오늘은 이전 개념에 이어 DataModel 생성하는 방법에 대해 알아보겠다.
DataModel 생성
데이터 모델은 기본적으로 계층적인 구조이다. 이번에 새로운 케이스로 생성할 데이터 모델의 계층 구조는 다음과 같다. 아래의 구조를 데이터 모델로 정의하는 작업을 진행할 것 이다.
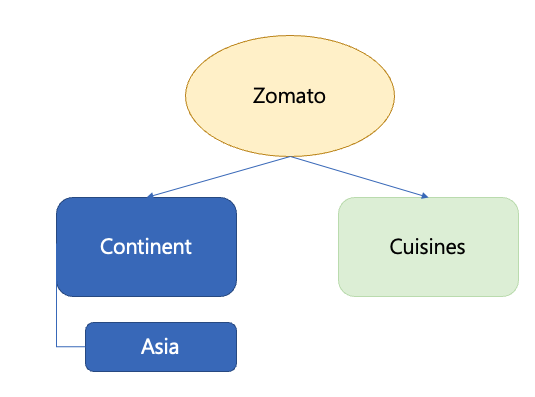
완성 시, 화면으로 보면 아래와 같은 모습이다. 데이터 모델 정의를 함으로써 Continent 데이터는 하위에 Asia라는 데이터 셋이 있고, 그와 별개로 또 Cuisines 데이터 셋이 존재함을 관계로 파악할 수 있다.
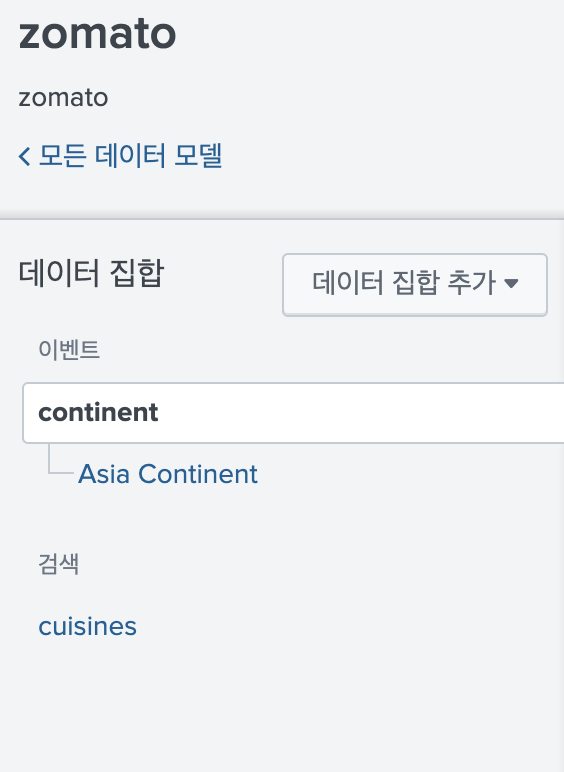
1) 최초 데이터 셋 생성
데이터 모델에서 새 데이터 모델을 생성한다.
