오늘은 Indexer Cluster 에서 등장했던 중요한 개념 중 하나인 Bucket 개념에 대해 조금 더 상세하게 알아보려고 한다. 아래의 나온 그림은 이 문서에서 가져왔으며, 내용의 대부분은 공식 문서를 참고하였다.
1. Bucket 이란?
Splunk 에서 데이터가 저장된 공간을 생각하면 흔히 우리가 검색할 때에 사용하는 index="인덱스 명"을 떠올리게 된다. 이때의 인덱스는 데이터를 논리적으로 그룹한 단위이다. 아래의 그림에서 3번째 구간에 있는 부분이라고 볼 수 있다.
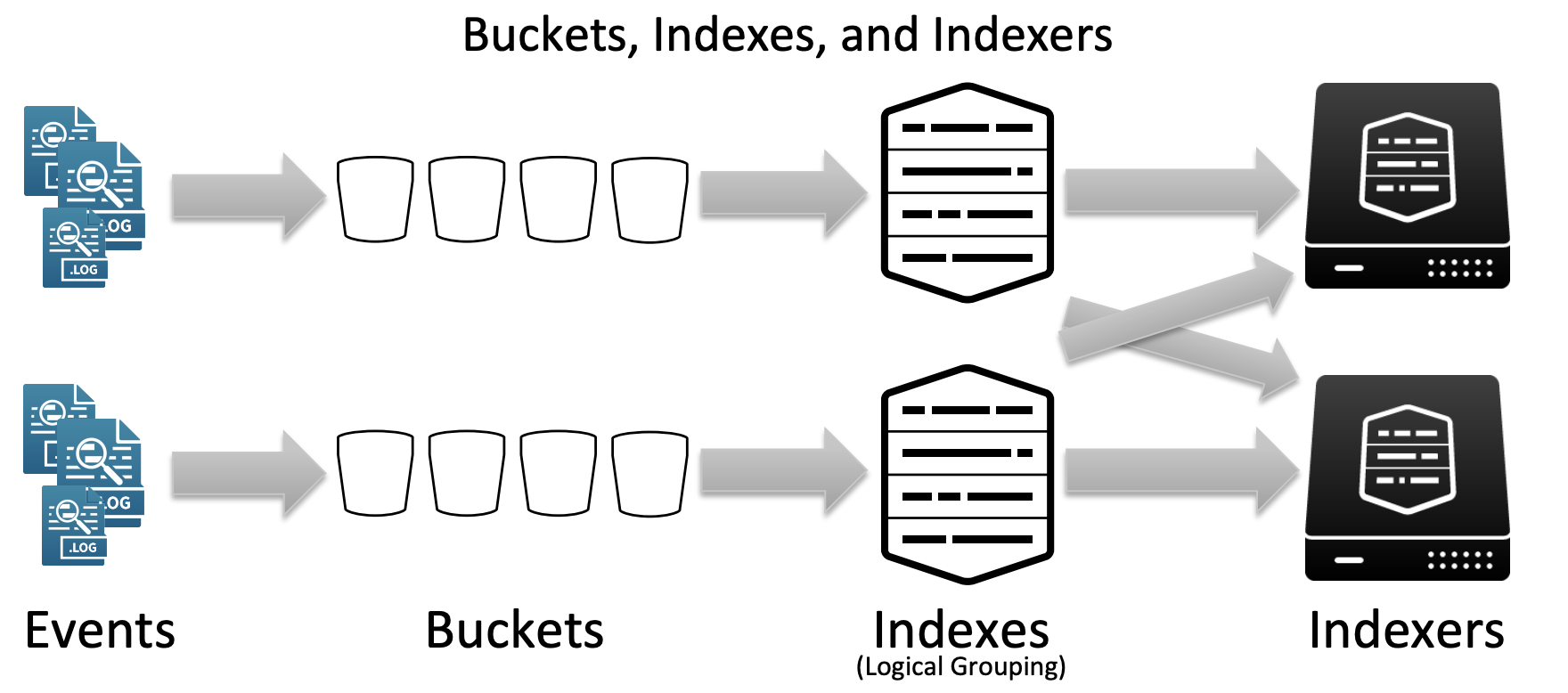
이렇게 우리가 보는 인덱스는 여러개의 이벤트가 만나 버킷이 되고, 여러개의 버킷들이 만나 하나의 논리적인 인덱스 그룹이 된다. 이후에 인덱스가 피어노드 서버에 저장이 되는 형태이다.
