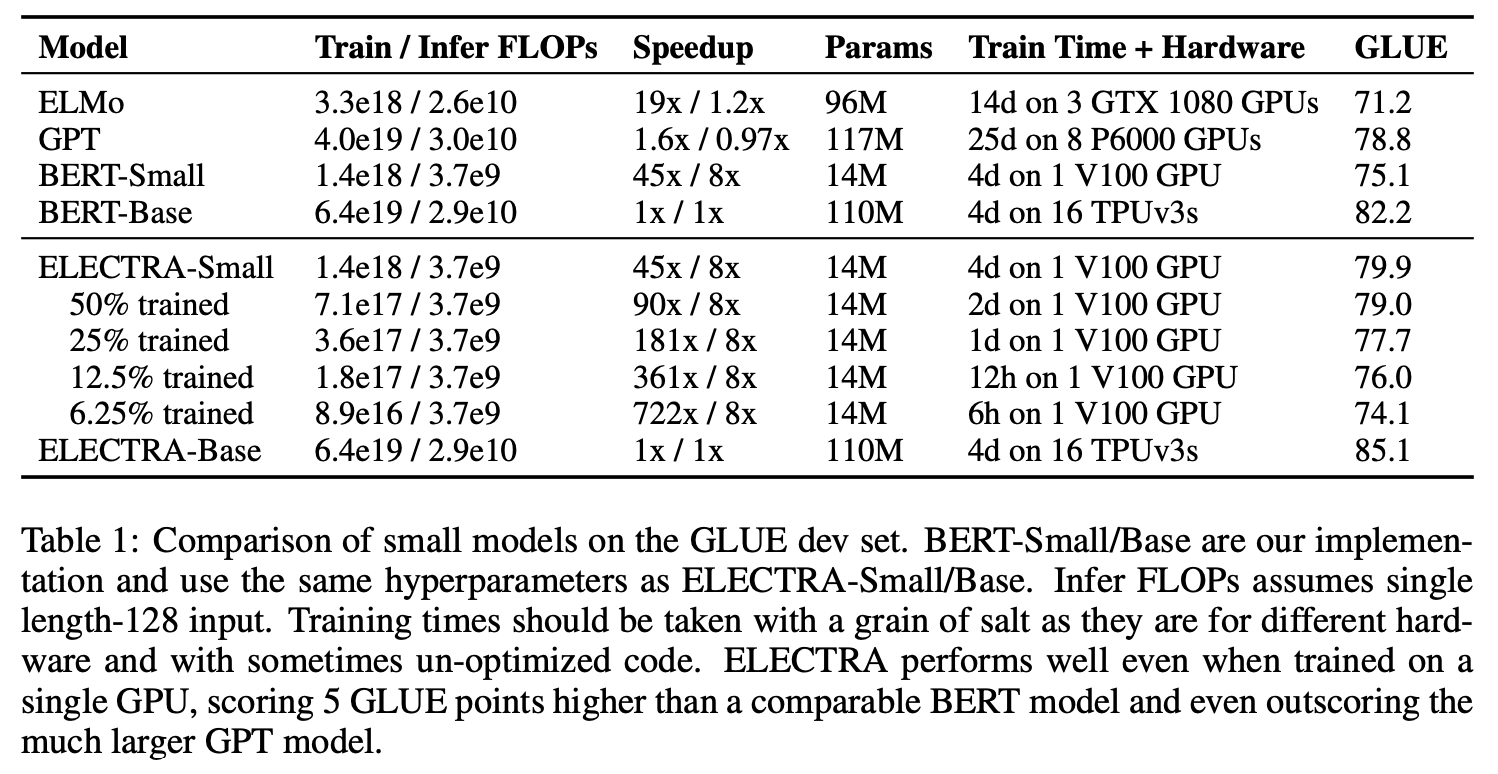 pre-training 효율성을 높이기 위해 gpu 1대에서도 돌아갈 수 있는 small model을 개발했다.
pre-training 효율성을 높이기 위해 gpu 1대에서도 돌아갈 수 있는 small model을 개발했다.
BERT-Base의 하이퍼파라미터를 사용하되, 시퀀스 길이를 512 토큰에서 128 토큰으로, 배치 사이즈를 256에서 128로, 은닉층의 차원을 768에서 256으로, 임베딩 차원을 768에서 128로 줄여서 실험했다.
그럼에도 불구하고 Table 1에서 볼 수 있듯, 높은 수준의 GLUE를 달성했다.
