SQLD 2회차 2과목 오답
2회차
11. 별칭(alias)
SELECT T.COL1 C1, TABLE1.COL2 AS C2
FROM TABLE1 T
WHERE TABLE1.COL2 = 'A'
ORDER BY 1, 2;FROM절에서 테이블 별칭을 선언한 경우는 반드시 테이블 별칭만으로 컬럼을 구분해야 한다
where 절에서 table1.col2라고 했는데 t.col2로 하면 정상동작. (select는 정상동작)
13 group by
SELECT T.COL1, COL2, SUM(COL3) AS "SUM VALUE"
sum value의 경우 중간에 띄어쓰기가 있어서 꼭 "" 사용.
ORDER BY COL3;
ORDER BY절에는 GROUP BY에 사용하지 않은 컬럼을 명시할 수 없다.
집계된 값(sum) 기준으로 정렬 x
ORDER BY "sum value"; 하면 정상작동
14 문자열 연결 / 연결연산자
문제가.. 이상?
-- 14. 아래의 SQL 에 대해서 결과값이 다른 것은?
① SELECT CONCAT ('RDBMS', ' SQL') FROM DUAL;
② SELECT 'RDMBS' || ' SQL' FROM DUAL;
③ SELECT 'RDBMS' + ' SQL';
④ SELECT 'RDBMS' & ' SQL' FROM DUAL;① RDBMS SQL (띄어쓰기 포함)임을 주의.
③ SELECT 'RDBMS' + ' SQL';의 경우 문자열 + 문자열은 숫자덧셈으로 인식하려고 시도.
문자열은 +연산자로 연결할 수 없다
||(연결연산자)는 오라클에서의 문자열 결합 방식이며, SQL SERVER에서는 +를 사용하여 문자열을 결합 할 수 있다.
④ &는 Oracle에서 변수 substitution 기호. 'RDBMS' & ' SQL' 중 & 이후 문자열을 변수로 간주해서 입력값을 요구함.
→ & SQL을 변수로 보고 입력하라고 뜸
& 연산자로 문자열 결합은 불가
15 숫자 f-string
TRUNC는 소수점 이하 버림
CEIL은 값보다 큰 최소정수.
FLOOR는 값보다 작은 최대 정수가 리턴
ROUND는 소수점 첫번째 자리에서 반올림
날짜 형식
SELECT TO_CHAR(TO_DATE(SUBSTR(JUMIN, 1, 6), 'RRMMDD'), 'YYYY-MM-DD')
TO_DATE(..., 'RRMMDD') : 문자열을 날짜로 바꿔줌.
'RRMMDD'는 두 자릿수 연도를 1900 또는 2000년도로 해석
두 자리 연도가 1~49 사이면 2000년대를, 50~99이면 1900년도의 4자리 연도로 출력.
TO_CHAR(..., 'YYYY-MM-DD') : 날짜를 문자열로 변환해서 YYYY-MM-DD 형식으로 출력
YY를 사용하면 2000년대를 출력