따라서 우리가 index=fw라고 하여, fw라는 방화벽 데이터를 수집한다면 방화벽에 로그로 찍히는 한줄 한줄이 모여 하나의 버킷을 이루고, 여러개의 버킷이 만나 fw라는 인덱스로 저장이 된다.
1. Bucket을 이루고 있는 3가지 요소
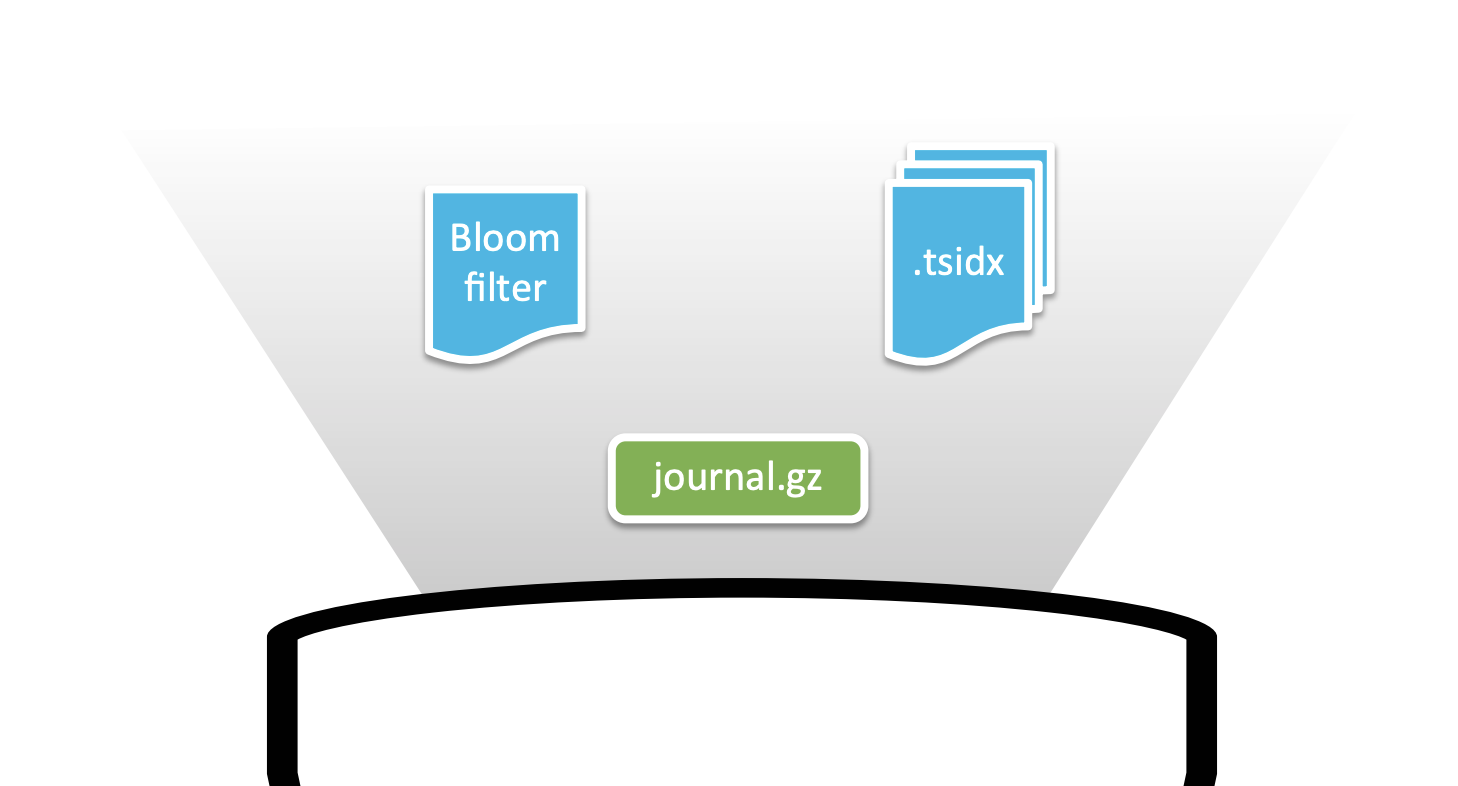