루트 이벤트 셋 혹은 루트 검색 셋 생성
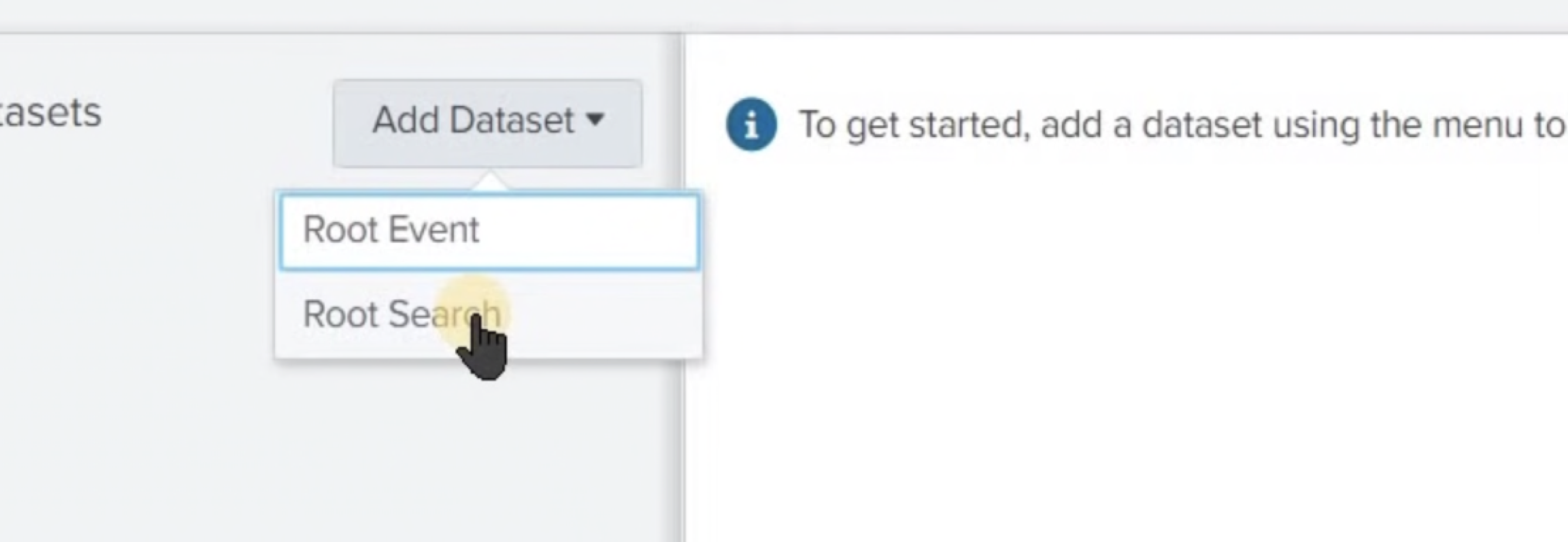
최초에 데이터 셋을 생성할 때에는 루트 이벤트 셋을 생성한다. 하위 데이터 셋은 루트 데이터셋 혹은 루트 검색 이벤트 셋이 있어야 생성이 가능하다. (트랜잭션 세트 또한 동일)
제약 조건 생성
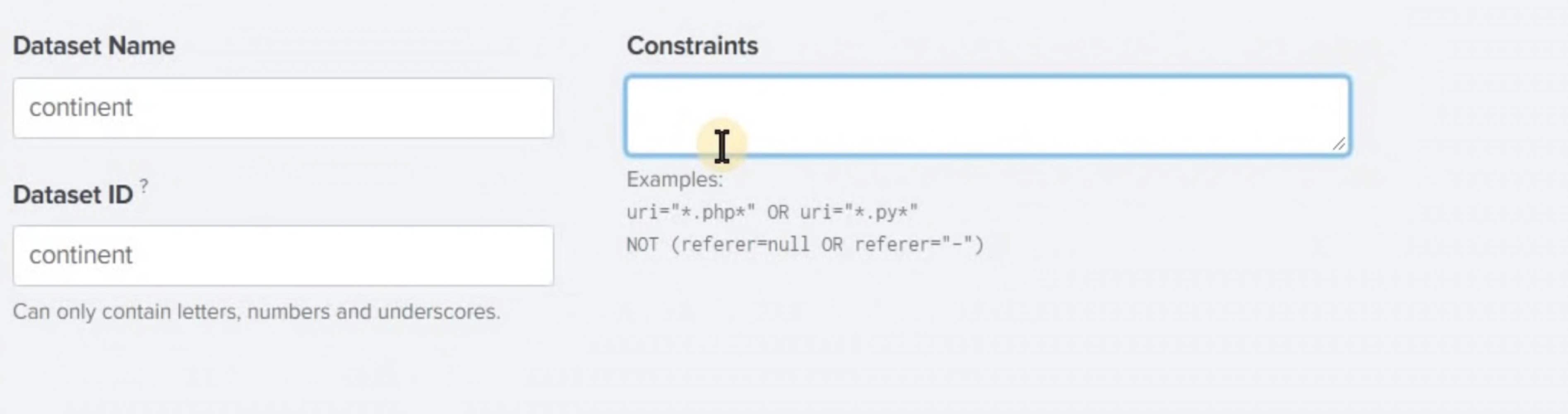
제약 조건은 말 그대로 데이터셋을 정의하는 쿼리문이다. 예시문에서 나와있는 것과 같이 루트 이벤트를 정의하는 쿼리는 일반적인 SPL에 사용하는 최상단 쿼리를 주로 사용한다고 보면 된다.
index=main 'Country Code'=*을 제약조건으로 입력해줬다.
루트 이벤트와 루트 검색의 차이점이 뭐야?
