splunk를 알아보려면 어떤 요소가 있고 그것이 어떤 구조로 이뤄져있는지 파악해야 하는데, 이번 시간에는 어떤 요소가 있는지 알아볼 것 이다.
참고 문서는 Splunk Docs이다.
1. Splunk Component
splunk의 구성 요소는 아래와 같다. 아래의 구성요소는 모두 같은 인스턴스로 설치된다. (Universal Forwarder) 이후 구성 정보(.conf등)를 변경하여 아래의 요소로서 사용되는 것 이다.
Universal forwarder
Indexer and indexer clusters
Search head and search head clusters
Deployment server
Deployer
Cluster master
License master
Heavy forwarder
Monitoring Console1) Universal Forwarder
포워더는 2가지 종류로 나뉘어지는데 첫번째가 유니버셜 포워더이다. 유니버셜 포워더는 는 지정된 로그에서 데이터를 수집하기 위해 각 애플리케이션, 웹 또는 기타 유형의 서버(다양한 Linux 또는 Windows 운영 체제)에 설치되는 Splunk Enterprise의 무료 버전이다.
따라서 실제 운영할 때에는 Splunk Enterprise인스턴스가 아닌 별도의 설치파일을 설치해준다.
파일 혹은 서버를 모니터링하고, 이를 저장하기위해 데이터를 Splunk 인덱서에 전달한다.
2) Indexer
인덱서는 데이터가 저장되는 인덱스를 생성하고 관리하는 Splunk 구성 요소이다. 인덱서는 두 가지 주요 기능을 수행한다.
- 포워더나 기타 데이터 소스로부터 받은 데이터를 구문 분석하여 인덱스에 저장
- 검색 요청에 대한 응답으로 인덱싱된 데이터를 검색하고 반환
3) Indexer cluster
인덱서 클러스터는 시스템이 모든 데이터의 여러 복사본을 보관할 수 있도록 서로의 데이터를 복제하도록 구성된 인덱서 그룹이다.
위의 프로세스를 인덱서 복제라고 한다. 인덱서 클러스터는 여러 개의 동일한 데이터 복사본을 유지함으로써 데이터 손실을 방지하는 동시에 검색을 위한 데이터 가용성을 높여준다.
간략하게 가용성을 높이기 위해 복사본을 여러 서버에 저장하고 있는 인덱서 서버의 그룹이라고 보면 된다.
4) Search head
사용자가 SPL로 검색 요청을 보내는 Splunk Web이라는 웹 기반 사용자 인터페이스를 제공하고, 이러한 요청을 처리하는 서버이다. 서치헤더로부터 시작되는 검색 과정은 아주 간략하게 아래 2단계이다.
- 사용자(또는 보고서 또는 대시보드)가 시작한 검색 요청은 요청된 데이터를 찾아 반환하기 위해 하나 이상의 인덱서로 전송된다. 그런 다음 검색 헤드는
- 사용자에게 표시하기 위해 반환된 데이터의 형식을 지정하여 변환해준다.
5) Search head Cluster
검색 헤드 클러스터는 더 많은 수의 사용자에게 서비스를 제공하고 검색 요청 서비스를 위한 중복성을 제공하기 위해 함께 작동하도록 구성된 여러 검색 헤드 그룹입니다.
검색 헤드 클러스터는 아래와 같은 이유(장점)으로 사용한다.
-
수평 확장이 가능하다: 사용자 수와 검색 로드가 증가하면 클러스터에 새 검색 헤드를 추가할 수 있다. 또한, 검색 헤드 클러스터를 사용자와 클러스터 사이에 로드 밸런서를 결합하면 사용자와 검색서버 간 네트워크 구성이 깔끔해진다.
-
고가용성: 검색 헤드가 작동 중지되면 동일한 검색 세트를 실행하고 클러스터의 다른 검색 헤드에서 동일한 검색 결과에 접근할 수 있다.
-
No single point of failure: 검색 헤드 클러스터는 동적 캡틴을 사용하여 클러스터를 관리합니다. 캡틴이 작동 중지되면 다른 구성원이 자동으로 캡틴으로 선정된다. 따라서 하나의 포인트로 인해 실패가 발생하지 않는다.
6) Deployment server
배포 서버는 여러 Splunk 구성 요소에 대한 중앙 집중식 구성 관리자 역할을 하지만 실제로는 UF를 관리하는 데 사용되는 Splunk Enterprise 인스턴스이다.
예를들어 엔터프라이즈 환경의 서버에 설치될 수 있는 수백 또는 수천 개의 UF는 모두 정기적으로 배포 서버에 구성 정보 변경을 수행하여 새로운 구성 정보를 가져올 수 있으므로 이러한 모든 UF 관리 작업이 훨씬 편리해진다.
7) Deployer
Splunk 앱 및 기타 특정 구성 업데이트를 검색 헤드 클러스터 구성원에 배포하는 데 사용되는 Splunk Enterprise 인스턴스이다. 대표적으로 아래 3가지의 용도로 사용된다.
- 비클러스터 인스턴스 및 검색 헤드 풀에서 검색 헤드 클러스터로의 앱 및 사용자 구성 마이그레이션을 처리한다.
