보통 대시보드를 만들때 두가지 결과를 합치고 싶을 때가 많다. 그럴때 많이 사용하는 것이 append 명령어 이다. appendpipe, appendcols는 거의 사용한 적이 없으나 알아보니 유용한 기능이고 이왕 아는거 3가지 다 아는게 나은것 같다. 검색을 합치는 것이 multisearch라는 유사한 기능도 있는데, 이는 검색 결과를 합치는게 아니라 검색 자체를 합친다. 그래서 2가지 검색을 동시에 실행한다. 나중에 이 기능도 다뤄야겠다.
1. append
1) 기본 사용법
형태만 보면 이렇게 보면 된다.
first search
| append
[second search]사용법은 매우 간단하다. 이러한 쿼리가 있다고 하면 다음과 같은 결과가 나온다.
index="tmdb_index"
| stats count by genre_id
| where genre_id IN (99,28)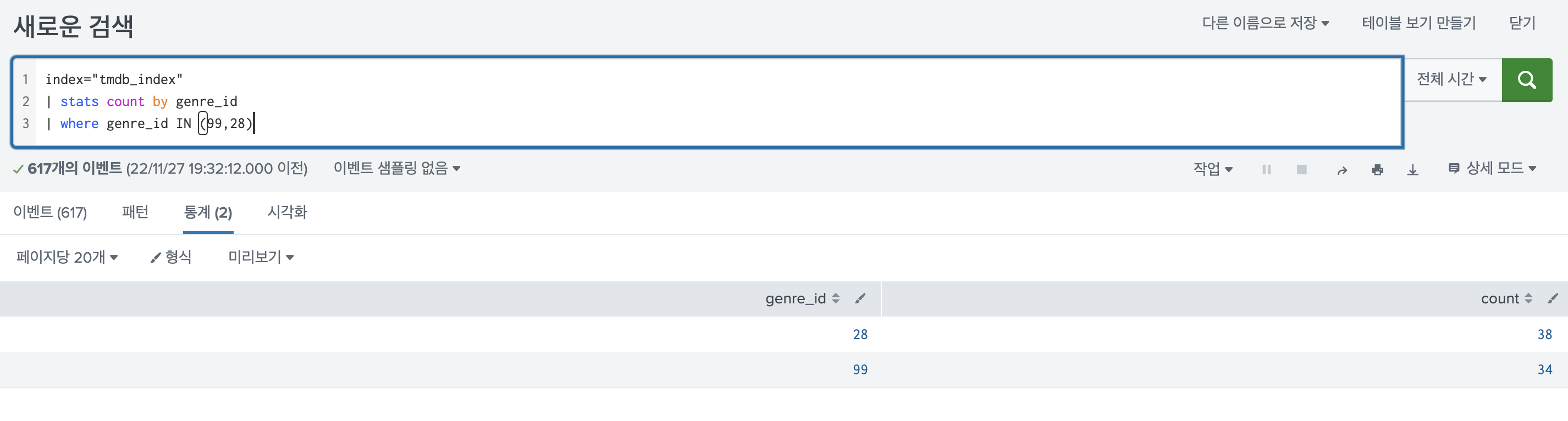
여기에 내가 어떤 검색결과를 단순히 합쳐서 그대로 보여주고 싶다면 이렇게 하면 된다.