3.4 LARGE MODELS
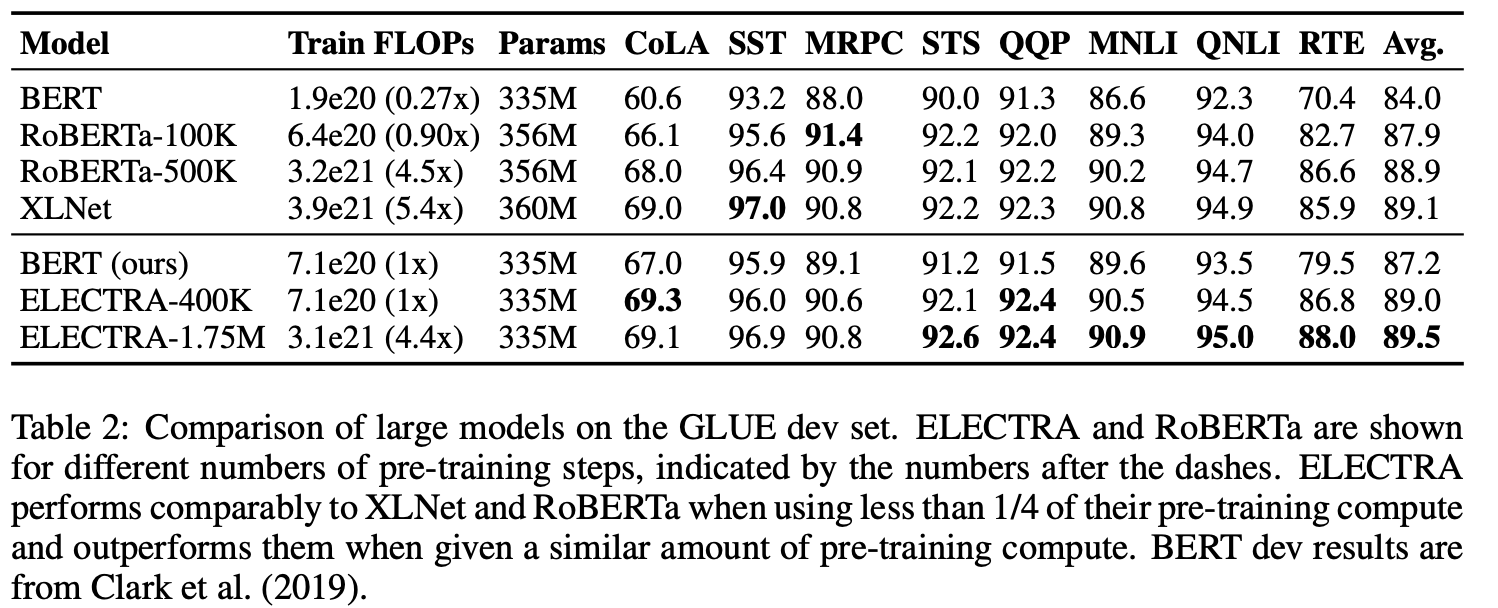
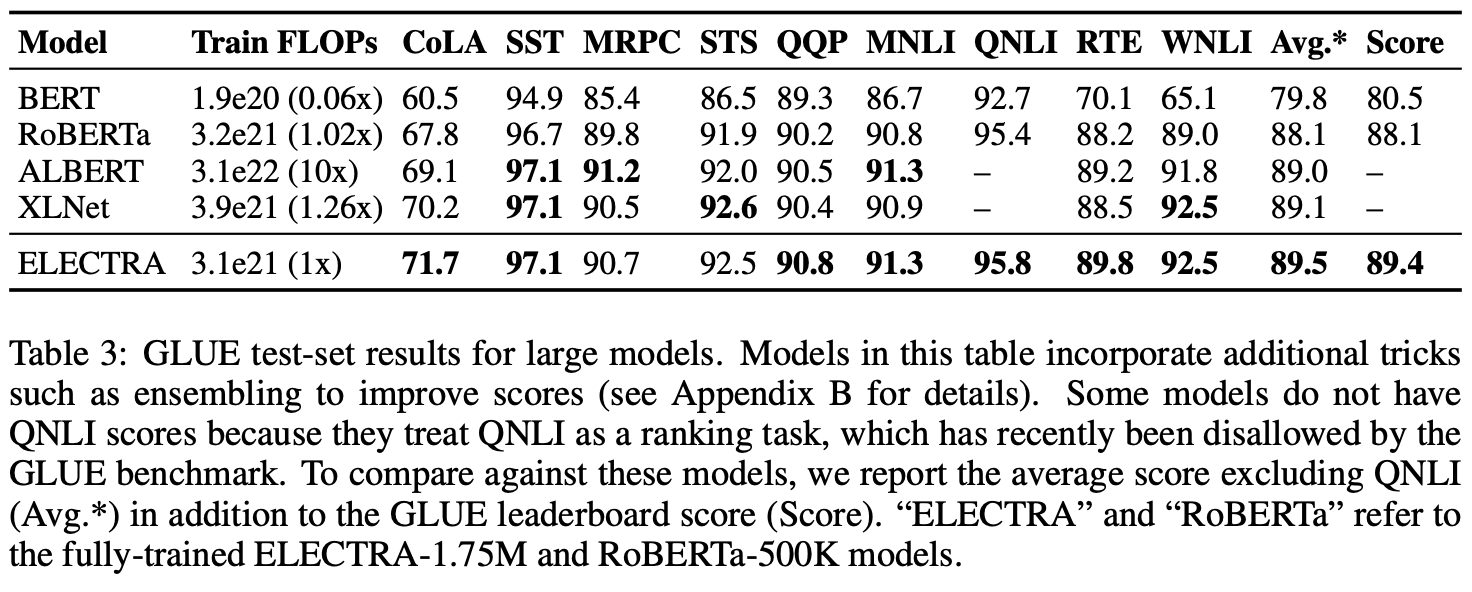
BERT-LARGE에 준하는 ELECTRA-LARGE 모델을 개발하여 실험하였다.
