이전까지 Splunk DataModel에 관한 개념, 생성법에 대해 알아봤다. 이번에는 가속화의 상세 설정, Summary Index 와의 차이점에 대해 알아보려고 한다.
1. DataModel 가속화의 설정에 대해
1) 가속화란?
데이터 모델 가속화는 나의 블로그 포스팅에 개념에 대해 여러번 언급했기 때문에 이 게시글을 참고해주길 바란다!
2) 데이터 모델 가속화의 요약 범위에 대해
최초에 데이터 모델 가속화를 하려 보면, 조금 의아한 부분이 보인다. Summary Index를 생각하고 눌렀는데 조금 다른 것 같은 느낌이 든다.
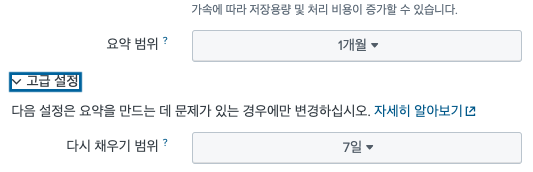
일단 요약 범위가 1일, 7일, 1달 등으로 나뉘어져있다. 그리고 기간을 설정하는 것이 요약 범위와 다시 채우기 범위 2가지가 있다.
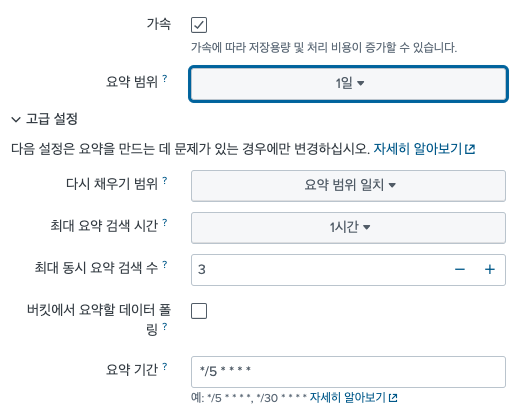
내가 생각한 Summary Index와는 다른걸까?
크론 */5 * * * * 으로 설정하고, 기간은 5분 전으로 요약하면 되는거 아니었나? 라고 생각을 하는 경우가 많다.
일단 결론적으로 말하면, 기능상 가능은 하다. 그런데 데이터 모델에서 정의되는 데이터의 보존 기간은 최초에 정의한 요약 범위만을 유지한다.
무슨 말이야?
데이터 모델 가속화를 이용해 5분으로 요약범위를 정하면, 논리적으로는 지금부터 5분 전 까지의 데이터만 보존이 된다.
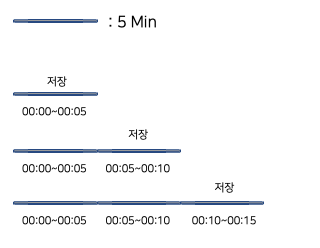
그래서 데이터 모델 Use Case, Practice를 보면 보통 요약 범위가 1달, 1일 정도로 나와있다. 왜? 그 기간만큼의 데이터를 보존하기 때문에 2분, 5분과 같은 너무 짧은 단위는 사용가치가 떨어지기 때문이다.
- 데이터 가속화를 통해 언제서부터 데이터가 저장되었는지 확인하는 쿼리
출처: Splunk Community
| rest /services/admin/summarization by_tstats=t splunk_server=local count=0
| eval key=replace('title',"tstats:DM_".'eai:acl.app'."_",""),datamodel=replace('summary.id',"DM_".'eai:acl.app'."_","")
| rename summary.time_range AS retention
| eval retention=retention/(60*60*24)
| table datamodel retention이상한데? 나는 1일로 요약범위를 설정 했는데, 7일 전 데이터가 잘 조회 되는데?
이것은 데이터 모델 가속화 시, 데이터가 저장되는 방식에 대해 알아야 한다.
데이터 모델 가속화 시, 가속화된 데이터들은 모두 기존의 index가 저장되는 곳과 동일한 Bucket에 저장된다.
