Splunk에서 은근 json 데이터를 많이 다루게 되는데, 이때 무조건 json 관련 함수를 쓰게된다. 쓸 때마다 찾아봐야해서 블로그에 정리해두려고 한다.
일단 공식 홈페이지에 가보면 json 과 관련된 함수가 11개나 있다. 각기 사용 방법이 다른데, 비슷한듯 하면서도 다르다.
1탄과 2탄을 나눠서 쓰는데, 1탄에서는 json 객체의 생성, 수정 부분을 다룰 것 이다.
** 공식 홈페이지 문서를 참고했습니다.
1. json_object (json 객체 생성하기)
1) 기본 사용법
- 기본 객체 생성
json 객체를 만들어주는 함수이다.{ "name": "maria" }인 json 객체를 만든다고 하면 다음과 같이 쿼리를 사용해주면 된다.
| eval name = json_object("name", "maria")-
주의할 점
key값은 문자열로 이뤄져야 하며, 변수가 아닌 문자열을 그대로 넣는다면 쌍따옴표로 묶어야 한다. value값은 문자열, 숫자, 부울, null, 다중값 필드, 배열 또는 다른 JSON 객체로 이뤄질 수 있다. -
다중값 필드를 이용해 json 객체 생성
{ "name": ["maria", "arun"] }인 json 객체를 만드는 쿼리이다.
| eval firstnames = json_object("name", mvappend("maria", "arun"))- json 배열을 만드는 json 객체 생성
{"cities":["London","Sydney","Berlin","Santiago"]}인 json 객체를 json_array를 이용해 만드는 쿼리이다.
| eval locations = json_object("cities", json_array("London", "Sydney", "Berlin", "Santiago"))- 중첩 json 만들기
json array를 이용해{"movies":{"genres":{"space travel":["Star Wars","Intersesllar","Star Trek"]}}}인 json 객체를 만드는 쿼리이다.
| eval json_data = json_object("movies",json_object("genres",json_object("space travel", json_array("Star Wars", "Intersesllar", "Star Trek"))))
2. json_set (json value 값 수정, json value 값 할당)
이 함수는 특정 key에 해당하는 value를 할당하거나 덮어쓸 때, 혹은 새로운 key-value 쌍을 할당하는 경우에 사용한다.
1) 기존 json객체에 값 삽입
이러한 json 데이터가 있다고 했을 때, genres 속성에 space travel 말고 새로운 속성을 만들고 싶다. 이때 사용하면 된다.
{
"movies":{
"genres":{
"space travel":[
"Star Wars",
"Intersesllar",
"Star Trek"
],
"새로운 속성": "속성 값"
}
}
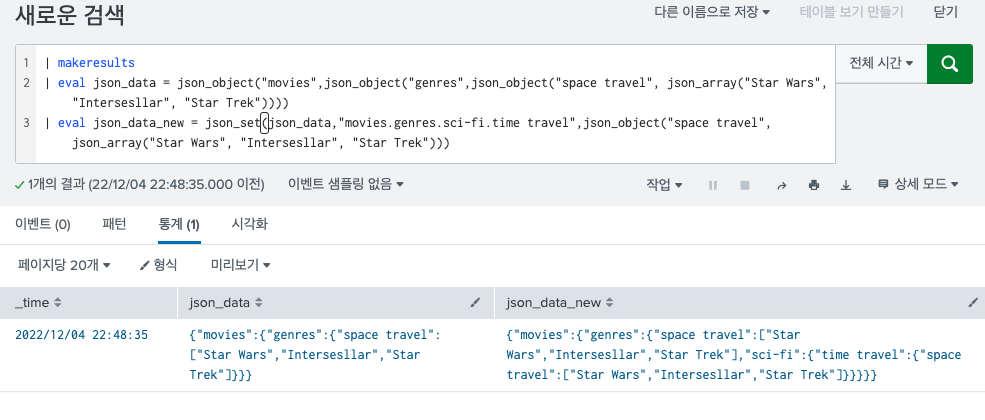
}위의 json 객체를 json_data라는 eval로 생성했다고 했을때, json_set을 이용해서 새로운 속성을 할당하는 쿼리문이다.