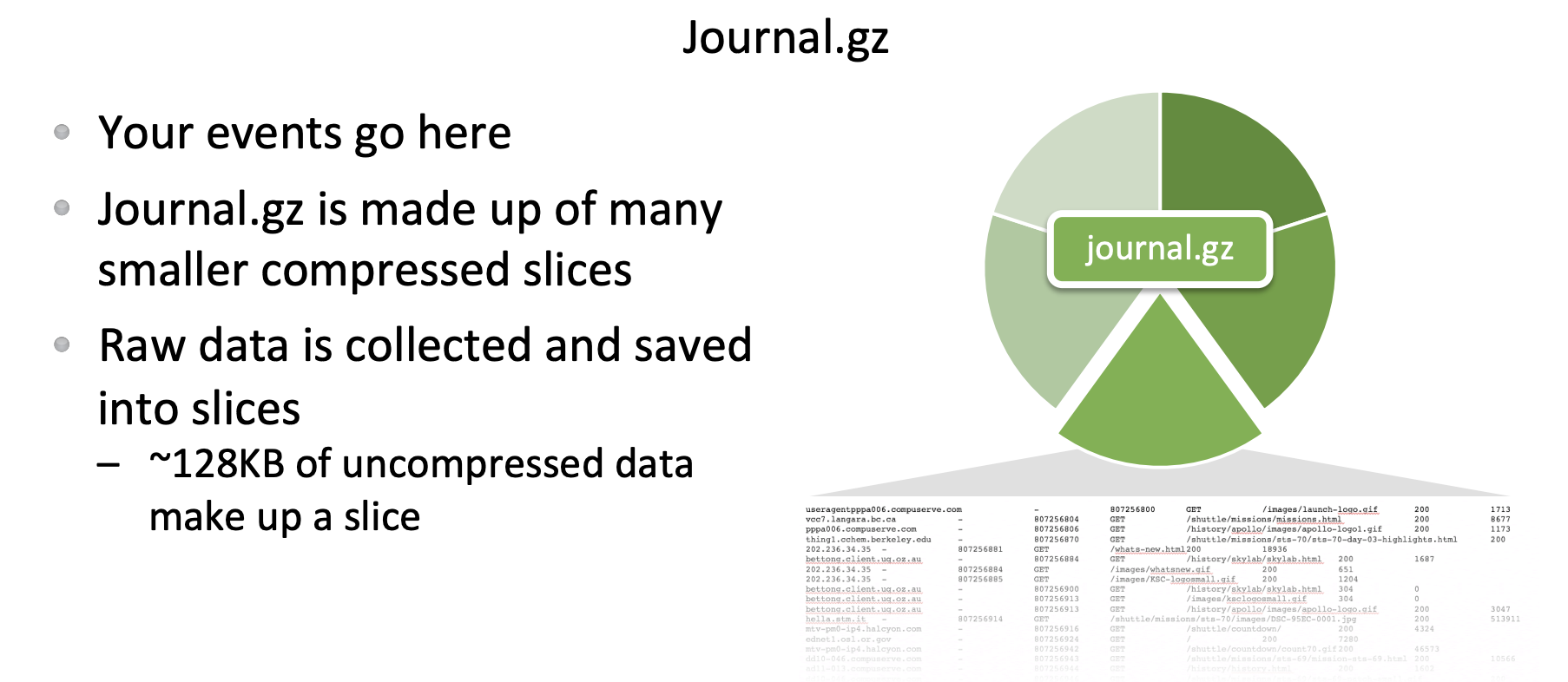
1. journal.gz: Bucket에 데이터가 단순히 여러 row가 쌓여서 저장되는 것은 아니다. 압축 파일 형태로 저장되는데, 여러개의 데이터가 모여 journal.gz 파일로 저장된다.