ELECTRA-400K:RoBERTa 사전학습의 대략 1/4 연산
ELECTRA-1.75M: RoBERTa 사전학습의 연산과 비슷한 수준
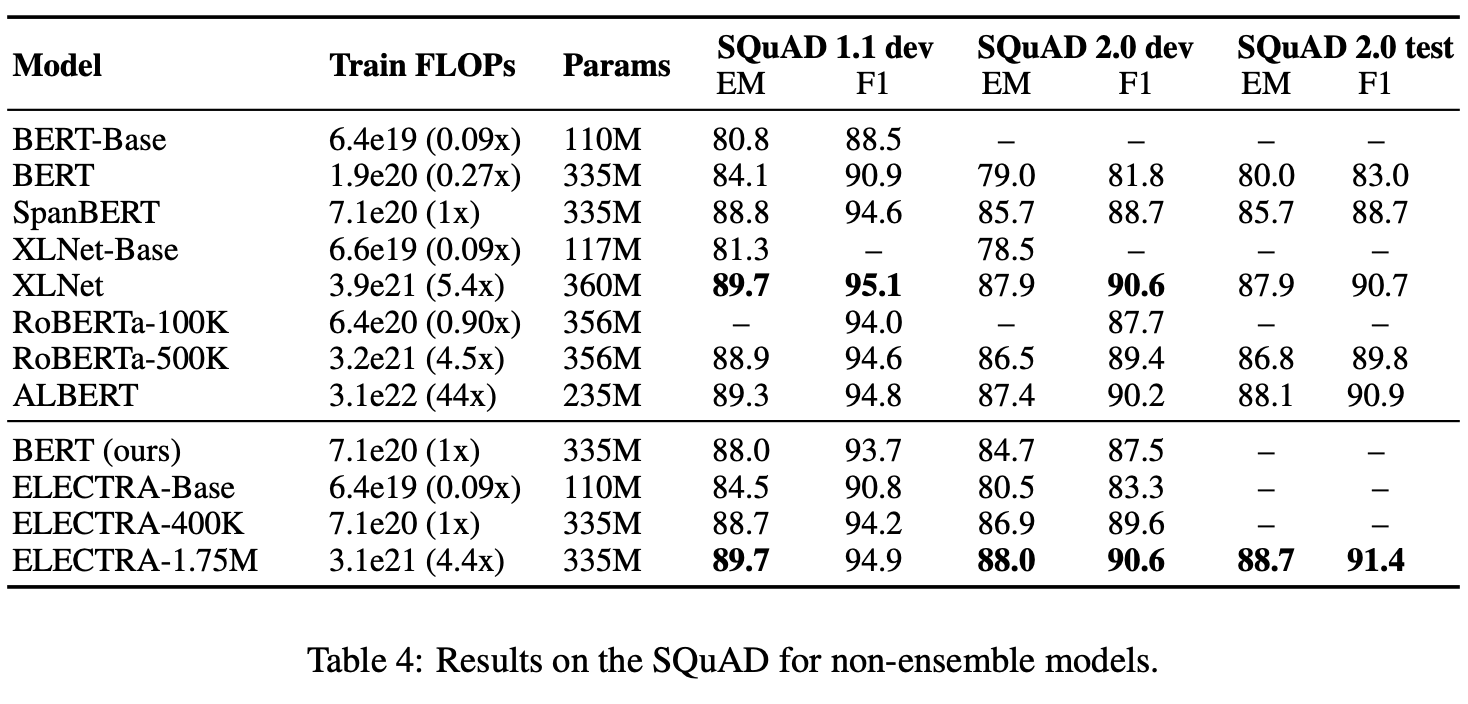
3.5 EFFICIENCY ANALYSIS
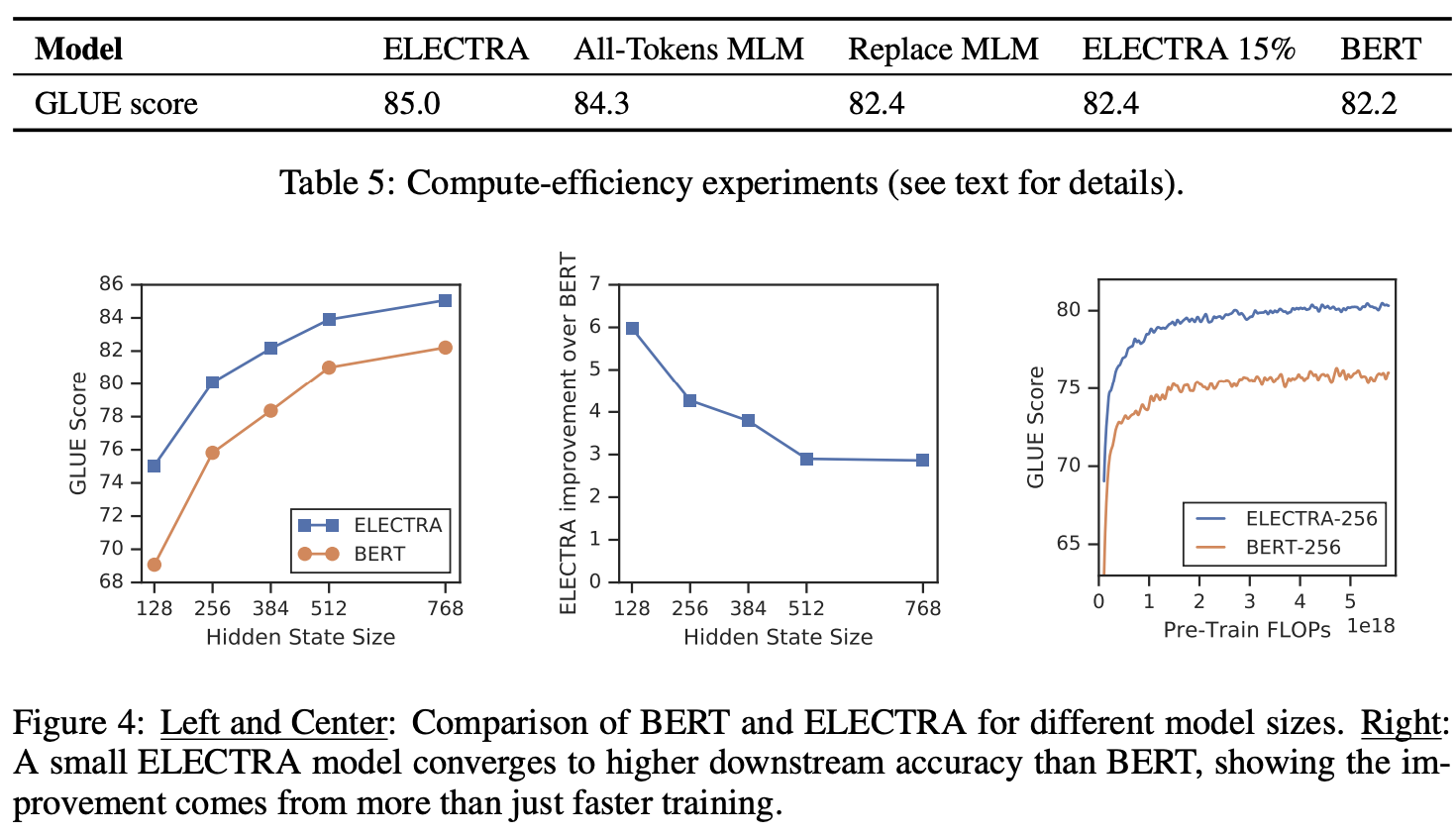
-
ELECTRA 15% : discriminator loss 를 전체 token 이 아니라 masking된 15%에만 계산
-
Replace MLM : 마스킹 할 token을 [MASK] token으로 replace함
-
All-Token MLM : 위에서 masking된 token을 predict, discriminator에선 mask에 대해서만 예측이 아닌 모든 token 에 대해 예측
5. CONCLUSION
언어 표현 학습을 위한 새로운 자기 지도 학습 작업인 RTD를 제안했다.
핵심 아이디어는 text encoder를 훈련하여 small generator에 의해 생성된 고품질 부정적 샘플과 입력 토큰을 구별하도록 하는 것입니다.
MLM과 비교하여, 해당 논문에서 RTD pre-trainig는 더 많은 계산 효율성을 가지며 downstream task에서 더 나은 성능을 보여준다. 비교적 작은 계산량을 사용해도 잘 작동하므로,
-> 더 적은 리소스로 적용하고 개발할 수 있다.