TO_DATE('1975-10-23') : 1975-10-23 00:00:00
17 isnull
ISNULL(대상, 대체값) : 대상이 NULL이면 대체값으로 치환하는 함수
18 문자열 함수
-
LTRIM: 문자열의 왼쪽 공백을 제거
AB DE→ 왼쪽의 ' '(공백) 제거 → 결과:AB DE
LTRIM 함수에 제거문자열을 전달하지 않을 경우 왼쪽에서 공백을 제거 -
INITCAP 함수는 첫 문자만 대문자로 나머지 문자는 소문자로 반환하는 함수
-
TO_CHAR(숫자, '포맷')
TO_CHAR('123', '999.99'):123.00
| 포맷 기호 | 의미 |
|---|---|
9 | 자리수 지정, 빈 자리는 공백 |
0 | 자리수 지정, 빈 자리는 0 |
. | 소수점 |
, | 천 단위 구분 쉼표 |
TO_CHAR(1234567.89, '9,999,999.99') -- '1,234,567.89'
TO_CHAR(78, '000.00') -- '078.00'
함수에 의해 소수점 둘째 자리까지, 정수자리는 세자리로 표현
19 COALESCE
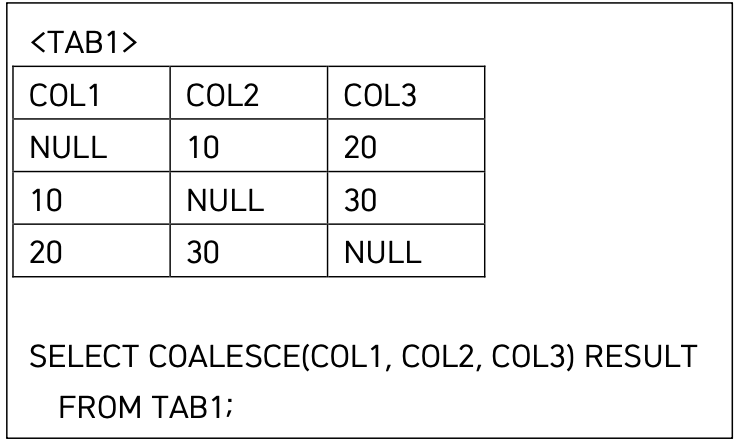
COALESCE(값1, 값2, 값3, ..., 값N)
SELECT ENAME, COMM, COALESCE(COMM, 0) AS COMM_OR_ZERO
FROM EMP;
-- COMM(커미션) 컬럼에 null값을 0으로 채워줌
-- SELECT NVL(COMM, 0) FROM EMP; 이것과 같음
대상들 중 NULL이 아닌 첫 번째 값을 출력, 전부 NULL이면 NULL 반환
col1 = 10
col2 = 10
col3 = 20
NVL(a,b) a가 null이면 b반환, 아니면 a반환. 인자는 2개만 사용가능
20 NULL
NOT IN문의 서브쿼리 결과 중 NULL이 포함되는 경우 데이터가 출력되지 않는다.
null은 항상 isnull 사용해야함.
NULL은 논리적으로 비교할 수 없는 연산이기 때문에
NULL을 비교하는 연산자로 인해 전체조건이 거짓이 된다.
조건 만족하는 값 x => null로 출력
21 count(null)
WHERE절의 비교 연산 결과 COL2의 30과 40만 해당되고 그에 해당하는 COL1은 모두 NULL이다.
GROUP BY에 의해 COL1이 NULL인 한 그룹이 생성되지만
NULL은 COUNT하지 않기 때문에 0이 출력
25
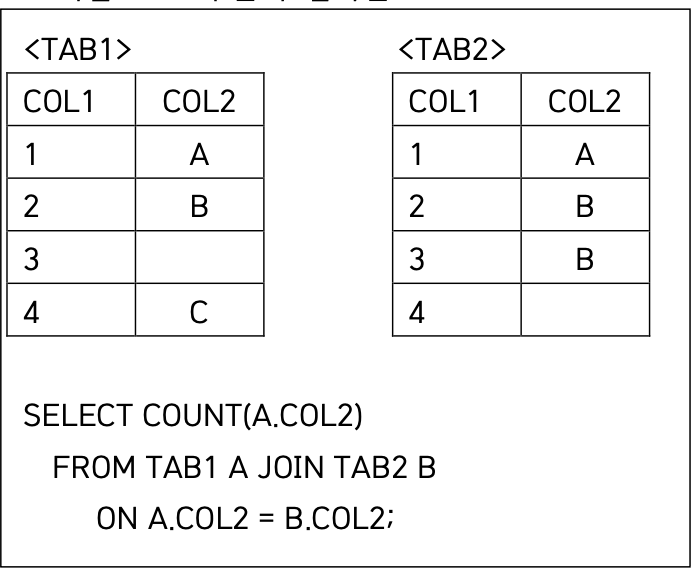
A.COL2 = 'A' <=> B.COL2 = 'A' → 1건
A.COL2 = 'B' <=> B.COL2 = 'B' (2건) → 총 2건
따라서 총 3건의 결과
NULL 끼리는 동등비교 조건에 참으로 리턴되지 않는다.
