Splunk의 필드 추출은 웹에서 진행할 수도 있다. 하지만, 보통 splunk 에서 필드를 추출하는 단위는 하나의 이벤트이다.
웹로그 상의 이벤트가 됐던, 어떤 네트워크 트래픽이 됐던 하나의 사건 단위여야 한다.
그런데, 터미널에서 우리가 실시간으로 top 명령어를 입력한 결과를 받아온다면?
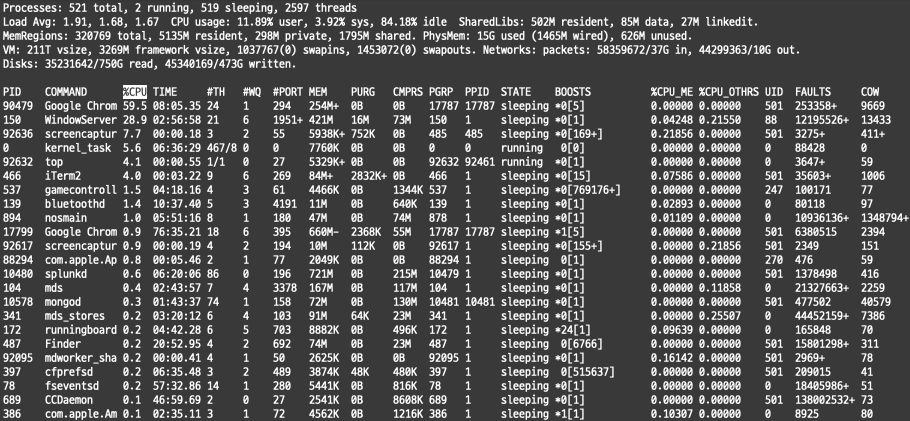
top을 입력한 그 결과 자체가 하나의 이벤트로 되는데 이런 경우에는 어떻게 파싱룰을 적용해야 할지 난감하다.
이럴때 명령어를 사용해서 본다. multikv 명령어 이다.
오늘은 Splunk 유튜브와 공식 홈페이지를 참고했다.
1. multikv는 distributed streaming command
이 명령어는 기본적으로 인덱서에서 바로 실행이 가능한 streaming 명령어이다.
즉 사용할때는 최상단 search 이후 바로 사용하거나, 앞에도 streaming 명령어를 사용한 후에 사용할 수 있다.
