오늘은 Splunk에서 쿼리의 속도를 올리는 법을 알아보고자 한다.
사용하다 보면, 가끔 같은 쿼리가 갑자기 느려질때가 있다. 혹은 사용하려던 쿼리의 데이터가 너무 많아서 처리가 불가능한 경우가 있다. 모든 경우를 커버할 수는 없지만 대부분 아래의 방법으로 해결이 되었다.
처음에는 기본적인 내용이지만 분명 놓치고 검색한 경우도 있을 것이라고 보기 때문에 천천히 읽어보길 바란다.
1. 고속 모드로 검색하셨나요?
처음에 가장 많이 실수하는 부분이다. 검색 모드에 관한이야기
검색 모드는 상세 모드, 스마트 모드, 고속 모드가 있다.
이중에서 속도는 고속 모드> 스마트 모드> 상세 모드 순으로 이뤄진다.
쉽게 그 이유를 설명하면
고속모드는 단순히 집계를 위해 명령어를 실행한다. 따라서 결과 데이터만 나온다. (더 자세히 말하면 필드 추출과 관련이 있지만 여기서는 생략하겠다!)
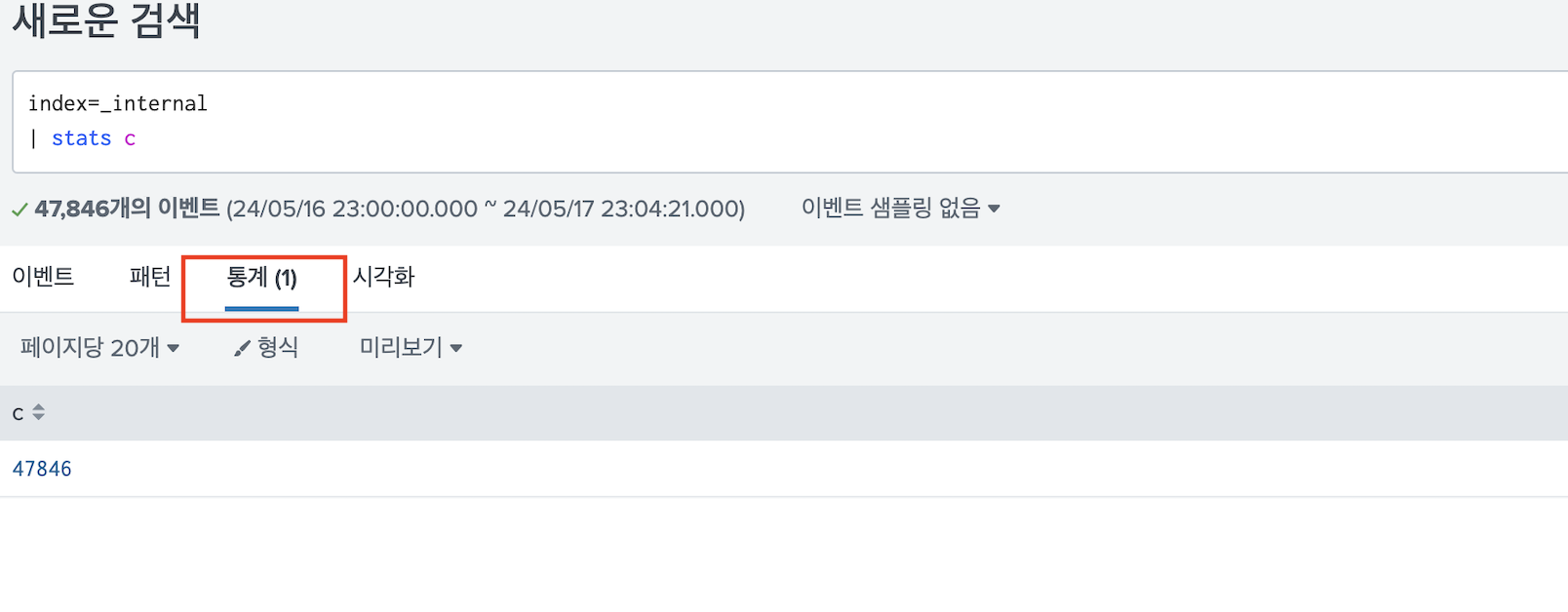
스마트 모드는 집계일 경우에는 결과 데이터만, 아닐 경우에는 실제 사용한 데이터를 모두 가져온다.
- 예를들어 table, fields 와 같은 명령어로 끝나면 모든 이벤트가 로드되고, stats과 같은 집계 명령어로 끝나면 통계 결과만 나온다.
상세 모드는 집계일 경우에도, 아니어도 모든 데이터를 가져온다.