-
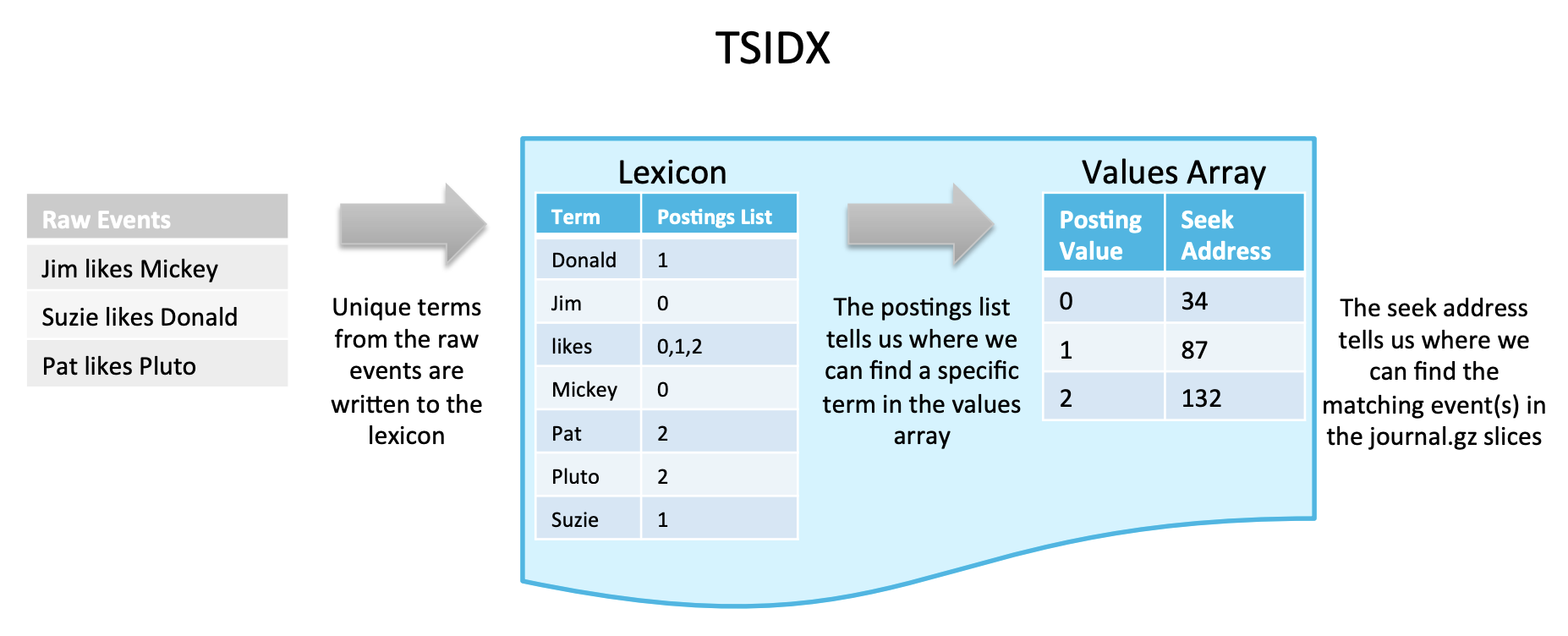
tsidx: 검색 가능여부에 따라 tsidx 파일이 포함되기도 하는데, tsidx 파일은 실제 raw데이터가 journal.gz의 어디에 존재하는지 그 참조값을 가지고 있는 인덱스 파일이다. 따라서 검색이 가능한 버킷의 경우는 tsidx를 가지고 있어 데이터 참조값을 이용해 데이터를 서칭한다.
-
Bloom Filter: 블룸 필터는
불필요한 버킷을 제외시켜주는 필터라고 보면 된다. 우리가 필터를 사용할 때에는 불필요한 것을 보지 않기 위해 사용한다. 말 그대로 불필요한 것을 제외시켜준다. 특정 검색키워드를 검색헤드로 부터 요청 받으면, 피어노드에서는 이 블룸필터를 이용해해당 데이터가 없는 버킷을 제외한다.
