QCC
다 맞을줄 알았는데 두개나 ㅋ 틀림 ㅋ 잉
3개중에 하나 맞은걸로 만족..한다 ㅜㅜㅜ
으악 근데 큐씨씨 할때마다 아쉬운 점
내가 뭘 맞추고 틀렸는지 말해주셨으면 좋겠다.. (번호만요..많은거바라는거 아니지않습니까..!!)
1번

진짜.. 복습을 너무 안해서 기본적인것도 기억이 안났다 ㅠㅠ
문자열 substring 써서 날짜표현하는거..
내 코드
with q1 as
(select category as ca, id
from calls
where category ='n/a' or category is null),
q2 as
(select count(c.category) as a, count (q1.ca) as b
from calls as c
left join q1 on c.id = q1.id
where substring(call_date,1,10) <= '2024-04-15')
select round(b / a * 100, 1)
from q2나는 11줄이나 나왔는데 왜 정답코드는 5줄이냐고 ~
정답코드
select
round((sum(if(category = 'n/a' or category is null, 1, 0))/
count(1)) * 100, 1) as uncategorized_call_pct
from calls
where date_format(call_date, '%Y-%m-%d') < '2024-04-16'count
일단 틀린점... count(ca)는 null값을 포함하지 않는다..
count(1)하면 전체 행 수를 세는 반면 count(ca)하면 null값을 세지않음...
효율 측면에서 substring과 with문이 있다.
substring
개선할 점..
1. substring 사용
substring을 사용하면 같은 값처럼 보이지만 date_format을 쓰는게 더 정확하다.
date_format(call_date, '%Y-%m-%d') < '2024-04-16'
with
개선할 점 2. with문 사용
q1은 하나의 열 값을 체크하는거라 굳이 join 안해도 됨!
ㅠㅠ 코드카타 열심히 해야겠다...
with문 쓰고나서 너무 코드를 길게 만들고 있는 것 같은데 주의해야겠다
2번

내 코드
with q1 as
(select user_id, event_type
from app_events
where event_type = 'order'),
q2 as
(select a.user_id, a.event_type, age_bucket,
count(case when a.event_type = 'view' then 1 end) as v,
count(case when a.event_type ='order' then 1 end) as o
from app_events as a
join q1 on a.user_id = q1.user_id
join user_profiles as u on a.user_id = u.user_id
group by age_bucket)
select age_bucket, round((o / (v+o)*100),2) as conversion_rate
from q2
order by 1와 이제보니까 가입자 조건 안걸었다...
진짜 문제읽으라고 ㅜㅜㅜㅜ 바부야
정답코드
select up.age_bucket,
round((sum(if(event_type = 'order', 1, 0)) / count(1)) * 100, 2) conversion_rate
-- 분자가 order한 수
-- 분모가 order / view 한
from user_profiles up
join app_events ap
on up.user_id = ap.user_id
where up.signup_date >= '2023-01-01'
and event_type in ('order', 'view')
group by 1
order by 1select문에 count(1)이 있길래 조건 걸어줘야하는거 아닌가 했더니
where절에 and 뒤에 in()이 있었다. 와 진짜 안한지 너무 오래돼서 ㅠㅠ 정말 다 까먹었다
in
in은 값이 조건안에 있는가를 확인하는 연산자
or을 여러번 쓰는걸 간단하게 줄여줌.
3번

내 코드
with q1 as
(select user_id, order_datetime,
row_number() over (partition by user_id order by order_datetime) as c
from user_orders),
q2 as
(select user_id, c, order_datetime
from q1
where c = 10),
q3 as
(select q1.user_id, q1.order_datetime as f, q2.order_datetime as e
from q1
join q2 on q1.user_id = q2.user_id
where q1.c = 1)
select user_id, datediff(e,f) as days_to_power_user
from q3
order by days_to_power_user
limit 1정답코드
select user_id,
datediff(tenth_ordertime, order_datetime) days_to_power_user
from (
select user_id
, order_datetime -- n번째 주문
, lead(order_datetime, 9) over
(partition by user_id order by order_datetime) as tenth_ordertime -- n+9번째 주문
, row_number() over (partition by user_id order by order_datetime) as seq -- n
from user_orders
) a
where seq = 1 and tenth_ordertime is not null
order by 2
limit 1이거 하나 맞췄다..!!
진짜 튜터님 코드 보면 아맞다의 연속임 ㅋㅋ..흐어어
lead
나는 10개를 다 뽑았는데 lead()함수로 현재 주문에서 9개 뒤 (=10번째 주문)를 뽑은것.
과제
1번
statistics csv 파일을 읽고, Category 기준 Customer ID 컬럼은 Count, Purchase Amount(USD) 컬럼은 Sum 연산을 진행해주세요. 동시에 2가지 연산을 진행해주세요. (한번의 group by)
한번에(동시에) 두가지 연산하는 법 저번 과제에서 튜터님이 알려주셨는데
여전히 기억안나서 다시 확인하러 감.. agg였던거같은데 어떻게 쓰는지 잘 기억나지 않았다
agg function
DataFrame.agg({
'컬럼1': 함수 또는 [함수들],
'컬럼2': 함수 또는 [함수들],
...
