정규화
목표: Regularization의 의미와 기법들에 대한 이해

Regularization
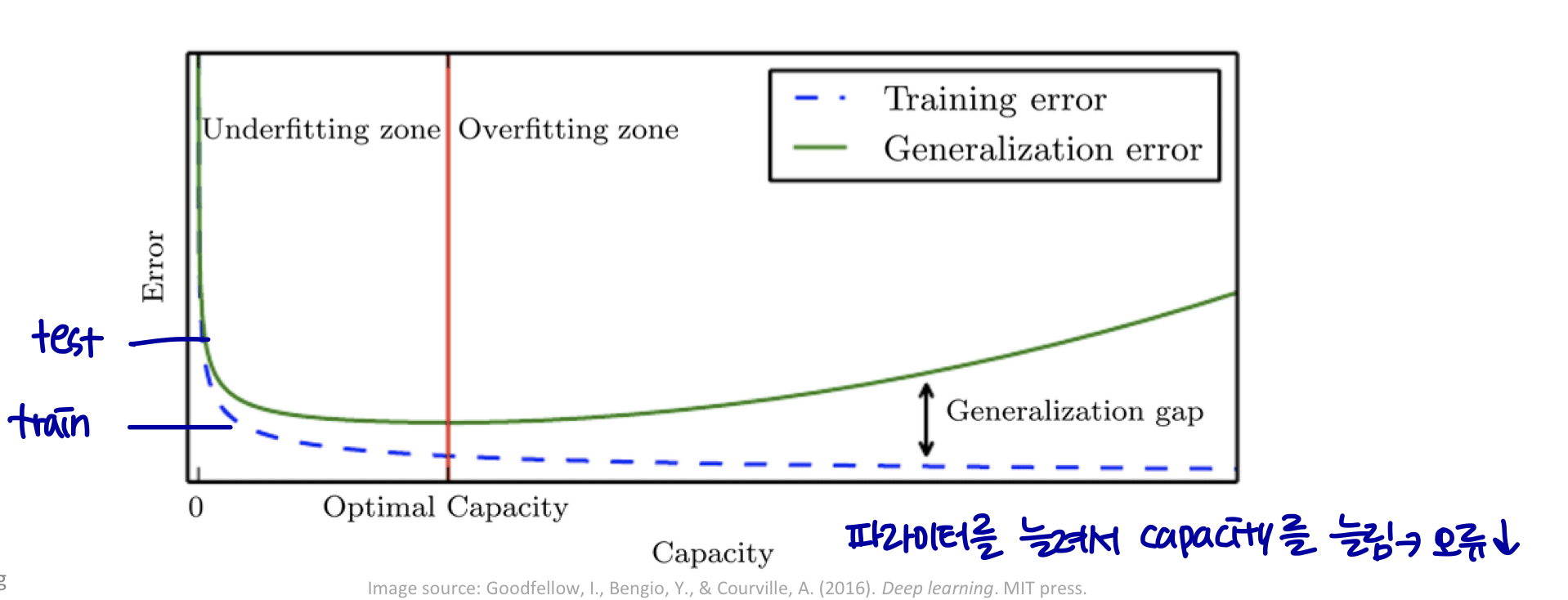
- 테스트 에러를 줄이는 전략 (= 일반화 오류)
-
train error가 증가할 수 있다.
-
왜? → 머신러닝의 목적은 트레이닝 데이터 뿐만 아니라 새로운 입력에서도 성능을 향상시키는 것이기 때문이다.
-
Regularization strategies
-
머신 러닝 모델에 추가적인 제약을 가한다.
- 매개변수 값에 대한 제한 추가 등
-
객체 함수에 extra term 추가
- 매개변수 값에 대한 소프트 제약
-
학습 데이터를 설명하는 여러 가설 결합
- 앙상블 기법
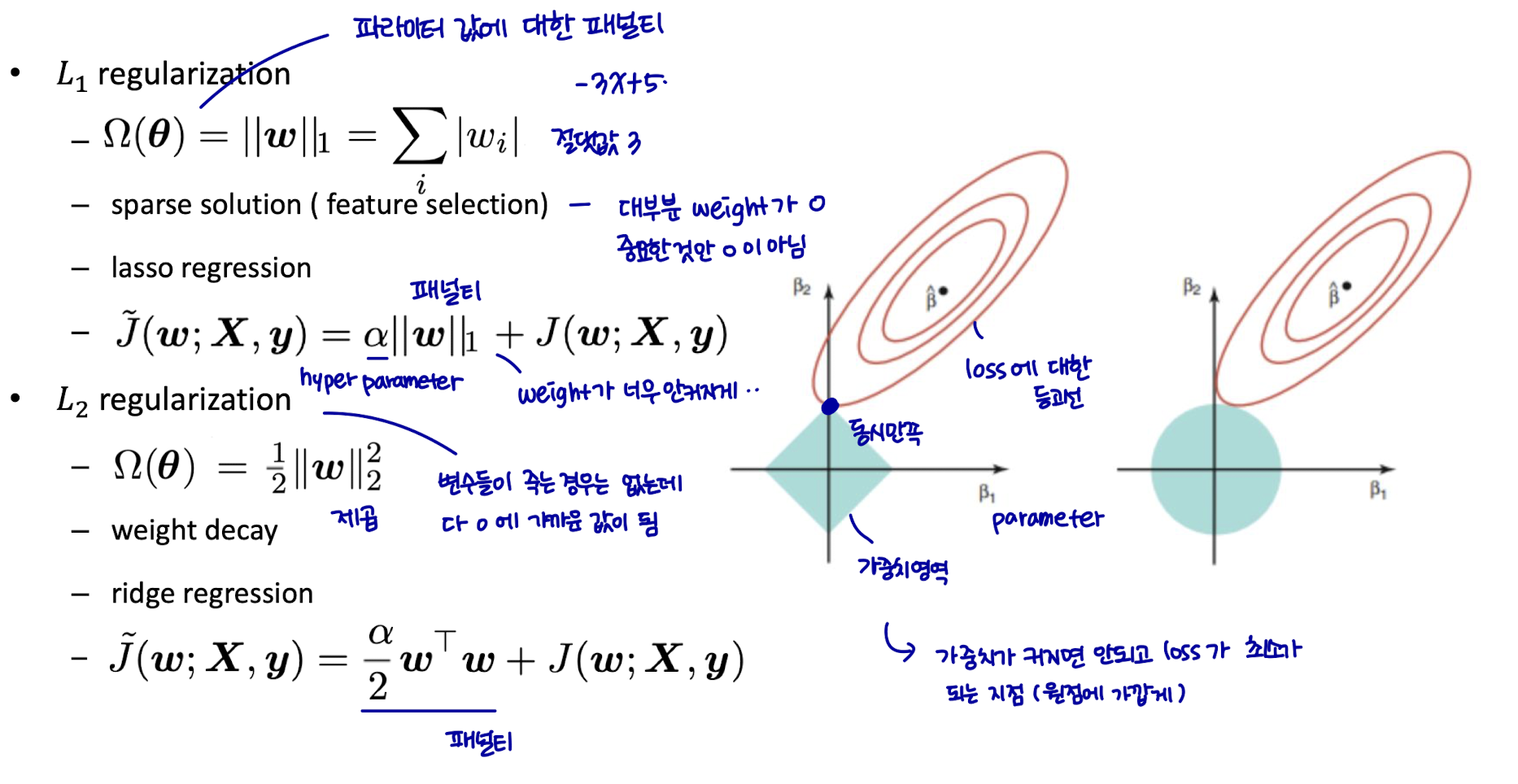
Parameter Norm Penalty
-
정규화는 딥러닝이 등장하기 수십 년 전부터 사용되어 왔다.
-
linear regression 과 logistic regression과 같은 선형 모델은 효과적인 정규화 전략이다.
-
모델 용량 제한
-
객체 함수 J에 매개변수 놈 패널티 Ω(θ) 추가 (e.g. 파라미터 값 안커지게, 개수 제한..)
-
가중치에만 패널티를 부여한다. (weight가 안커지도록 하는 패널티)
-
편향(bias)은 일반적으로 가중치보다 정확히 맞추기 위해 더 적은 데이터가 필요하다.