26 oracle outer join
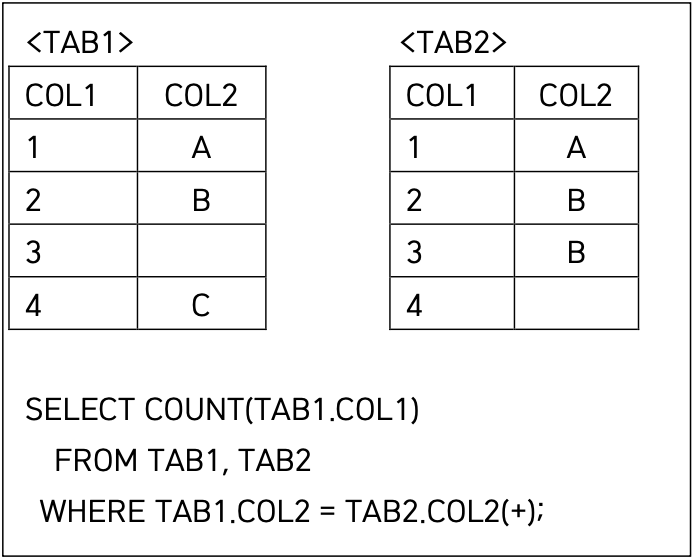
| 조인 유형 | 표현 방식 (Oracle, ANSI 이전 방식) |
|---|---|
| LEFT OUTER JOIN | = C.STUDENT_ID(+) ← 오른쪽 테이블(COURSE)에 (+) |
| RIGHT OUTER JOIN | = S.STUDENT_ID(+) ← 왼쪽 테이블(STUDENT)에 (+) |
| FULL OUTER JOIN | 불가능 (표준 JOIN 문법 써야 함) |
(+) 가 붙은 반대편 테이블이 기준이 되는 테이블로 TAB1 테이블을 기준 테이블로 LEFT OUTER JOIN이 수행된다.
결과 테이블
| TAB1.COL1 | TAB1.COL2 | TAB2.COL1 | TAB2.COL2 |
|---|---|---|---|
| 1 | A | 1 | A |
| 2 | B | 2 | B |
| 2 | B | 3 | B |
| 3 | NULL | NULL | NULL |
| 4 | C | NULL | NULL |
즉, 조인 조건이 일치하지 않아도 TAB1은 생략되서는 안되므로 INNER JOIN의 결과에 TAB1의 COL2가 NULL, C인 경우 추가적으로 출력 => 5건
27 NATURAL JOIN
NATURAL JOIN은 USING, ON, WHERE 절에서 조건 정의가 불가
INNER JOIN, CROSS JOIN, NATURAL JOIN, OUTER JOIN = 표준조인
NATURAL JOIN
두 테이블 간의 동일한 이름을 가지는 모든 컬럼들에 대해 EQUI JOIN(=)을 수행(의도하지 않아도 동일행으로 join) => USING, ON, WHERE 절에서 조건 정의 불가
JOIN 에 사용된 컬럼들은 데이터 유형이 동일해야 하며 접두사를 사용불가
SELECT ENAME, DNAME
FROM EMP
NATURAL JOIN DEPT;
조건을 정해주지 않아도 알아서 찾아서 join함
USING 조건절
조인할 컬럼명이 같을 경우 사용. 다를 땐 On 사용 (using 쓸 수 없다)
Alias 나 테이블 이름 같은 접두사 붙이기 불가
-> USING (DEPTNO) 가능, USING(EMP.DEPTNO) 불가능
괄호 필수
- 사용이유
- 중복컬럼 제거: 테이블에 같은 이름의 컬럼이 있을 때 using을 쓰면 결과에 그 컬럼이 한번만 나타남
사용하지 않으면 두개 다 나옴 - on보다 코드가 짧고 명확함
cross join은 두 테이블의 조인 컬럼의 값과 상관없이 항상 모든 경우의 수를 출력한다 (실제로 cross join은 조건을 쓰지 않는다)
29 연관 서브쿼리(where)
서브쿼리가 메인쿼리의 값을 사용하는 경우 (서브쿼리의 값이 결정되는데 메인쿼리에 의존)
SELECT SUM(T1.COL2)
FROM TAB1 T1
WHERE T1.COL2 = (SELECT MAX(COL2)
FROM TAB1 T2
WHERE T1.COL1 = T2.COL1);전체 집합에서 하나의 값을 리턴할 때 MAX() 같은 집계함수는 GROUP BY 없이도 쓸 수 있다.