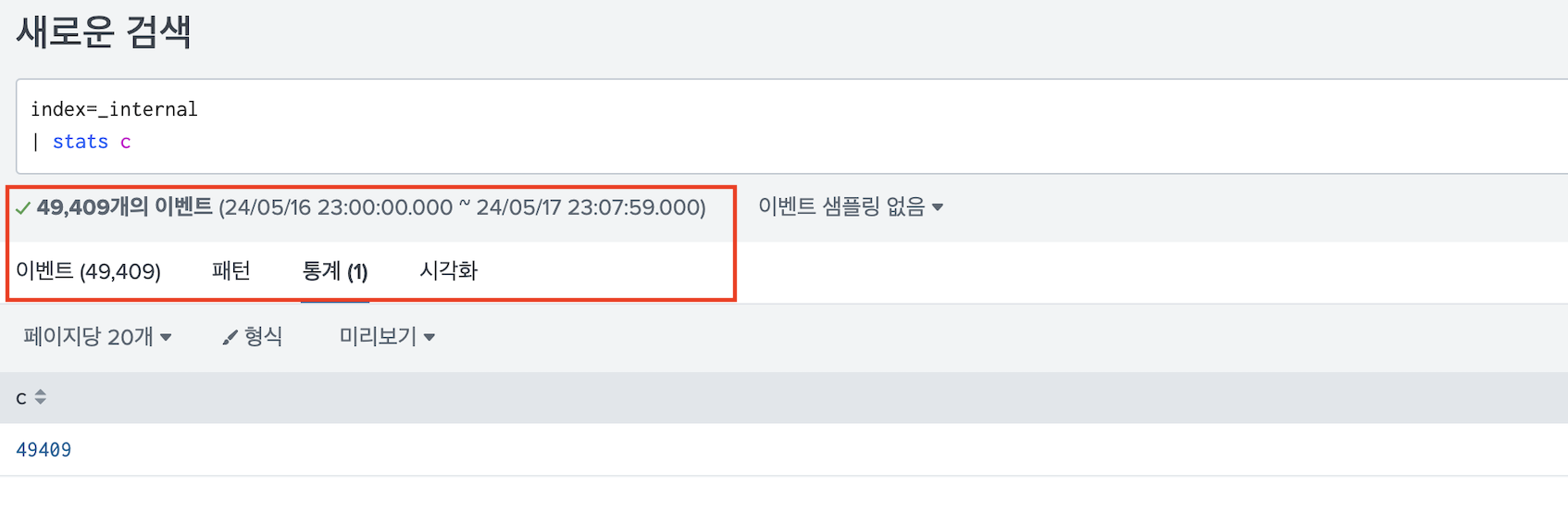
데이터가 많을 경우 검색 모드로 인한 성능 차이는 상당하기 때문에 꼭 체크하길 바란다.
2. 브라우저에 탭이 너무 많지는 않나요?
Splunk를 사용하면 크롬 등의 브라우저를 이용해보면 새탭에서 보기, 탭 복제 등으로 어느순간 탭이 수십개가 된다.
이렇게 되면 똑같은 쿼리를 탭 복제를 통해 실행했는데 갑자기 쿼리가 상당히 느려진다.
이럴때 작업 관리자나 탭 위에 커서를 올려보면 얼마나 메모리를 사용하고 있는지 볼 수 있다. 사용량이 많은 순으로 혹은 불필요한 탭을 삭제하거나 쿠키 캐시 등을 삭제해준 뒤, 재검색 시 원활하게 검색되는 경우를 볼 수 있다.
3. 설마 index=*? 혹은 index=*fw?
검색 문자열에서 대상의 앞에 *를 쓰는 것은 좋지 않다. 모든 인덱스를 스캐닝해야하기 때문이다. 최대한 인덱스 명을 index=firewall_fw 이런식으로 명시적으로 지정해줘야 한다.
4. NOT조건, != 보다는 =가 더 좋아요
NOT 혹은 != 조건을 사용하게 되면 일치하지 않는 모든 것을 찾아봐야 한다. 따라서 일치하는 것 만을 가져오는 것이 성능면에서 일반적으로 좋다고 한다.
5. TERM()을 사용해 보세요.
우리가 예를 들어 아래의 검색쿼리를 사용했다고 하자.
index=botsv1 sourcetype=suricata 192.168.225.125이때 Splunk는 위의 검색을 5가지로 나누어 실행한다.
index=botsv1 sourcetype=suricata 192
index=botsv1 sourcetype=suricata 168
index=botsv1 sourcetype=suricata 225
index=botsv1 sourcetype=suricata 125
index=botsv1 sourcetype=suricata 192.168.225.125
인 데이터를 모두 스캔한다.
그런데, TERM을 사용하면?
index=botsv1 sourcetype=suricata TERM(192.168.225.125)오직 아래의 경우를 모두 스캔한다.
index=botsv1 sourcetype=suricata 192.168.225.125
검색의 결과 데이터는 같지만, 스캔하는 데이터의 범위를 줄일 수 있다.