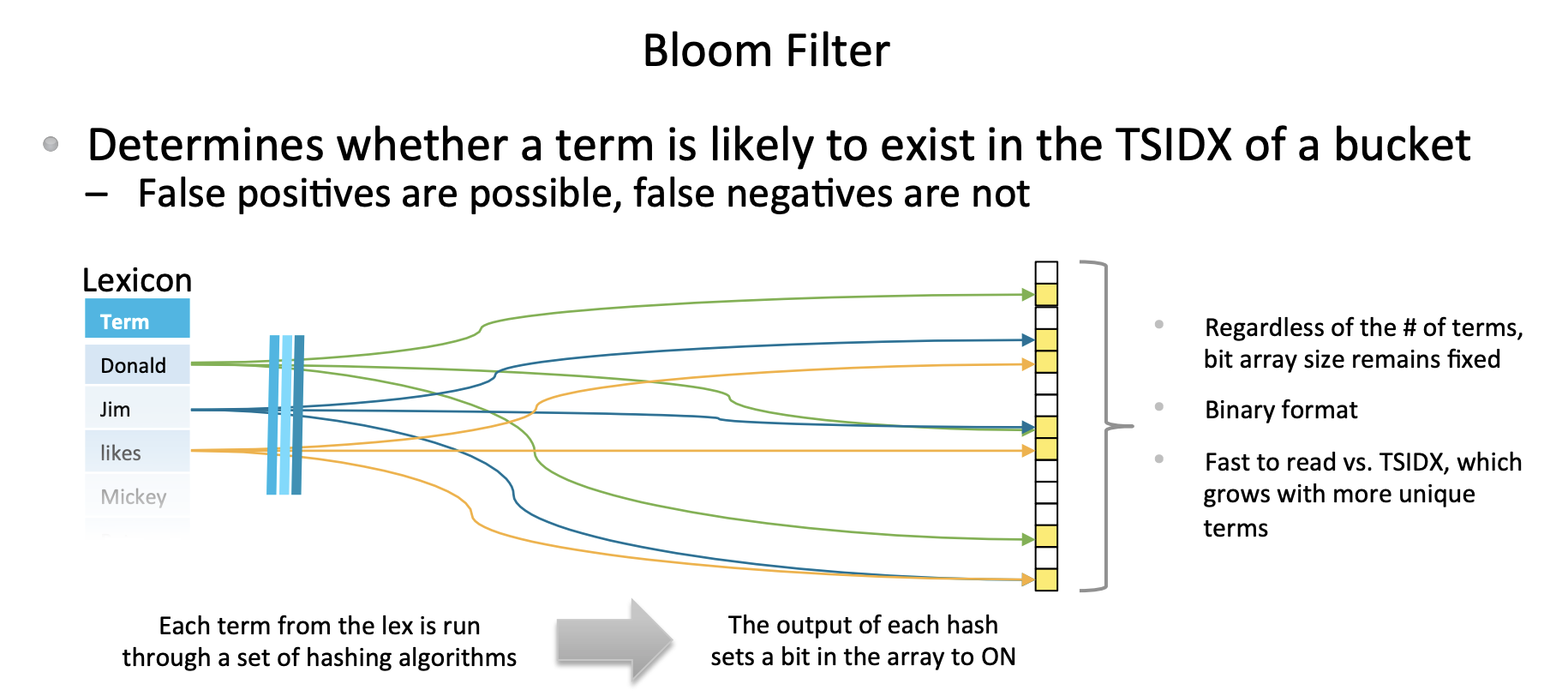
- 참고사항
버킷에는 시간에 따라 단계가 변화하는데, 크게 hot, warm, cold, frozen 단계가 있다. 피어노드는 버킷이 Warm단계가 되면, Bloom 필터를 생성한다. Bloom 필터는 Warm, cold 단계에서만 사용한다. 핫 버킷에는 블룸 필터가 존재하지 않으며 버킷이 frozen 단계로 가면 사라진다.
2. Bucket의 단계
앞에 참고 사항에서 봤듯이 버킷은 단계가 존재한다. 시간이 지남에 따라 아래의 단계 순서로 변화한다. 단순히 네이밍만 변화하는 것은 아니다. 실제로 우리가 검색할 때에 뒤로 롤링될 수록 검색되는 속도가 낮아진다.
- hot
- warm
- cold
- frozen
* thawed
실제 사용할 경우 hot, warm 위주로 사용하게 된다.
이렇게 버킷을 롤링하는 이유는 무엇일까? 이건 개인적인 생각이지만 기본적으로 데이터는 시간에 의존적이다. 오래된 데이터일 수록 가치가 없다. 보안 뿐 아니라 비즈니스의 영역에서도 오래된 데이터가 아닌 최신의 데이터로 미래를 예측하는 경우가 더 많기 때문이다.
따라서 hot, warm, cold, frozen 구간의 데이터로 나누어 우리가 자주 보고 빨리 봐야하는 데이터의 단계를 구분시킨 것 같다.