- 루트 이벤트의 경우 위의 경우처럼 검색 쿼리의 최상단 검색에 사용하는 일반 문자열 기반 검색을 주로 사용한다. 집계명령어와 같은 추가 명령어를 사용할 수 없다. 따라서 단순히 제약조건으로 정의를 해야한다.
- 루트 검색 이벤트의 경우 SPL 사용이 가능하다. stats와 같은 집계명령어로 구성할 수 있다. 제약조건이 아닌 검색 문자열로 이뤄진 것을 볼 수 있다.
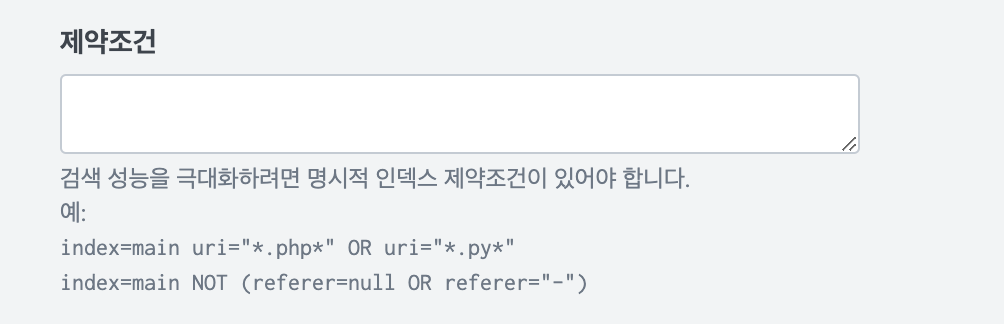
필드 추출
제약 조건을 생성하게 되면 아래와같이 루트 이벤트 셋 기반의 데이터 모델이 생성되었다.
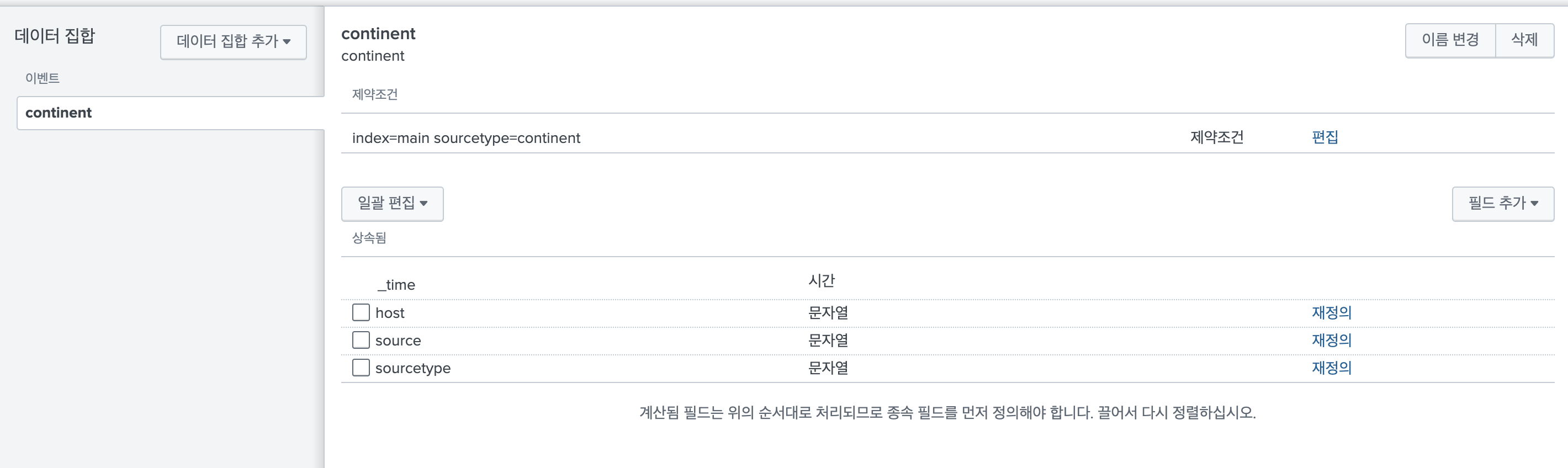
이후에는 위에서 정의한 데이터의 필드를 추출해준다. 기본적으로 데이터 모델을 정의하게 되면, 정의된 데이터의 메타 필드(host, source, sourcetype)만 필드로 추출되기 때문에 필요한 필드는 추출 작업을 해줘야한다.

여기서 눈여겨볼 필드 추출 방법은 크게 3가지이다.
