오늘은 Splunk Indexer Cluster에 대해 포스팅을 한다.
공식 문서를 참고하였다.
1. Indexer Cluster이란?
Splunk 시스템이 모든 데이터의 여러 복제본을 보관할 수 있도록 서로의 데이터를 복제하도록 구성된 Splunk Enterprise의 인덱서 그룹이다. 동일한 데이터의 복제본을 가지고 있어, 데이터의 손실을 막고 검색할 수 있는 데이터의 가용성을 높여준다.
1. Indexer Cluster의 구성
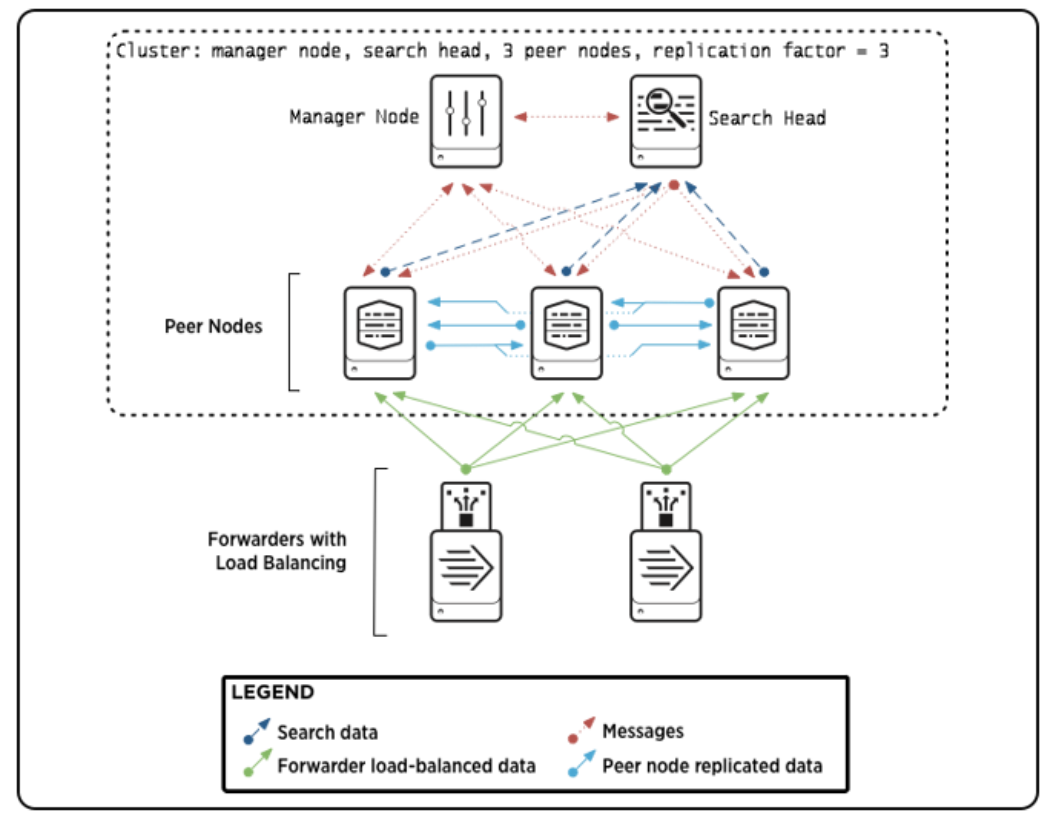
인덱서 클러스터라고 하면 인덱서로만 이뤄진 클러스터를 말하는 것이라 생각했으나, Splunk 공식 문서에서는 인덱서가 클러스터링 되어있는 하나의 아키텍처를 통칭하여 말하는 듯 했다.
(실제 업무 할 때에는 보통 인덱서가 클러스터링 되어있는 그룹을 말하는 경우가 많았다.)
인덱서 클러스터는 크게 3가지 구성원으로 이루어져 있다. 위의 그림은 replication factor 가 3이고 3개의 피어노드, 1개의 관리자 노드, 1개의 검색 헤더로 이뤄진 인덱서 클러스터의 모습이다.
각 컴포넌트의 역할을 기재하면 아래와 같다.
- 관리자 노트 (Cluster Master) : 클러스터를 관리하기 위한 관리자 노드이다. 피어노드간 데이터 복제 활동을 조정한다. 검색 헤드에게 데이터를 찾을 위치를 알려주는 역할을 하며, 피어노드가 다운됐을 때의 조정을 하기도 한다.
- 피어 노드 (Peer Node): 흔히 인덱서라고 통칭하는 서버를 말한다. 클러스터 내에서 데이터 저장 기능을 담당한다. 또한, 다른 피어노드로 부터 복제할 데이터를 받거나, 복제된 데이터를 다른 피어노드에게 전달할 수 있다. 추가로 검색 헤드의 검색 요청에 따라 저장된 데이터를 검색한다.