- 검색 헤드 클러스터 구성원에 기준 앱 구성을 배포한다.
- 이는 복제되지 않고 런타임이 아닌 구성 업데이트를 모든 검색 헤드 클러스터 구성원에 배포해준다.
* 혼동의 여지가 있다. 배포자(Deployer)와 배포서버(Deployment Server)는 다르다. 배포자는 검색 헤드 클러스터에 앱을 배포하는 데 사용되고, 배포 서버는 앱을 포워더에 배포하는 데 사용된다.
8) Cluster master
인덱싱 클러스터의 활동을 조정하는 Splunk Enterprise 인스턴스이다.
인덱스 클러스터에서는 데이터가 여러 인덱서 인스턴스에 분산되어 데이터의 중복성을 제공한다. 클러스터 마스터는 해당 데이터가 배포되는 방식을 제어하고 검색 헤드가 특정 데이터 집합을 찾기 위해 검색 요청을 보낼 위치를 알 수 있도록 도와준다.
9) License master
인덱서로 가기 전 모든 데이터가 라이센스 마스터를 통과해 데이터가 라이센스화 된다. (사용량 측정이 된다.) 독립 실행형 인스턴스가 아닌 이상 라이센스 마스터가 필요하다.
10) Heavy forwarder
헤비 포워더 는 다른 포워더나 데이터 소스로부터 데이터를 수신하고, 인덱싱을 위해 데이터를 구문 분석, 인덱스 및/또는 다른 Splunk 인스턴스로 보낼 수 있는 Splunk Enterprise 인스턴스이다.
헤비 포워더는 수신된 데이터를 구문 분석하고 수신된 데이터의 소스 및 유형에 따라 인덱싱을 위해 다양한 대상으로 라우팅하거나 필터링이 가능한 포워더이다.
11) Monitoring Console
모니터링 콘솔은 모니터링 도구이다. 각 컴포넌트 들의 행위를 매니징한다. 전체 네트워크 정보 및 성능정보를 확인할 수 있는데, 어떤 Search가 리소스를 잡아먹는지? 이슈가 없는지? 전체적인 시스템에 Health Check를 한다고 보면 된다.
2. 위의 구성정보를 포함한 예시
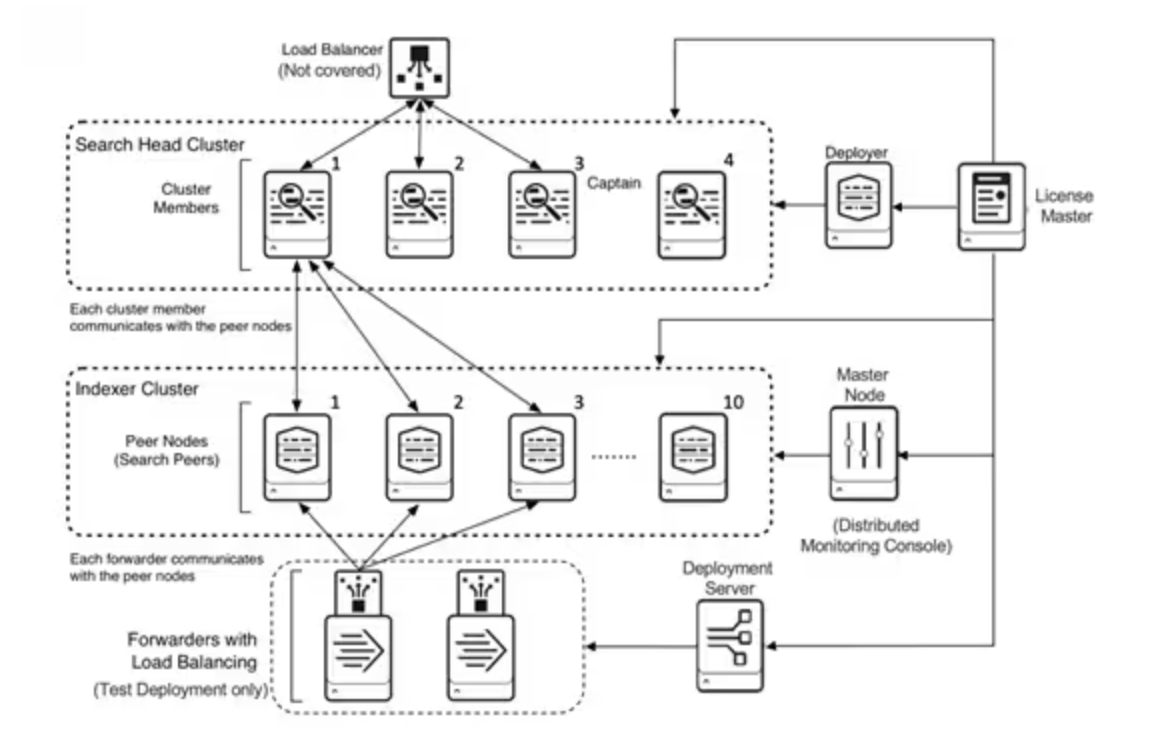
1에서 확인한 요소들을 반영하여 기본적인 구성도를 나타내면 위와 같다.
그림출처는 이 곳이다.
끝이다.