index="tmdb_index"
| stats count by genre_id
| where genre_id IN (99,28)
| append
[ search index="tmdb_index"
| stats count by genre_id
| where genre_id IN (14,12)]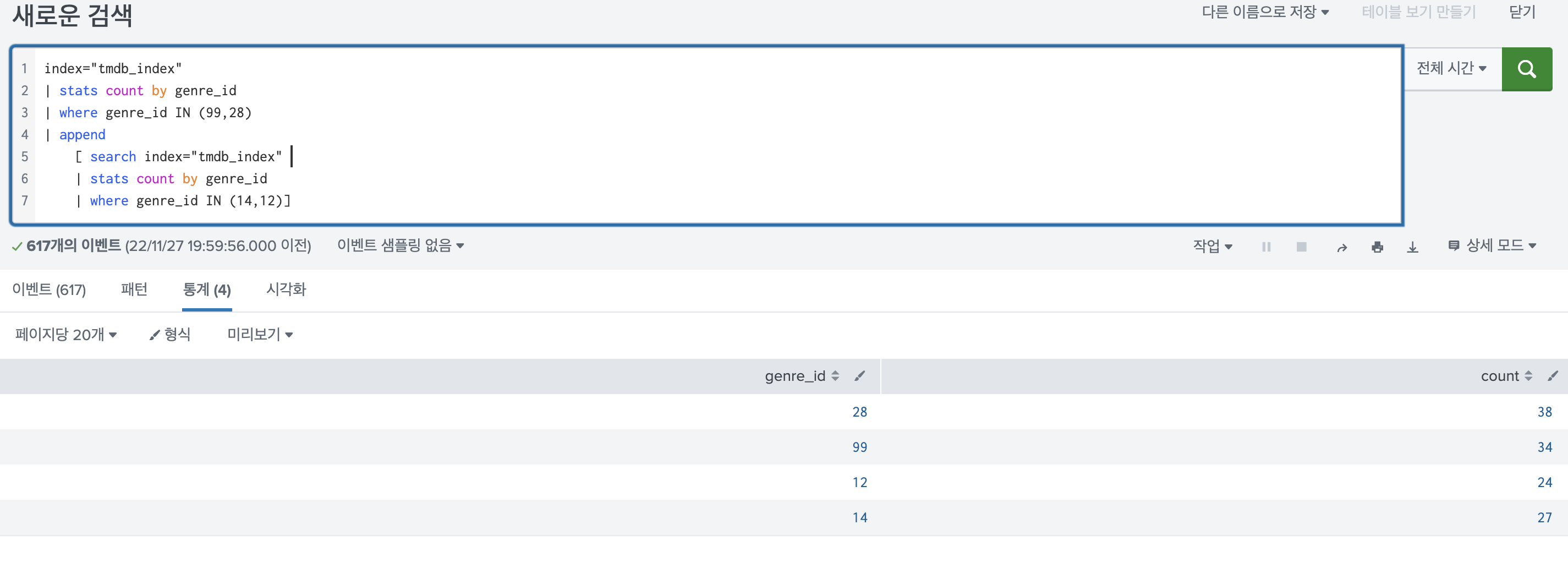
2가지의 검색 결과가 합쳐서 보인다. 말 그대로 추가가 되었다.
(동일한 컬럼이 아닐경우, null값으로 채워지고 뒤에 추가된 컬럼이 새로 생겨난다.)
2) 옵션 사용법
append 자체가 하위 검색과 함께 동작하는 방식이어서 옵션도 모두 하위 검색과 관련된 옵션이다.
* extendtimerange
원래 하위 검색을 실행할 때에는 시간 범위를 재정의 해줘야 한다. (참고로 재정의하지 않으면, 시간 선택기에서 지정된 범위로 자동검색하게 된다.) 이때 재정의된 time 범위를 mainsearch 의 earliest 에서 subsearch 의 latest로 가지게 하고 싶다면 extendtime range 옵션을 사용하면 된다.
바로 다음과 같은 쿼리를 확인해보자.
index=_internal earliest=11/01/2022:00:00:00 latest=11/15/2022:11:59:00
| append
[ search index=_internal earliest=11/10/2022:00:00:00 latest=11/19/2022:11:59:00]
| timechart span=1d count원래 이 쿼리의 시간 검색 범위는
main search -> earliest=11/01/2022:00:00:00 latest=11/15/2022:11:59:00
sub search -> earliest=11/10/2022:00:00:00 latest=11/19/2022:11:59:00
이었다.
하지만 extendtimerange 옵션을 사용하게 될 경우
main search -> earliest=11/01/2022:00:00:00 latest=11/19/2022:11:59:00
sub search -> earliest=11/01/2022:00:00:00 latest=11/19/2022:11:59:00 가 된다.
사용은 이렇게 하면 된다.