(앞에 다른 transforming, dataset command, non-streaming한 명령어를 사용하면 streaming 명령어에만 사용이 가능하다며 오류를 뿜어낼 것 이다.)
또한, 그래서 강력하다. streaming 하기 때문에 인덱서에서 바로 실행해서 가져올 수 있기 때문에 SH에 부담을 줄여준다.
2. 사용 예
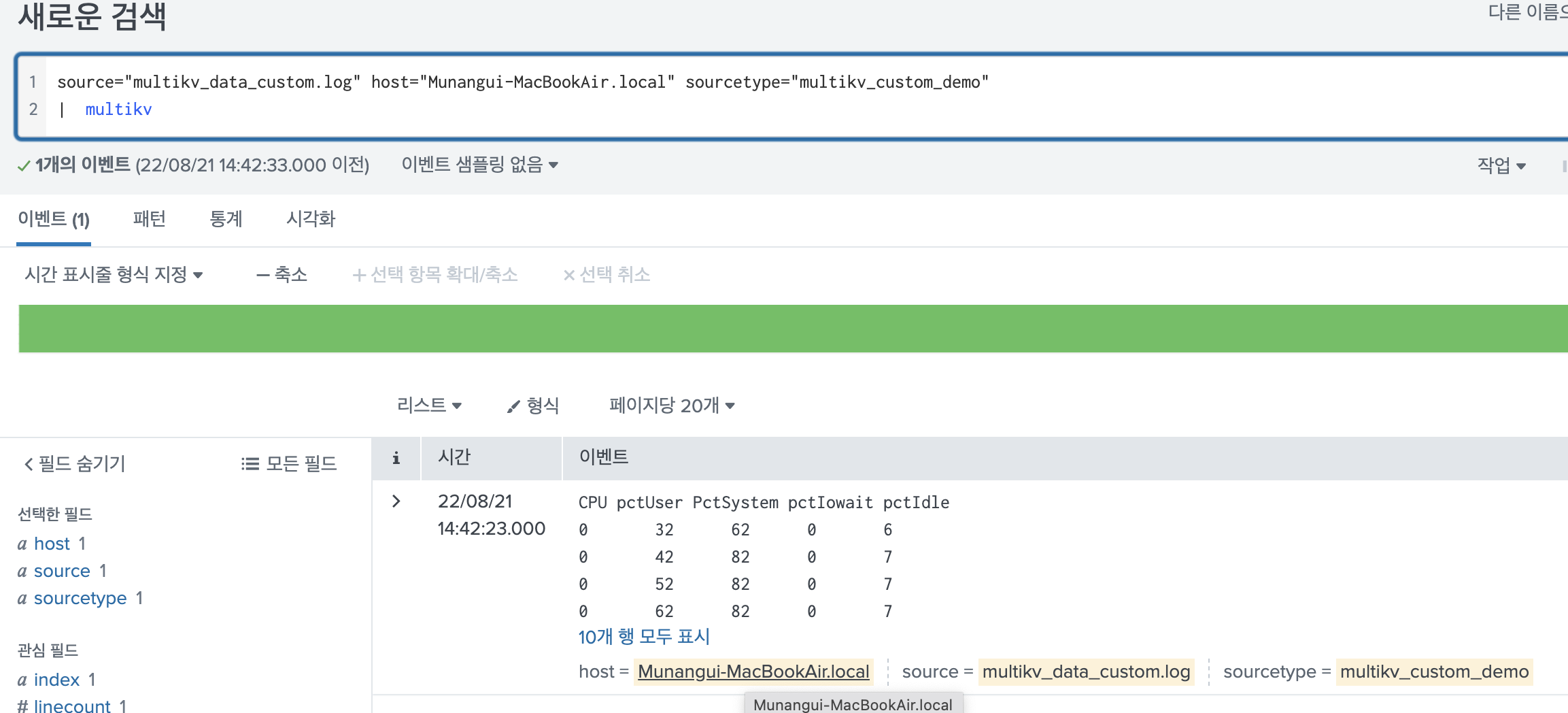
다음과 같은 테이블 형식의 이벤트가 있다고 하면, 그대로 뒤에 multikv 명령어를 사용해주면 된다.
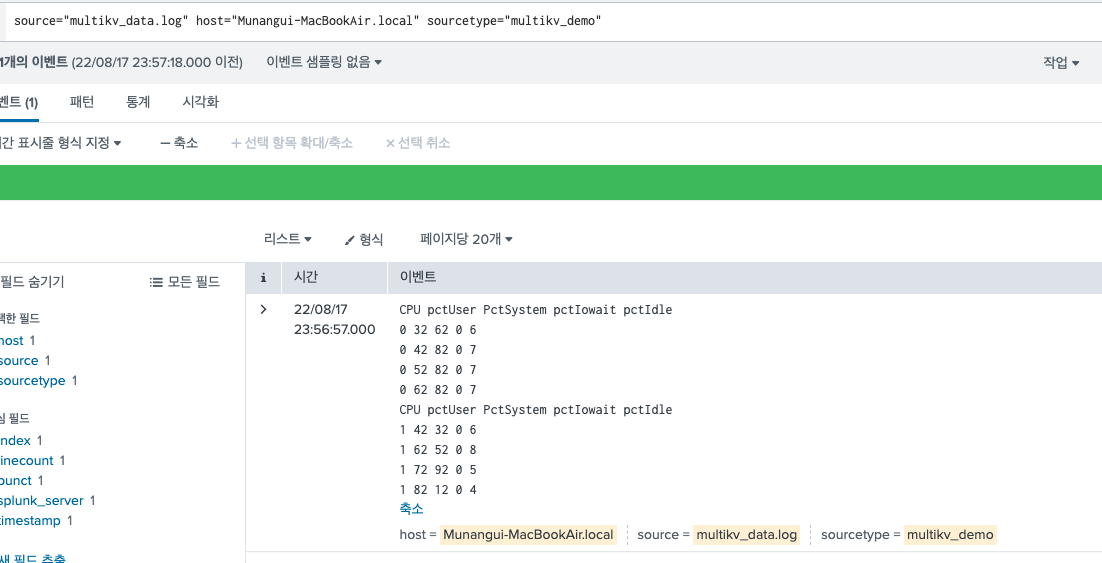
source="multikv_data.log" host="Munangui-MacBookAir.local" sourcetype="multikv_demo"
| multikv 그러면 이렇게 각각 필드가 추출되어 있는 결과를 확인할 수 있다.
