딥러닝
1.퍼셉트론
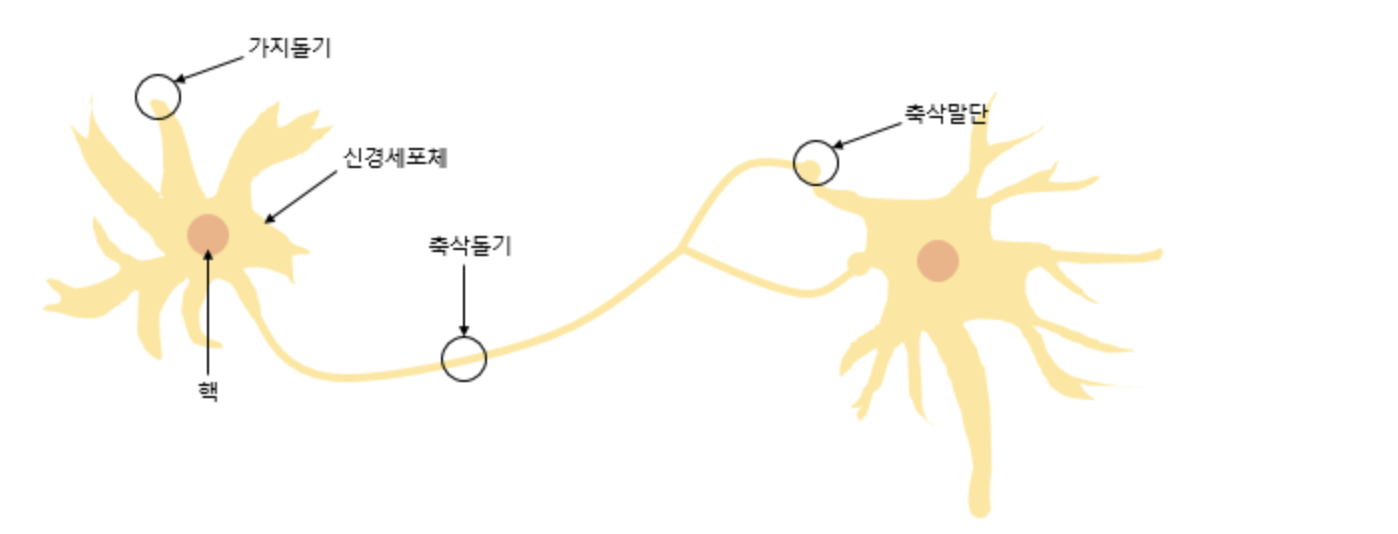
본 내용은 밑바닥부터 시작하는 딥러닝. 사이토 고키 저.를 참고하여 작성되었습니다.퍼셉트론(Perceptron)은 프랑크 로젠블라트(Frank Rosenblatt)가 1957년에 제안한 초기 형태의 인공 신경망으로 다수의 입력으로부터 하나의 결과를 내보내는 알고리즘이다
2.Gradient Descent

본 내용은 공돌이의 수학정리 노트(https://angeloyeo.github.io/2020/08/16/gradient_descent.html) 님의 블로그 정리에 기초합니다. gradient?점 p에서 f의 편미분을 구성 요소로 하는 벡터gradient 벡터
3.순전파, 역전파란

전형적인 딥러닝 모델심층 feedforward network, MLP머신러닝 실무자에게 매우 중요많은 중요한 상용 응용 프로그램의 기초e.g.) convolutional networks, recurrent networks목표: approximating some func