30 진짜 꼴보기싫은문제임.
2번 보기를 제외한 모든 지문은 기혼 40대 여성 중 구매이력이 있는 고객의 고객아이디를 출력하는 문장이다. 실제 구매이력은 ORDERS에 있기 때문에 ORDERS의 CUSTOMER_ID 값에 존재하는지를 확인하여 구매자의 고객번호를특정할 수 있다.
이는 INNER JOIN, IN, EXISTS 연산자로 구현 가능한데, 2번 보기의 경우 인라인 뷰의 결과가 PROMOTION_ID 가 1 이상인 상품을 구매한 고객 아이디만 특정하기 때문에 전체 상품 구매를 기준으로 출력하는 다른 보기와는 결과값이 다르게 출력된다.
32 서브쿼리
다중행 서브쿼리 비교 연산자(IN, ANY, ALL, EXISTS)는 단일행 서브쿼리의 비교연산자로도 사용할 수 있다.
SELECT *
FROM EMP
WHERE SAL IN (
SELECT MAX(SAL)
FROM EMP
WHERE DEPTNO = 10
);
max는 하나의 값만 나옴 -> 단일행 서브쿼리
① 단일 행 서브쿼리는 단일 행 비교연산자인 =, <>, >, >=, <, <=의 연산자를 주로 사용한다.
비연관 서브쿼리
서브쿼리가 메인쿼리의 값을 사용하지 않는 경우 (메인과 전혀 상관없이 독립적 실행)
서브쿼리가 메인쿼리에 값(서브쿼리 결과) 제공
③ 메인쿼리에 값을 제공하기 위한 목적으로 사용하는 쿼리는 비연관 서브쿼리이다.
④ 연관 서브쿼리는 일반적으로 메인쿼리가 먼저 수행된 후에 서브쿼리에서 조건이 맞는지 확인하고자 할 때 사용하기 때문에 항상 서브쿼리 조건이 만족하는지를 확인하는 방식이라고 볼 수 없다
36 GROUPING SETS
특정 항목에 대한 소계를 구하는 함수
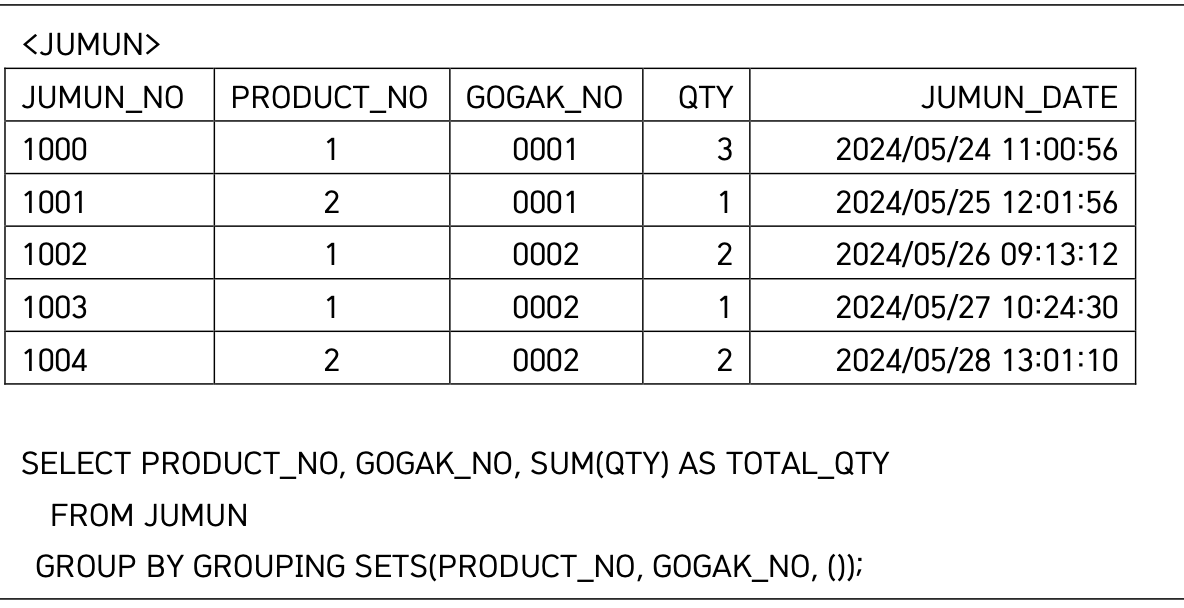
결과
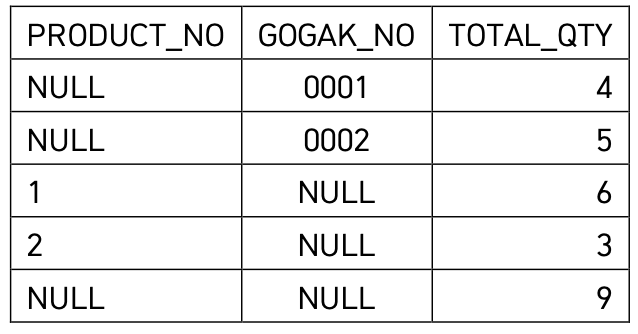
순서대로 나오지않음.....
grouping sets 결과 순서는 정해져있지않다
40 계층형 질의
하나의 테이블 내 각 행끼리 관계를 가질 때, 연결고리를 통해 행과 행 사이의 계층(depth)을 표현하는 기법
- START WITH : 데이터를 출력할 시작 지정하는 조건
- CONNECT BY PRIOR : 행을 이어나갈 조건 (자식 = 부모)
