머리말
아무래도 나는 인프라 쟁이였으니까.. 결국 AI 를 운용하는데 있어 기업에서는 어떻게 운영할지에 대해 생각해보았다. Public Cloud 와 Private Cloud 에서는 결국 비슷해도 다르게 운영할테지만 Kubernetes 를 활용하지 않을 수 없을테니 포함해서 GPT 에게 물어보았다.
Public Cloud
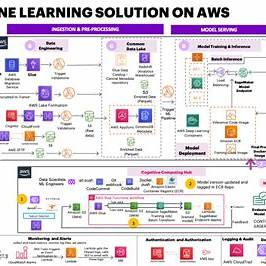
 - 출처: AWS
- 출처: AWS
아키텍처 사례 상세 분석
1. AWS 기반 엔터프라이즈 ML/딥러닝 플랫폼
- Ingestion & Pre-processing: S3, Kinesis, Lambda 등을 통해 데이터 수집
- Model Training & Serving: SageMaker 또는 EC2, Auto Scaling 기반 모델 학습 및 배포
- Monitoring & Governance: CloudWatch, IAM, CloudTrail 등을 통한 안전·운영 감시
2. 구글 클라우드(GCP) 기반 RAG 앱
- Ingestion: Cloud Run → 외부 데이터 수집 및 파싱
- Embedding 저장소: AlloyDB + pgvector
- 검색·Serving: Cloud Run API → 질문에 맞는 유사 텍스트 추출 및 LLM 엔진 호출
- 품질 검사(Subsequent service): 응답 정확도 평가, 로깅, 모니터링 포함
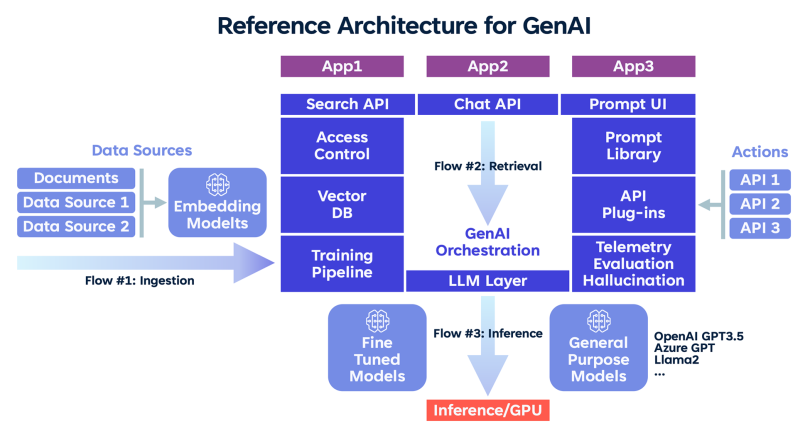
3. BMC의 GenAI 오케스트레이션 레이어
- Search API / Chat API / Prompt UI: 사용자 인터페이스 구성
- LLM Layer: 다양한 모델을 배치하거나 추론
- Azure OpenAI, fine-tuned model 등 다양한 모델을 골라 배포 가능
4. 핵심 구성 요소 (공통 분모)
| 모듈 | 설명 |
|---|---|
| 데이터 수집(Ingestion) | 웹/DB/API/파일 등에서 원천 데이터 확보 |
| 전처리 + 임베딩 저장(Index) | 유의미한 단위로 분할 후 벡터화, 검색 최적화 |
| 검색/튜닝(RAG) | 벡터 검색 + LLM 프롬프트 준비, hallucination-방지 |
| LLM 실행(Inference) | 클라우드 GPU나 로컬/온프레미스에서 자연어 응답 생성 |
| 모니터링 & 거버넌스 | 성능, 보안, 비용, 사용자 피드백 관리 |
Private Cloud
Private Cloud AI 아키텍처 구성
| 구성 요소 | 설명 |
|---|---|
| 온‑프레미스 서버/VM | GPU 서버(NVIDIA), 가상 머신, 베어메탈 |
| 스토리지 | 사내 파일 저장소(NAS/SAN) 또는 분산 파일 시스템 |