index=_internal earliest=11/01/2022:00:00:00 latest=11/15/2022:11:59:00
| append extendtimerange=true
[ search index=_internal earliest=11/10/2022:00:00:00 latest=11/19/2022:11:59:00]
| timechart span=1d count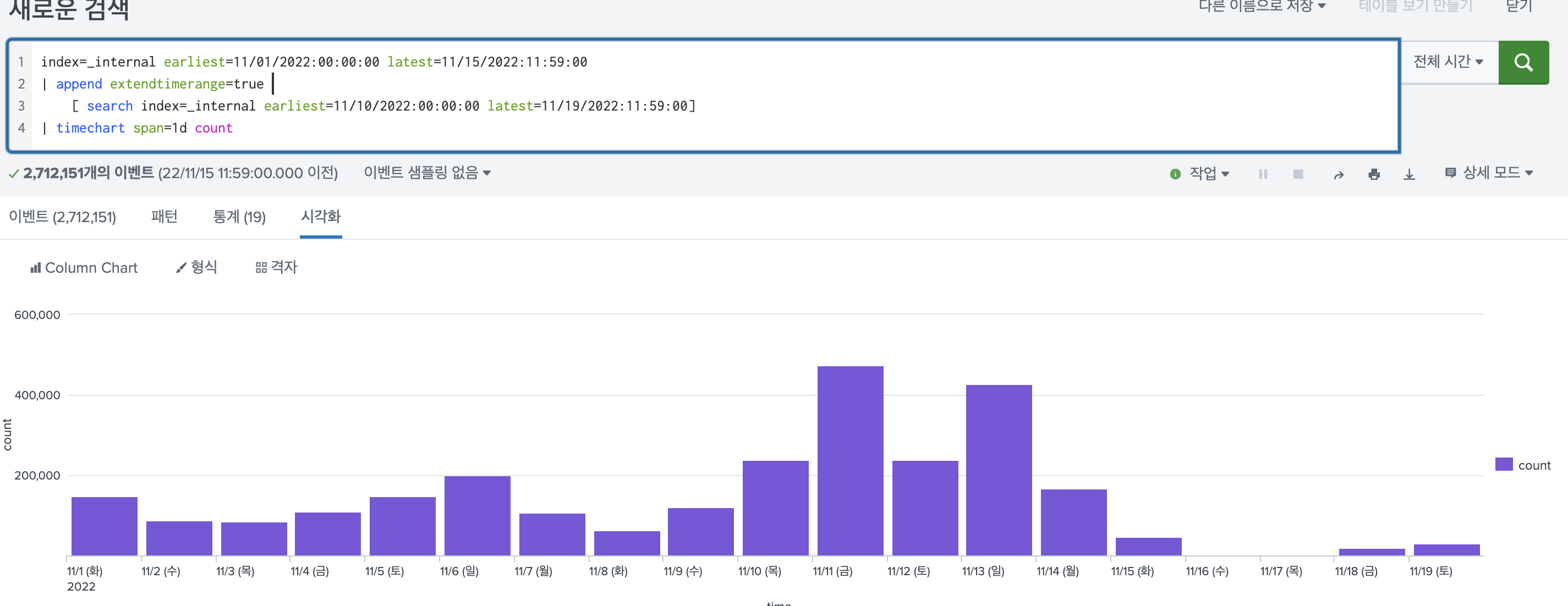
기본적으로 하위 검색에 있는 속성이지만, append 명령어 자체에서 속성 값을 부여하여 config 파일에 있는 속성값을 무시할 수 있다!
* maxtime
검색이 완료되기 까지 대기하는 최대시간이다. 처음에 timeout과 굉장히 헛갈렸는데, timeout은 해당 시간까지 하위검색이 완료되지 않으면 timeout으로 검색이 중단된다. 하지만 maxtime은 지정된 시간까지 검색이 완료되지 않으면, 부정확한 결과를 내뱉어 주되 검색이 완료된다.
| append maxtime=100디폴트 값은 60초이다. (초 단위임)
* maxout
최대로 출력할 수 있는 결과의 row 수 이다.
| append maxout=100000디폴트 값은 50000이다.
* timeout
하위 검색이 timeout걸리기 까지의 시간 제한 값
| append timeout=100디폴트는 60 이다.
2. appendpipe
appendpipe는 main search의 결과를 subsearch를 이용해 다시 별도의 데이터 프로세싱 과정을 거쳐서 main search로 붙이는 과정이다. 글로 설명하는 것에는 한계가 있으니, 쿼리 결과로 확인하자.
index="tmdb_index"
| stats count by genre_id, original_language이러한 쿼리의 결과를 확인한 후, 이 결과를 A라 하자. 이후에 A를 다시 집계하여 결과를 확인할 수 있다. 바로 이렇게
index="tmdb_index"
| stats count by genre_id, original_language
| stats sum(count) as count by original_language
| eval genre_id = "All Languages"]이 결과를 B라고 하자. 이때 내가 A와 B를 하나의 결과로 보고싶을 때 appendpipe를 사용할 수 있다. 바로 이렇게 말이다.
index="tmdb_index"
| stats count by genre_id, original_language
| appendpipe
[ stats sum(count) as count by original_language ## A의 결과를 이용해 다시 집계한 결과를 추가
| eval genre_id = "All Languages"]여기서 주의해야 할 점은 B의 쿼리는 A의 결과를 다시 집계하는 것으로, appendpipe 명령어를 통해 합칠 수 있는 경우는 main 쿼리를 다시 집계하여 집계한 결과를 다시 추가할 경우이다.
appendpipe의 옵션은 run_in_preview밖에 없는데 간단하다. 검색 도중에도 결과를 실시간으로 보면서 할 것인지에 대한 옵션이다. 엄청 대용량의 데이터의 집계결과를 대략적으로라도 빨리 보고 싶을때 사용할 것 같다.