4.Data representation
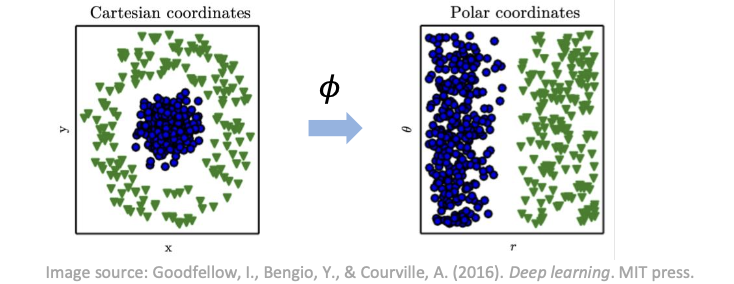
Linear models (선형 모델)e.g.) logistic regression, linear regression장점: efficient, reliable, closed form or convex optimization단점: 모델 복잡도, 두 입력 변수간의 상호작용
5.Output units
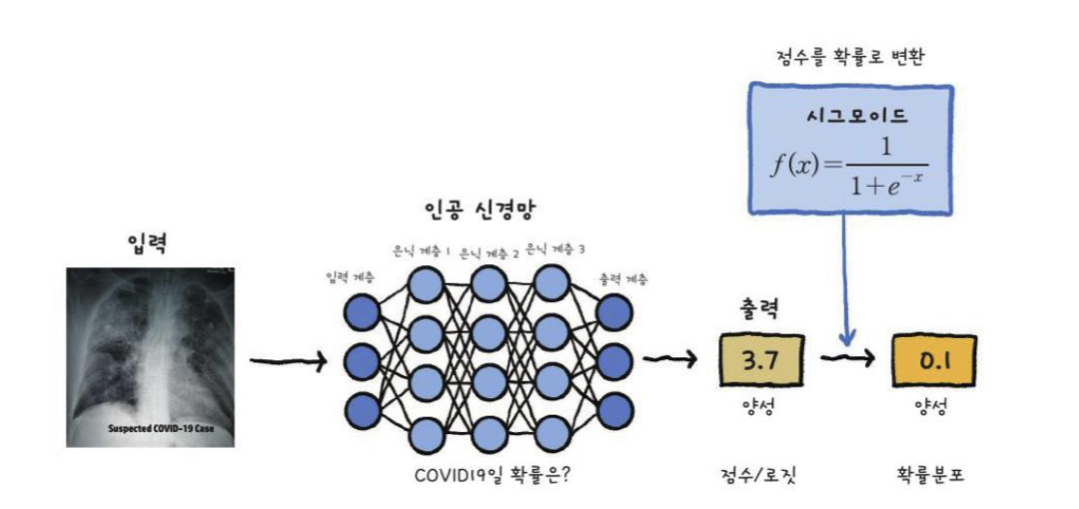
출력 계층의 역할은 네트워크가 수행해야 하는 작업을 완료하기 위해 기능에서 일부 추가 변환을 제공하는 것이다.feedforward network가 hidden features h = f(x; Θ) 를 제공한다고 가정하자.h → output units → y^linear
6.Likelihood
