
🎯 목표
- 사용자가 웹사이트 URL을 입력하면,
- 해당 페이지의 텍스트 콘텐츠를 추출해
- 의미 기반 문장 검색(RAG) + 로컬 LLM으로 응답을 생성하는 AI 만들기
🧩 전체 구성 요약
| 단계 | 설명 | 사용 도구 |
|---|
| 웹 텍스트 수집 | HTML 페이지에서 본문만 추출 | requests, BeautifulSoup |
| 문장 분할 및 임베딩 | 의미 벡터로 변환 | sentence-transformers |
| 유사 문장 검색 | 질문 벡터와 가장 가까운 문장 찾기 | FAISS (벡터 인덱싱) |
| 자연어 응답 생성 | 사용자 질문에 대해 부드러운 답변 생성 | llama-cpp-python + Mistral 모델 |
🔎 실습 내용 요약
여기 까지..
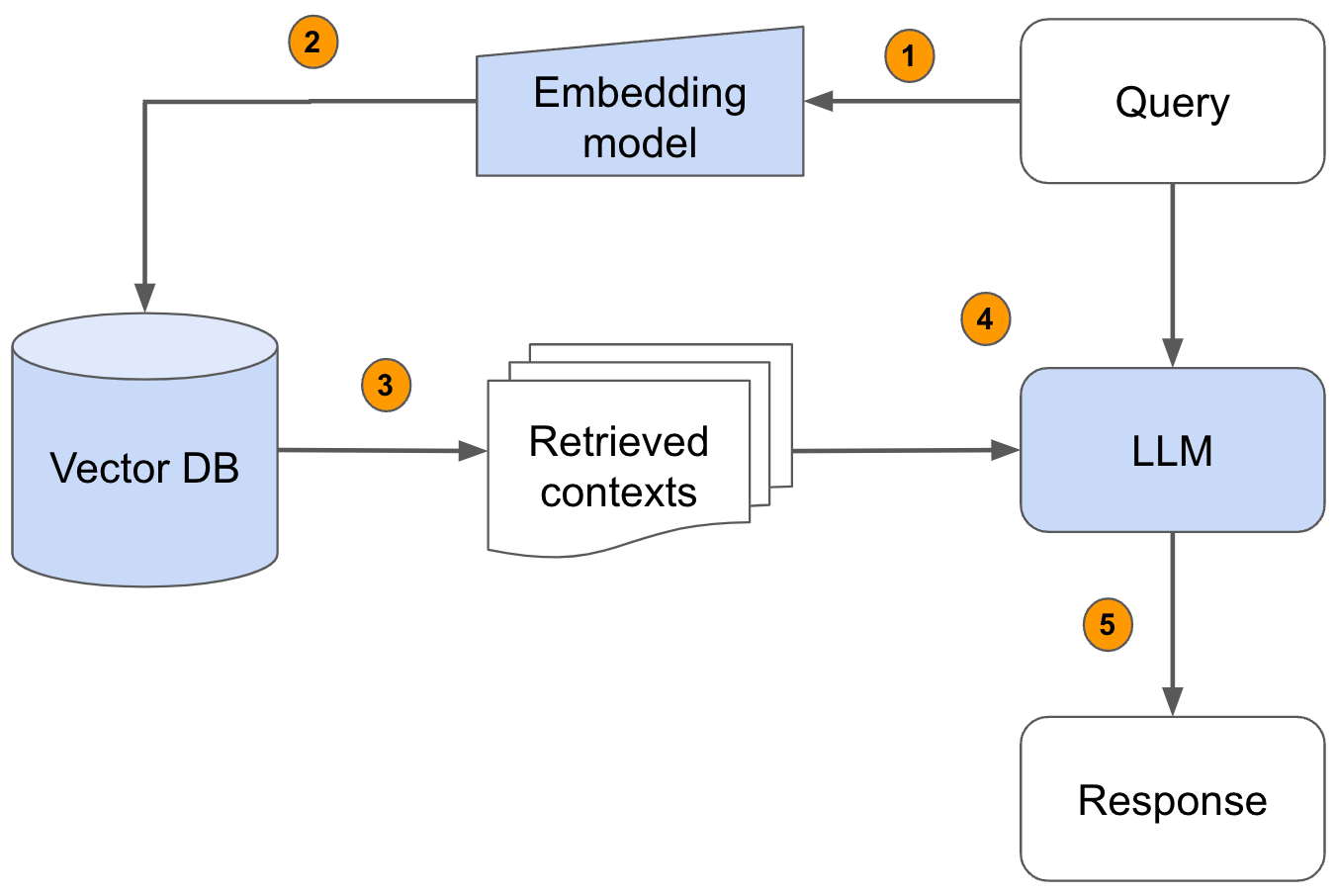
- 사용자 질문 (Query)
자연어 입력 형태로 질문이 들어옵니다.