- 평가식: eval커맨드를 사용할 때에 방법으로 직접 쿼리를 작성하여 정의한다.
- 룩업: lookup 커맨드를 넣어서 필드를 추출한다.
- 정규식: 직접 정규식을 사용해 필드를 추출한다.
나는 평가식을 이용해서 필드를 추출했다.
아래와 같이 평가식을 정의했는데, 이를 eval 커맨드로 표현하면 다음과 같다.
| eval countryCode = 'Country Code'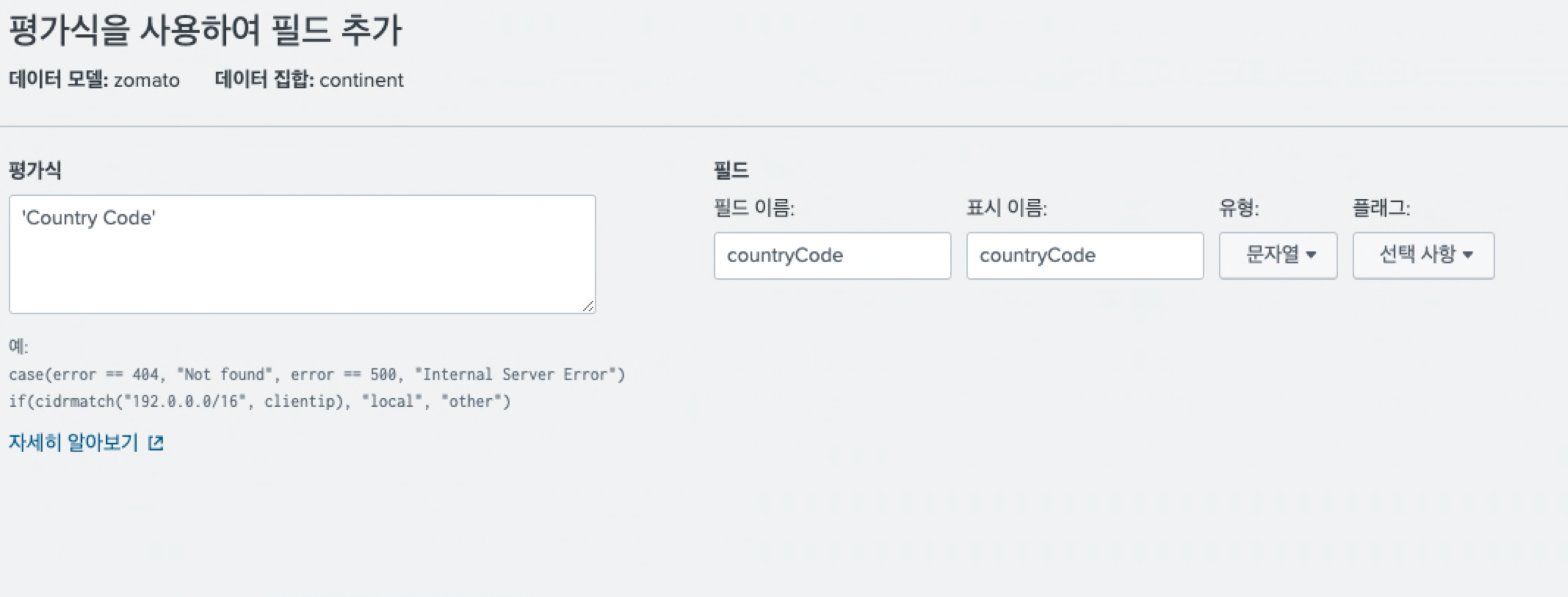
필드 이름은 말 그대로 평가식을 통해 정의될 필드의 이름을 나타낸다. eval식에서 정의된 필드명이다. 표시 이름은 피벗을 사용할 때 표시되는 이름을 나타낸다. 보통 두 가지를 같은 명칭으로 사용한다. 저장을 눌러준다.