3. appendcols
이것도 append와 함께 가끔씩 사용하는 명령어 이다. 말 그대로 컬럼을 추가해준다.
바로 컬럼 결과로 확인해보자.
1) 기본 사용법
index="tmdb_index"
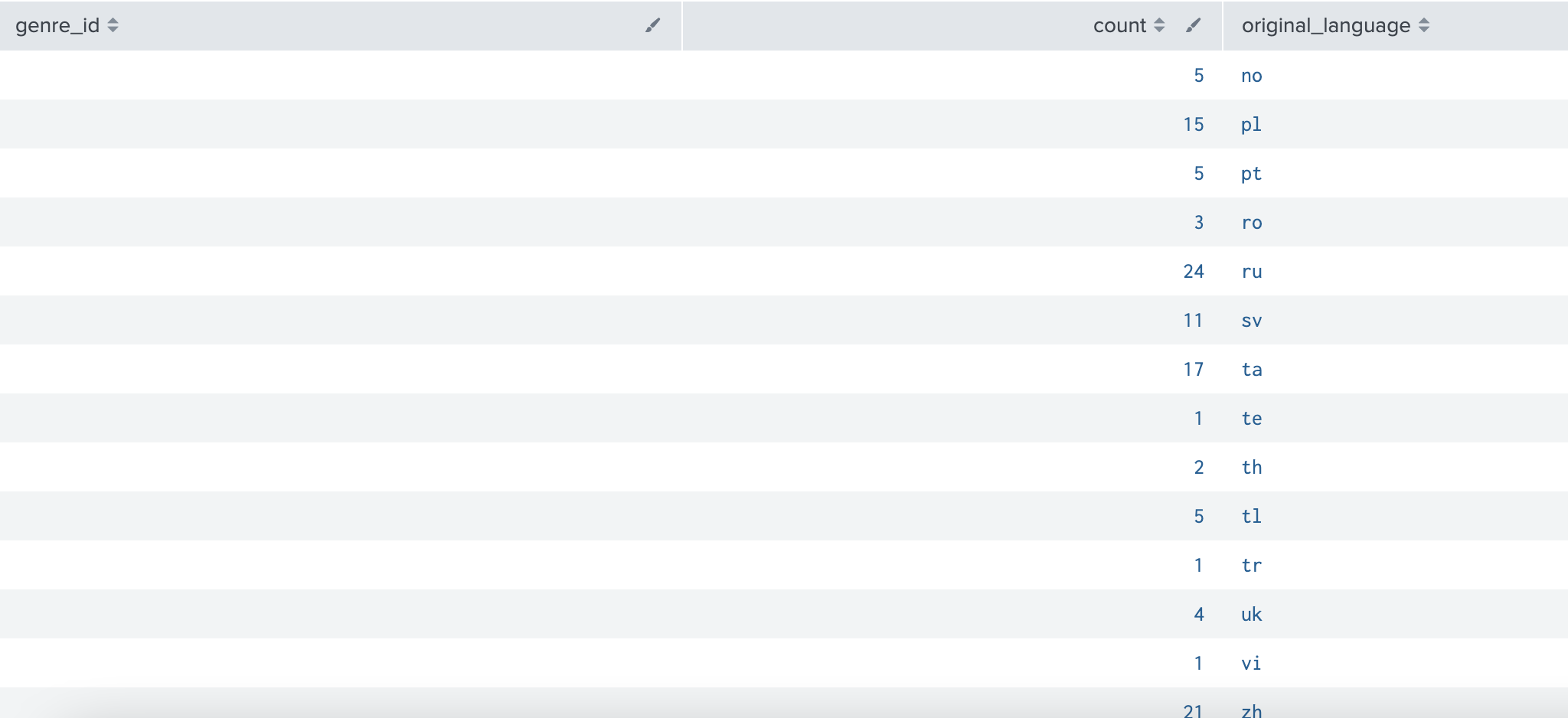
| stats count by original_language쿼리 결과는 다음과 같다.