나는 요약범위를 1일로 지정했다. 하지만, 조회 시 7일치의 데이터가 모두 확인되고 있었다.
그러면 실제 저장은 아래와 같이 이뤄진다.
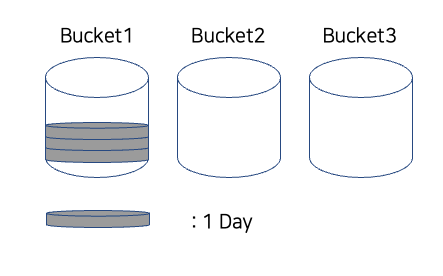
1일 치의 데이터가 버킷에 쌓이고, 그 다음 데이터가 계속 쌓이게 된다.
이론상 1일이 지나면 맨 처음에 쌓였던 데이터는 삭제가 되어야 하나, 그렇지 않다. 데이터의 보존기간은 버킷에 저장된 데이터의 보존기간이 모두 만료되어야 버킷이 삭제된다. 참고: Splunk Community
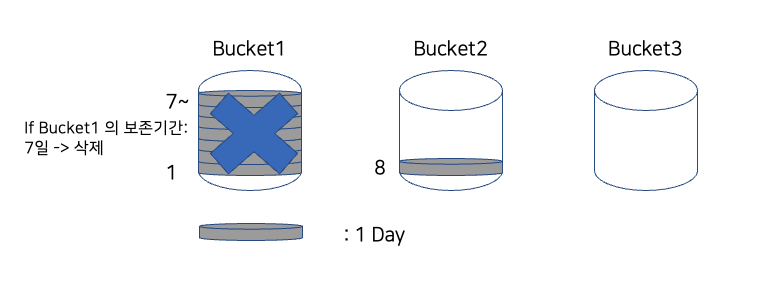
즉, 버킷에 있는 가장 최신의 데이터의 기간이 만료되어야 삭제된다.
이때의 보존 기간은 DataModel 가속화에서 Summary Range 즉, 요약 기간으로 설정한 값이다.

따라서 실제 검색 쿼리를 날려 조회했을 때에는 1달로 설정 했음에도 2달 이상의 데이터가, 1년으로 설정 했음에도 2년 이상의 데이터가 나오게 된다.
3) 데이터 모델 가속화의 다시 채우기에 대해
상세 설정에는 다시 채우기 범위라는 것이 존재한다.
한번에 1달의 데이터를 요약하게 되면 시스템에 부하가 갈 수 있기 때문에 이를 backfill 범위로 나누어 작은 범위로 요약한다.
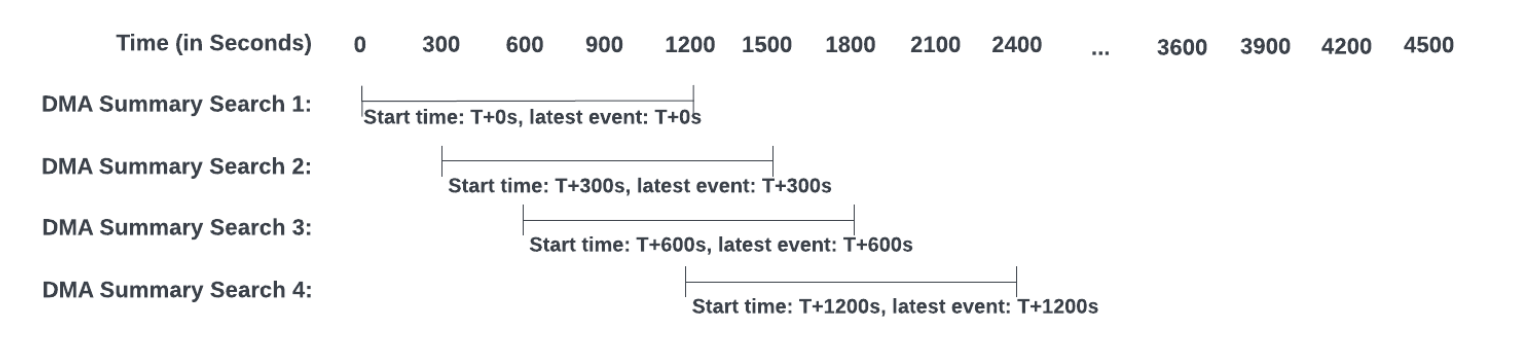
예를들어 요약범위를 1달로 하고, 다시 채우기 범위를 7일로 했다면 데이터가 보존되는 기간은 1달이고(실제 물리적으로는 더 저장될 수 있음), 데이터가 요약되는 검색이 earliest="-7d@d"로 시작 된다는 것 이다.