- 클러스터 내의 피어 노드 개수는 replication factor 와 indexing load 라는 두 가지 요소에 따라 달라진다. 이 두가지 개념은 아래에서 설명하겠다.
- 검색 헤드 (Search Head): 검색 헤드는 피어 노드 집합 전체에서 검색을 관리한다. 검색 쿼리를 동료에게 배포하고 결과를 통합한다.
2. Indexer Cluster의 데이터 흐름
여기서 보이는 데이터&요청의 흐름은 아래와같다.
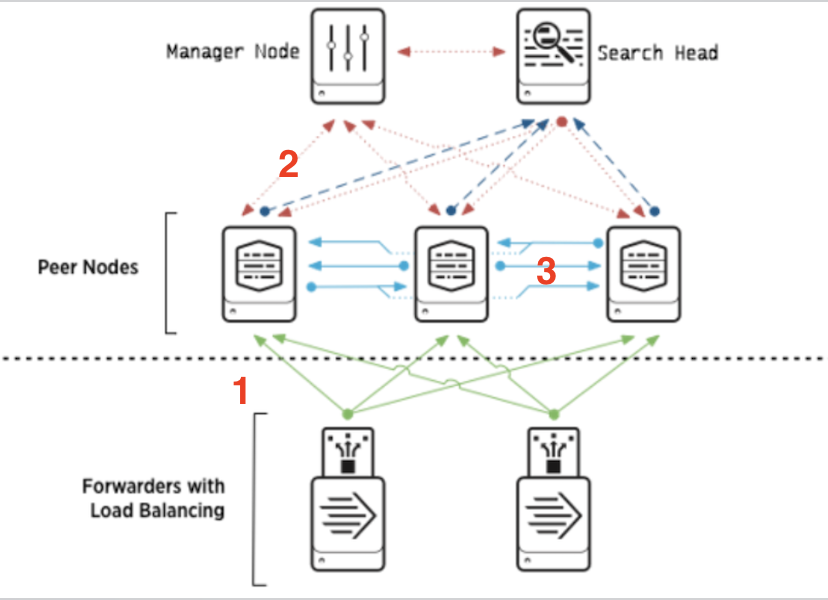
1. 포워더를 통해 외부 데이터를 수신받은 피어노드는 데이터를 저장한다.
2. 이 저장된 데이터를 관리자 노드의 명령에 따라 다른 피어노드에 배포한다.
3. 동일한 데이터의 복사본을 3개를 만들어 각 노드에 저장해둠으로써 검색 가용성을 높인다.
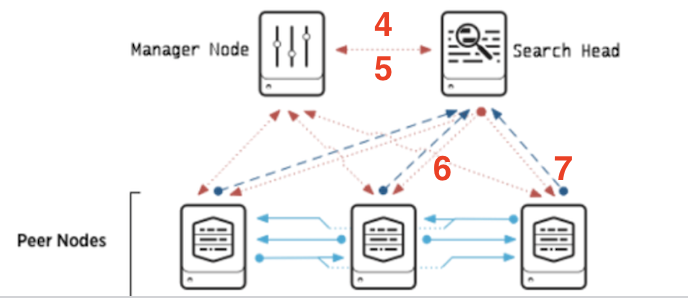
- 이후 검색 헤드에서 특정 데이터의 검색 요청이 온다.
- 관리자 노드는 검색 헤드로부터의 검색 요청에 따라 어떤 피어노드를 접근해야 하는지 검색헤드에게 알려준다.
- 응답을 받은 검색헤드는 피어노드에 데이터 검색을 요청한다.
- 피어노드는 요청받은 정보에 따라 데이터를 검색하여 검색 헤드에게 전달한다.
2. 중요한 개념
1. Replication Factor 복제 인자
관리자 노드에서 구성하는 값으로, 저장되는 데이터의 복사본을 몇개로 할 것인지를 의미한다. 이것을 Replication Factor 이라고 한다.
복제 요소는 클러스터의 오류 허용 범위를 결정한다. 무슨 말이냐하면, 시스템의 복제 요소가 3으로 지정되어있으면 동일한 복사본을 3개 가지고 있다.(원본 + 2개를 복제) 따라서 이것은 3대의 피어노드에 나누어 저장되고, 2대의 피어노드가 Down 되더라도 데이터 가용성이 보장된다.
따라서 클러스터는 (복제요소 - 1)의 오류를 허용한다고 한다.
2. Search Factor 검색 인자
관리자 노드에서 구성하는 값으로, 바로 검색이 가능한 복사본은 몇개인지를 의미한다.
