오늘은 Splunk의 검색 팩터에 대해 다룬다. 이전에 Splunk Search Head Clustering을 구성할 때에 복제 팩터에 대해 언급한 적이 있다. 바로 이 부분이다.
splunk init shcluster-config -auth <username>:<password> -mgmt_uri <URI>:<management_port> -replication_port <replication_port> -replication_factor <n> -conf_deploy_fetch_url <URL>:<management_port> -secret <security_key> -shcluster_label <label>위의 명령어에서 클러스터의 구성 정보를 지정할 때에 복제 팩터를 지정해 줘야 한다.
init shcluster-config: sh 구성을 초기화 한다.
auth <username>:<password>: 현재 명렁어를 실행하는 서버의 사용자와 PW를 입력
mgmt_uri <URI>:<management_port>: 현재 명렁어를 실행하는 서버의 관리 uri를 입력한다.
replication_port <replication_port>: sh 클러스터 멤버는 항상 서로 커뮤니케이션을 하는데, 이때 사용할 포트 번호이다. (항상 접근 가능해야 한다)
replication_factor <n>: 현재 Splunk SH시스템에 몇개의 복제 팩터를 지정하냐에 대한 요소이다. 디폴트는 3개이다.
conf_deploy_fetch_url <URL>:<management_port>: deployer 서버의 주소와, 관리포트이다.
secret <security_key>: 기존에 SH 클러스터링에 구성된 비밀번호이다. 이것은 다른 SH 구성원의 $SPLUNK_HOME/etc/system/local/server.conf 경로에 shclustering 스탠자를 보면 암호화된 pass4SymmKey 비밀번호를 확인할 수 있고, 이 값을 그대로 사용해주면 된다.
shcluster_label <label>: 기존에 SH 클러스터링에 구성된 <$SPLUNK_HOME/etc/system/local/server.conf> 경로에 shclustering 스탠자의 shcluster_label 라벨값이다.이때 디폴트로 3개의 복제 팩터를 설정하는데, 처음에는 3개의 복제팩터를 구성한다는 것이 무슨의미지? 뭘 복제하지? 싶었다.
애초애 Search Head Cluster로 대부분의 날리지 데이터가 복제되는데 왜 복제 팩터가 필요한 것 인지 이해가 안됐다.
찾아보니 아래와 같았다.
1. Search Artifact 의 복제본 수 = Replication Factor
검색헤드 클러스터링을 설정할 때에 지정하는 복제 팩터의 수는 검색 아티팩트의 복제본 수와 같다. 즉, 검색 아티팩트를 몇개나 복제해둘거냐? 에 관한 옵션이다.
+) 추가로, 위의 복제 팩터에서는 예약되어있는 Saved Search의 검색 아티팩트를 복제한다. 일반적인 Ad Hoc검색(검색 창에서 시간을 지정하고 검색하는 것) 결과에 대한 검색 아티팩트를 복제하지 않는다.
2. Search Artifact란?
완료된 검색 작업의 메타 정보와 검색 결과를 검색 아티팩트라고 한다. 실제로 Splunk의 $SPLUNK_HOME$/var/run/splunk/dispatch/ 하위에서 저장된 검색 아티팩트를 확인할 수 있다.
우리가 검색한 결과에서는 아래의 검색 결과와 작업 검사기에서 나오는 정보이다.