- NOCYCLE : 순환이 발생하면 무한 루프가 될 수 있기 때문에 이를 방지하고자 사용
SELECT ...
FROM 테이블
START WITH 조건 -- 루트(시작점)
CONNECT BY [NOCYCLE] PRIOR 자식컬럼 = 부모컬럼- level : 각 dept 표현(시작부터 1)
- connect by isleaf : leaf node(최하위노드) 여부(참1, 거짓0)
- SYS_CONNECT_BY_PATH(컬럼, 구분자) : 이어지는 경로 출력
- ORDER SIBLINGS BY 컬럼 : 같은 LEVEL 일 경우 정렬 수행
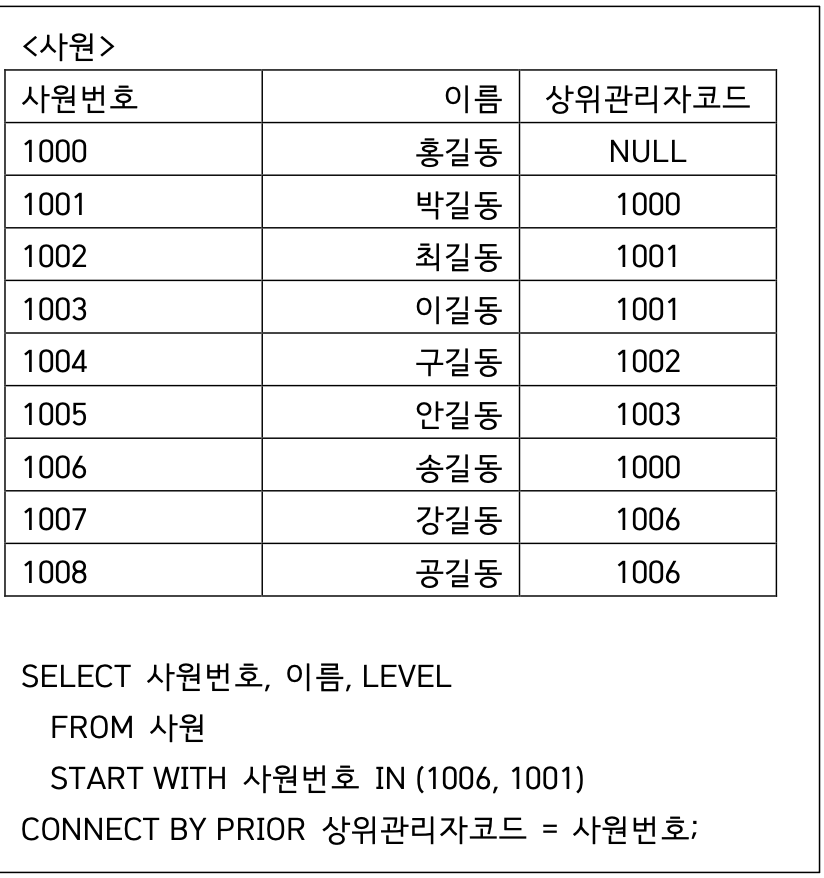
SELECT 사원번호, 이름, LEVEL
FROM 사원
START WITH 사원번호 IN (1006, 1001)
CONNECT BY PRIOR 상위관리자코드 = 사원번호;
START WITH: 시작 노드를 1006, 1001로 시작해라
CONNECT BY: 계층을 따라 위로 혹은 아래로 탐색해라 (여기선 부하 → 상사 방향)
PRIOR 상위관리자코드 = 사원번호:
즉, 현재 사원의 상위관리자코드 = 이전 단계(PRIOR)의 사원번호
START WITH 조건이 1006과 1001이므로 두 행이 1레벨이 되고, 해당 행의 상위관리자코드를 사원번호로 갖는 행을 찾으면 둘 다 홍길동이 출력
각 행별로 연결 시 PRIOR 컬럼을 먼저 읽고, 뒤에 있는 컬럼과 일치하는 행을 찾기 때문에 홍길동 나옴.
42 UNPIVOT
select *
from 테이블명
unpivot ( value 컬럼명 for stack컬럼명 in (값));
-- unpivot (값컬럼이름 for 열컬럼이름 in (열 이름))stack컬럼: 컬럼명(가로)을 값으로 넣을때 (새로 만들) 컬럼이름
value: value값을 새로 넣을 컬럼 이름
sales data
| PROD | Y2022 | Y2023 |
|---|---|---|
| TV | 100 | 150 |
| PHONE | 80 | 120 |
SELECT *
FROM sales_data
UNPIVOT (
amount FOR year IN (Y2022 AS '2022', Y2023 AS '2023')
);
결과
| PROD | YEAR | AMOUNT |
|---|---|---|