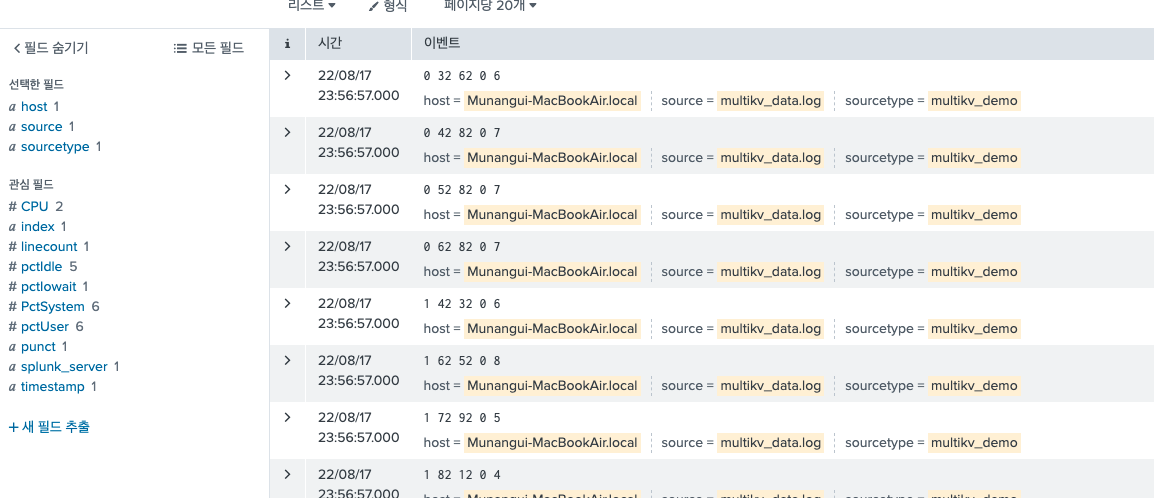
1) 옵션
index=main | multikv copyattrs=false
index=main | multikv copyattrs=true
index=main | multikv copyattrs=true fields pctIdle,pctIowait
index=main | multikv filter "1 "
index=main | multikv forceheader=2
index=main | multikv noheader=t
index=main | multikv rmorig=false
- copyattrs=false
index=main | multikv copyattrs=false기본 옵션이 true, 이다. 데이터의 형태가 테이블일때 테이블 각각의 row를 하나의 이벤트로 추출해준다는 의미이다. 그래서 multikv 명령어를 사용했을 때, 이벤트가 각각 분리 되어서 나오게 된다.
그런데 false를 사용하면, 아무런 결과가 나오지 않을 때가 있다. 그 이유는 _time 필드가 없을 때 이런 결과를 확인할 수 있다. splunk는 기본적으로 _time을 참조하여 이벤트를 뿌려주기 때문에 _time 필드가 없으면 이벤트를 나열할 수 없다.
- filter "1 "
말 그대로 필터이다.1이 포함된 row만 추출해주게 된다. - forceheader=2
테이블 데이터의 헤더(컬럼)을 2번째 컬럼으로 하겠다는 의미이다. 내가 가진 샘플 데이터로 이 옵션을 적용하면 이렇게 나온다.
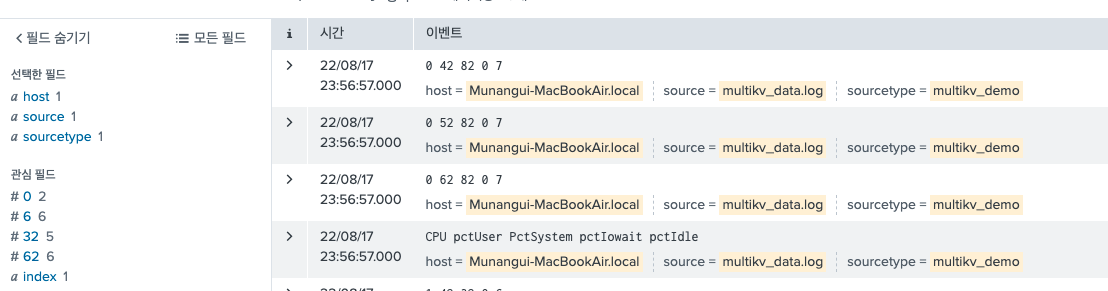
원래 이벤트는 이렇게 되어있었고, 이 이벤트의 2번째 row가 헤더가 되는 것이다.