최초의 검색 시, 7일 요약이 끝나면 이후에는 그 범위를 점차 늘려 시스템 부하에 따라 요약을 진행한다.
참고: Splunk Community
4) 최대 동시 요약 검색 수
최대 동시 요약 검색 수는 데이터 모델이 가속화 될 때 여러 개의 검색이 병렬처리 되는데, 이때 검색을 몇 개로 할 것인지에 대한 문제이다.
3개로 하게 되면, 요약 검색이 시작될때마다 3개의 프로세스가 요약 검색이 생성되어 병렬처리된다.
5) 최대 요약 검색 시간
최대 검색 시간은 4)에서 지정한 요약 검색이 실행될 때 검색 실행 시간을 제한하는 것 이다. 이 시간을 너무 길게하면 병렬 처리되는 다음 검색이 느려질 수 있다.

따라서, 이 시간을 짧게하여 검색 프로세스의 종료를 앞당겨 요약 인덱싱의 처리 효율을 올릴 수 있다.
6) 가속화한 데이터 모델 요약은 서치헤더에 저장될까?
간혹 데이터를 빠르게 조회하는 기능이어서 인덱서를 사용하지 않는다고 생각하는 경우가 있다. 가속화한 데이터 모델은 인덱서에 저장된다. 기존에 우리가 저장하는 원시 데이터의 저장소와 똑같은 버킷 형태로 저장이 된다.
docs에 DAS(DataModel Acceleration Summary)이 저장되는 경로는 인덱서 상의 데이터가 저장되는 경로로 나와있다.
$SPLUNK_DB/<index_name>/datamodel_summary/<bucket_id>/<search_head_or_pool_id>/DM_<datamodel_app>_<datamodel_name>
2. Summary Index와 DataModel Accelation의 차이
두가지 모두 데이터를 빠르게 조회하고 싶어 사용하는 방법이다. 하지만 그 용도에는 미세한 차이점이 있다.
1) 용도의 차이
Summary Index는 언제 쓰나?
Summary Index는 보통 사전 분석된 결과를 보고서로 저장하여 이를 주기적으로 확인할 때에 사용된다.
예를 들어 내가 5분동안의 사용자 유입 수, 유입 host별 평균, 표준편차 등에 대한 결과를 주기적으로 보고싶다고 하자.
그러면 이 집계 커맨드를 실행한 결과를 매번 5분마다 내가 직접 실행할 수 없다. 이럴 때 SavedSearch를 이용해 사용자 대신 데이터 집계를 해주고, 사용자가 보려는 결과만을 summary index에 저장하는 것 이다. 말 그대로 요약된 결과만을 확인하고 싶을 때 사용하는게 적절하다.
그렇다면 데이터 모델은 어떨까?
DataModel 가속화는 언제 쓰나?
일단 데이터가 많아야된다. 보통 데이터 모델 가속화는 방화벽 로그에 자주 사용한다. 왜? 제일 많기 때문이다. 사용자가 특정 서비스에 1번 접속을 하더라도 방화벽 로그는 적게는 수십개에서 수백,수천개 생성된다.