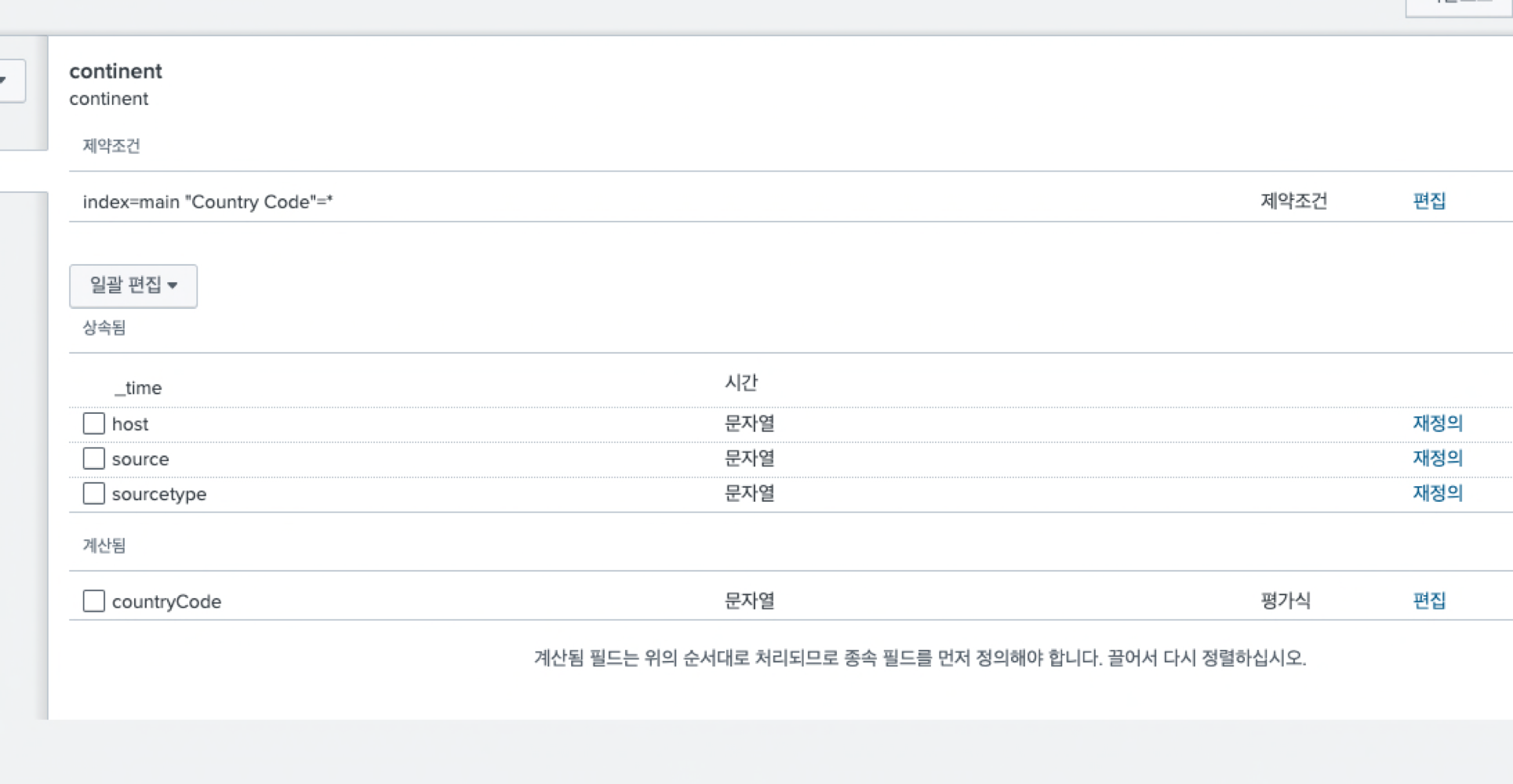
위와 같이 계산됨 필드 아래에 정의된 필드가 생성된 것을 볼 수 있다.