-
-

Parameter Norm Penalty
-
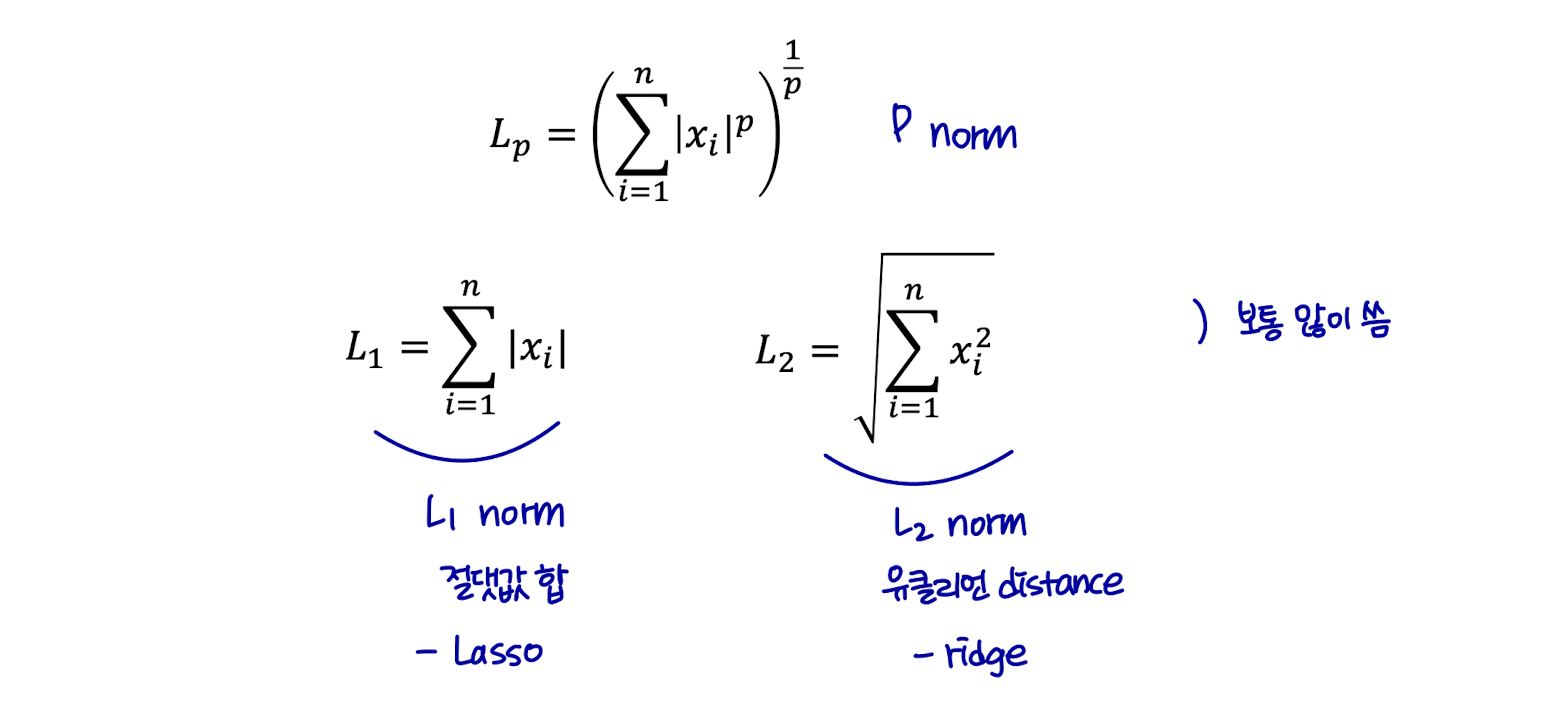
Norm?
- 실수 또는 복소수 벡터 공간에서 원점으로부터의 거리와 같은 특정 방식으로 동작하는 음이 아닌 실수에 대한 함수이다.
Parameter Norm Penalty
Parameter Norm Penalty
Parameter Norm Penalty → weight가 안커지도록 하는 패널티
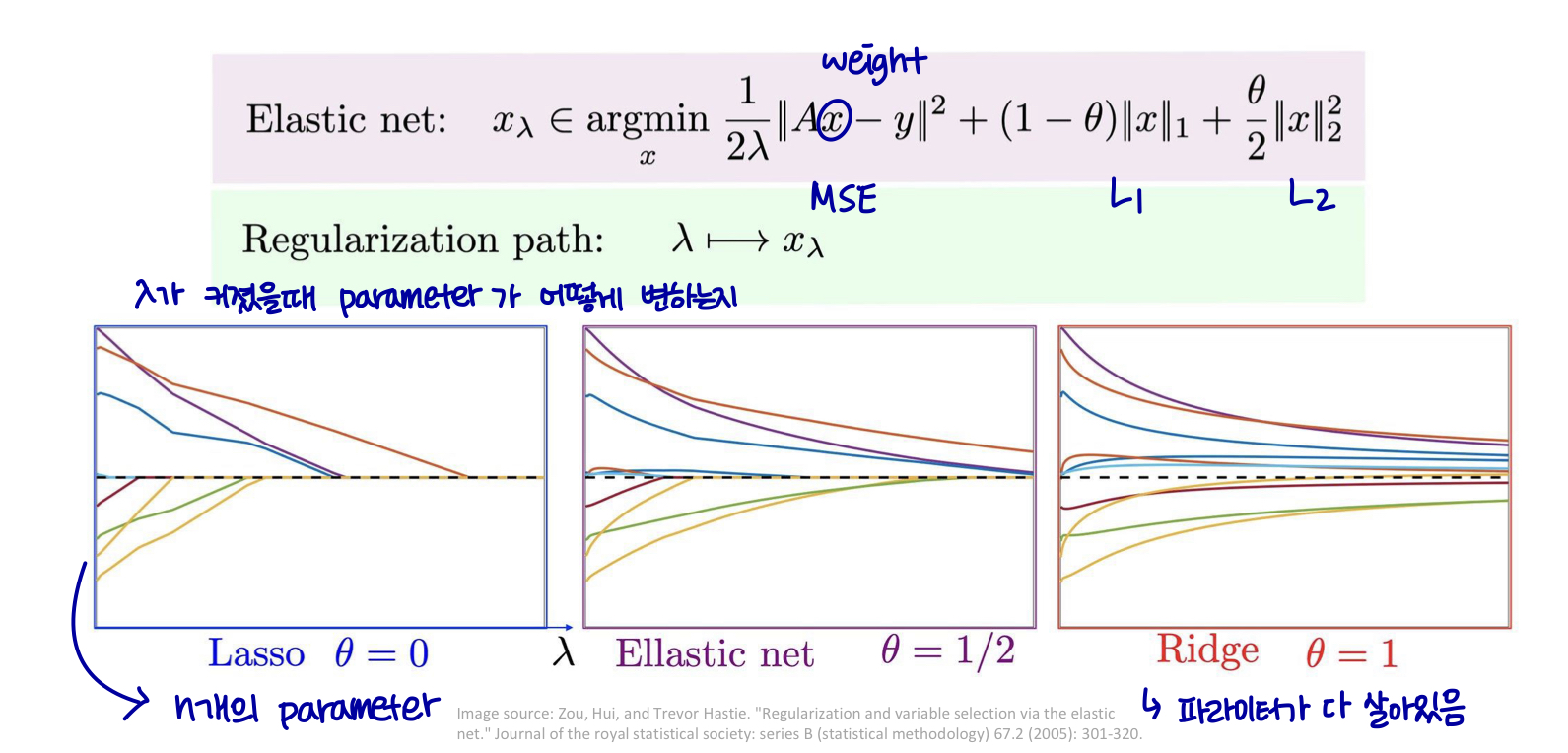
Weight decay
weight를 업데이트할 때 새로운 weight는 이전 weight에 1보다 작은 값이 곱해져 절댓값이 줄어들고 loss값이 새로 업데이트 된다.
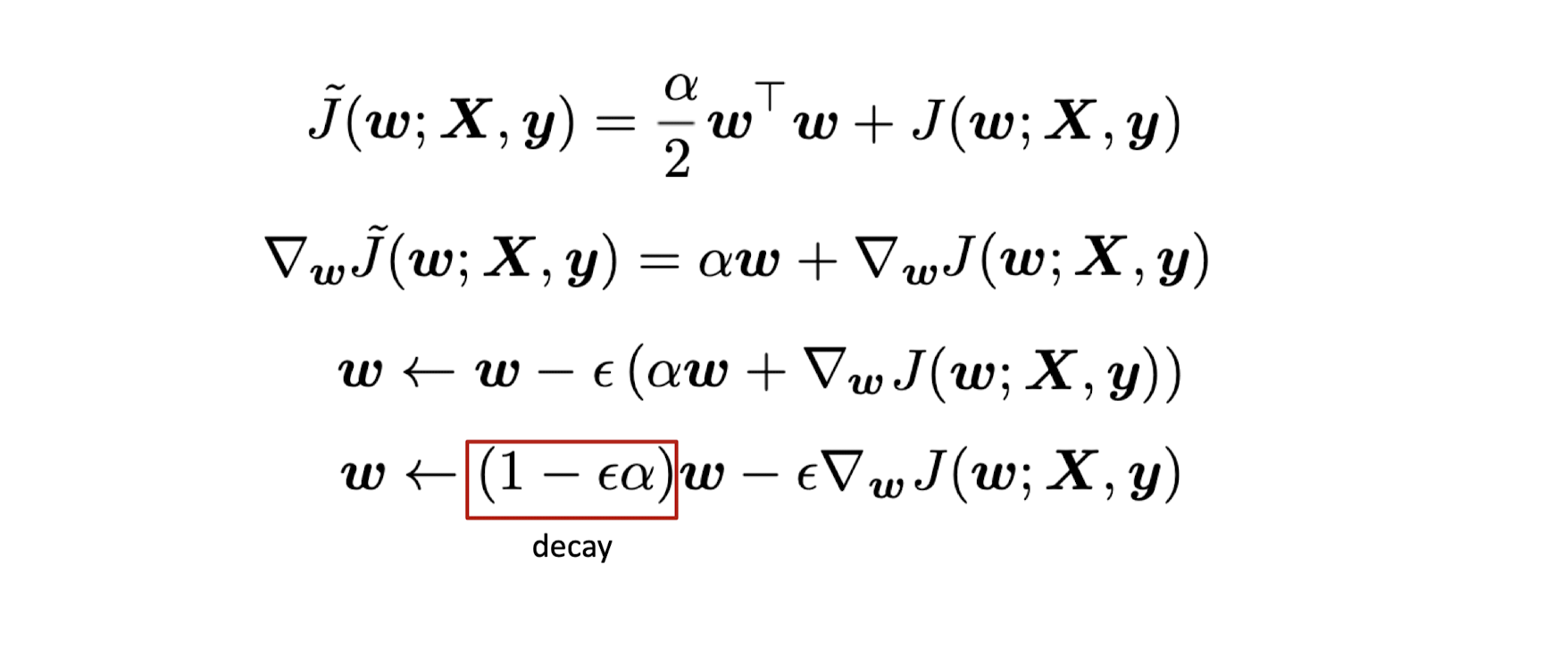
Effect of Norm Penalty
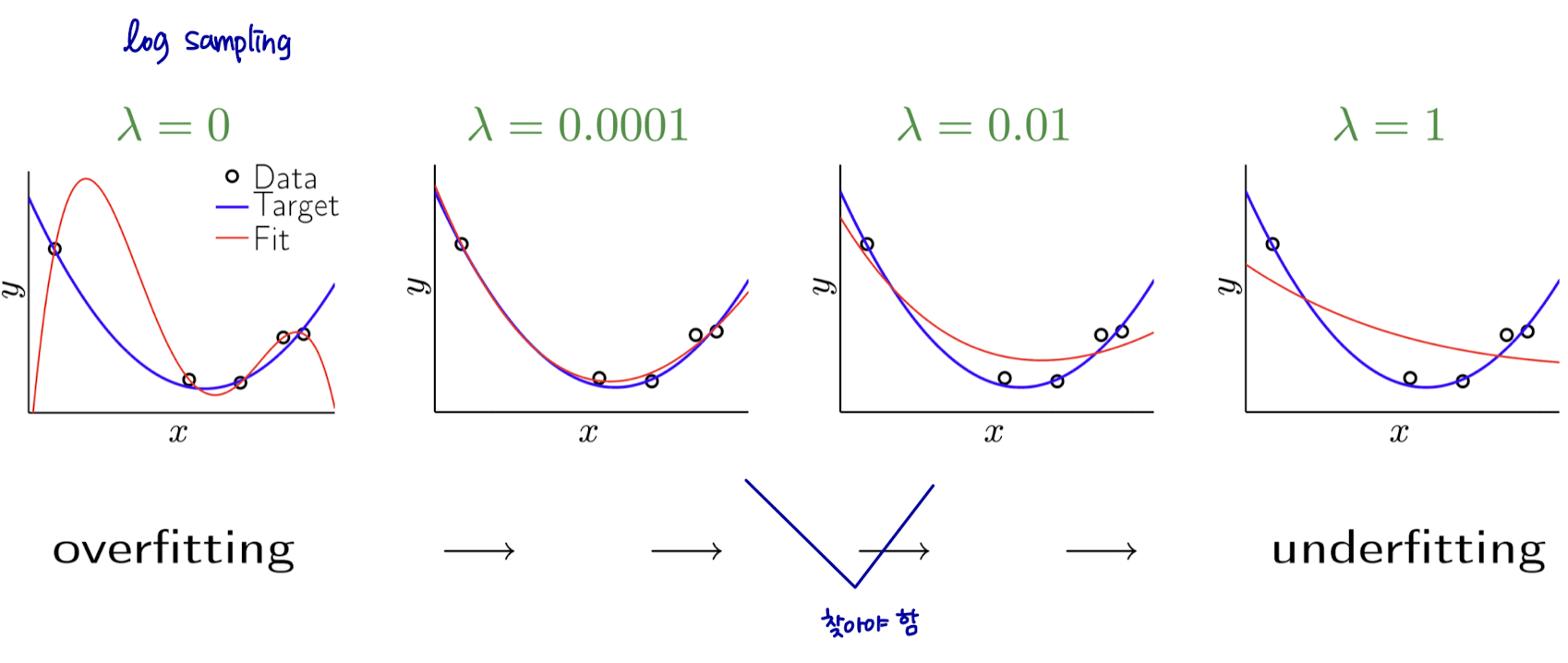