검색 가능한 데이터 복사본에는 검색 불가능한 복사본보다 더 많은 저장 공간이 필요하므로 정확한 요구 사항에 맞게 검색 요소의 크기를 제한하는 것이 가장 좋다.
- 검색 불가능한 데이터 복사본: 원시 데이터(journal.gz)
- 검색 가능한 데이터 복사본: 원시 데이터(journal.gz) + 인덱스(.tsidx)
대부분의 경우 기본값인 2를 사용한다. 이렇게 하면 단일 피어 노드가 작동 중지되는 경우 다른 피어 노드에서 즉각 검색이 가능하기 때문에 클러스터가 거의 중단 없이 검색을 계속할 수 있다.
- 다중 사이트 클러스터는 조금 형태의 검색 인자, 복제 인자를 사용한다. 이 내용은 다음에 포스팅 하겠다.
3. Bucket 버킷
1) 버킷이란?
Splunk는 인덱싱된 데이터를 데이터 파일이 포함된 디렉터리인 버킷에 저장한다. 인덱스는 일반적으로 여러 개의 버킷으로 구성된다. 앞에서 데이터의 복사본이라고 표현한 것은 사실 버킷 복사본이라고 봐야한다.
인덱스 = 여러개의 버킷 이며, 버킷은 raw 데이터가 있는 저장소 단위라고 볼 수 있다.
2) 버킷으로 표현된 피어 노드
아래의 그림은 복제 요소가 3인(원본 데이터 + 복사본 2개)인덱서 클러스터를 표현한 것 이다.
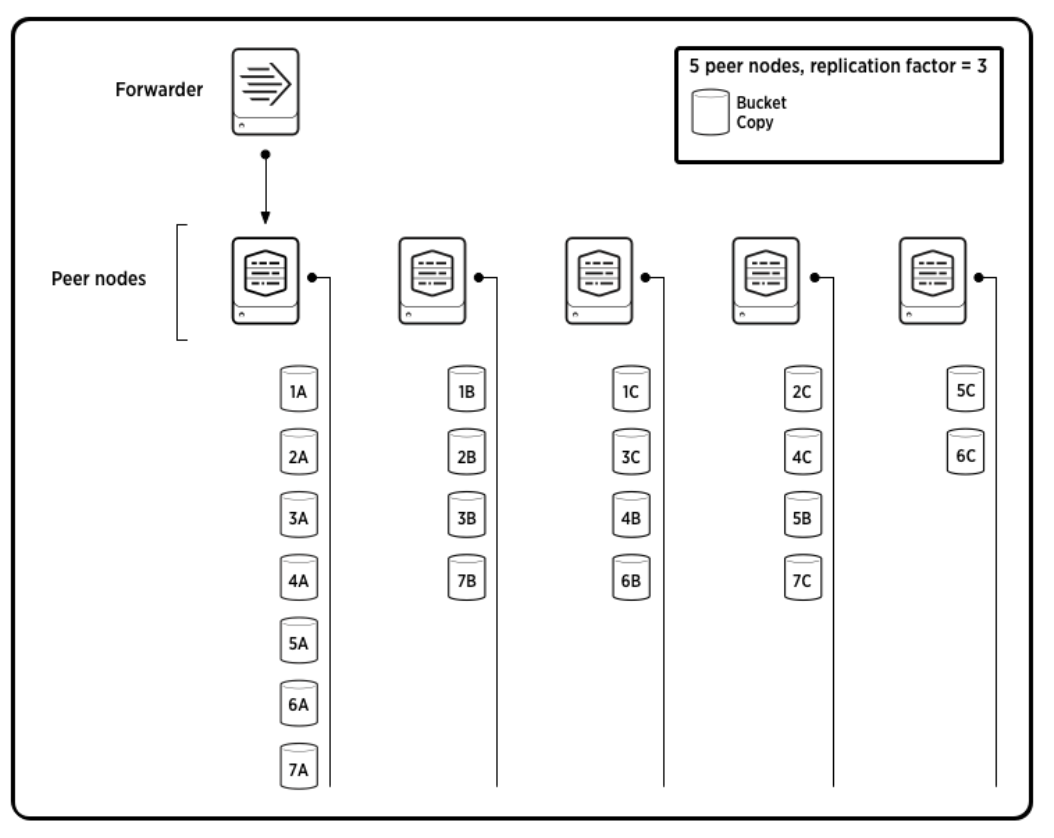
3) 검색 가능한 버킷, 불가능한 버킷
또한, 버킷 복사본은 검색 가능하거나 검색 불가능한데 이것은 앞서 확인했던 검색 인자와 관계가 있다.