2) 하위 데이터셋 Asia 생성
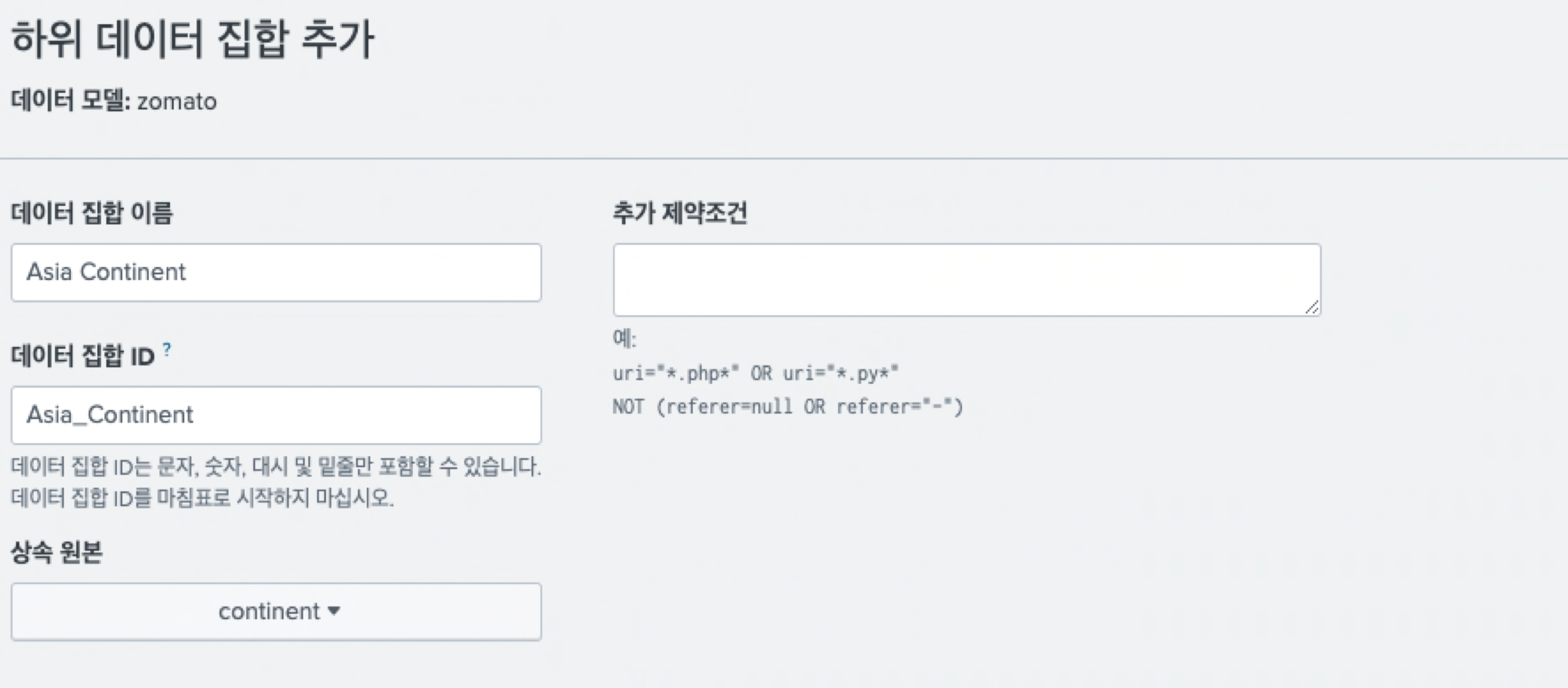
Countinent 데이터 셋에서 Asia 데이터만을 분리해 하위 데이터로 생성하려고 한다. 새로운 데이터 셋을 클릭한 후 하위 데이터셋 생성을 눌러준다.
하위 데이터 셋을 추가할 경우, 기존의 부모 데이터로부터 모든 데이터를 상속받기 때문에 위에 정의했던 쿼리index=main 'Country Code'=* 외에 추가 쿼리를 하위 데이터로 작성한다.
continent="Asia"그러면 아래와 같이 하위 데이터가 생성된다.
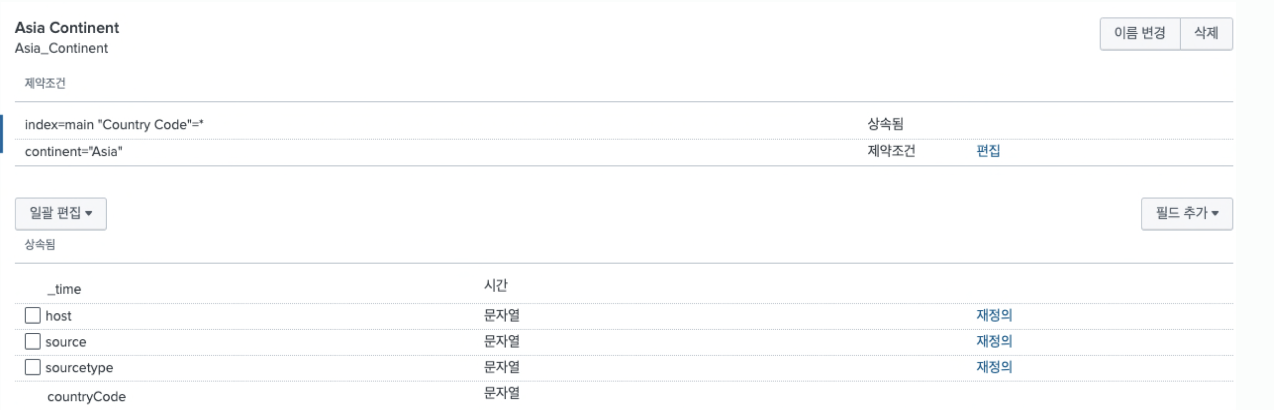
- 여기서 추가적으로 필드를 추출해줄 경우, 자동 추출은 불가능하다. 정규식, 평가식과 같은 추가적 수동 추출기능을 사용해야 한다.