validation accuracy가 제일 좋은 것을 고르면 된다.
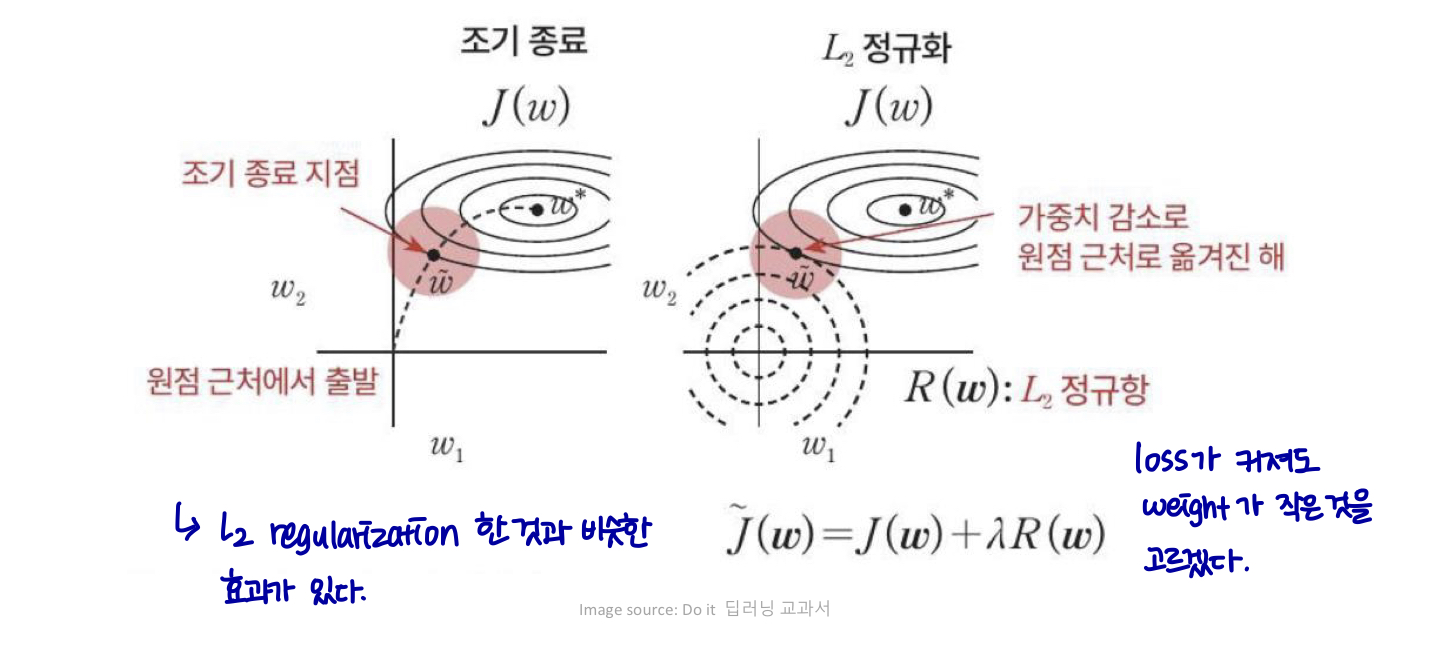
Early Stopping
-
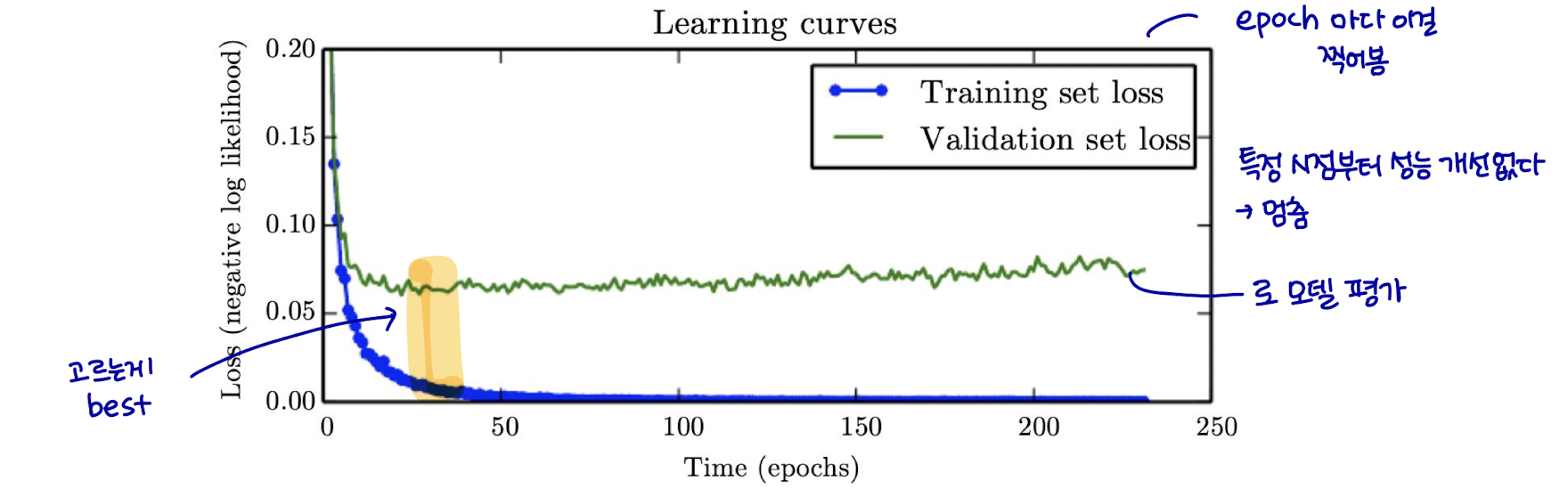
작업을 과적합하기에 충분한 표현 능력을 가진 대형 모델을 트레이닝할 때, training error는 시간이 지남에 따라 꾸준히 감소하지만 validation set 오류는 다시 증가하기 시작한다.
-
early stopping: 가장 낮은 validation set error에 트레이닝 중지 → hope better test set error
Early Stopping
-
validation set error가 개선될 때마다, 모델 파라미터의 복사본을 저장한다.
-
딥 러닝에서 가장 일반적으로 사용되는 정규화 형식이다.
-
효율적이고 간단하다.