| eval json_data_new = json_set(json_data,"movies.genres.sci-fi.time travel",json_object("space travel", json_array("Star Wars", "Intersesllar", "Star Trek")))json_set(대상이 되는 JSON객체, 할당할 속성의 경로, 할당할 값) 의 순서로 나열된다. 그대로 해석하면 json_data의 json 객체에서 movies > genres > sci-fi > time travel 에 json_array("Star Wars", "Intersesllar", "Star Trek"))) 값을 할당하는 것 이다.
이떄 기존의 json에서는 sci-fi > time travel 가 없었음으로 새로 값이 삽입된다고 보면 된다.
그래서 결과는 이렇게 나온다.
{
"movies":{
"genres":{
"space travel":[
"Star Wars",
"Intersesllar",
"Star Trek"
],
"sci-fi":{
"time travel":{
"space travel":[
"Star Wars",
"Intersesllar",
"Star Trek"
]
}
}
}
}
}splunk에서 보면 이렇게 된다.
2) 기존 json 값 덮어쓰기
원래 이러한 json 객체를 games라고하자.
{
"category": {
"boardgames": {
"cooperative": [
{
"name": "Pandemic"
},
{
"name": "Forbidden Island"
},
{
"name": "Castle Panic"
}
]
}
}
}여기에서 cooperative의 속성 값에 3번째에 있는 { "name": "Castle Panic" } 이 값을 다른 값으로 변경한다고 하자.
쿼리는 다음과 같이 작성한다.
| eval my_games = json_set(games,"category.boardgames.cooperative{2}", {"name":"Sherlock Holmes: Consulting Detective"})그대로 해석하면 다음과 같다. games 의 category.boardgames.cooperative 경로에 있는 3번째 항목에(인덱스와 마찬가지여서 0부터 시작한다) {"name":"Sherlock Holmes: Consulting Detective"}값을 덮어 씌우는 것 이다.
- 주의사항
{}에 빈 값을 넣게되면, 전체를 의미한다. 그래서 cooperative 3가지 항목 전체의 name 값이 "Sherlock Holmes: Consulting Detective"} 으로 변경된다.
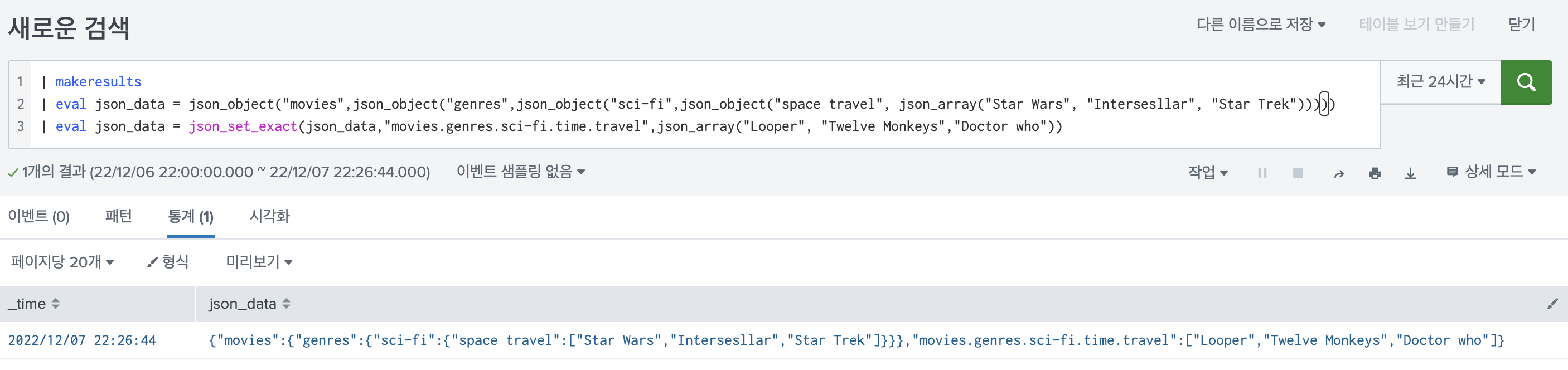
3. json_set_exact (json 계층 경로 무시하고 싶을때), json에서 key값의 . 무시하고 싶을 때
splunk에서 json관련 함수를 사용 시, 속성의 계층을 .으로 이어서 표현하게 된다. category.boardgames.cooperative 이러한 경로 처럼 말이다.