| 네트워크 | 내부망, 방화벽, 로드밸런싱, VLAN |
| 컨테이너/오케스트레이션 | Docker, Kubernetes 등 자원 관리 |
| 임베딩 서비스 | 입력 데이터를 임베딩해 벡터 데이터베이스 준비 |
| RAG 검색 | FAISS, ElasticSearch + vector 플러그인 등의 벡터 검색 엔진 |
| LLM 추론 인프라 | 로컬 GPU에 LLM 배포 (예: Mistral-7B, KoAlpaca) |
| API/서비스 레이어 | RESTful 또는 gRPC로 외부 요청 처리 |
| 모니터링 & 거버넌스 | 로깅, 인증(RBAC), 보안 감시 체계 |
| 데이터 파이프라인 | ETL/ELT, 배치 ingest, 큐(예: Kafka, RabbitMQ) |
🧩 핵심 흐름 요약
1. 데이터 수집 및 전처리
사내 문서나 웹 크롤링을 통한 콘텐츠 확보 → 텍스트 정제 → 저장소 적재
2. 임베딩 처리 & 저장
문서에서 필요한 단위(chunk)를 임베딩 → 벡터 DB(예: FAISS, pgvector)에 저장
3. 유사 문장 검색 (RAG)
사용자 질문이 벡터화되어 → 벡터 DB에서 Top-K 유사 컨텍스트 추출
4. LLM 추론
검색된 컨텍스트 + 질문이 프롬프트로 구성되어 로컬 LLM에 전달
5. 응답 반환
추론된 결과를 응답으로 패키징해 사용자에게 전달 (API 레이어)
6. 감시 및 거버넌스
요청 로깅, 출력 검증, 보안 검사, 리소스 사용 모니터링
🔐 Private Cloud 환경의 장점
- 완전한 내부 제어: 민감 데이터 유출 방지
- 지연시간 이점: 로컬망에서 빠른 응답 가능
- 맞춤형 구성: 하드웨어, 모델 등을 자유롭게 구성 가능
⚠️ 주의할 점
- 운영 복잡도: 하드웨어/소프트웨어 운영 및 유지보수 부담
- 확장성 한계: 수요 급증시 인프라 확장 어려움
- 비용/자원 제약: 초기 설치비, GPU 확보, 전기/냉각 비용
AI Infra on Kubernetes
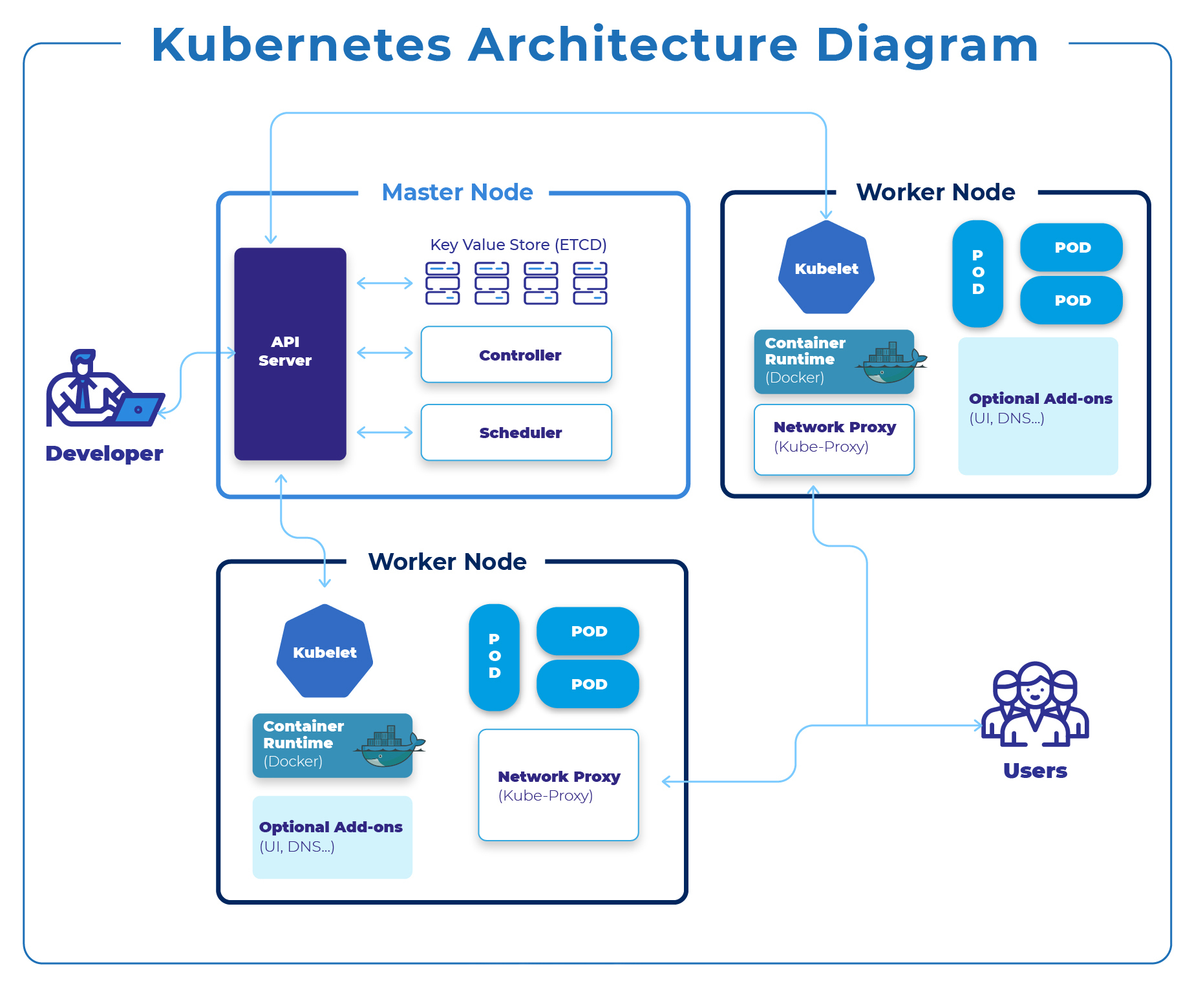
- 출처: https://dzone.com/articles/kubernetes-architecture-diagram
- 위 그림은 기본적인 Kubernetes 에서 사용자에게 서비스를 할 때의 간략화 된 구성도이다. (생각보다 이쁘게 잘 되어있)
AI Infra on Kubernetes – 핵심 구성 요소
Control Plane (마스터 노드)
- kube-apiserver, etcd, scheduler, controller-manager 등으로 이루어져 있으며 클러스터 상태를 관리
- API 요청 수락, 스케줄링, 리소스 원하는 상태 유지 등이 주요 역할입니다.
Worker Nodes (작업 노드)