-
단독으로 또는 다른 정규화 전략과 함께 사용 (섞어서 씀(e.g. norm penalty와 함께 사용, flexible)
-
훈련 절차의 계산 비용을 줄인다. (early stopping으로 인해 뒤의 쓸데없는 계산을 할 필요가 x)
-
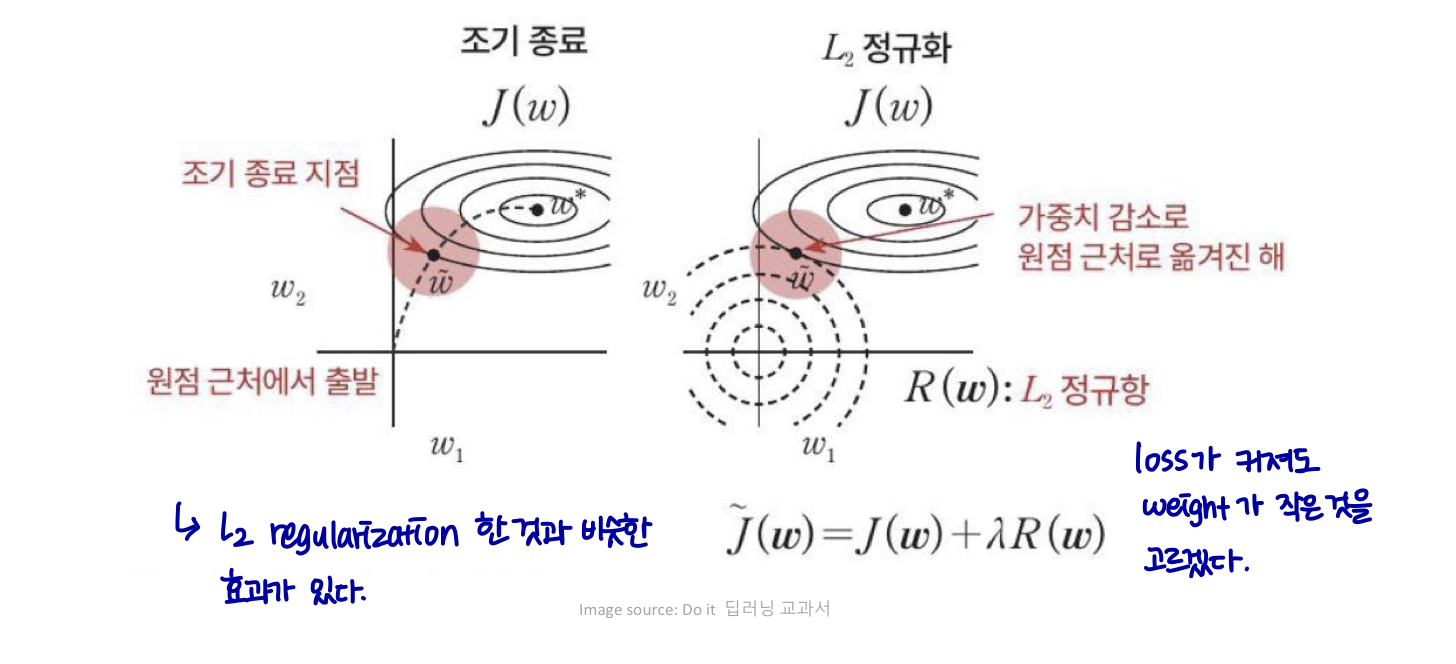
Early Stopping
Ensemble
-
구성(constitutent) 학습 알고리즘만으로 얻을 수 있는 것보다 더 나은 예측 성능을 얻기 위해 여러 학습 알고리즘을 사용한다.
- 약한 모델들을 결합하여 강한 모델(성능이 좋거나, 특정 데이터에 관해 bias가 적은..)을 만든다 → 모델 평균화
Ensemble
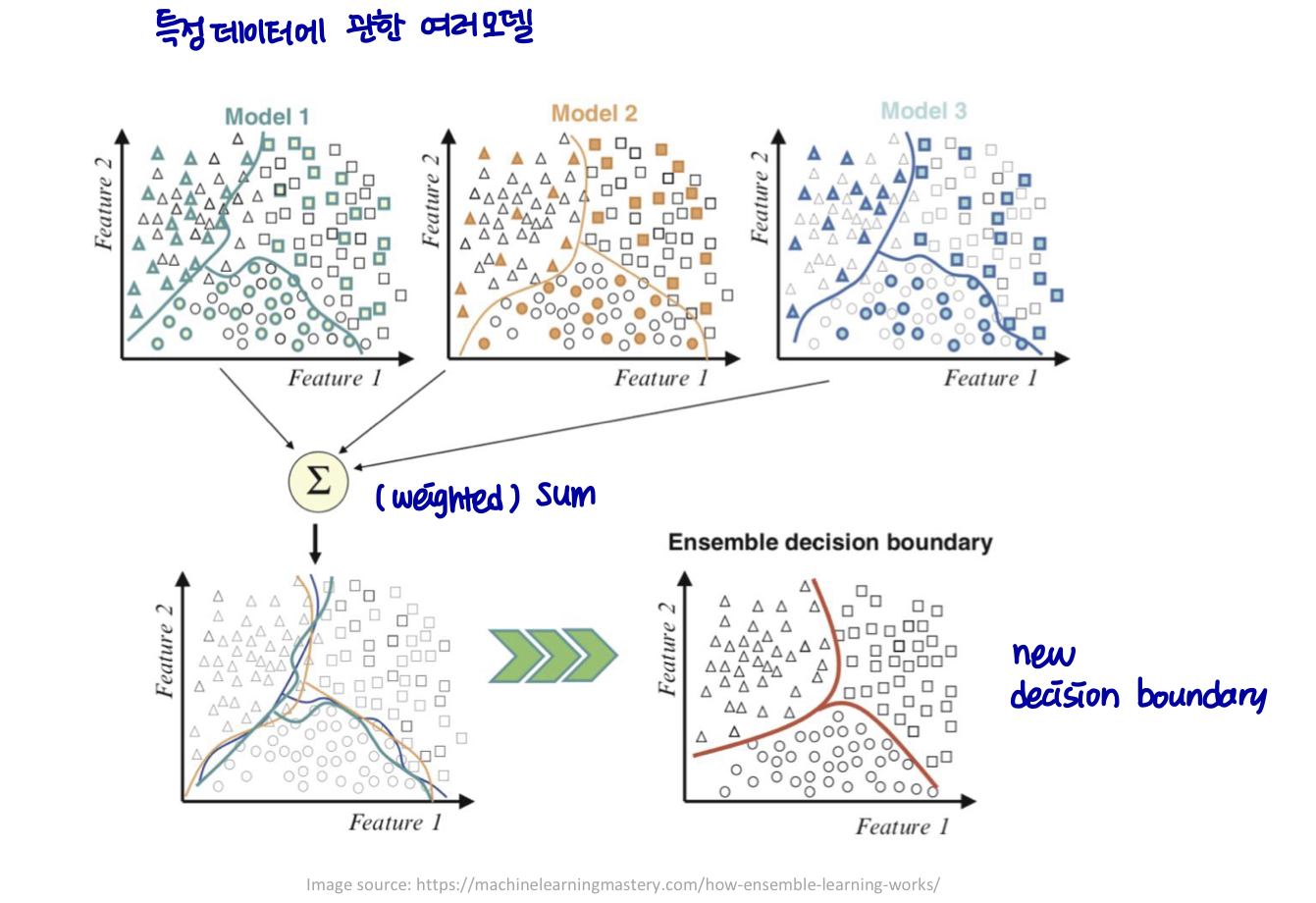
- 양상블 (배깅, 부스팅)
Bagging
-
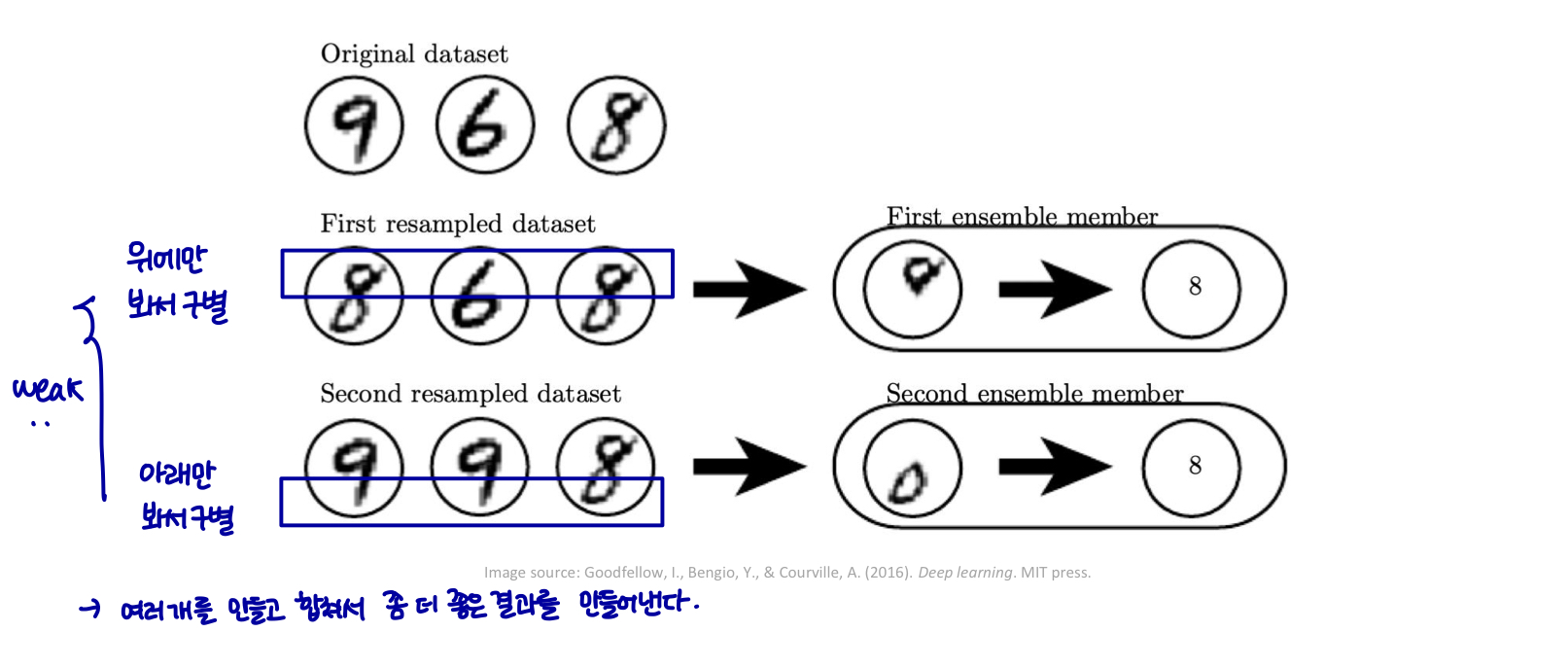
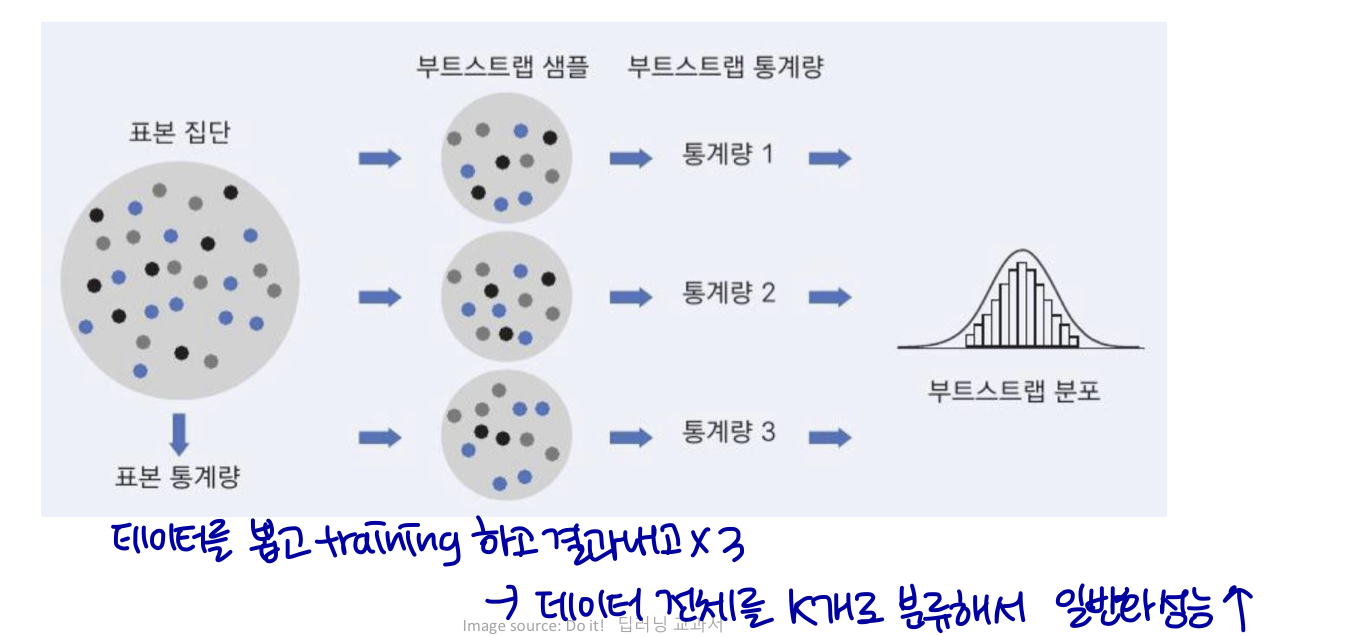
Bagging (boostrap aggregating의 약자)은 여러 모델을 결합하여 일반화 오류(generalization error)를 줄이는 기술이다.
-
아이디어는 여러 다른 모델을 개별적으로 train한 다음, 모든 모델이 테스트 예제의 output에 투표하도록 하는 것이다.
- 무작위 샘플링으로 k개의 서로 다른 데이터셋 구성