-
검색 결과
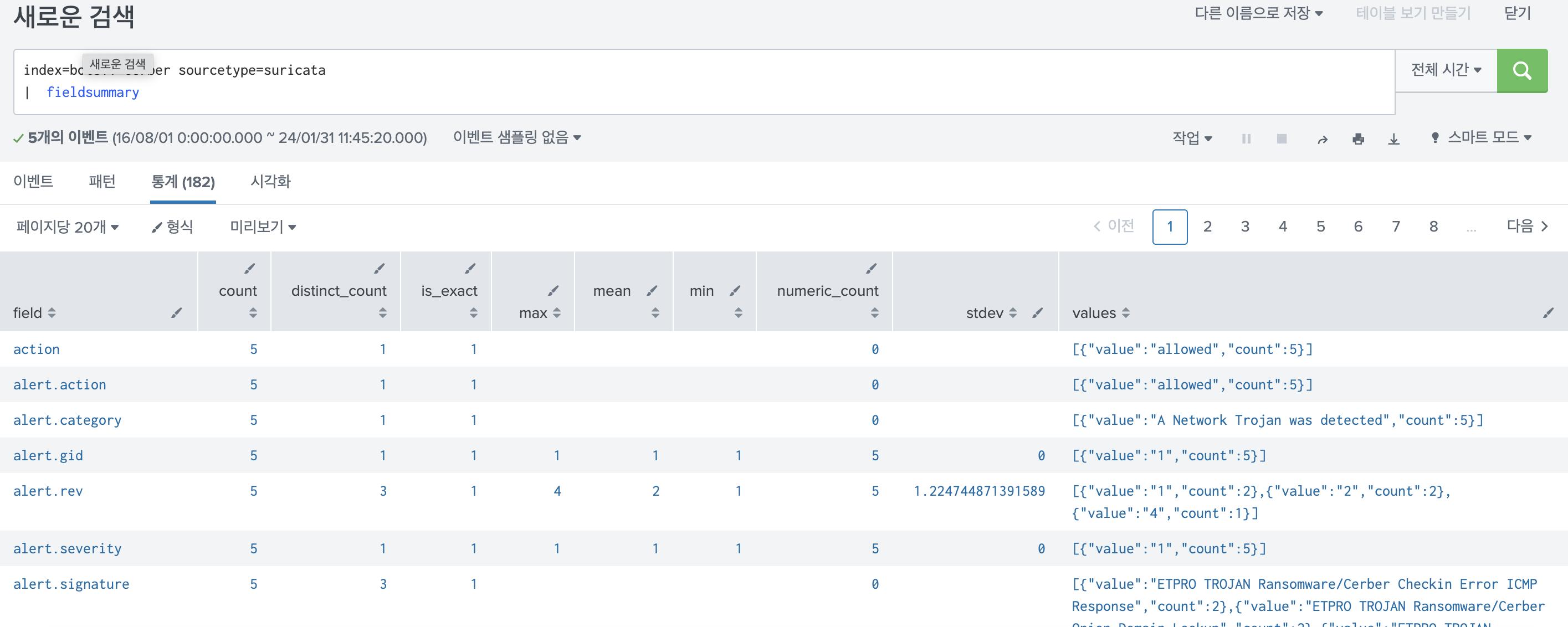
-
작업 검사기 정보 - 검색의 메타정보
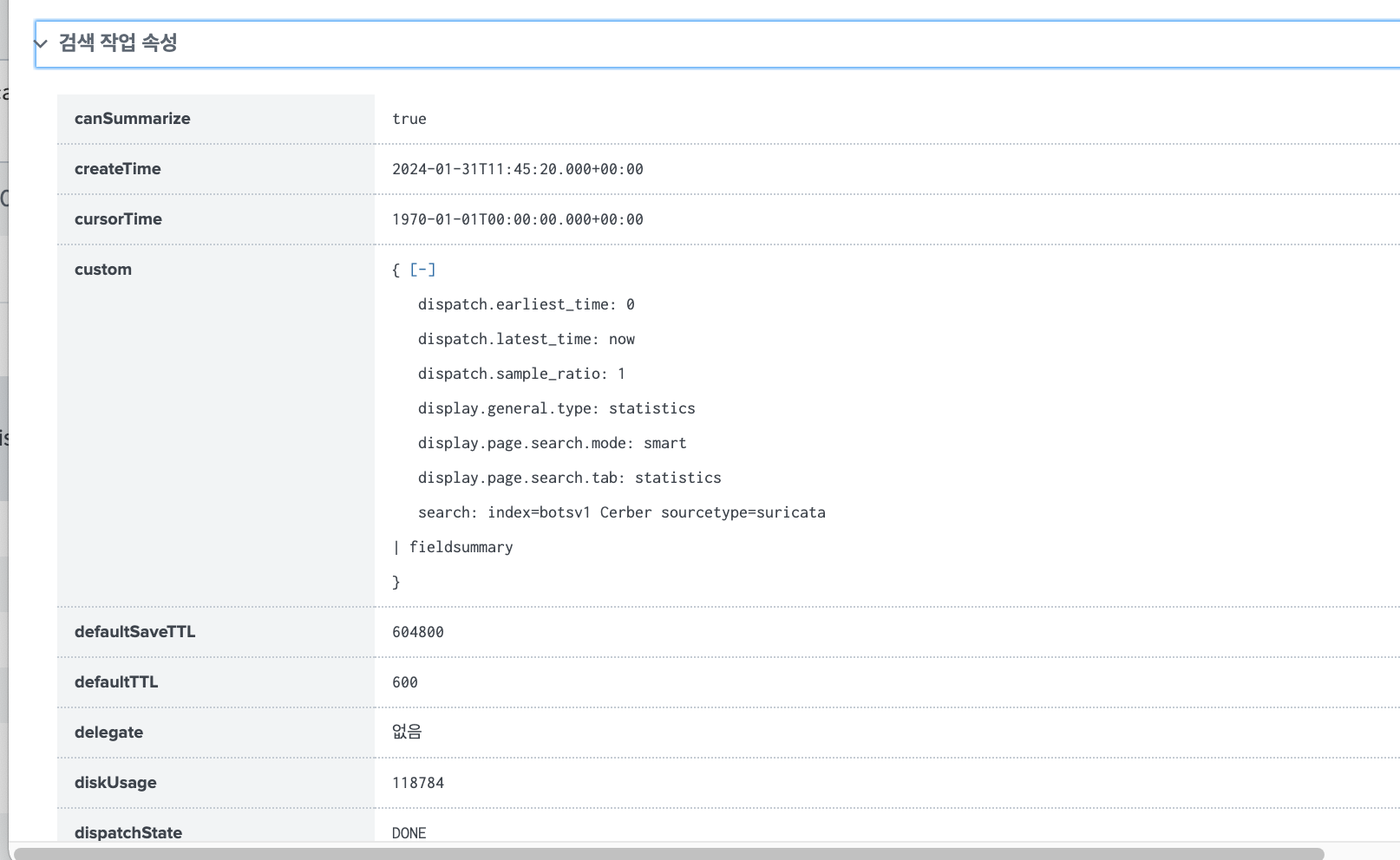
위의 정보가 $SPLUNK_HOME$/var/run/splunk/dispatch/ 하위에 저장된 것 이다.
이러한 검색 아티팩트는 수명이 정해져있다. 위의 작업 검사기 정보에서 ttl 값을 보면 600초라고 나와있는데 이것이 수명이다. 10분 뒤에 위의 결과를 보면 검색이 만료되었다고 나온다. 아티팩트가 사라졌기 때문에 보이지 않는 것 이다.
10분 뒤에 loadjob 명령어를 써서 검색했던 결과를 다시 불러오면 아래와 같이 검색을 찾을 수 없다고 나온다.