| TV | 2022 | 100 |
| TV | 2023 | 150 |
| PHONE | 2022 | 80 |
| PHONE | 2023 | 120 |
unpivot 값컬럼이름 for 열컬럼이름 in (열 이름)
43 REGEXP_REPLACE
SELECT REGEXP_REPLACE(COL1, 'A(X|Y)+\.') FROM TAB1;
REGEXP_REPLACE(문자열, '패턴') : 패턴과 일치하는 부분을 삭제하거나 다른 문자로 치환
패턴 'A(X|Y)+.' : A로 시작하고 X 또는 Y가 하나 이상 반복된 후 마침표로 끝나는 부분을 삭제
| 패턴 | 의미 |
|---|---|
A | 대문자 A로 시작 |
| `(X | Y)+` | X나 Y가 하나 이상 반복 |
. | 마침표 . (escape 됨) |
A 뒤에 X 또는 Y가 여러 개 오며 그 뒤에 .이 오는 문자열을 찾아 모두 지우는 쿼리문
44 REGEXP_SUBSTR
SELECT REGEXP_SUBSTR('ORA-00600 Oracle SQL-Server 50', '[^0-9]+') "REGEXPR_SUBSTR"
FROM DUAL;
REGEXP_SUBSTR(문자열, 패턴) : 정규표현식 패턴에 처음 일치하는 문자열을 반환
| 패턴 | 의미 |
|---|---|
[^0-9] | 숫자가 아닌 문자 하나 |
+ | 하나 이상 반복 |
[^0-9]+ 는 숫자가 아닌 값이 여러 개 반복되는 문자열을 의미
REGEXP_SUBSTR은 이 패턴에 해당하는 값을 처음부터 찾아 단 하나의 문자열을 추출
O R A - 0 0 6 0 0 O r a c l e S Q L - S e r v e r 5 0
ORA-
<숫자: 00600 스킵>
Oracle SQL-Server
<숫자: 50 스킵>
=> ORA-
45
CREATE TABLE TAB1(
COL1 VARCHAR(10) PRIMARY KEY, -- 문자열 기본키
COL2 NUMBER NOT NULL, -- 숫자, 필수
COL3 CHAR(10) NOT NULL, -- 고정 길이 문자열(10), 필수
COL4 DATE NOT NULL -- 날짜 타입, 필수
);
① INSERT INTO TAB1 VALUES(1, 10, 'AAA', SYSDATE)
1은 숫자지만 자동으로 '1'로 변환됨!