- 동일한 모델 / 훈련 알고리즘 / 객체 함수 재사용 (e.g. model: logistic regression, training algorithm: adam optimizer, objective function: cross entropy 쓸건데 L2로 penalty 주겠다..갖고 있는 데이터가 다르기 때문에 실제로 다른 모델이다.)
- voting (classification, 마지막 모델 예측) / weighted sum (regression, 값을 만듬)
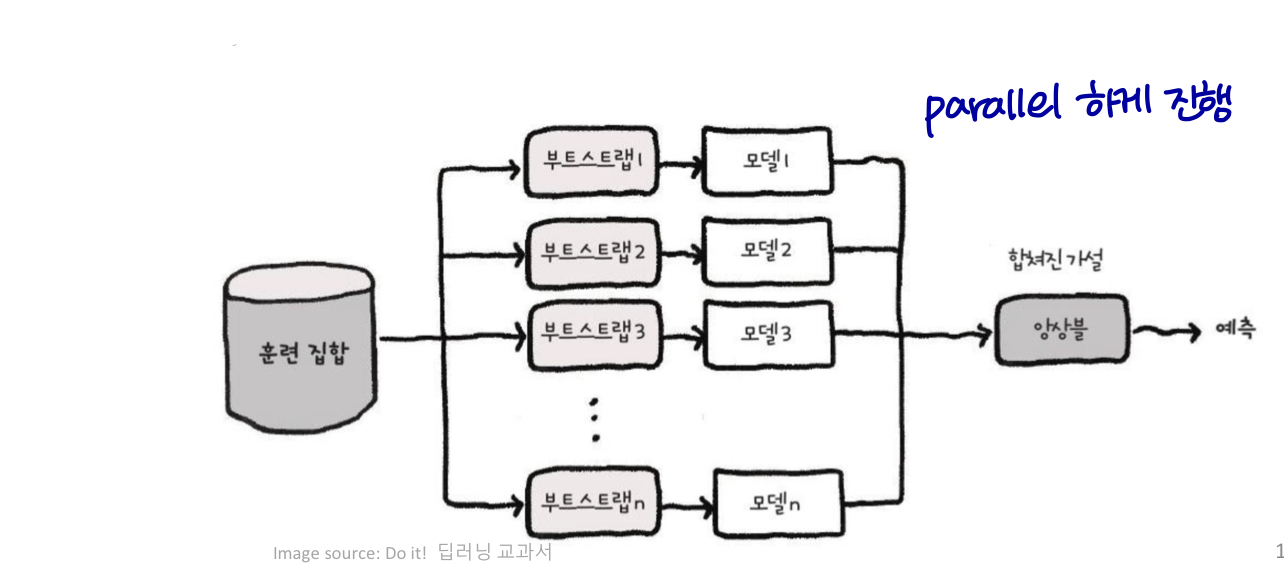
Bagging
Example: Decision Tree / Random forest
-
앙상블의 일종
-
통계 및 기계 학습에서 부트스트래핑은 종종 모집단 매개변수를 추정하기 위해 소스 데이터에서 복원 추출하는 리샘플링 기술이다.
Boosting
-
개별 모델보다 높은 용량으로 앙상블 구성
- AdaBoost
-
여러 week learner를 순차적으로(sequentially) 훈련하여 strong learner를 얻는다.
- 미래의 학습자는 이전 학습자가 잘못 분류한 예에 더 집중한다.
-
신경망의 부스팅 예제
-
앙상블에 신경망을 점진적으로 추가
-
앙상블에 hidden units을 점진적으로 추가
-
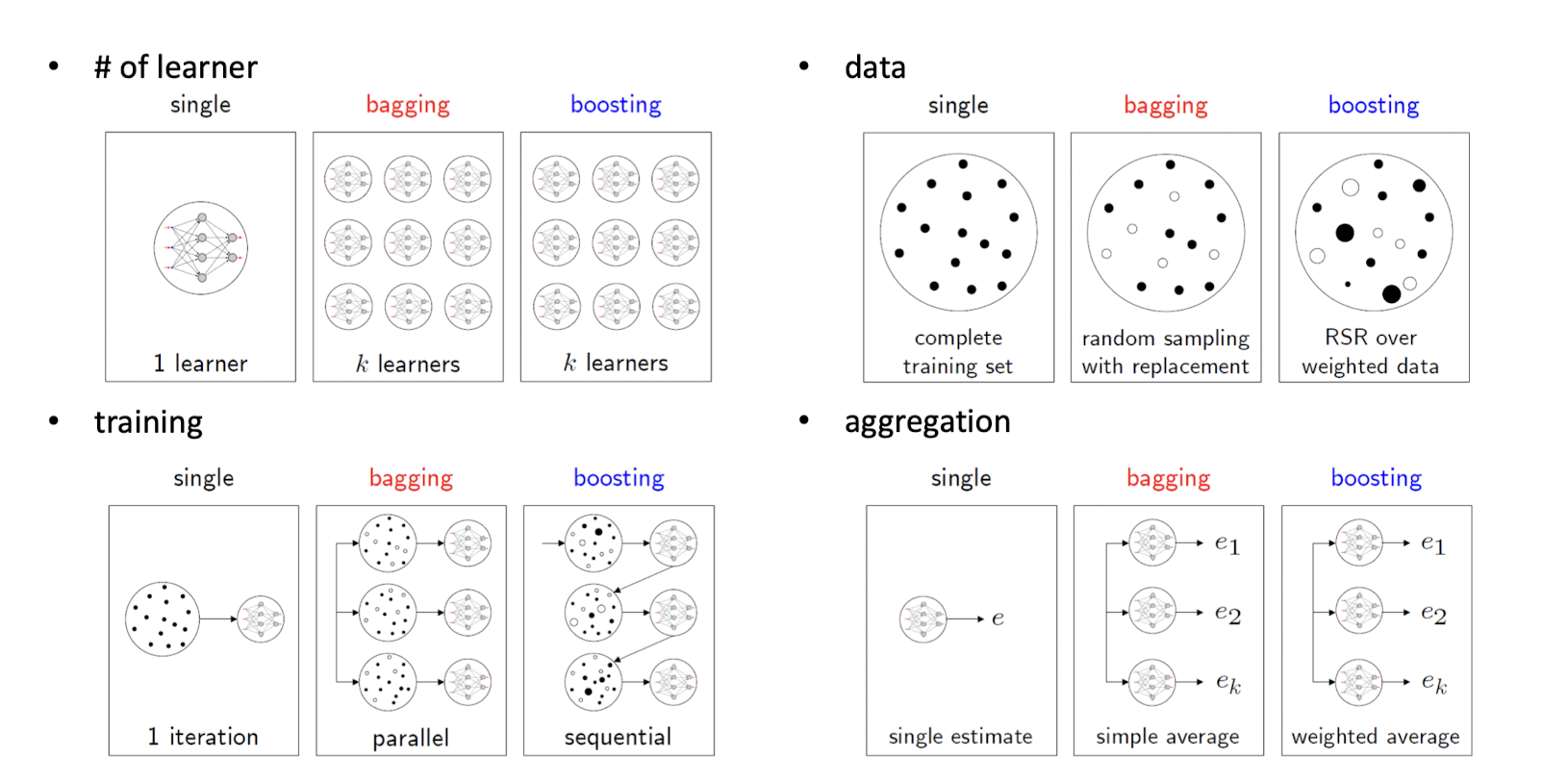
Bagging in Neural Network
-
신경망은 모든 모델이 동일한 데이터 셋에서 훈련된 경우에도 종종 모델 평균화의 이점을 얻을 수 있는 충분히 다양한 솔루션 포인트에 도달한다.