- 각 노드에는 kubelet, 컨테이너 런타임, kube-proxy와 사용자 애플리케이션이 실행되는 Pod이 위치
- 실제 AI 서비스(RAG, LLM, ETL, API 등)가 이곳에서 돌아갑니다.
GPU 지원 및 자원 관리
- GPU는 NVIDIA GPU Operator 같은 GPU 관리 툴로 설정
- AI 추론 및 학습 워크로드는 GPU가 할당된 Pod에서 수행됩니다
ML/AI 워크플로우 도구
- 종종 Kubeflow 같은 오픈소스 툴을 사용하여 Pipeline, 트레이닝, 서빙, 하이퍼파라미터 튜닝 등을 자동화
- KServe, Katib, Notebooks 등 모듈을 통해 엔드투엔드 ML 환경 구성
서비스 메시 & 네트워킹
- CNI 플러그인(e.g., Calico, Cilium)과 서비스 메시(Istio, Linkerd 등)를 사용해 네트워킹과 보안 강화
CI/CD 및 워크플로우 자동화
- Argo, Tekton, Airflow 등의 툴로 모델 학습 → 빌드 → 배포 자동화
- KubernetesPodOperator 등으로 AI 태스크를 스케줄링
⚙️ 왜 Kubernetes를 AI용 플랫폼으로 많이 쓰는가?
- 확장성: 여러 노드에 걸친 자동 스케일링 가능
- 리소스 효율성: CPU, 메모리, GPU 등 자원 쪼개서 다중 워크로드 동시 운영
- 이식성: 온프레미스 → 클라우드 → 엣지까지 일관된 운영 가능
- 자동화: 롤링 업데이트, self-healing, 데드라인 재시작 등 AI 작업의 신뢰성을 보장
Overall
🔍 비교 정리
| 기능/특징 | Public/Private Cloud Infra | Kubernetes 기반 AI Infra |
|---|---|---|
| 인프라 제어 | Public: CSP 관리 / Private: 온프레미스 직접 운영 | 쿠버네티스 클러스터 중심 운영 |
| 확장성 및 이식성 | Public: 자동 확장용이 / Private: 필요시 수동 증설 | XL Node 자동 스케일링 |
| 컨테이너 오케스트레이션 | VM 중심, 쿠버네티스 optional | 기본 구성, 쿠버네티스 핵심 |
| ML 파이프라인 | 수동 배치 + 스크립트 조립 | Kubeflow 등 자동화 도구 활용 |
| 거버넌스 · 보안 | CSP 또는 사내 보안 정책 따름 | 네임스페이스, RBAC, 네트워크 정책 적용 |
🤨음..?
GPT가 정리를 나름 깔끔하게 해주었는데, Kubernetes 기반 인프라에 대한 이야기가 껴서 그런지 Private Cloud 에서는 Baremetal 이나 VM 등을 기반으로 한 내용으로 정리가 되어 버렸다.
자동화 대세인 인프라 Domain 에서 AI 인프라에서 인프라쟁이들이 해야할 일이 무엇인지도 한번 고민해 보도록 하자.

Python Dev with Infra