})
df.agg({
'점수': ['mean', 'max'],
'시간': 'sum'
})
agg함수는 딕셔너리 형태로 컬럼과 함수를 넘겨줘야함!
함수 쓸 때도 '' 쓰는거 잊지말기
줄바꿈
괄호 {}, (), [] 안에서는 마음껏 줄 나눠도 된다
2번
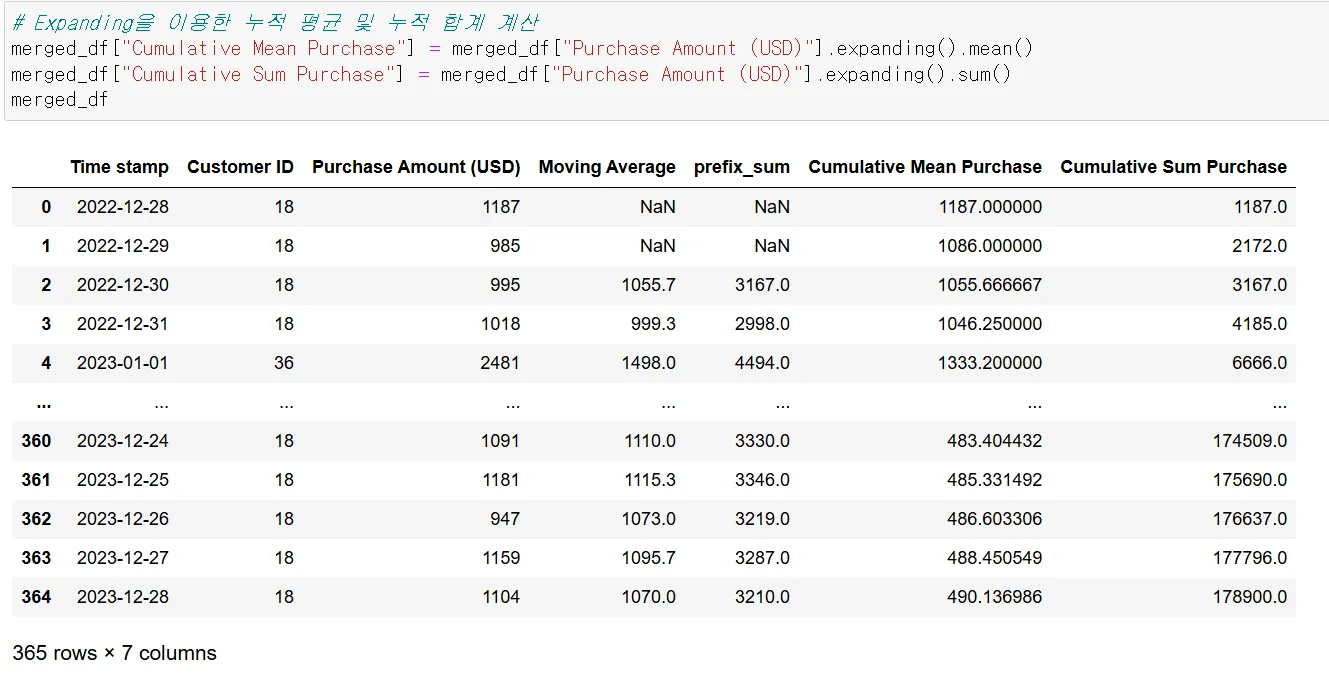
Expanding 메서드를 이용하여, Purchase Amount (USD) 의 누적 합을 계산해주세요.
그리고 결과값을 df의 “Purchase Amount (USD)_누적” 컬럼으로 새롭게 지정해주세요. 그리고 Purchase Amount (USD) 과 함께 보여주세요.
expanding을 사용하라 했는데 기억이 ㅋㅋ 안나는데 어떡해요..
expanding
(standard 3회차)
- 문법
df.expanding(min_periods=1, axis=0, method='single').추가메서드()
- 주요 파라미터
- min_periods: 연산을 수행할 요소의 최소 갯수입니다. 이보다 작으면 NaN을 출력
- axis : 연산할 축방향 설정. 0(행) / 1(열)
- method: 연산방식.
single(연산을 한 줄씩 수행)
table(전체 테이블에 대해서 롤링수행).
기본값 single , 롤링 연산할 경우 numba 라이브러리 추가로 import 필요.
3번
성별 Review Rating 에 대한 평균과 중앙값을 동시에 구해주세요. 결과는 소수점 둘째자리까지 표현해주세요. 그리고 이에 대한 해석을 간략하게 설명해주세요.
평균과 중앙값 보고 해석하기
4번
T-TEST
성별, Review Rating 컬럼에 대한 T-TEST 를 진행해주세요.
- 해당 데이터셋의 컬럼들은 정규성을 만족한다고 가정하겠습니다.