-
모델 차이점
-
random initialization
-
random selection of minibatches
-
differences in hyperparameter
-
-
모델 평균화는 일반화 오류를 줄이는 매우 강력하고 신뢰할 수 있는 방법이다.
Final remarks
-
모델 앙상블: 일반화 오류를 줄이기 위해 매우 강력하고 신뢰할 수 있음
-
여러 독립 모델 훈련
-
테스트 시간에: 결과의 평균을 낸다.
-
일반적으로 약 2%의 추가 성능을 제공한다.
-
-
ML contest:
-
수십 개의 모델에 대한 모델 평균을 사용하는 방법으로 승리했다.
- 넷플릭스 대상, 캐글.. 등
-
-
참조 과학 논문: 앙상블은 알고리즘을 벤치마킹할 때 권장되지 않는다.
- 벤치마크 비교: 일반적으로 단일 모델을 만든다.
Additional Topics
-
AdaBoost
-
Gradient Boosting
-
XGBoost
Dropout
-
드롭아웃은 계산 비용이 저렴하지만 광범위한 모델군을 정규화하는 강력한 방법을 제공한다.
-
Bagging에는 여러 모델을 트레이닝하고, 각 테스트 예제에서 여러 모델을 평가하는 작업을 포함된다.
- 각 모델이 대규모 신경망인 경우 비실용적이다.
-
드롭아웃은 기하급수적으로 많은 신경망의 배깅된 앙상블을 트레이닝하고 평가하는 저렴한 근사치를 제공한다.
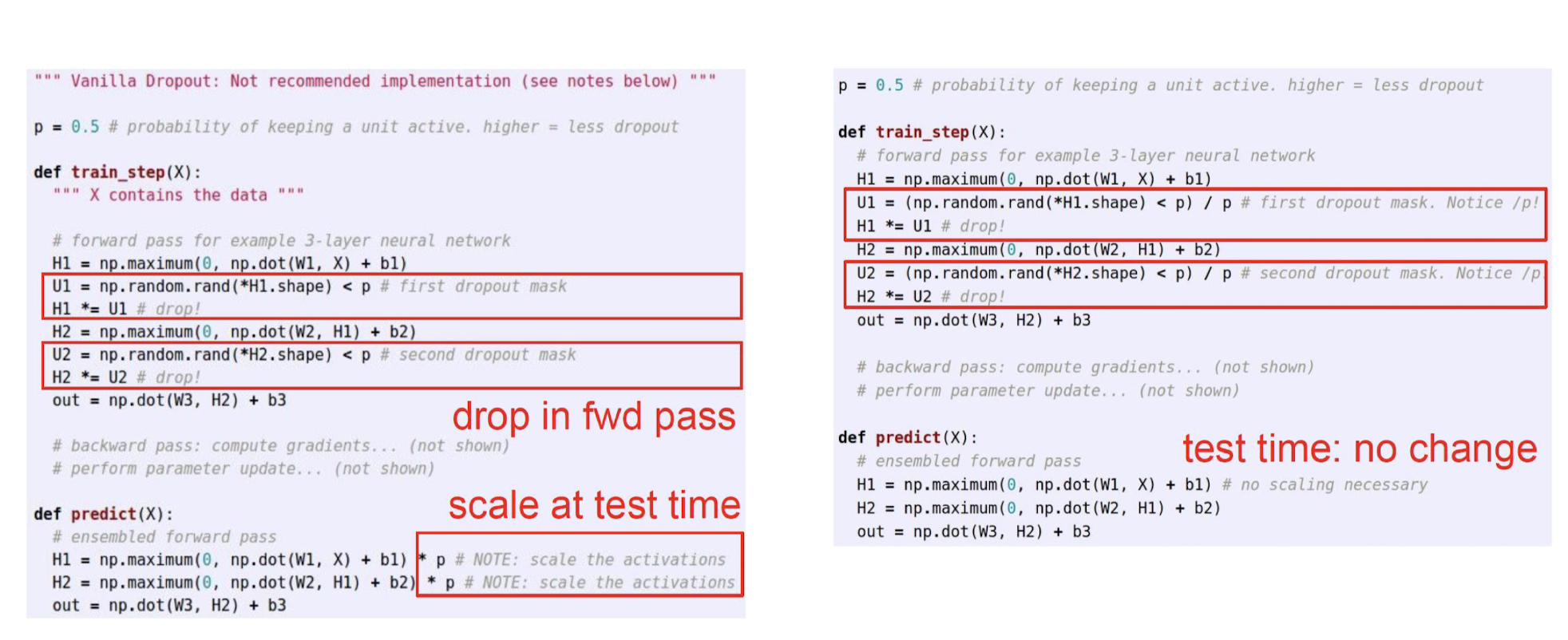
Dropout: Training
-
출력 값에 0을 곱해서 네트워크에서 unit을 제거한다.
-
하나의 마스크 값을 샘플링할 확률은 하이퍼파라미터이다.
- 일반적으로 hidden unit 에서 0.5 / input unit 에서 0.8을 사용한다.
-
-
드롭아웃은 모든 서브 네트워크의 앙상블을 훈련시킨다.
-
트레이닝
-
minibatch example 로드
-
input / hidden unit을 제거하기 위해 이진 마스크를 무작위로 샘플링
-
순전파 → 역전파 → 매개변수 업데이트
-
Dropout: Inference
-
Bagging 예측
-
Dropout 예측
-
기하급수적 항
-
다루기 힘든
-
10-20 마스크만 사용
-
근사치를 낸다.
-

Dropout: Weight scaling inference rule
-
가중치 대체: W → pW
- p는 포함될 확률이다. (탈락 확률 x)
-
테스트
-
모든 뉴런은 항상 활성 상태이다.
-
p를 곱하여 활성화 스케일링
-
테스트 시간의 출력 = 학습시간의 예상 출력
-
-
반전된 dropout
-
Training: 포함 확률이 p인 드롭아웃 및 활성화에 1/p 곱하기
-
Test: 변화 없음
-
Example
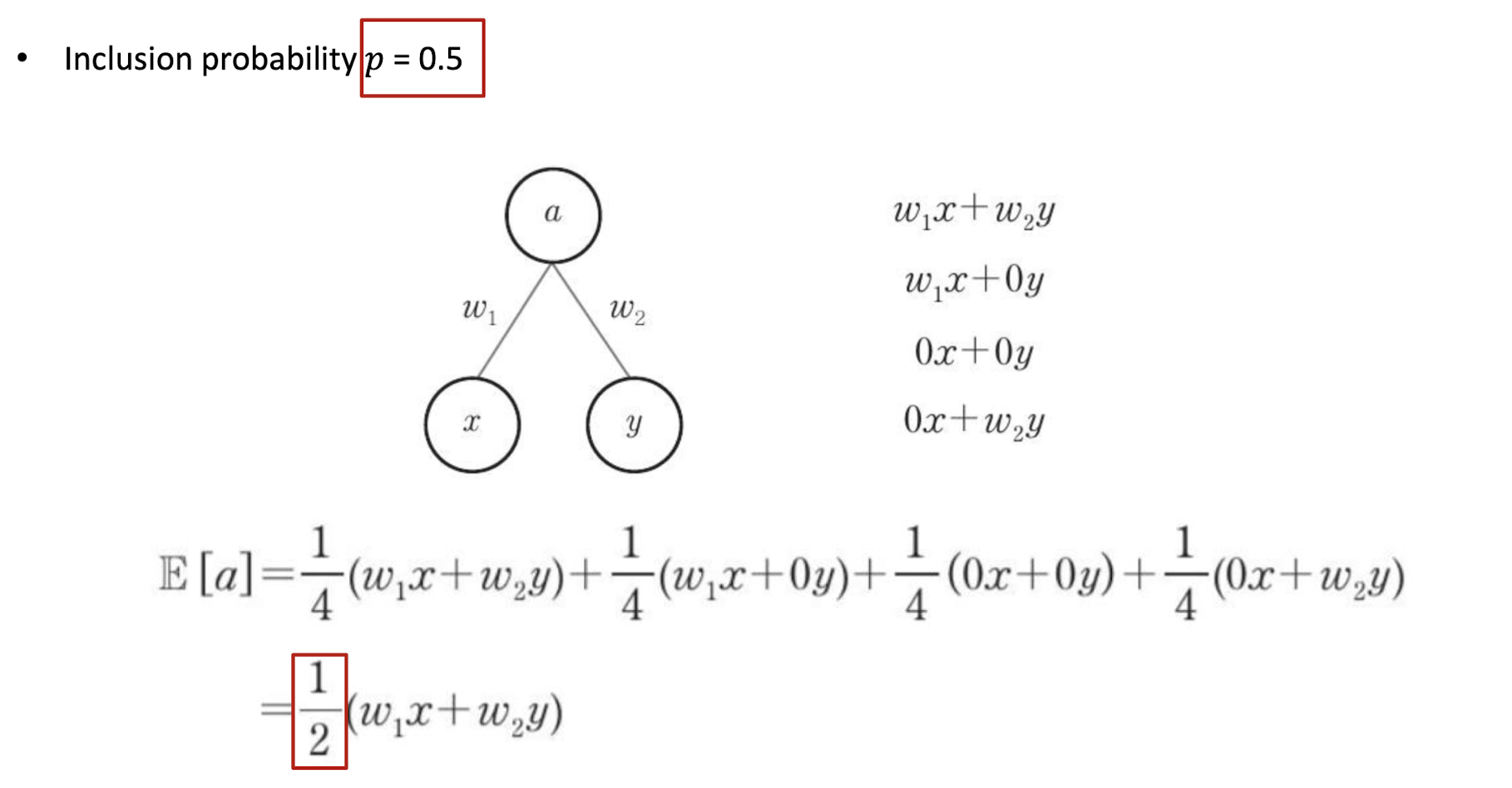
Example
- 포함 확률 p = 0.5
Dropout Advantages
-
dropout은 다른 표준 계산 비용이 저렴한 regularizer보다 더 효과적이다.