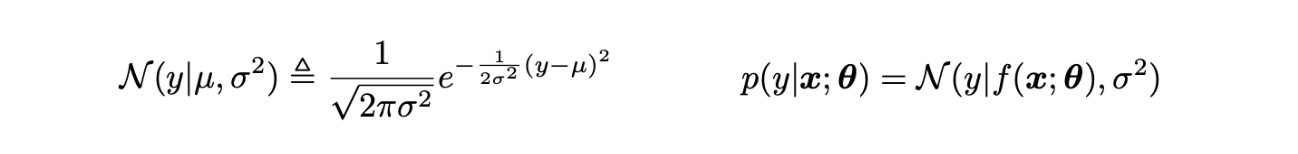
TaskClassification(분류): binary / multiclass / multilabelRegression(회기): scalar / vectorDataN-point data set D = {(x1, y1), (x2,y2), … , (xn, yn)}unkno
7.Data preprocessing
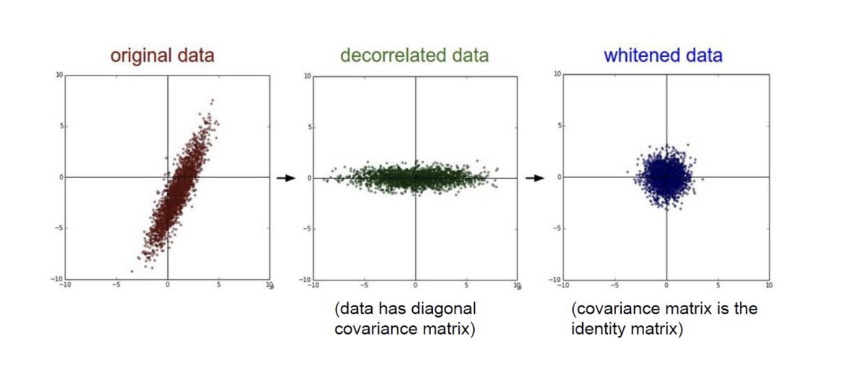
딥러닝을 성공적으로 적용하는 것알고리즘을 아는 것 이상이 필요하다.또한 알아야 한다.특정 응용 프로그램에서 골라야 할 알고리즘실험으로 부터 얻은 피드백을 모니터하고 응답하는 것신경망 훈련: 매우 중요 / 높은 비용 ⇒ 신중한 전술 필요데이터를 더 모을 것인지 아닌지모델
8.최적화
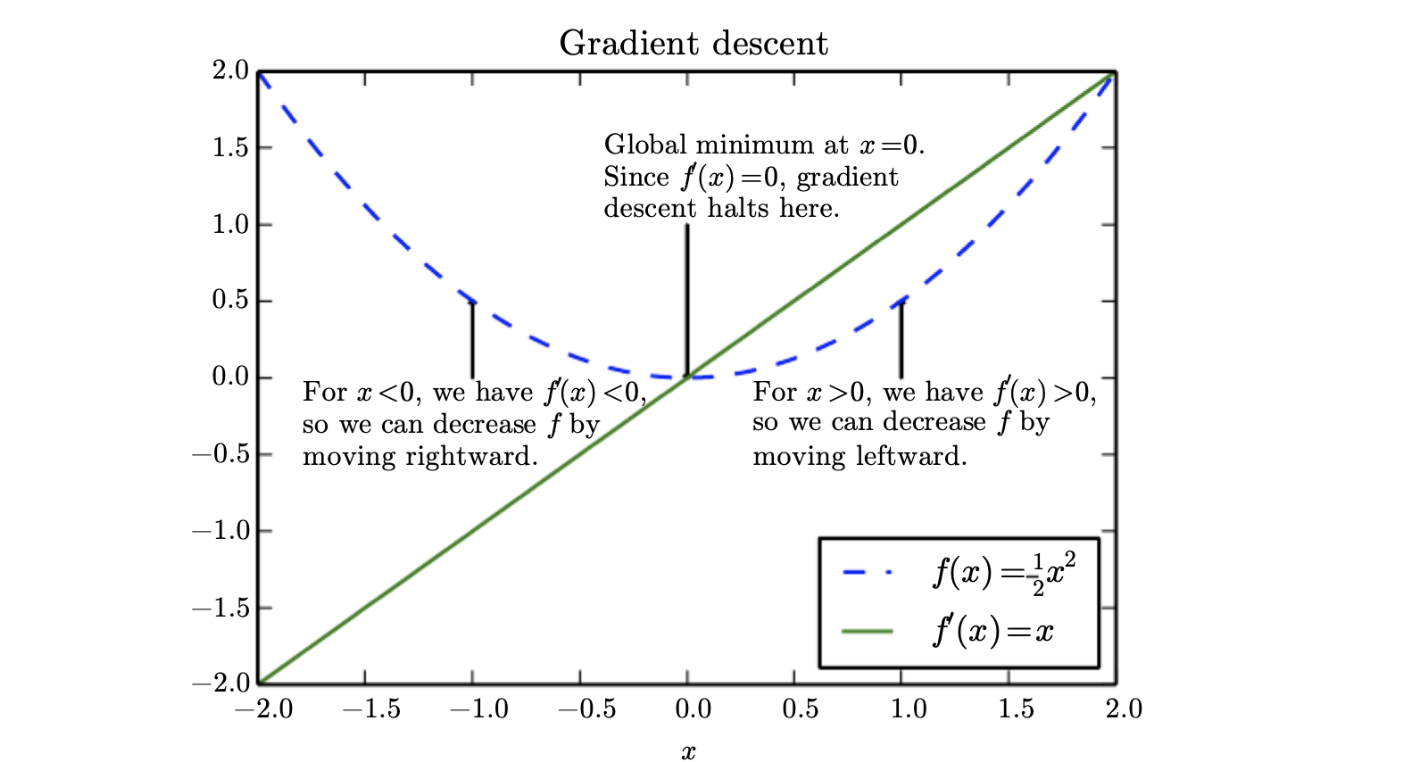