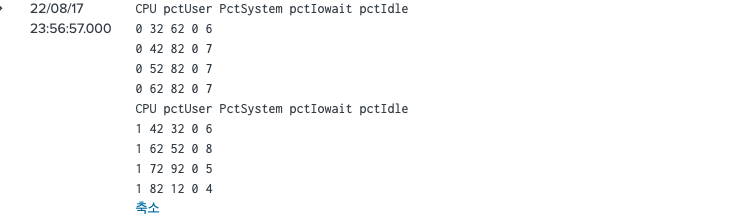
-
noheader=t
노 헤더 옵션을 주면 말 그대로 컬럼 명이 없이 단순히 데이터를 row단위로 출력해준다.
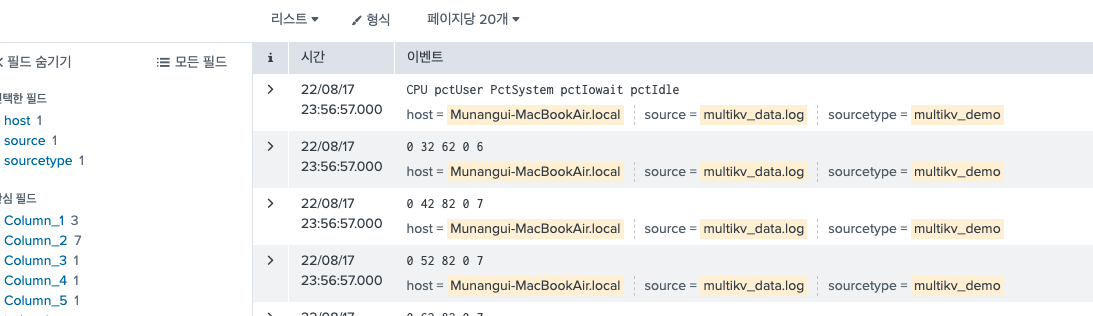
-
rmorig=false
원래 이벤트를 보존하면서, row의 이벤트도 따로따로 하나씩 출력해준다.
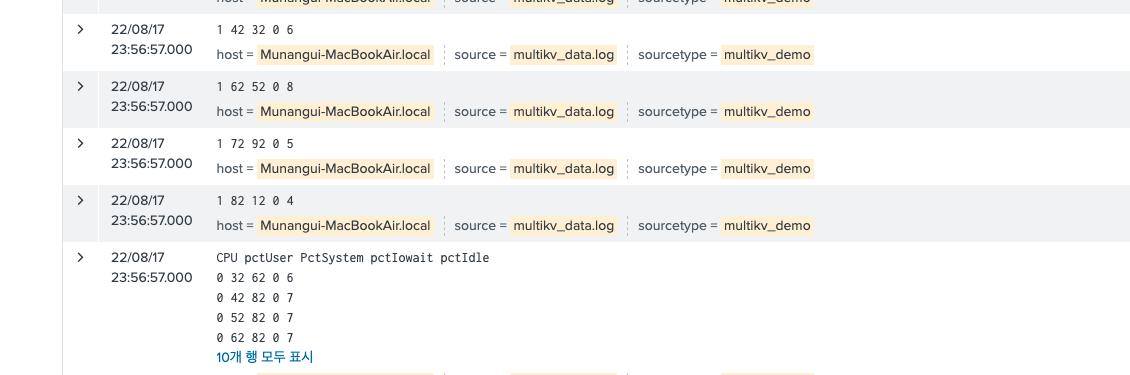
3. multikv.conf
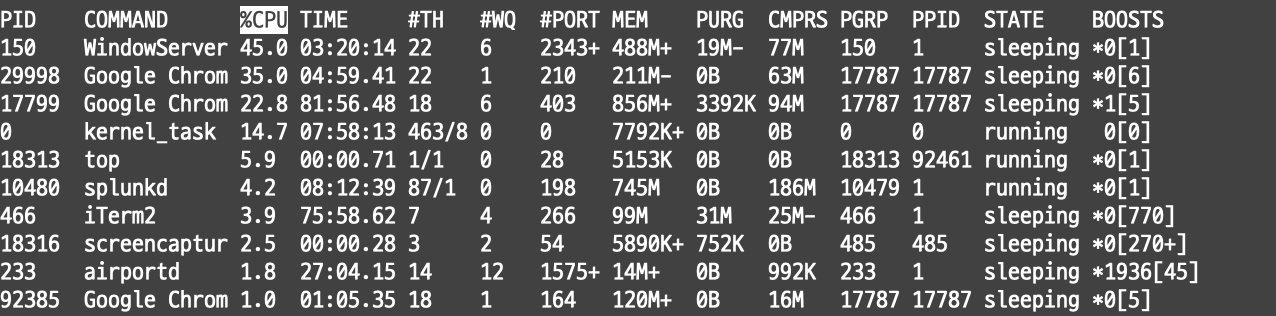
하지만 보통의 데이터들은 위와 같이 바로바로 multikv 명령어가 적용되지 않는 경우가 있다. top 명령어만 해도, 데이터의 구조가 컬럼 목록은 #으로 이뤄져 있고, 데이터는 탭으로 이뤄져 있다.
구분자가 매우 다양하기 때문에 이를 위해서 스플렁크에서는 multikv를 커스터마이징 할 수 있는 컨피그 파일을 제공한다.
이번 예시는 데이터의 헤더(컬럼)는 구분자가 스페이스로 되어있고, 데이터 row에는 구분자가 탭키로 이뤄져 있는 소스타입으로 테스트를 해본다.
다음과 같이 multikv 명령어를 입력하게 되면, 기존에는 하나의 row로 떨어져 보였던 데이터들이 그대로 나오게 된다.
이러한 현상을 해결하기 위해 multikv.conf를 편집할 수 있다.
1. 구간별 설명