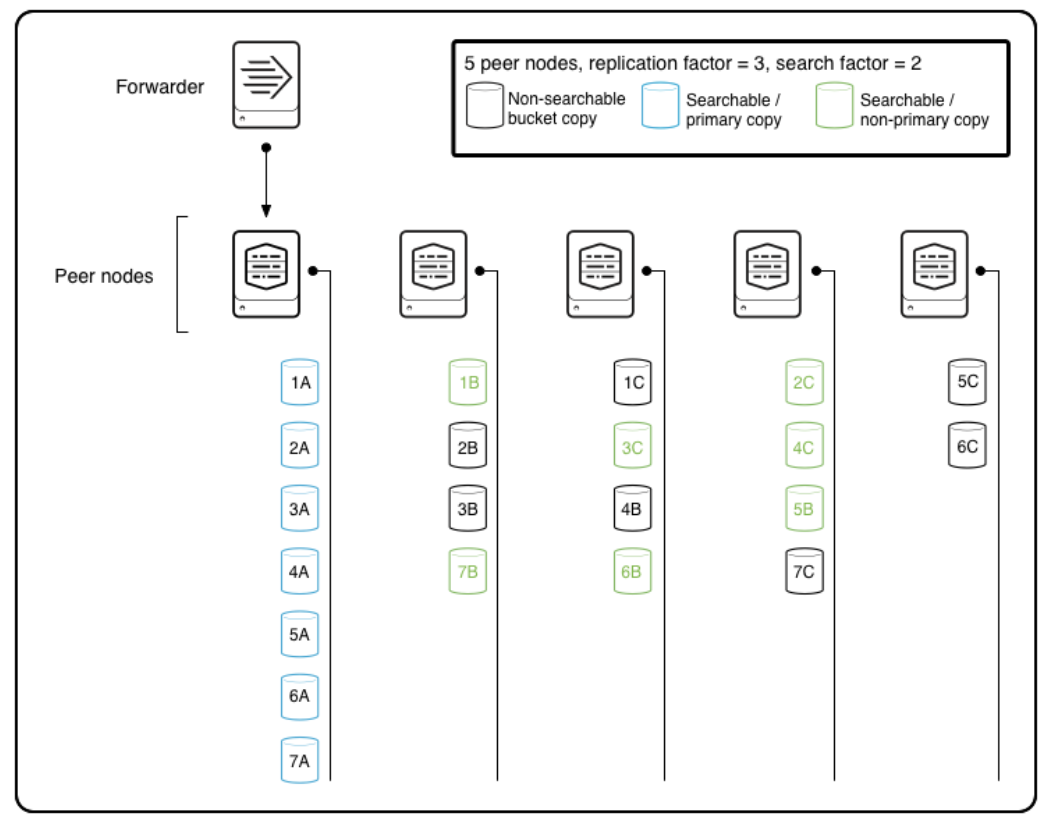
파란색 버킷은 데이터의 원본이고, 연두색은 복제본이면서 검색 가능한 버킷, 검은색은 복제본이면서 검색이 불가능한 버킷이다.
복제 인자를 3으로 했기 때문에 파란색 외에 연두색 + 검은색의 버킷 복제본이 존재하고, 검색 인자를 2로 했기 때문에 파란색 외에 연두색 버킷 또한 검색이 가능한 것 이다.
검색 가능 여부는 인덱스 파일을 포함하는 버킷이냐에 따라 다르다. 인덱스 파일은 쉽게 말해 데이터가 어디에 저장되어있는지 알려주는 파일이라고 생각하면 된다.
- 검색 불가능한 버킷: 원시 데이터(journal.gz)
- 검색 가능한 버킷: 원시 데이터(journal.gz) + 인덱스(.tsidx)
- 그림의 primary copy에 관해서는 다음 포스팅에서 자세히 설명한다.
4) 버킷 복사본은 복제 인자를 초과할 수 있다.
피어가 새 버킷을 생성할 때마다 관리자 노드와 통신하여 버킷의 데이터를 전달할 피어 목록을 가져온다.
피어 노드 수가 복제 인자를 초과하는 클러스터가 있는 경우 피어는 새 버킷을 생성할 때마다 다른 피어 집합으로 데이터를 전달할 수 있다.
결국 복제 인수가 3인 경우에도 만약, 피어노드가 5대라면 3대 이상의 서버가 복제본을 가지고 있을 수 있다.
그 외에도 오류나, 상세한 과정에 대한 정보는 공식 문서를 참고하면 된다. 일반적인 인덱서 클러스터의 개념은 여기 까지이며, 다음 포스팅에서는 버킷과 인덱서 클러스터에 관한 내용을 다루겠다.
