참고한 문서는 git splunk sdk
그리고 splunk 문서이다.
custom search command 를 개발하다가 Reporting command 를 개발하는데, records를 못받아오는 문제점이 생겼다. 내가 사용했던 SPL의 구조는 다음과 같다.
index=velog*munang sourcetype=munang_velog
| customsearch 여기서, 원시 데이터를 검색하고 바로 customsearch command를 사용했는데, 원시 데이터를 못받아오고 있었다. (index=velog*munang sourcetype=munang_velog 를 검색한 결과가 | customsearch로 못넘어가는 현상)
그런데 이렇게 하니 해결이 되었다.
index=velog*munang sourcetype=munang_velog
| sort 0 -munang_values
| customsearch sort함수를 집어넣으니, 해결이 된 것이다. 이것 저것 시도를 하다가 해결이 됐는데 sort함수를 사용하고 해결이 됐을 때 이 문제가 메모리 문제임을 직감했다.
reporting command 의 구조는 map, reduce 함수 2가지로 실행되는데, 나는 reduce함수만 사용하고 있었기 때문에 이러한 문제가 발생했다.
주말 내내 쉬면서 생각하다가, Reporting Command의 소스코드를 보면서 깨닳았다.
1. Splunk의 명령어가 실행되는 과정(MapReduce를 중심으로..)
Splunk의 명령어가 실행되는 프로세스는 MapReduce방식으로 이뤄져있다. Map 방식은 본질적으로 병렬 실행 방식으로 데이터를 수집하는 작업이고, Reduce 기능은 "map" 기능이 제공한 결과를 가져와 추가 처리를 수행하는 작업이다.
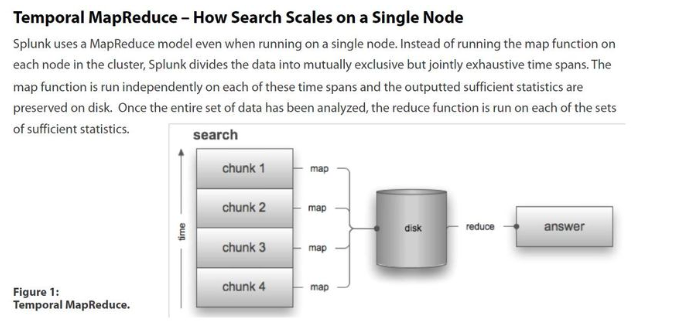
정말 간단하게 쿼리를 예를 들어서 확인해보면 다음과 같다.
source src_ip=192.168.1.1
| stats c by host1. Map
위의 쿼리에서 source src_ip=192.168.1.1 쿼리 부분은 map이 담당한다. 최상단에 위치한 검색 쿼리는 Splunk가 데이터를 수집하는 데 사용하는 기준이 되고, 이 검색은 인덱스에서 이 기준과 일치하는 모든 이벤트를 반환하게 된다.
이때, 이 Map의 기능을 Splunk에서는 인덱서가 담당하고 있다.
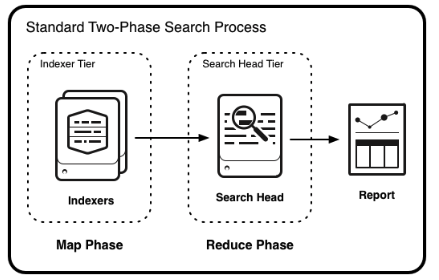
2. Reduce
이후, | stats c by host 이 부분은 reduce가 담당한다. map 이 가져온 결과를 목적에 맞게 변환하고 처리하는 부분이다.
이떄, 이 Reduce의 기능을 서치헤더가 담당하고 있다.
2. Reporting command 의 Map Reduce
Reporting command는 데이터를 이용해 변환해서 사용자에게 특정한 데이터 형식으로 보여주는 역할을 가진다.
이때 이 Reporting commands의 과정은 map과 reduce 과정으로 이뤄져 있다. 즉 인덱서에서 실행되는 부분과 검색 헤더에서 실행되는 부분으로 나뉘어져 있다는 의미이다.
따라서, map을 사용하지 않으면 reduce함수에서 오버라이딩 된 내용만 실행됨으로 최상단 search에서 내려온 결과를 받아올 수 없게 된다.
1. 왜 이렇게 나뉘어져 있을까?
왜 이렇게 나뉘어져 있을지에 대해 고민해봤는데, 고민 시간은 길지 않았다. 말 그대로 데이터를 변환해서 보여주는 역할을 하고있다. 즉 전체 데이터가 필요하다.
이러한 전체 데이터를 처리하는 과정은 서치헤더에서만 담당할 수 있는 부분, 인덱서에서 담당할 수 있는 부분으로 나눈 후 필요에 따라 오버라이딩 해서 사용하여
인덱서의 부하를 최소화 하게끔 의도한 것 같다.
2. 사용하려면
-> 실제 적용해봤는데, 적용되지 않았다. Splunk Community에 질의 글을 올려서 답변을 기다리는 중이다. 답변이 오면 글을 수정하겠다. (인덱스가 SH에 있을 경우 잘됨 하지만 IDX에서 받아오는 인덱스로는 안되고 있다^^..)
reduce는 기본적으로 재정의 해서 사용할 것이다. 다만, map함수를 사용하게끔 하려면 별도의 옵션을 넣어줘야 하는데, 다음과 같이 넣어주면 된다.
@Configuration(requires_preop = True)
class TestReportingCommand(ReportingCommand):그리고, commands.conf 파일에 다음과 같이 넣어준다.
requires_preop=true이렇게 Configuration데코레이터 옵션에 requires_preop 옵션을 활성화 해주면 된다.
이것을 설정해주지 않으면 Splunk는 이를 건너뛸 수 있는 최적화로 간주한다. 따라서 이 옵션을 설정해줘야 최상단 search 에서 내려온 데이터들을 records로 받아서 처리해줄 수 있다.
내가 sort함수를 추가해서 실행이 된 이유는, 데이터들이 sort함수를 실행해서 모두 SH상의 메모리로 올라가 있었기 때문이다. (sort함수는 SH에서 실행되는 커맨드임, 기본적으로 streaming 한 명령어들만 indexer에서 실행된다.)
아무튼 이러한 결론으로 인해 내 의문은 해소되었다...
command 타입의 동작 방식과 기본적으로 어떻게 데이터가 실행되는지 맥락을 알고있다면 충분히 해결할 수 있는 문제였다.
다음에는 splunk sdk를 분석하는 시간을 갖도록 해야겠다.