# pre | optional: info/description (for example: the system summary output in top)
# header | optional: if not defined, fields are named Column_N
# body | required: the body of the table from which child events are constructed
# post | optional: info/description
#---------------------------------------------------------------------------------------
# NOTE: Each section must have a definition and a processing component. See
# below.
[<multikv_config_name>]
* Name of the stanza to use with the multikv search command, for example:
'| multikv conf=<multikv_config_name> rmorig=f | ....'
* Follow this stanza name with any number of the following setting/value pairs.예시를 top 명령어로 빗대어 config파일의 구간별 설명을 하겠다.
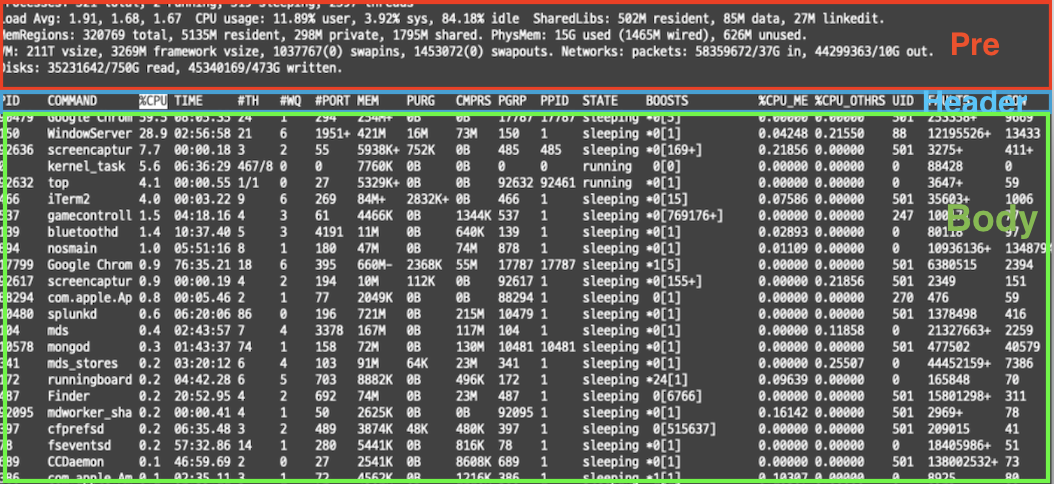
- pre: top 명령어를 사용했을 때 나오는 이 결과에서 실제 우리가 확인하는 테이블 정보는 PID컬럼부터 COW 컬럼이 있는 부분이다. 위의 Processes~Disks까지의 데이터는 multikv.config에서는 pre 라고 표현한다.