④ INSERT INTO TAB1 VALUES('0003', 40, 'CCC', '2024/01/01');
4번에서 COL4의 값은 문자상수이므로 날짜 변환 후 입력을 해야 한다. DBMS의 기본 날짜 포맷이 YYYY/MM/DD가 아닌 경우는 이 문장은 에러가 발생
46 DDL AUTO COMMIT
DDL : CREATE, ALTER, DROP, TRUNCATE
처음 INSERT 3개의 문장은 COMMIT을 수행했으므로 영구 저장된다. 이후 COL3을 추가하면 이미 입력된 세 개의 행에 대해 NULL을 갖게 된다. 그 뒤 수행하는 INSERT, UPDATE, DELETE 문장은 이어서 실행하는 ALTER TABLE DROP COLUMN 문장으로 인해 자동 확정된다.(DDL AUTO COMMIT). 따라서 ROLLBACK을 수행해도 취소되지 않는다.
49 제약조건(constraint) - UNIQUE
열에 중복허용 x, NULL 허용
기본키(PK)는 null허용도 안된다는 차이점.
-- 테이블 생성시
-- 컬럼명 type **제약조건**
CREATE TABLE USER_INFO (
USER_ID VARCHAR2(20) UNIQUE, -- 사용자 ID는 중복 불가
EMAIL VARCHAR2(50),
PHONE VARCHAR2(20)
);
-- 복합 unique
CREATE TABLE COURSE_ENROLL (
STUDENT_ID NUMBER,
COURSE_ID NUMBER,
CONSTRAINT unique_enroll UNIQUE(STUDENT_ID, COURSE_ID)
);
-- 같은 학생이 같은 과목을 중복수강하지 못하게 함
-- alter로 추가 (테이블 구조 바꿈, constraint - 제약조건 -추가)
ALTER TABLE USER_INFO
ADD CONSTRAINT unique_email UNIQUE(EMAIL);
CREATE TABLE 복제
복제시 not null 속성은 복제된다.
50 권한부여
-
WITH GRANT OPTION (오브젝트 권한)
테이블에 대한 권한부여
중간관리자 부여 - 중간관리자만 회수 가능
중간관리자에게 부여된 권한 회수 시 제 3 자에게 부여된 권한도 함께 회수 -
WITH ADMIN OPTION (시스템 권한)
시스템에 대한 권한 부여
중간관리자를 거치지 않고 직접 회수 가능
중간관리자 권한 회수해도 제 3자에게 부여된 권한은 함께 회수 X(남아있음)
중간관리자가 WITH GRANT OPTION으로 부여 받은 권한을 제 3자에게 부여한 경우, 관리자가 제 3자의 권한을 직접 회수할 수 없다. 하지만 중간관리자 권한을 회수하면 제 3자에게 부여한 권한도 함께 회수된다.
반대로 WITH ADMIN OPTION으로 부여할 경우 중간관리자 권한 회수 시 제 3자에게 부여한 권한은 함께 회수되지 않는다.