- 다른 형태의 정규화와 결합될 수도 있다.
-
계산적으로 매우 저렴하다.
-
업데이트 의 예제 당 O(n) 계산만 필요하다.
-
역전파 단계까지 이러한 이진 수를 저장하려면 O(n) 메모리가 필요하다.
-
-
모델 또는 훈련 절차의 유형을 크게 제한하지 않는다.
-
Feedforward
-
RNN
-
RBN
-
Data Augmentation
-
머신 러닝 모델을 더 잘 일반화 시키는 가장 좋은 방법은 더 많은 데이터로 모델을 훈련시키는 것이다.
- 실제로는, 우리가 가지고 있는 데이터의 양은 제한되어 있다.
-
이 문제를 해결하는 한 가지 방법은 가짜 데이터를 만들어 훈련 세트에 추가하는 것이다.
-
transformation (변환)
-
generative model
-

Data Augmentation
- Generative model example

Data Augmentation
-
올바른 클래스를 변경하는 변환을 적용하지 않도록 주의해야 한다.
-
클래스 불변 가정
-
‘b’ and ‘d’ / 6 and 8
-
-
가짜 데이터를 생성하는 것은 어렵다.
-
특정 ML 작업에 따라 다름
-
사물 인식, 음성 인식 성공
-
Data Augmentation
-
ResNet 예시
-
Training: sample random crops / scales
-
[256, 480] 범위 내의 무작위 L 선택
-
훈련 이미지 크기 조정, short side = L
-
무작위 224 x 224 패치 샘플
-
-
Test: average a fix set of crops
-
5 가지 크기로 이미지 크기 조정: {224, 256, 384, 480, 640}
-
각 크기에 대해 10개의 224x224 크롭 사용: 4개의 모서리 + 중앙, + 뒤집기
-

Batch normalization
-
Covariate (공변량)
- input variable, independent variable, predictor variable, regressor, covariate, manipulated varable, explanatory variable, exposure variable(reliability theory), risk factor(medical statistics), feature(machine learning), control variable(econometrics)
-
Covariate shift
-
입력 분포를 학습 시스템으로 변경한다.
-
e.g., training: web image → test: mobile phone images
-

Batch normalization
-
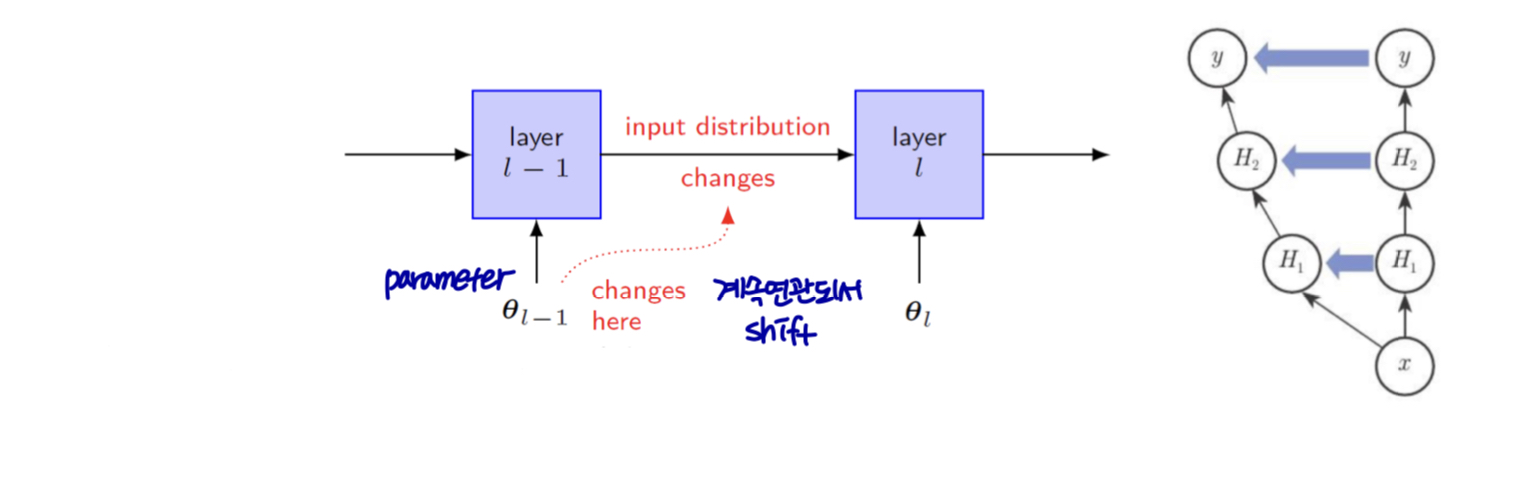
internal covariate shift (내부 공변량 이동)
- training 중의 각 계층의 입력 변경 분포
-
내부 공변량 이동으로 NN training이 복잡해진다.
-
낮은 학습률
-
신중한 매개변수 초기화
-
-
포화 비선형으로 모델을 훈련하기 어렵게 만든다.
Batch normalization
-
해결책? → 상호작용 제거
-
How?
-
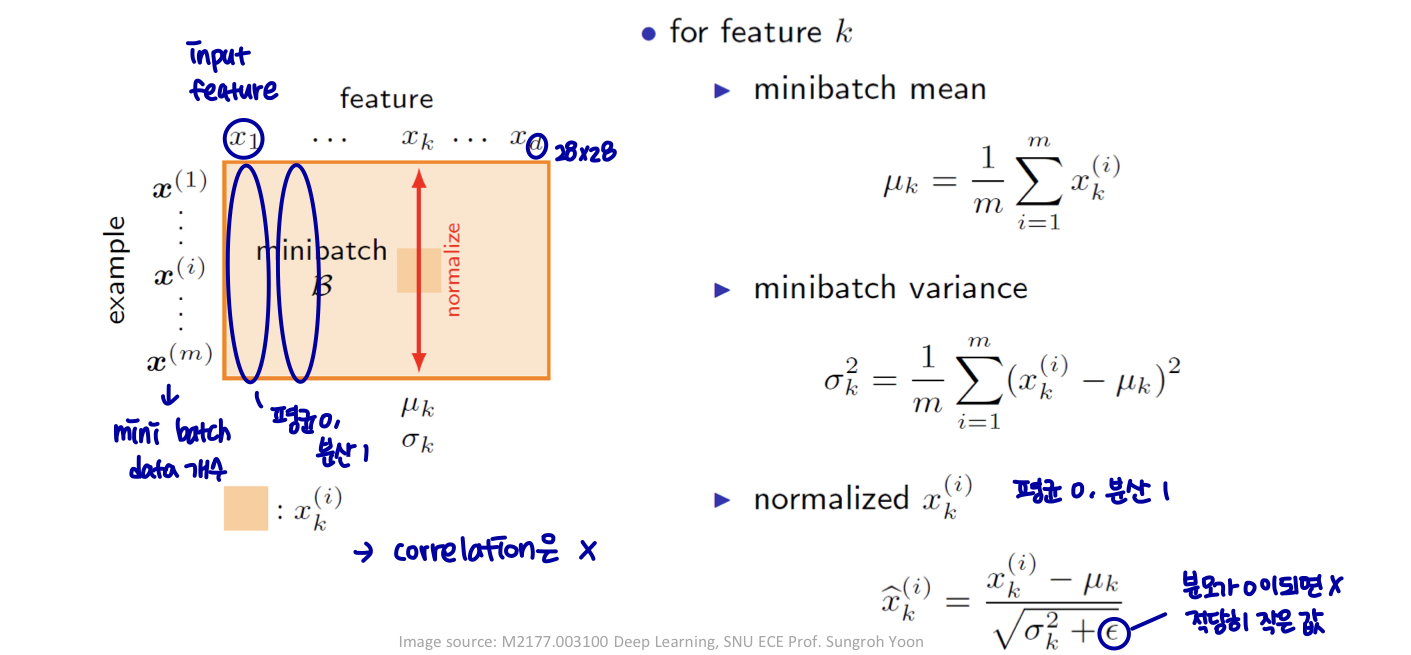
whitening(백색화): 정규화 (zero mean, unit variance(단위 분산)) + 상관 관계
-
입력이 백색화된 경우 네트워크 트레이닝이 더 빠르게 수렴한다. (Lecun et al., 1998)
-
각 층의 입력을 화이트닝하는 것은 어떨까?
