
9/30 2, 3세션
A. 범주형 & 범주형 분석
A-1. 교차표(crosstab)
pd.crosstab(행, 열, normalize=)- normalize 옵션 : 비율로 변환
- columns : 열 기준으로 100%- index : 행 기준으로 100%
- all : 전체에서의 비율
ex)
pd.crosstab(titanic['Survived'], titanic['Sex'])- columns : 여자 중에서 생존자 비율, 여자 중에서 사망자 비율
- index : 사망자 중에서 여자 비율, 사망자 중에서 남자 비율
A-2. 교차표 시각화 (mosaic plot)
- statsmodels.graphics.mosaicplot 사용
mosaic(df, [ feature, target])- 가로 : feature
- 세로 : target
from statsmodels.graphics.mosaicplot import mosaic
mosaic(titanic, [ 'Pclass','Survived'])
plt.axhline(1- titanic['Survived'].mean(), color = 'r')
plt.show()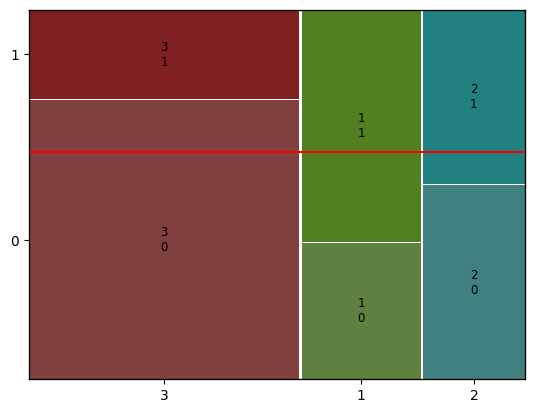
ex)
- 빨간 선 : 전체 생존율 평균
- 31 의 크기 : 3등급 객실 생존자의 비율
- 20 의 크기 : 2등급 객실 사망자의 비율
- 1, 2등급 객실은 생존율이 평균보다 높고, 3등급 객실은 낮다 -> 객실 등급이 생존에 유의미한 관계가 있다
A-3. 카이 제곱 검정
기대 빈도
귀무 가설이 참일 때(변수 간 아무런 관련이 없을 때) 기대되는 빈도 수
자유도
- 개별 자유도 : 범주의 수 - 1
- 전체 자유도 : (x 변수의 자유도) * (y 변수의 자유도)
ex)
Plcass -> Survived일때, Plcass 의 자유도 2, Survived 자유도 1 = 2
crosstab()
pd.crosstab(행, 열)- 카이제곱 전, 교차표로 집계해야 함
카이제곱 수행
spst.chi2_contingency(table)- 카이제곱 통계량이 클 수록, 차이가 크다
- 보통, 자유도의 2~3배 보다 크면, 차이가 있다고 본다
# 1) 먼저 교차표 집계- normalize 하면 안 됨
table = pd.crosstab(titanic['Survived'], titanic['Pclass'])
print(table)
print('-' * 50)
# 2) 카이제곱검정
spst.chi2_contingency(table)결과
result = spst.chi2_contingency(table)
- 카이제곱통계량 : result[0]
- p-value : result[1]
- 자유도 : result[2]