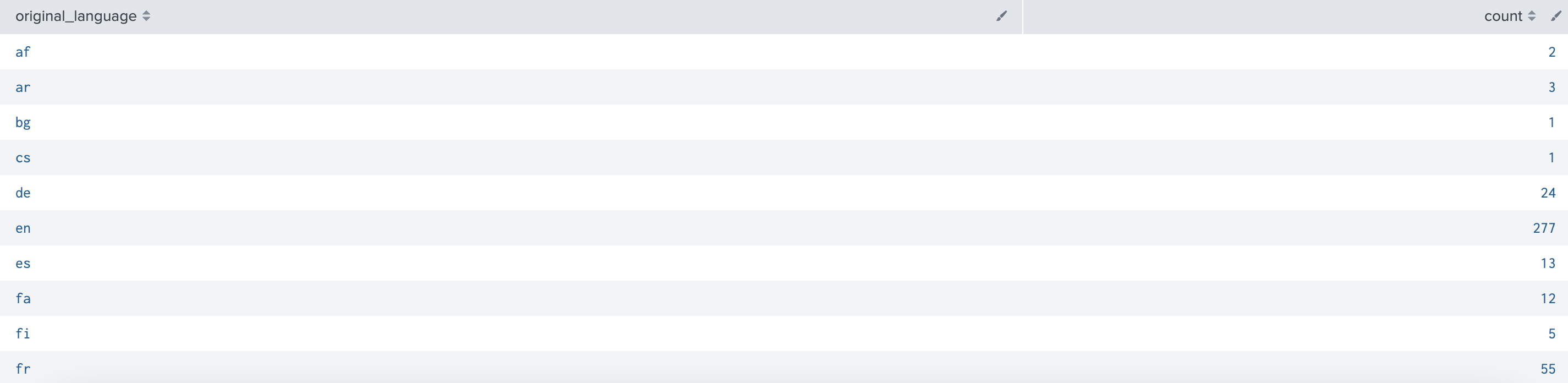
이 쿼리를 A라고 하자. A쿼리의 결과는 count, original_language로 되어있다.
여기에 genre_id로 집게한 카운팅 쿼리를 추가하려고 한다.
index="tmdb_index"
| stats count by genre_id쿼리 결과는 다음과 같다.
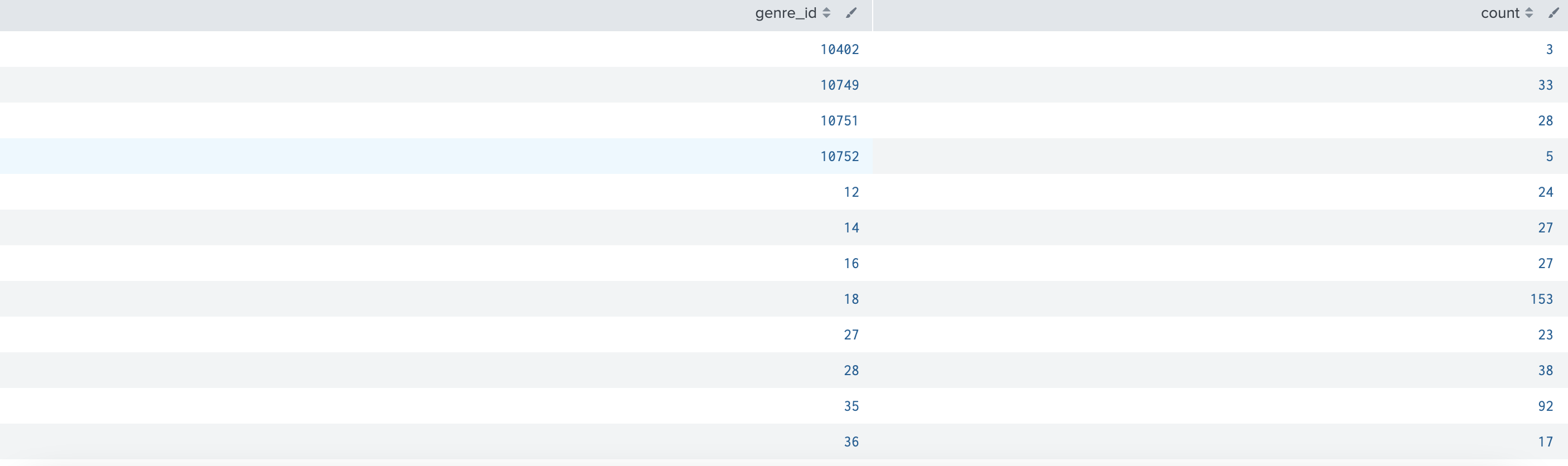
추가를 하면 이렇게 두개의 결과가 단순 합쳐지는것이 아니라 옆으로(?) 붙는다.