-
분포: 항상 고정됨 (평균 0, 단위 분산 가우시안)
- 내부 공변량 이동 감소 → 더 빠른 훈련
-
계산 비용이 많이 들고 (covariance matrix / inverse) 미분할 수 없다.
-
간소화된 대안 → 배치 정규화: 계층 입력의 미니배치 방식 정규화.
- 상관 관계 없음
-
-
Batch normalization
-
Idea: 네트워크 전체에서 활성화를 명시적으로 강제한다.
-
트레이닝 시작 시 단위 가우시안 분포
-
정규화는 단순 미분 연산이다.
-
-
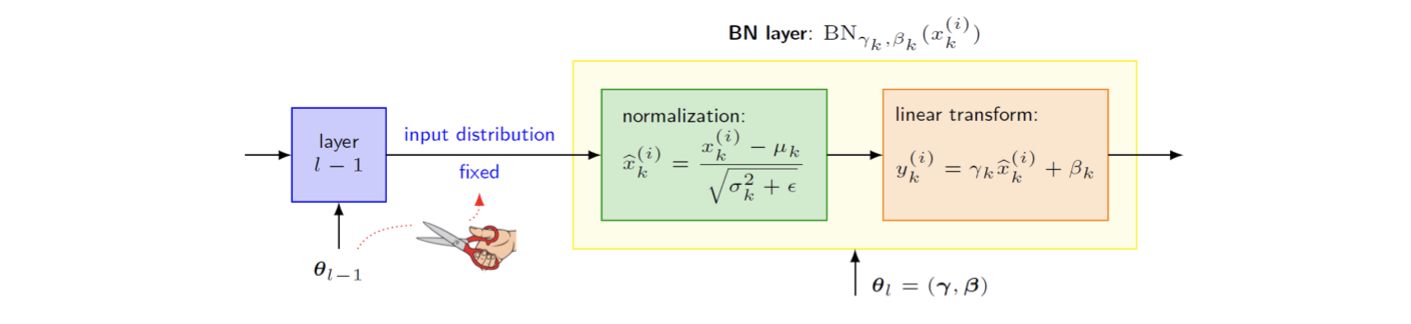
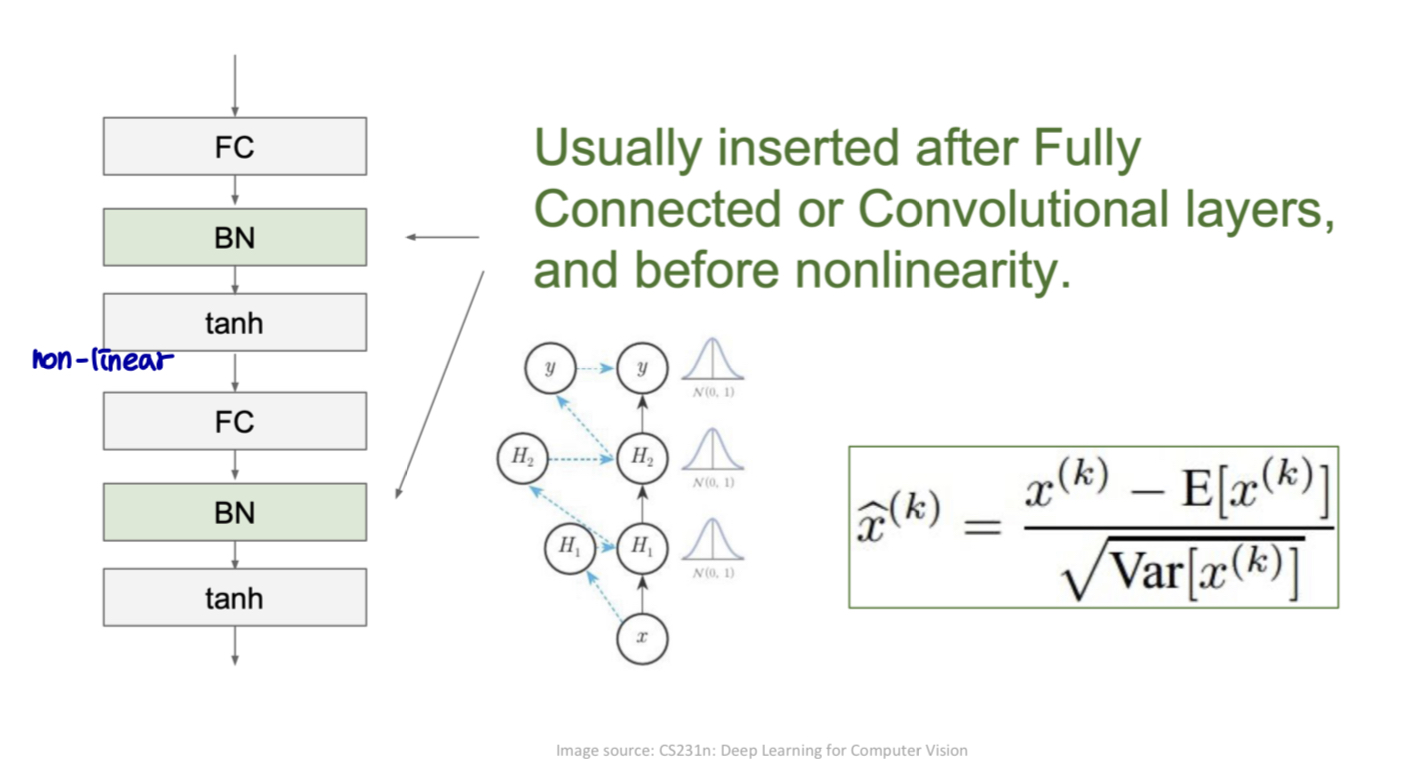
Implementation: BN layer 생성 및 삽입
-
FC layer → BN layer → 비선형 layer
-
BN layer → 네트워크의 모든 레이어에서 전처리
- 미분 가능한 방식으로 신경망 자체에 통합된다.
-
Batch normalization
-
각 기능을 독립적으로 정규화 (공동으로 기능을 백색화 하지 않음)
- 학습 속도 향상 (융합)
Batch normalization
-
레이어의 각 입력에 대한 간단한 정규화: 문제가 있음
-
레이어가 표현할 수 있는 것이 변경될 수 있다.
- 레이어의 표현력이 감소한다.
-
hidden unit은 항상 평균과 단위 분산이 0이다.
→ layer의 각 뉴런의 범위가 (평균 0, 분산 1)로 다 똑같아져서
representation power가 감소한다.
-
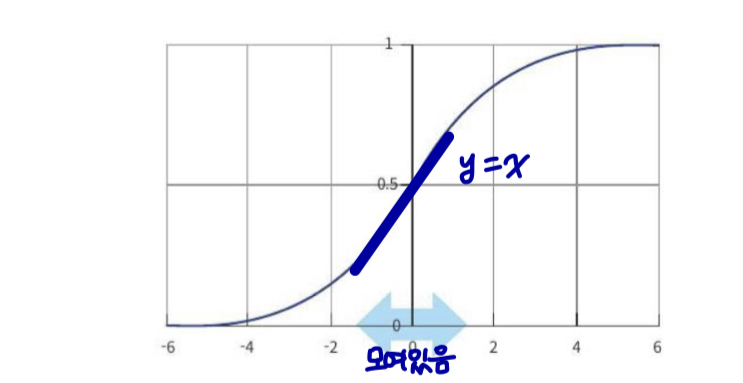
⇒ nonlinearity를 주려고 한건데 normalization 때문에 ↔ 에서 y=x 가 되어 nonlinearity가 의미 없어진다.
- 해결책? 선형 변환 (Linear transformation)
-
각 활성화 에 대해 두 개의 매개변수 를 도입한다.
-
는 hyper parameter가 아니고 model parameter 이므로 gradient descent로 찾을 수 있다.
-
sgd에 의해 원래의 모델 파라미터와 함께 학습한다.
-
신경망의 표현력을 복원한다.
-
-

Batch normalization
-
요약
-
정규화: 각 레이어에 대한 입력 분포를 수정한다.
-
서로 다른 레이어 간의 고차 상호작용(high-order interactions)을 제거한다.
-
학습 역학을 단순화한다. → 교육속도를 높인다.
-
-
선형 변환
- 네트워크의 표현력을 복원한다.
-
⇒ layer 간 영향 최소화. interaction을 끊음
→ training이 빨라짐, 하지만 표현력 감소 → scaling (minibatch + linear transform)
Batch normalization

Batch normalization
Batch normalization
-
테스팅 시간
-
평균 / 표준편차 값은 배치를 기반으로 계산되지 않는다.
-
단일 고정 경험적 평균 (a single fixed empircal mean) / 훈련 시간동안 활성화의 표준편차
-
각 테스트 예제에 대한 결정적 결과를 얻는다.
-
-
평균 / 표준편차는 이동 평균으로 훈련 중에 추정할 수 있다.
Batch normalization
-
장점
-
더 높은 학습률 허용 → 가속화된 training
-
정규화 효과
- Dropout + BN, L2 정규화가 필요하지 않을 수 있음 (이만큼 좋더라~.. 절대적인 건 아니고 data, parameter에 따라 다를 수 있음)
- Dropout + BN, L2 정규화가 필요하지 않을 수 있음 (이만큼 좋더라~.. 절대적인 건 아니고 data, parameter에 따라 다를 수 있음)
-
포화 비선형성 (sigmoid, tanh) 으로 훈련 가능
- BN은 포화범위에 갇히는 것을 방지한다.
-
초기화에 대한 종속성을 줄인다.
-

정리가 잘 되어 있네요! 잘 보고 갑니다.