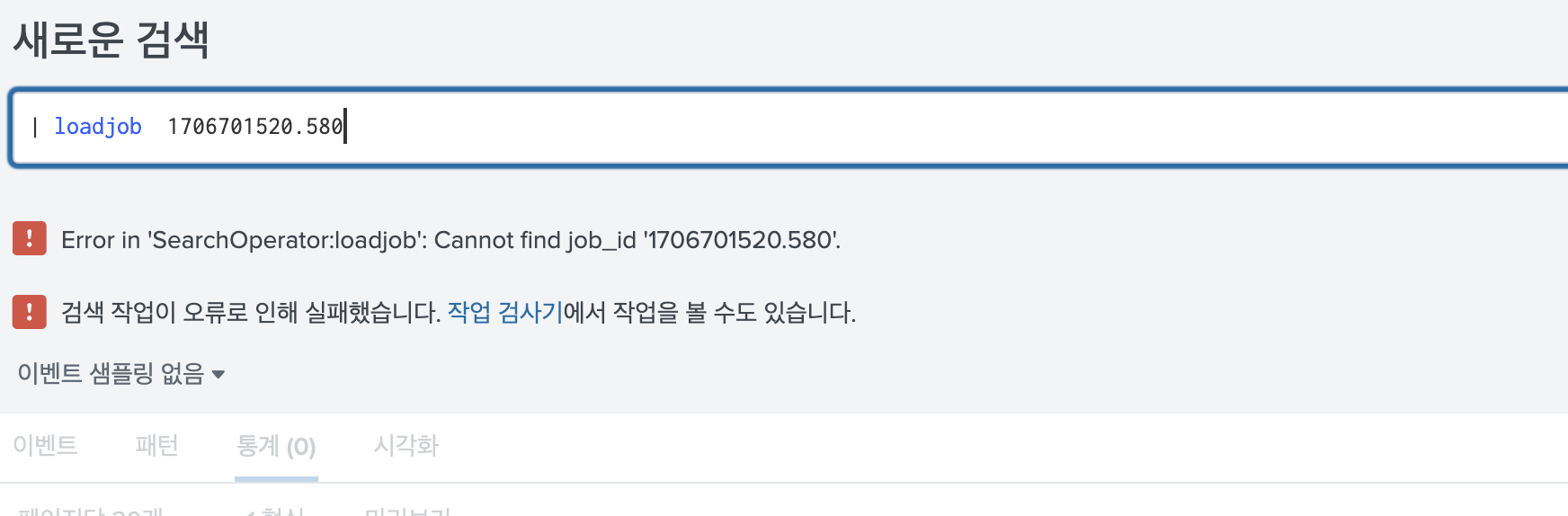
이러한 시간은 수정이 가능하다. 자세한 상세 설명은 공식 문서 에서 확인할 수 있다.
3. 왜 이 정보를 복제할까?
1) 고가용성
- 검색헤드 클러스터링에서 복제팩터가 3이라고 한다면, 검색헤드가 2대가 Down 되더라도, 남은 1대가 검색 팩터를 공유하여 예약된 검색의 결과 정보를 사용자에게 제공할 수 있다. 따라서 (복제 인자 - 1) 실패를 허용하여 고가용성을 제공하기 위함이라고 볼 수 있다.
참고: 공식문서
2) 그러면 왜 Ad-hoc 검색은 복제하지 않을까?
검색 아티팩트를 공유하는 것이면 왜 세이브 서치 결과만 공유하는 것 일까에 대해 Splunk 커뮤니티에 질문을 올렸다.
-
Ad-Hoc 검색을 저장하지 않는 이유: 은 대화형으로 사용되므로 다른 SHC 구성원에 로그인한 다른 사람이 loadjob을 사용하여 호출한 다른 세션에서 결과가 필요하지 않을 것이라고 가정하기 때문이다.
-
예약된 검색의 결과를 저장하는 이유: 세이브 서치의 경우는 이미 수행이 된 검색의 결과를 활용하는 것 이다. 이를 위해 비동기적으로 검색을 예약하여 수행하기 때문에 검색 결과의 공유가 필요한 것이다. 서머리 인덱스를 사용해 저장한다면, 불필요할 수도 있지만 단순히 예약된 검색의 경우 검색 결과를 저장해 재사용하는 케이스가 많기 때문에 이를 복제한다.
끝이다!!!!