데이터를 인덱싱 하면서 시간에 따라 bucket이 rolling 되는 과정
- 포워더에서 막 데이터를 받으면 hot 버킷에 기록이 된다. hot 버킷은 이처럼 현재 기록중인 데이터를 보관할때 사용한다.
- 피어노드가 hot 버킷에 대한 쓰기를 마치면 버킷을 warm 상태로 롤링하고, 새 hot 버킷에 쓰기 시작한다. Warm 버킷은 검색 하는 데에 사용되지만, 피어노드는 여기에 새 데이터를 쓰지는 않는다.
- 시간이 지나 버킷은 cold 상태로 전환된 다음 frozen 상태로 전환된다.
- 피어노드 서버의 용량이 모두 차게 되면, frozen 상태로 전환된 데이터가 삭제된다.
- 만약 frozen 상태의 데이터가 보관되어있을 경우, 다시 검색 가능하게 변경이 가능한데 이렇게 변경된 데이터는 thawed 상태라고 한다.
단계별 검색 가능 여부
| 단계 | 검색 가능여부 |
|---|---|
| hot | O |
| warm | O |
| cold | O |
| frozen | X |
| thawed | O |
버킷 별 저장되는 디렉토리 위치
| 단계 | 저장위치 |
|---|---|
| hot | $SPLUNK_HOME/var/lib/splunk/defaultdb/db/ |
| warm | $SPLUNK_HOME/var/lib/splunk/defaultdb/db/ |
| cold | $SPLUNK_HOME/var/lib/splunk/defaultdb/colddb/ |
| frozen | 삭제가 디폴트 값이며, 별도로 지정한 경우 지정된 경로 |
| thawed | $SPLUNK_HOME/var/lib/splunk/defaultdb/thaweddb/ |
2. Bucket의 검색 가능성
1. Bucket의 우선권 개념
클러스터는 검색 가능한 버킷 복사본을 여러 개 유지할 수 있음으로 클러스터에는 검색에 참여하는 복사본을 식별하는 방법이 필요하고, 이를 위해 클러스터 내에서는 버킷의 우선권 개념이 존재한다.
primary copy 이거나 non-primary copy이다. 버킷이 primary copy인 경우가 우선권을 가지고 있다.
검색 가능한 버킷(journal.gz와 tsidx파일을 모두 포함한 버킷)은 다시 우선권 여부에 따라 primary copy, non-primary copy로 나뉜다.
아래의 그림을 보면서 설명하겠다.
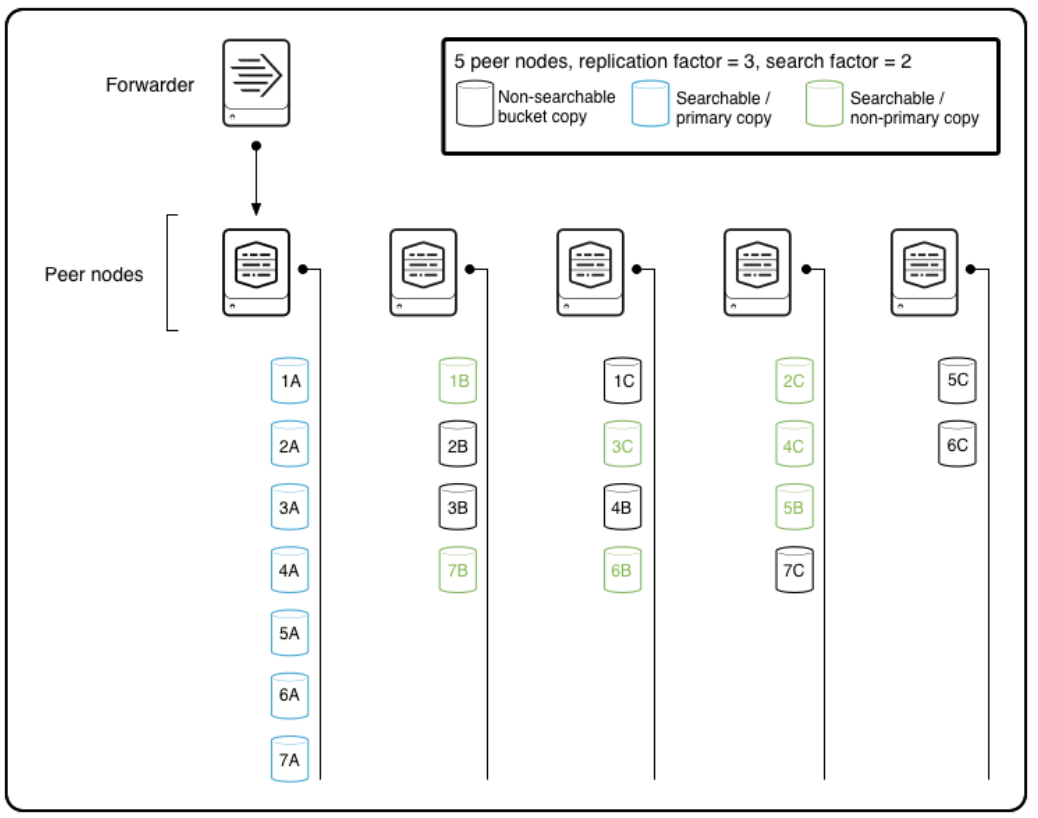
위의 그림에서 하늘색 버킷에만 primary copy에 해당된다. primary copy가 지정되는 흐름을 보면 아래와 같다.