근데 json_set을 통해서 key-value 쌍을 할당할 때에 . 문자를 그대로 사용하고 싶은 경우가 있다. 이때 사용하는 함수가 json_set_exact이다.
바로 비교해서 보면 다음과 같다.
| makeresults
| eval json_data = json_object("movies",json_object("genres",json_object("sci-fi",json_object("space travel", json_array("Star Wars", "Intersesllar", "Star Trek")))))
| eval json_data = json_set(json_data,"movies.genres.sci-fi.time.travel",json_array("Looper", "Twelve Monkeys","Doctor who"))이러한 쿼리를 사용하게 되면, movies.genres.sci-fi.time.travel 경로에 ["Looper","Twelve Monkeys","Doctor who"] 배열이 추가된다.
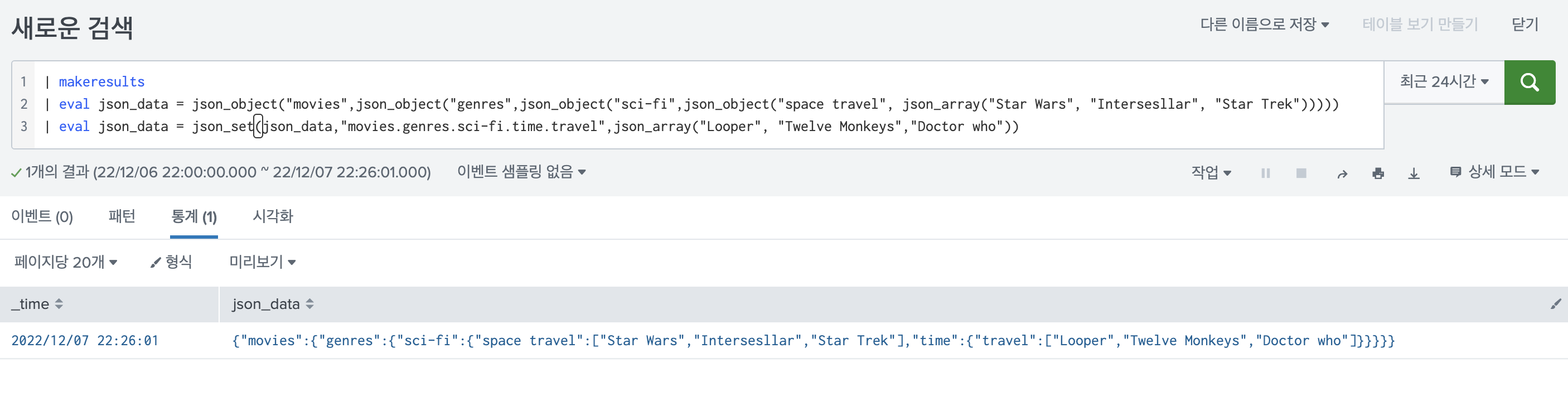
하지만 여기서 json_set을 json_set_exact로 변경하면
| makeresults
| eval json_data = json_object("movies",json_object("genres",json_object("sci-fi",json_object("space travel", json_array("Star Wars", "Intersesllar", "Star Trek")))))
| eval json_data = json_set_exact(json_data,"movies.genres.sci-fi.time.travel",json_array("Looper", "Twelve Monkeys","Doctor who"))이처럼 .을 값 자체로 사용할 수 있게 된다.