index="tmdb_index"
| stats count by genre_id
| appendcols
[ search index="tmdb_index"
| stats count by original_language]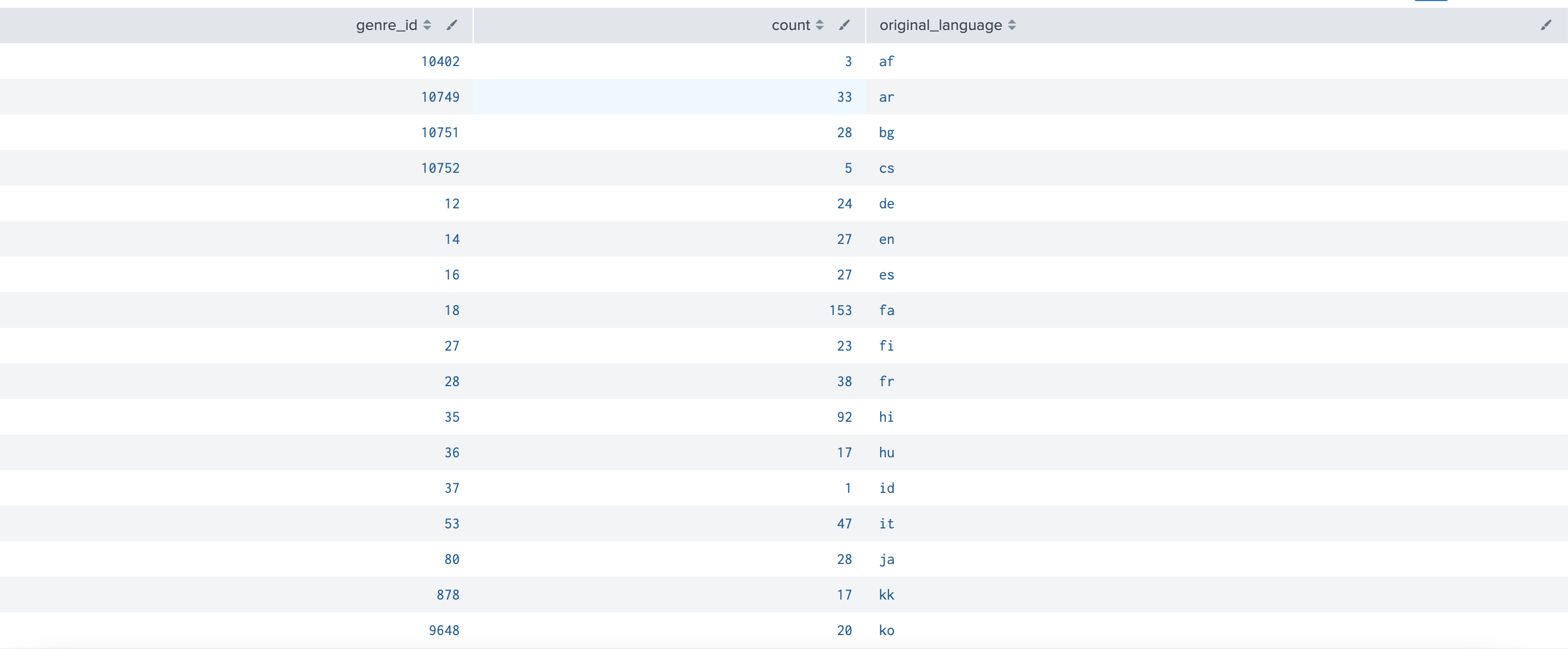
2) 주의할 점
주의할 점은 appendcols는 join 문이 아니다. 위에서 약간 위화감을 느낀 사람도 있을 것 이다.
바로 count 결과 2가지를 합쳤는데, count의 컬럼은 동일하기 때문에 다른 집계 결과에 대한 count지만 1개의 컬럼으로 나온다는 것 이다.
동일한 컬럼이 있다면 main 컬럼 쿼리가 우선순위로 나오고 그 다음에 sub쿼리의 결과가 붙는다. 따라서 위의 count 컬럼은 genre_id에 대한 count가 나왔다고 보면되고, original_language의 count 정보와는 무관하다.
추가로, 2가지 쿼리의 결과 row수가 일치하지 않을 경우 더 많은 쪽은 없는 컬럼을 null으로 채워서 보여준다.