3) 루트 검색 데이터 셋 생성
루트 검색 데이터 셋은 파이프 라인을 사용한 SPL 쿼리 사용이 가능하다.
따라서 아래와 같이 쿼리를 작성해서 데이터 모델을 정의해줬다.
index=main
| table Cuisines
| eval Cuisines = split(Cuisines,",")
| mvexpand Cuisines
이렇게 데이터 모델을 생성해봤다. 이렇게 하여 처음에 계획했던 데이터의 계층 관계를 정의할 수 있었다.
4) 데이터 모델 가속화
데이터 모델 가속화는 데이터 모델 화면에서 가속 편집을 누른 후
가속을 활성화 해주면 된다.
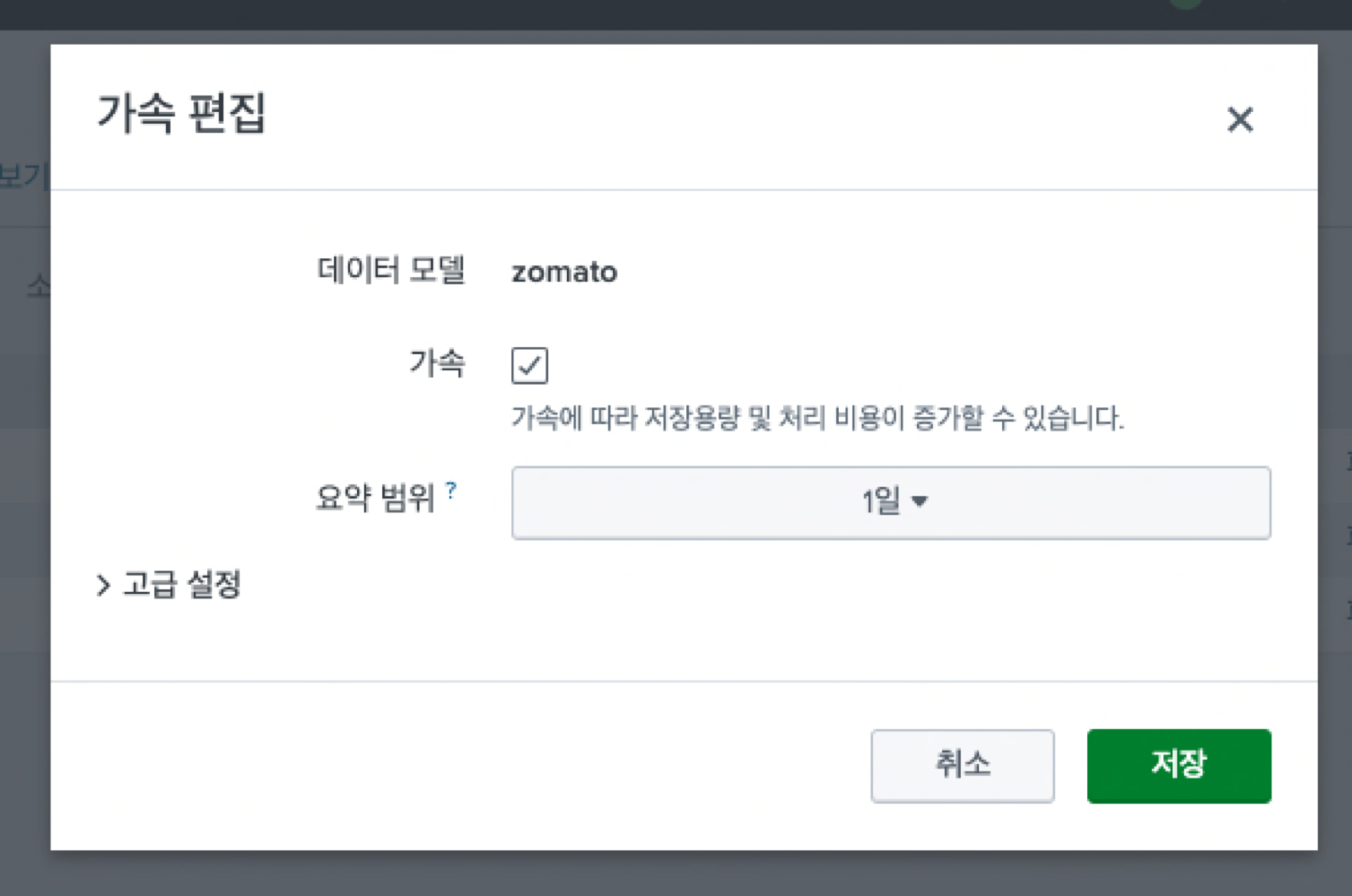
데이터 모델을 가속화 하게 되면, 루트 이벤트 데이터셋에 대해서만 가속화 인덱스가 생성된다. (검색 데이터 셋, 하위 및 트랜잭션은 해당 X)
또한, 데이터 모델을 가속화 하게 되면 제약조건을 편집할 수 없게 된다.
