A Star 알고리즘
Q. AI 어디 위에서 길을 찾을까?
A. Graph 위에서 움직인다.
Node 설계
Node 데이터 구조
bool walkable: 지나갈 수 있는지 여부Vector2 position: Node 좌표int gCost: 시작점부터 현재 위치까지int hCost: 현재위치에서 목표까지 (휴리스틱; heuristic "경험적인, 스스로 발견하게 하는"이라는 뜻)int fCost: gCost + hCost. 시작위치에서 목표까지의 예상 값Node parent: 이전 Node. 경로 역추적을 위함.
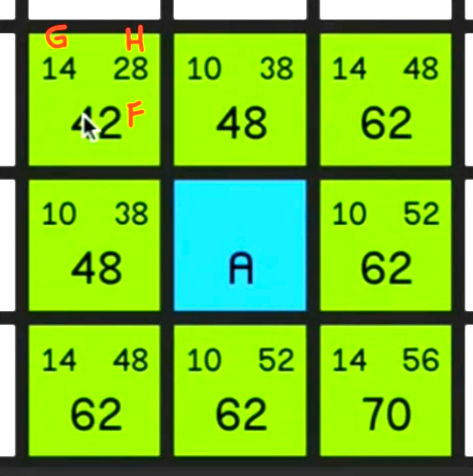
-> Node 를 알면, Grid는 Node 들의 집합체임을 알 수 있음.
Q. 노드 하나로 길찾기 가능?
A. 불가능. 하나 이상의 노드가 필요하며 노드간 연결 필요.
Q. 현재 노드 어디로 갈 수 있음?
A. 4방/8방
Dijkstra
gCost만 사용.
- 시작점
- 주변 확장
- 거리 기록
Q. Node 가 퍼져 나가려면 코드에서 있어야할 데이터는?
A. 방문한 Node
List OpenList: 순회 가능. Index 접근HashSet Closed: 빠른 검사를 위해. 재방문 처리.
Q. Step 함수에서 어떤 일이 일어나야 할까?
A.
- OpenList 에서 어떤 것을 꺼내야 하지?
- 꺼낸 노드는 어디로 가지?
- 이웃 노드는 어떻게 처리하지?
- 이동 비용은 어떻게 계산되지?
문제점
목표를 찾는 방식이 비 효율적임. ->
휴리스틱을 포함한A* 알고리즘탄생
A* 설계
A*는 목표 지점 방향으로 퍼짐 -> 필요 영역 우선 탐색
hCost
S ... T
S = (0, 0)
T = (4, 0)현재 노드 좌표 (1, 0) -> 타겟까지 우측 3칸 => hcost = 3; (맨하튼 거리를 이용한 계산)
Q. 왜 맨하튼 거리?
- ex)
- 현재 위치 (1, 2)
- 타겟 위치 (4, 5)
// |4 - 1| + |5 - 2|
hCost = 6Previous Node
S -> A -> B -> C -> TS.previous = null;
A.previous = S;
B.previous = A;
C.previous = B;
T.previous = C;정리
Node- 데이터 기본 구조
1) Walkable
2) Position
3) gCost / hCost / fCost
4) Previous
OpenList; PriorityQueue. 확인할 Node 데이터
ClosedSet; 재방문 확인
다잌스트라- gCost 로만 판단
A*- fCost 판단. fCost 가 동일할 경우 hCost 판단경로는 Node 에 boolean 을 넣던가, 따로 Path 전용 데이터 관리를 하는 것이 좋음.
추가
PriorityQueue 란
https://learn.microsoft.com/ko-kr/dotnet/api/system.collections.generic.priorityqueue-2?view=net-8.0
Queue 에 Priority 를 추가한 내용이다.
PriorityQueue 를 쓰면 더 좋은 이유?
fCost 값이 낮은 순으로 데이터를 뽑아와야 한다. PriorityQueue 의 Dequeue는 우선순위가 낮은 데이터를 먼저 뽑는다.
즉, List 등으로 Loop 를 돌며 데이터를 뽑을 필요 없이 Dequeue만으로도 데이터를 획득 가능하며, 시간 복잡도도 낮아지는 효과를 얻을 수 있다.