따라서 방화벽 로그의 수, src_ip별 통계, dest_ip별 통계를 보려고 하면 쿼리 자체가 돌아가지 않는다. 기본적으로 한번 검색 시 검색 범위가 1시간이라고 하더라도 수십억개를 넘어가는 경우가 많기 때문이다.
따라서 위의 케이스 처럼대용량의 최신의 데이터를 빠르게 검색하고 싶을 때 사용한다.
2) 저장 인덱스 차이
Summary Index는 index
Summary Index가 저장되는 인덱스는 기존의 원시데이터를 수집해 인덱스에 저장하는 방식과 동일하다. 보고서를 통해 저장한 결과는 stash 파일로 임시저장 된 후, SH에서 인덱서로 데이터가 전달되어 지정한 인덱스에 저장된다.
DataModel Acceleration Summary는 tsidx
DAS는 tsidx에 데이터 셋에 저장했던 루트 이벤트 셋의 데이터들이 저장된다.
3) 사용하는 대표적인 커맨드
sistats
- sistats는 일반적으로 사용하는 stats와 사용법은 완전히 똑같다. 하지만 어떤 차이점이 있냐? 세이브 서치를 사용해 Summary Index에 데이터를 저장할 때 검색 쿼리가 시간이 오래걸릴 경우 검색 속도를 높여주는 효과가 있다.
똑같은 stats 구문을 사용해서 요약 인덱싱을 한다면 sistats로 바꾸는 것이 효과적일 것 이다.
## Example
| sistats avg(count) as avg, stdev(count) as stdev by host- 그 외 collect, overlap 등
tstats
-
tstats
stats와 기능은 동일하지만 tsidx데이터를 위한 stats 커맨드라고 보면된다. 사용이 가능한 데이터는 뭐가 있을까?* 데이터 인덱싱 시 저장되는 메타데이터: sourcetype, host * csv, json 형식으로 수집된 데이터, 단 INDEXED_EXTRACTIONS 설정을 수행한다는 가정이다. * prefix() 사용이 가능한 필드 * 데이터 인덱싱 시, field extraction 설정되어 추출된 필드 * 데이터 모델 가속화된 데이터등이 있다. 이 중에서도 데이터 모델로 가속화된 데이터에는 summariesonly 옵션을 사용하여 검색하면 빠르게 검색 결과를 조회할 수 있다!
| tstats 통계함수 from datamodel=datamodel_name summariesonly=true -
그 외 datamodel 등
끝이다.
이번 포스팅은 정말 많은 글을 참고했다. 개념에 굉장히 혼란스러운 부분이 많았고, 직접 커뮤니티에 여러번 질문도 올렸다. 정리하면서 많은 공부가 된 것 같다!
- 참고문서
https://community.splunk.com/t5/Knowledge-Management/How-to-deal-with-datamodel-retention-period-as-summary-range-is/m-p/212062
https://community.splunk.com/t5/Splunk-Enterprise-Security/What-is-the-retention-period-for-summaries-generated-by-Data/td-p/657972
https://community.splunk.com/t5/Reporting/How-far-back-in-time-will-datamodel-data-be-kept/m-p/137257
https://solsys.ca/yielding-optimized-spl-using-term-on-splunk/
https://djangocas.dev/blog/splunk/splunk-search-best-practices-for-better-performance-response-time/
https://community.splunk.com/t5/Splunk-Dev/data-model-acceleration/m-p/525728
https://docs.splunk.com/Documentation/SplunkCloud/9.1.2312/Knowledge/Usesummaryindexing
https://www.slideshare.net/Splunk/splunklive-data-models-101
https://docs.splunk.com/Documentation/Splunk/9.2.1/Knowledge/Acceleratedatamodels#Parallel_summarization
https://docs.splunk.com/Documentation/ITSI/4.18.1/Configure/datamodels.conf
https://stackoverflow.com/questions/66752948/summary-index-in-splunk
https://community.splunk.com/t5/Security/Different-data-acceleration-methods/m-p/343319

프사 얼굴 행복도 160467%