- 외부 데이터를 수신하는 피어는 원시 데이터를 저장하고 원시 데이터의 복사본을 다른 피어에게 보낸다.
이때 원시 데이터(1A)가 primary copy로 지정된다. - 검색 인자가 1보다 큰 경우 해당 피어 중 일부 또는 전체가 복제 중인 버킷에 대한 tsidx 파일도 생성한다.
이때 복사본 데이터(1B)가 non-primary copy가 된다. - 예를 들어 복제 팩터가 3이고 검색 팩터가 2이고 클러스터가 완료 되면 클러스터에는 각 버킷의 복사본 3개가 존재한다.
- 세 개의 복사본 모두 원시 데이터 파일을 포함하고 복사본 중 두 개에도 인덱스 파일이 포함되므로 검색이 가능합니다.
- 세 번째 사본은 검색할 수 없지만 검색 가능한 버킷 복사본을 보유하고 있는 피어가 다운되면, tsidx 파일을 만들어 검색 가능하게 할 수 있다.
이런식으로 사이트의 검색 가능한 primary copy는 1개로 유지된다. 따라서 버킷 중 하나만 검색에 참여하게 된다.
- primary copy가 있는 노드가 다운되면 non-primary copy를 즉시 기본으로 지정할 수 있으므로 먼저 새 인덱스 파일이 생성될 때까지 기다릴 필요 없이 검색을 계속할 수 있게된다.
2. Bucket의 세대
세대는 클러스터내에서 버킷의 어떤 복사본이 primary copy인지 식별하는 기준이라고 볼 수 있다. 쉽게 말하면 스냅숏 개념과 유사하다.
예를 들어 최초에 데이터가 인덱싱 되고, 인덱싱 된 원본 데이터가 primary copy으로 지정되었다면 이때를 A세대라고 했을 때 특정 노드가 다운되어 primary copy가 변경되면 B세대가 되는 것이다.
해당 클러스터가 세대가 되는지의 여부는 클러스터의 버킷에 정확히 primary copy가 1개 있다는 점에서 유효한 세대라고 볼 수 있다.
검색에서 세대 정보는 어떻게 사용될까
- 검색헤드는 정기적으로 최신 세대 정보에 대해 관리자 노드로부터 정보를 가져온다.
- 만약 세대가 변경되면 관리자 노드는 검색 헤드에 새로운 세대 ID와 해당 세대에 속한 피어 목록을 검색헤드에 제공한다.
- 검색헤드는 검색을 시작하여 피어노드에게 세대의 ID를 제공한다.
- 피어는 ID를 사용하여 버킷 중 해당 검색의 기본 버킷을 식별한다.
- 일반적으로 검색은 가장 최근 세대의 기본 버킷에 대해 수행된다.
피어 노드가 다운되어 세대가 바뀌는 경우
- 피어가 다운되면 관리자 노드가 다운된 피어의 primary copy을 다른 피어의 복사본에 재할당한다.
- 다운된 피어로 인해 primary copy이 바뀌어 관리자 노드가 새세대를 생성한다.
예를 들어, 아래의 그림을 살펴보자.