가장 간단한 경우, 최적화 문제는 허용된 집합 내에서 입력 값을 체계적으로 선택하고 함수의 값을 계산하여 실제 함수를 최대화하거나 최소화하는 것으로 구성된다.최적화는 심층 신경망에서 중요하고 어렵고 비용이 많이 드는 부분이다.비용 함수를 대폭 감소시키는 신경망의 파라미
9.정규화

목표: Regularization의 의미와 기법들에 대한 이해테스트 에러를 줄이는 전략 (= 일반화 오류)train error가 증가할 수 있다.왜? → 머신러닝의 목적은 트레이닝 데이터 뿐만 아니라 새로운 입력에서도 성능을 향상시키는 것이기 때문이다.머신 러닝 모델에
10.CNN (1)
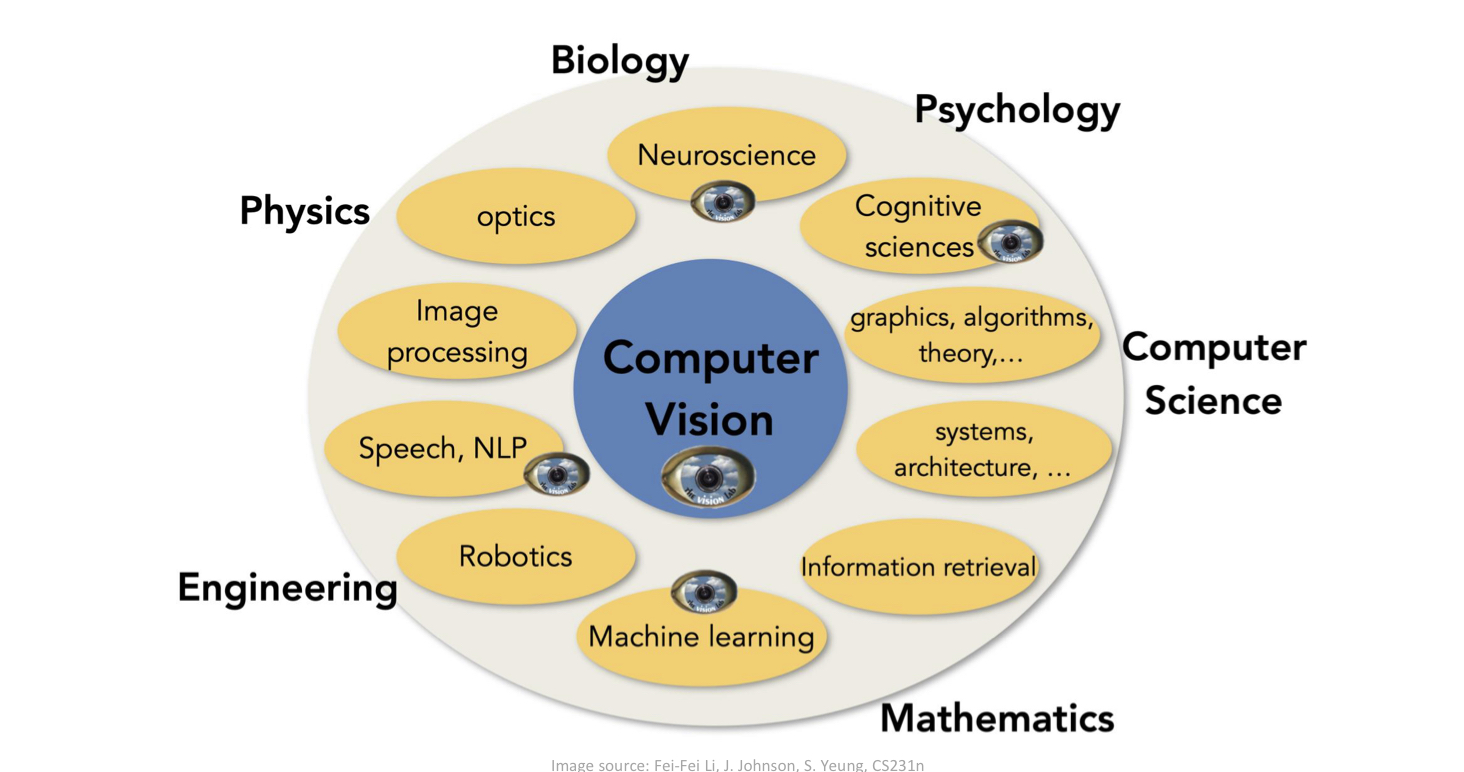
컴퓨터 비전을 위한 신경망매우 높은 차원의 입력 (4k)픽셀의 2d / 3d topology변동에 대한 불변성합성곱 신경망 (Convolutional Neural Network, CNN)Local connectivityParameter sharingPooling / s