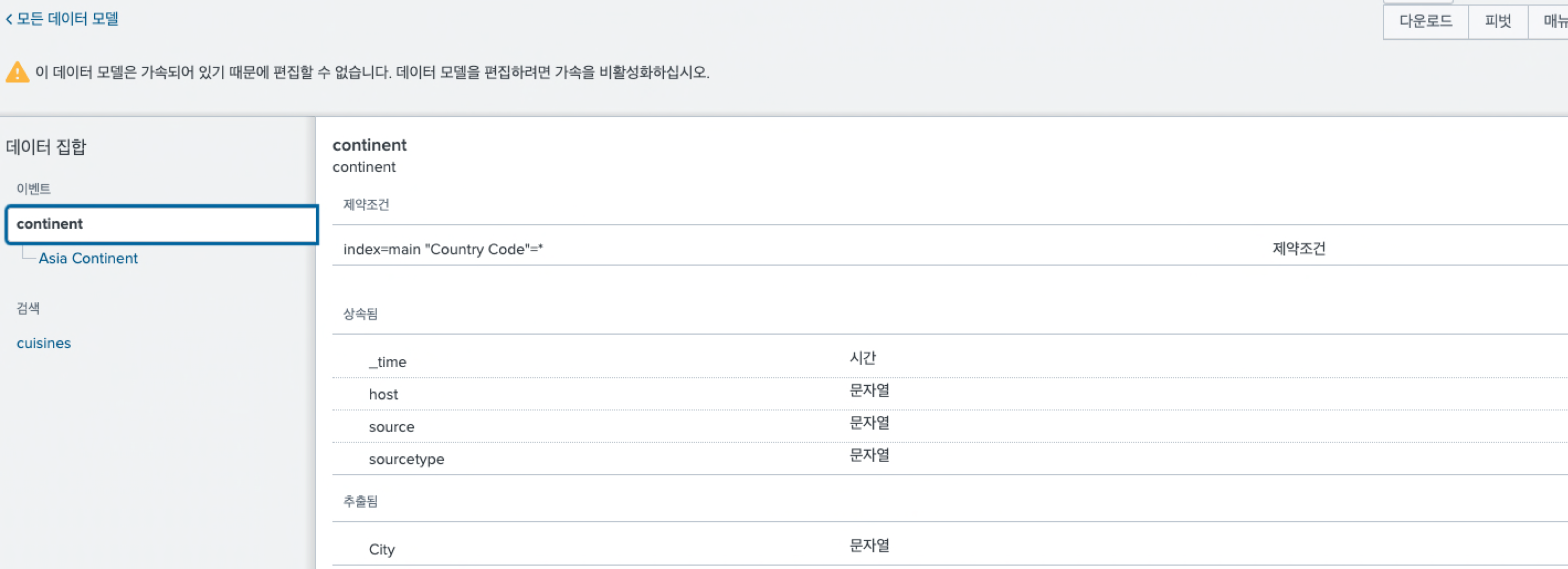
이로써 데이터 모델을 계층 구조에 맞게 생성하고, 가속화 하는 방법을 알아 봤다. 다음 시간에는 가속화된 데이터 모델 어떻게 사용하고, Summary Index와의 차이점은 무엇인지에 대해 알아보겠다.
