오늘은 Splunk에 데이터가 입력되는 순간부터 검색되는 순간 까지의 데이터 파이프 라인에 대해 알아 볼 것 이다. 스플렁크 공식 문서를 참고하였다.
- 출처: Splunk 공식 Docs
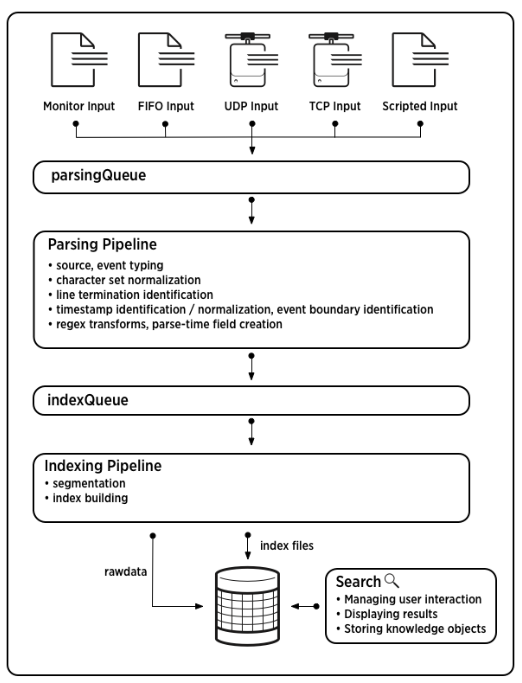
데이터 파이프 라인은 크게 4가지 단계로 이루어져있는데 입력, 파싱, 인덱싱, 검색 과정이다.
1. Inputs
- 먼저 스크립트, 네트워크, 파일 등의 다양한 출처로부터 데이터를 모은다.
- 데이터는 각기 다른 작은 Chunk 단위(64KB)로 나뉘어진다.
- 각각의 데이터 블록(Chunk)에 host, source, sourcetype(메타데이터)가 붙는다.
- 그 다음은 Parsing Queue에 들어가 파싱 과정을 대기한다.
2. Parsing
Parsing Queue에서 나온 데이터는 다음과 같은 순서를 거친다. 이 곳의 문서를 참고했다.
-
Parsing Queue에서 나온다.
-
구문 분석
1. UTF-8 디코딩을 한다.
2. 데이터 스트림을 개별 줄로 나눈다
3. 데이터의 헤더를 파싱한다.
4. 이후 AggQueue에 들어간다. -
병합
5. 특정 요소에 멀티라인이 있다면 합친다.
6. timestamp를 추출한다.
7. 이후 typingQueue에 들어간다. -
타이핑
8. 정규식 규칙에 따라 변환하거나, 함수를 적용한다.
9. IndexQueue에 들어간다.
우리가 포워더에 props.conf, transforms.conf를 통해 데이터를 필터링하거나 정규식을 적용하는 과정이 parsing 과정에서 이뤄진다.
3. Indexing
이 곳의 문서를 참고했다.
- 모든 이벤트를 검색할 수 있는 세그먼트로 나눈다.
- 인덱스 데이터 구조를 만든다.
- raw 데이터와 인덱스 파일을 디스크에 기록한다.
4. Searching
SPL을 통해 검색한다.
5. 그 외, 컴포넌트 별로 일어나는 데이터 파이프 라인
모든 컴포넌트가 위의 과정을 지원하는 것이 아니다. 각 컴포넌트 별로 역할이 제한되어있다. 표로 정리하면 다음과 같다.
| 데이터 파이프 라인 | 지원 컴포넌트 |
|---|---|
| Inputs | Indexer, Universal Forwarder, Heavy Forwarder |
| parsing | Indexer, Heavy Forwarder |
| Indexing | Indexer |
| Searching | Indexer, Search Head |
끝이다.