- header: 그 다음, 데이터의 헤더 부분(컬럼)을 명시한 구간은 Header 라고 표현한다.
- body: 실제 데이터 row단위가 모여있는 부분을 Body 라고 한다.
- post: 추가로 post 옵션도 있는데, 이것은 이벤트 단위를 구분하는 구분자 라고 보면 된다.
보통 예를 들어 top 명령어 결과를 수집한다고 하면 이 결과를 .log데이터에 일렬로 쌓아두게 되는데 이떄 이 이벤트 하나하나를 어떤 단위로 구분할지에 대해 명시하는 옵션이라고 생각하면 된다.
그리고 실제 conf 파일에 이 구간별 파싱 룰을 적용할 때에는 Section processing에 나와있는 내용을 기준으로 룰을 적용할 수 있다. 이 내용은 공식 홈페이지를 참고하길 바라며, 아래에는 예시 데이터를 기준으로 구간별 파싱을 적용한 예시 conf 파일 내용이다.
(1) Pre Section
Processes: 519 total, 4 running, 515 sleeping, 2612 threads 14:52:28
Load Avg: 2.02, 1.80, 1.74 CPU usage: 6.43% user, 4.79% sys, 88.77% idle SharedLibs: 505M resident, 69M data, 22M linkedit.
MemRegions: 344269 total, 5057M resident, 288M private, 1730M shared. PhysMem: 15G used (1649M wired), 274M unused.
VM: 212T vsize, 3269M framework vsize, 1149321(0) swapins, 1578720(0) swapouts. Networks: packets: 71595731/43G in, 55270108/12G out.
Disks: 45375023/918G read, 56489644/582G written.
PID COMMAND %CPU TIME #TH #WQ #PORT MEM PURG CMPRS PGRP PPID STATE BOOSTS %CPU_ME %CPU_OTHRS UID FAULTS COW
466 iTerm2 25.3 76:22.61 7 4 265- 139M+ 31M+ 22M 466 1 sleeping *0-[824] 0.57150 0.88748 501 78990+ 1011
top 명령어를 사용했을 때 나오는 이 결과에서 실제 우리가 확인하는 테이블 정보는 PID컬럼부터 COW 컬럼이 있는 부분이다.
위의 Processes~Disks까지의 데이터는 multikv.config에서는 pre option이라고 표현한다.
Splunk 에서는 이부분을 완전히 버리고, 나머지 테이블 정보만 취할 수도 있고 이부분을 별도로 처리해서 노출시켜줄 수 있다.
[top_mkv]
# pre table starts at "Process..." and ends at line containing "PID"
pre.start = "Process" -> pre 내용이 시작하는 부분
pre.end = "PID" -> pre 내용이 끝나고 나오는 바로 다음 토큰
pre.ignore = _all_ -> 이 부분을 생략할 것인지에 대한 옵션이다. 특정 regex에 필터링 되는 내용만 생략할 수도 있다.
생략하지 않으려면, 이 옵션을 사용하지 않으면 된다. (2) Header Section
헤더 부분은 실제 데이터의 정보를 컬럼으로 기재한 부분이다.
Disks: 45375023/918G read, 56489644/582G written.
PID COMMAND %CPU TIME #TH #WQ #PORT MEM PURG CMPRS PGRP PPID STATE BOOSTS %CPU_ME %CPU_OTHRS UID FAULTS COW --> 이 부분
466 iTerm2 25.3 76:22.61 7 4 265- 139M+ 31M+ 22M 466 1 sleeping *0-[824] 0.57150 0.88748 501 78990+ 1011이 부분도 실제 conf 파일에 적용하려면 다음과 같다.