직접 작업 검색기를 통해 확인하면 아래와 같다.
-
TERM을 사용하지 않았을 경우

-
TERM을 사용했을 경우

TERM을 사용했을 때에가 스캐닝한 이벤트의 수가 훨씬 적고 비용도 적게든 것을 확인할 수 있다. 보통 TERM을 사용할때에는 작업 검사기에서 검색 결과 구문의 X 개의 결과 by scanning Y에서 X와 Y의 차이가 많을 경우에 사용하는 것이 좋다.
현재는 346개에서 117개를 스캐닝 하는 것으로 줄었으니, 비용이 확실히 줄어든다.
- 참고사항
예를들어 raw데이터에 src_ip=192.168.225.125 와같이 검색 대상 바로 앞이나 뒤에 바로 breaker가 있는 경우는 반환되지 않는다. 따라서 이러한 경우를 포함하고 싶다면(필드 정보를 모두 알지 못하는 경우) TERM을 사용하지 않는게 나을 것 이다.
굳이 사용하고 싶다면, 필드의 정보를 알고 있다면 검색할때 TERM(src_ip=192.168.225.125)로 포함시켜 검색하는 방법이 있다.
minor breaker: / : = @ . – $ # % \ _
또한 검색하는 대상이 major breaker가 포함된 경우에는 작동하지 않는다.
major breaker: [ ] < > ( ) { } | ! ; , ' " \n \r \s \t & ? + %21 %26 %2526 %3B %7C %20 %2B %3D -- %2520 %5D %5B %3A %0A %2C %28 %29 / : = @ . - $ # % \ _
minor, major 브레이커 관련 정보는 segmenters.conf에 저장 되어있다.
6. 작업 검색기를 이용해 가장 많은 시간을 소비하는 항목을 찾아보세요
작업 검색기를 자주 사용하는 것이 좋다. 생각지도 못했던 부분에서 상당히 많은 시간을 잡아먹은 케이스를 찾을 수 있다.
필자의 경우 태그나, 이벤트 타입, 계산된 필드 등이 수~없이 많음을 확인하고 정리했던 계기를 만들어주기도 했다.
Job Inspecter에 관한 내용은 이 포스팅을 참고하길 바란다!
이번 게시물도 생각 외로 많은 게시글을 참고했다. 나 또한 여러 케이스와 비교하면서 많은 도움이 된 것 같다.
7. dedup 보다는 stats, stats 보다는 eventstats와 sistat, tstat
-
dedup 보다는 stats: 일반적으로 dedup 보다는 stats가 성능이 더 낫다고 한다. 실제로 이에 관련된 여러 커뮤니티 게시글이 있다.

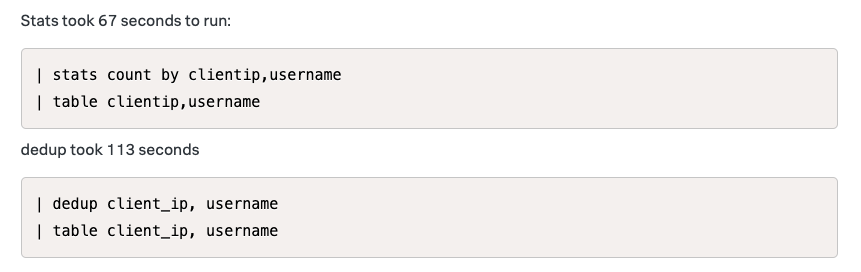
-
stats 보다는 eventstats: 이것은 내 개인적인 경험에 의한 것 인데, stats를 2~3번 사용하는 쿼리에서 중간 쿼리를 사용할 때 stats보다는 eventstats를 사용하는 것이 성능이 좋다. 예를들어 아래의 쿼리가 있다고 하면
| bin span=5m _time | stats c by _time, src_ip, dest_ip | stats avg(c) stdev(c) by src_ip, dest_ip이것보다는 아래가 낫다.
| bin span=5m _time | eventstats c by _time, src_ip, dest_ip | stats avg(c) stdev(c) by src_ip, dest_ip -
stats 보다는 tstat, sistat: 이것은 특수한 경우인데 summary index를 사용해 인덱싱 하는 경우 혹은 가속화된 데이터 모델을 사용하는 경우에는 tstats를 사용하는 것이 더 효과적이다. sistat, tstat 관련한 사용법은 나의 블로그에도 있으니 참고하길 바란다!
8. 결론 & 정리
검색하는 최상단 쿼리에서 가장 많은 데이터를 필터링 해주는게 키포인트 인 것 같다.
검색은 크게 아래의 3가지 단계로 나뉘며, 각 단계에서의 솔루션을 정리하면 아래와 같다.