(T-TEST 진행시, equal_var=True 로 지정해주세요.)
- 귀무가설과 대립가설을 작성해주세요.
- t-score, P-value 를 구해주세요. 단, t값의 부호는 어느 집단의 평균이 더 높은지에 대한 방향성에 대한 내용이므로, 아래와 같이 해석해주세요.
- t > 0: 첫 번째 그룹 평균이 더 큼
- t < 0: 두 번째 그룹 평균이 더 큼
귀무가설: 성별과 Review Rating은 관련이 없다
대립가설: 성별과 review rating은 관련이 있다. (여자가 크다?..)
관련으로 가설을 짓는게 맞나..?
급.. 헷갈리는점 남자가 여자보다 review rating을 높게 준다 이런식으로 하면 안된다고 했던거같은데... 아티클쪽이었던듯
코드
# 오류코드
fr = df['Gender' == 'Female']['Review Rating']
mr = df['Gender' == 'Male']['Review Rating']
# 독립표본 t검정
t_stat, p_val = stats.ttest_ind(fr, mr)
print(f"T-Statistic: {t_stat}, P-value: {p_val}")
# 정답코드
fr = df[df['Gender'] == 'Female']['Review Rating']
mr = df[df['Gender'] == 'Male']['Review Rating']
# 독립표본 t검정
t_stat, p_val = stats.ttest_ind(fr, mr)
print(f"T-Statistic: {t_stat}, P-value: {p_val}")
이바보야... 오류나서 Gender = Female도 해봄 ㅋㅋ
'Gender' == 'Female' 이건 항상 False! 당연함 문자열 비교임 ;
T-TEST가 뭐더라.....
T-TEST
두 집단의 평균이 통계적으로 차이가 있는지 확인하는 방법
관찰한 두 그룹의 평균 차이가 우연히 생긴 차이인지, 진짜로 의미 있는 차이인지 확인
t값이 크다 = 평균 차이가 크다
T-test에서 귀무가설과 대립가설
- 귀무가설 : 두 평균의 차이가 없다
여자와 남자의 review rating의 평균의 차이가 없다
여자와 남자의 평균 리뷰 점수는 같다 - 대립가설 : 두 평균의 차이가 있다
여자와 남자의 review rating의 평균은 차이가 있다
여자와 남자의 평균 리뷰 점수는 다르다
T-Statistic: -0.5097147504896427
t값이 음수이므로 남자의 평균리뷰 점수가 더 크다
p-value
귀무가설이 참일때, 이것(관측)이 운으로 생길 확률
귀무가설이 참일때, 관측값(또는 더 극단적인 값)이 일어날 확률 = p-value
p값이 작다 = 귀무가설이 참일 때, 관측값(또는 극단적인 값)이 일어날 확률이 작다 -> 귀무가설 기각
귀무가설이 참 = 남자와 여자의 평균차이 0
우리가 관측한 평균 차이 = 0.05
만약 진짜로 두 그룹의 평균이 똑같은데(귀무가설이 참인데)
샘플을 우연히 뽑았을 때 평균 차이가 0.05, 또는 그 이상 벌어질 확률이 얼마나 될까?가 P-value
P-value: 0.6102801734916257
평균의 차이가 0.05, 또는 그 이상 나타날 확률이 60%다.(흔한 일이다)
이는 유의수준 0.05보다 훨씬 높다 -> 귀무가설을 기각할 수 없다(근거가 없음)
귀무가설(여자와 남자의 평균 리뷰 점수는 같다)을 기각하는게
의견주장(여자와 남자의 평균 리뷰 점수는 다르다)에 근거가 되는데
p-value가 높다= 귀무가설이 참일때 관측값(또는 극단적인 값)이 나타나는 일이 흔하다
= 통계적으로 유의미한 차이(평균 점수 차이)가 없다
p-value가 0.61로 유의수준 0.05보다 크기 때문에,
관측된 평균 차이(0.05)는 ‘우연히 생길 수 있는 흔한 수준의 차이’이며,
통계적으로 유의미하다고 볼 수 없다.
→ 따라서 귀무가설(남자와 여자의 평균 점수는 같다)을 기각할 수 없다.
통계 3주차 유의성검정
두 집단 간 평균 차이의 크기와 방향을 나타냄
독립표본 vs 대응표본으로 나뉨. 대응 = 사전/사후 평균 비교
- 귀무가설(h0): 우리 가설 의미없다(차이가 없다, 효과가 없다. -신약은 기존약과 효과차이가 없다-)
- 대립가설(h1): 의미 있다(차이가 없다, 신약은 기존 약보다 효과가 있다)
귀무가설을 기각할 지를 결정하는 것.
p-값: 귀무가설이 참일때, 관찰된 결과 이상으로 극단적인 결과가 나올 확률.
p_val이 0.05보다 낮으면 우연히 벌어진 일이 아님을 시사.
p-가 유의수준보다 작다면 귀무가설을 기각한다(= 귀무가설이 틀렸다고 보고 대립가설을 채택한다.)