- 임베딩 모델 (Embedding Model)
질문과 문서의 각 텍스트 chunk를 벡터로 변환합니다.
- 유사도 검색 (Retrieve Relevant Contexts)
질문 벡터와 문서 벡터를 비교해 가장 관련 있는 문장(들)을 선택합니다.
- LLM에 전달 (LLM)
검색된 컨텍스트와 원 질문 합쳐서 LLM(로컬 Mistral 등)에 전달합니다.
- 최종 응답 생성 (Response)
LLM이 자연스럽고 논리적인 답변을 생성해 사용자에게 전달합니다.
가장 기본적인 AI 실습이며, 현존 LLM 관련 개발에서 자주 쓰이는 Diagram 이라고 한다. 이에 대한 "기업"에서의 중요도에 대한 정리는 다음과 같다.
✅ 1위: 문서 검색 (Retrieval Quality)
이유:
- LLM은 입력된 컨텍스트(context)에 기반해서만 답변합니다.
- 즉, 잘못된 문장을 주면 LLM도 틀린 답을 냅니다.
- 기업에서는 “정확한 정보에 근거한 답”이 핵심 (예: 고객지원, 의료정보 등)
기업 관점 중요 요소:
| 항목 | 설명 |
|---|
| 문장 자르기 방식 | 몇 줄 단위로 나눌지, 중복 포함할지 등 |
| 유사도 기준 | cosine? Euclidean? dense embedding? |
| 벡터 품질 | 어떤 embedding 모델을 쓰느냐 (e.g. BGE, E5, KoSimCSE) |
| 다중 문장 조합 | top-3 문장 뽑고 연결하기 등 |
✅ 2위: 프롬프트 구성 (Prompt Engineering)
이유:
- 같은 정보라도 프롬프트를 다르게 주면 답변 품질이 완전히 달라짐
- 신뢰도, 말투, 형식, 분량, 법적 책임 문구까지 조정 가능
기업 관점 중요 요소:
| 항목 | 설명 |
|---|
| 정제된 어투 | 고객 대응용인지, 사내 회의용인지 |
| 추측 방지 | "추측하지 말고 문서 기반으로만 답해" 같은 문구 |
| 출처 포함 | "출처 문장을 함께 보여줘" 등 |
| 포맷 | "요약 3줄 + 핵심 키워드 리스트" 형태 지정 등 |
✅ 3위: 거버넌스 / 안전성 (신뢰도 & 책임 회피)
이유:
- 기업용 AI에서 가장 무서운 건 사실이 아닌 말(환각 hallucination)
- 이를 피하기 위해 "문서 기반 답만 하라"거나 "출처도 함께 제시" 요구함
✅ 나머지 (상황별 중요)
| 항목 | 중요 상황 |
|---|
| 임베딩 품질 | 사내 문서가 많고 복잡한 경우 |
| LLM 응답 시간 | 실시간 응답 챗봇 등 |
| 비용 제어 | API 사용시 또는 대규모 사용 |
| UI 설계 | 챗봇 또는 검색 UI 제공 시 |
🎯 요약 정리
| 순위 | 기업이 중요시하는 모듈 | 이유 |
|---|
| 1️⃣ | 문서 검색 정확도 | 답변 품질의 70% 이상을 결정 |
| 2️⃣ | 프롬프트 구성 전략 | 컨트롤 가능성과 신뢰도 확보 |
| 3️⃣ | 신뢰도 / 책임 회피 | 법적/품질 위험 최소화 |