# specify table header location and processing
header.start = "PID" -> 헤더가 시작하는 부분의 토큰
header.linecount = 1 -> 헤더가 1줄이면 1, 여러 줄이면 2~를 기재해서 헤더를 분리할 수 있다.
header.replace = "%" = "_", "#" = "_" -> 헤더에서 %으로 시작하는 부분은 _으로 치환하고, #으로 시작하는 부분도 _으로 치환하겠다는 의미이다.
header.tokens = _tokenize_, -1," " -> 한 row당 구분하는 구분자를 스페이스 키로 할 것이며, -1은 전체를 토큰으로 분할하겠다는 의미이다. 토크나이즈의 옵션은 Section processing에 나와있으니 잘 참고하길 바란다.
- 추가 참고사항
- 글을 쓰다가 갑자기 언더스코어_의 의미에 대해 궁금해졌다.. 왜 # 에서 그냥 빈 문자열로 했을 수도 있는데 굳이_으로 한건지 좀 위화감이 들었다.
스플렁크에서_는 내부에서 사용하는 인덱스를 구분할때 잘 사용하기도 하고 주로_time, 이나_raw와 같이 원시적인 필드에 자주사용한다. 그런데 찾아보니 데이터를 구분할 때에도 가끔씩 쓰이는 듯 했다. 확인해보니 다음과 같은 내용이 있다.- 이벤트를 분리할때 Major breaker와 Minor breaker가 있는데, 이중에 Major breaker는 큰 단위의 컬럼을 분할할 때에 사용된다. 예를들어서
[13/Aug/2019:18:22:16] "GET /oldlink?itemId=EST-14&JSESSIONID=SD6SL7FF7ADFF53113 HTTP 1.1"이런 문자열에서 [], "" 등등은 Major breaker이다. - 이때, Minor breaker는 Major breaker로 분할한 이후 추가 분할할때 사용하는 문자열인데, 여기에
_가 포함되어있다. 추가로 다음과 같은 문자열이 사용된다. A period .,A forward slash /,A double backslash \\,A colon :,The equal sign =,The AT sign @,The pound sign #,The dollar sign $,The percent sign %,The dash sign -,The underscore sign _- 이런식으로 위의 예시에서는 기존의 필드와 구별해서 replace 되었음을 명시하기 위해
_으로 사용한게 아닐까 추측했다. (기본적인 구분자 중 하나이기 때문에 검색 결과에는 생략된다.)
- 이벤트를 분리할때 Major breaker와 Minor breaker가 있는데, 이중에 Major breaker는 큰 단위의 컬럼을 분할할 때에 사용된다. 예를들어서
(3) Body Section
body는 실제 데이터 정보 이다.
Disks: 45375023/918G read, 56489644/582G written.
PID COMMAND %CPU TIME #TH #WQ #PORT MEM PURG CMPRS PGRP PPID STATE BOOSTS %CPU_ME %CPU_OTHRS UID FAULTS COW
466 iTerm2 25.3 76:22.61 7 4 265- 139M+ 31M+ 22M 466 1 sleeping *0-[824] 0.57150 0.88748 501 78990+ 1011 --> 이 부분 # table body ends at the next "Process" line (ie start of another top) tokenize
# and inherit the number of tokens from previous section (header)
body.end = "Process" -> Body가 끝난 후 다음에 오는 이벤트의 최초 토큰
body.tokens = _tokenize_, 0, " " -> 이전 세션에서 상속한다는 의미 즉 헤더의 옵션과 동일하다는 의미2. 실습 데이터
아까 확인했던 이 데이터에서는 어떻게 conf 파일을 작성해야 할까?
[multikv_for_test] -> multikv 명령어의 옵션으로 넣어줄 conf파일의 네임이다.
header.start="CPU"
header.linecount=1
header.tokens=_tokenize_, -1," "
body.end="CPU"
body.tokens = _tokenize_, -1, " "
이렇게 되면 된다!
그럼 이 conf 파일을 작성 후, splunk를 restart 시킨다. ( 컨피그 파일을 적용할 때에는 반드시 재시작을 해줘야 한다. )
source="test.log" host="Munangui-MacBookAir.local" sourcetype="top_custom.log"
| multikv conf=multikv_for_test완료이다!