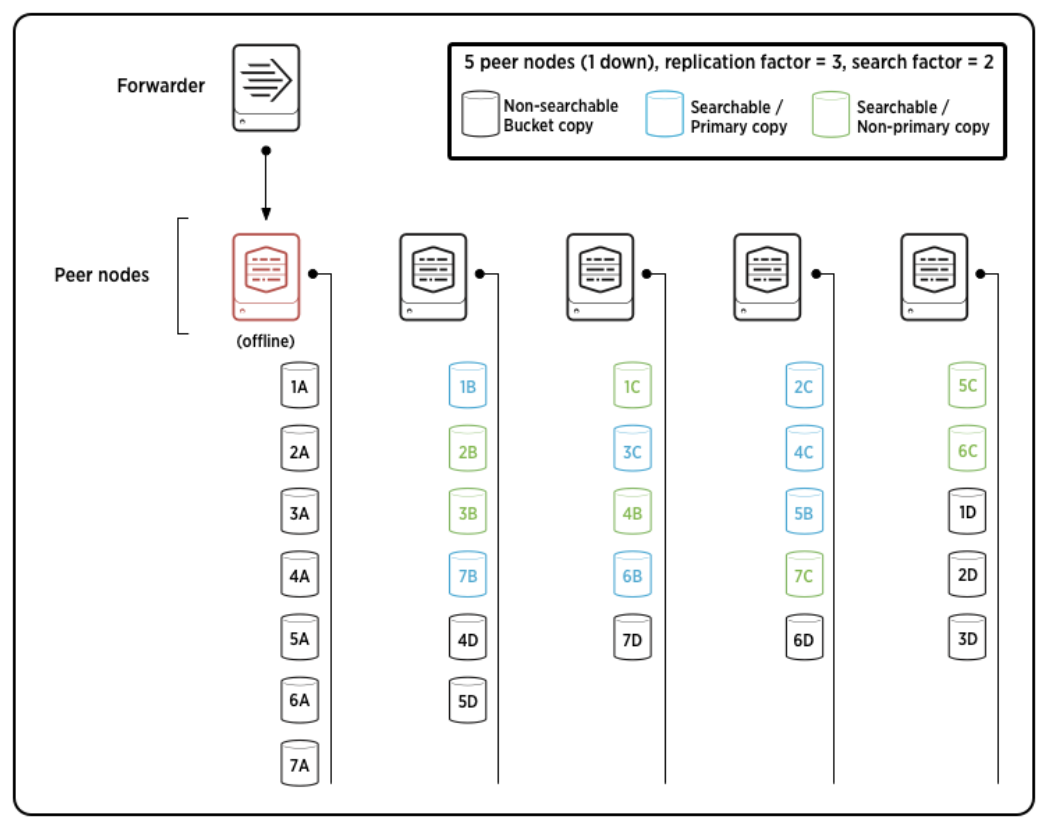
5개의 피어노드가 있고, 복제 버킷은 3개(원본 포함), 검색 가능한 버킷은 2개이다.
1. 그림에서 이전 세대의 primary copy는 1~7A 이었다.
2. 하지만, 해당 노드가 다운되어 primary copy가 1~7B 버킷으로 변경된 모습이다.
3. 관리자 노드는 이전 세대에서는 검색 불가능 했던 1~7C 버킷이 검색 가능하도록 tsidx 파일을 생성하여 검색 가능하게 한다.
4. 마지막으로 검색할 수 없는 새로운 복사본 세트(1~7D)의 복제를 나머지 피어 간에 확산하도록 지시한다.
이렇게 하여 원본 노드가 다운되었음에도 불구하고 클러스터는 전체 버킷 복사본의 복제 요소 번호(3), 검색 가능한 버킷 복사본의 검색 요소 번호(2) 및 정확히 하나의 primary copy을 사용하여 완전 하고 유효한 상태 를 모두 완전히 복구할 수 있다. 이때 기primary copy이 다른 피어로 이동했기 때문에 이전 다이어그램과 다른 세대를 가지게 된다.
이번 포스팅은 버킷에 대한 개념과 버킷의 세대에 대한 개념을 알아봤다. 인덱서 클러스터와 버킷에 관한 개념은 여기까지로 하고, 다음에는 직접 실습을 하면서 클러스터를 구성해보려고 한다.