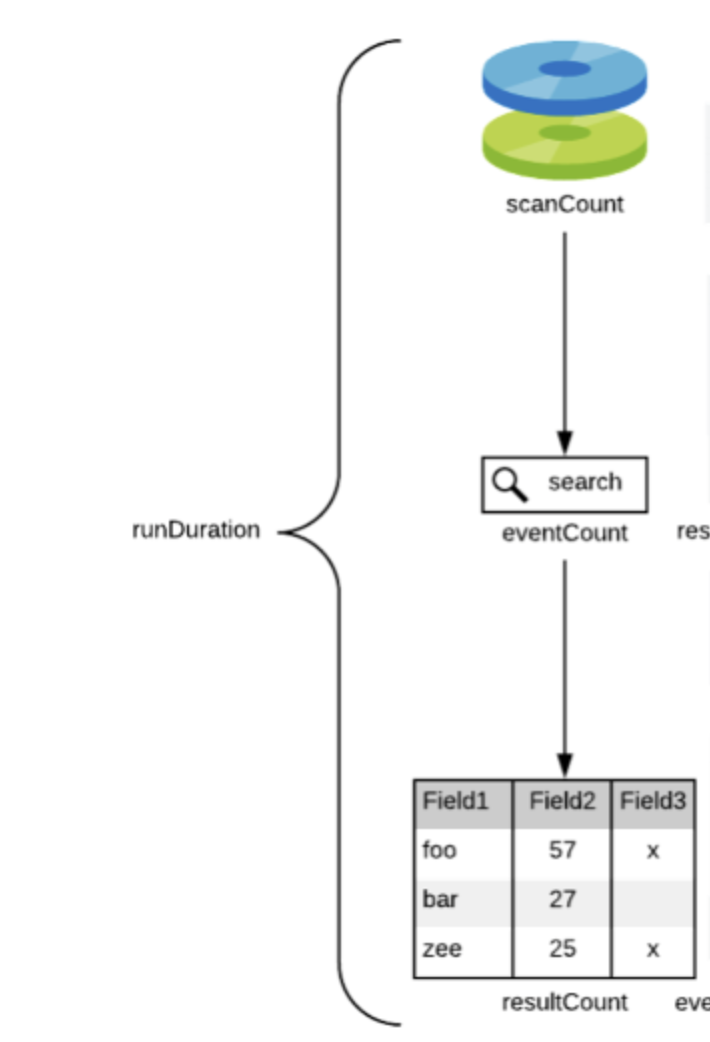
- scanCount: 인덱서에서 props.conf가 적용된 후 필터링된 데이터 수
여기서 최적화 하는 방법 -> TERM함수- eventCount: 검색 명령이 실행되어 필터가 적용된 이벤트 수
여기서 최적화 하는 방법 -> index 명시하기, !=사용하지 않기- resultCount: SPL의 마지막 명령에 의해 반환된 이벤트 수
여기서 최적화 하는 방법 -> dedup보다는 다른 것, stats 보다는 다른 것 사용하기
- 그 외 환경적인 요소: 브라우저 닫아주기, 고속모드 켜주기(집계 검색일 경우), 작업 검색기 살펴보기
이다!!
- 참고
https://community.splunk.com/t5/Splunk-Search/Splunk-search-over-11-million-records-is-very-slow-How-can-I/m-p/228753
https://medium.com/silenttech/splunk-search-query-and-commands-7c6e127e9fef
https://hurricanelabs.com/splunk-tutorials/5-tips-for-navigating-your-splunk-search-head-performance-nightmares/
https://solsys.ca/yielding-optimized-spl-using-term-on-splunk/
https://idelta.co.uk/3-easy-ways-to-speed-up-your-splunk-searches-and-why-they-help/
https://community.splunk.com/t5/Splunk-Search/How-to-improve-the-performance-of-our-Splunk-search-query/m-p/112261
https://djangocas.dev/blog/splunk/troubleshooting-splunk-search-performance-by-search-job-inspector/
https://djangocas.dev/blog/splunk/splunk-search-best-practices-for-better-performance-response-time/
https://www.domaintools.com/resources/blog/tuning-performance-on-splunk-searches/
https://docs.splunk.com/Documentation/Splunk/9.2.1/SearchReference/Noop
https://www.splunk.com/en_us/blog/customers/splunk-clara-fication-search-best-practices.html
https://splunk.illinois.edu/splunk-at-illinois/using-splunk/searching-splunk/how-to-optimize-your-searches/

3개의 댓글

splunk 인덱스 관련 자료를 검색하다 여기까지 왔고 작성하신 관련 글들을 보았습니다. 혹시 실례가 안된다면 splunk 공부는 어떻게 하고 계신지 궁금합니다.
네. 그게 바로 접니다. ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ
국룰 : 어 방화벽 종류가 뭐가 있더라? 무지성 index=*fw 검색 드가즈아
이건 첨 알았는데 꿀팁이네!!!!!