
📝 이 포스트는 1998년에 발표된 CNN의 초창기 모델인 "Gradient-Based Learning Applied to Documnet Recognition" 에 대해 알아보겠습니다.
배경
이 논문은 'Yann LeCun'저자의 Convolutional Neural Network의 시초인 LeNet을 개발한 1998년 게재된 논문입니다.
이 논문은 나온 합성곱 신경망 모델은 손글씨 숫자와 문자로 이루어진 대규모 데이터셋을 학습시키는데 성공적인 결과를 이끌었는데 그 이유와 비교를 설명해줍니다.
LeNet-5의 등장배경
- Hand-disigned feature extractor는 제한된 특징만 추출한다.
이는 사람이 손수 직접 feature extractor(Filter)를 설계하기 때문에 주관이 개입된다.
떠러소 인간의 실수가 허용되어 몇몇 중요한 feature를 누락하고 feature extractor를 설계할 수 있다. - 과도한 파라미터를 수용한다.
전 층이 Fully-connect Layer로 수많은 연산을 겪어 많은 양의 파라미터를 갖게 된다.
이 많은 파라미터를 저장해야 하므로 많은 양의 저장공간을 차지하게 된다.
이와 같은 전통적인 손글씨인식 방식을 보완하기 위해 CNN(Convolutional Neural Network)을 도입하게 됩니다.
CNN은 shift, scale distortion 불변성을 갖기 위해 'Local receptive field' 와 'shared wieght', 'sub-sampling'의 개념을 도입했습니다.
간단한 📚용어정리 차원에서 설명이 필요할 것 같습니다.
- Local receptive field
receptive field는 연산이 적용되는 영역을 뜻합니다. receptive field를 local로 국한시켜 local feature를 추출하는 방법입니다.
✅즉, 필터를 적용하여 3X3, 5X5 local receptive field에서 feature를 추출하는 방식을 말합니다. - sub-sampling
입력 데이터의 공간적 크기를 줄이고, 계산량을 줄이면서 중요한 특징을 보존하는 역할을 수행하는 층을 말합니다.
✅즉, 현대 용어로 'Pooling Layer'를 말합니다. Pooling 방식에는 Max Pooling / Average Pooling이 있습니다. - shared weight
전통적인 방식은 각 입력 채널마다 필터가 별도로 학습되고, 결과적으로 필터의 수는 입력 채널의 수와 동일합니다. 하지만 LeNet-5에서는 입력 채널들이 같은 필터를 공유함으로써 학습 파라미터를 크게 줄이고 모델의 크기를 줄이는 장점을 가집니다.
📎 ) RGB 3개의 채널이 각각 3개씩 필터를 사용하여 총 9개의 필터를 사용하던 전통적인 방식에서 LeNet-5는 3개의 채널들이 필터를 공유하여 총 3개의 필터만 사용한다.
논문의 Introduction 내 2번째 문단에
"The main message of this paper is that better pattern recognition systems can be built by relying more on automatic learning, and less on hand-designed heuristics."
을 읽어보면 패턴인식시스템은 automatic learning에 더 의존하고 스스로 직접 손수 만드는 방식을 덜 의존 한다고 합니다.
머신러닝의 발전에 이바지한 논문임을 알 수 있는 문장이죠.
따라서 우리는 이 논문을 통해 전반적으로 CNN architecture를 이해할 수 있습니다.
알고리즘
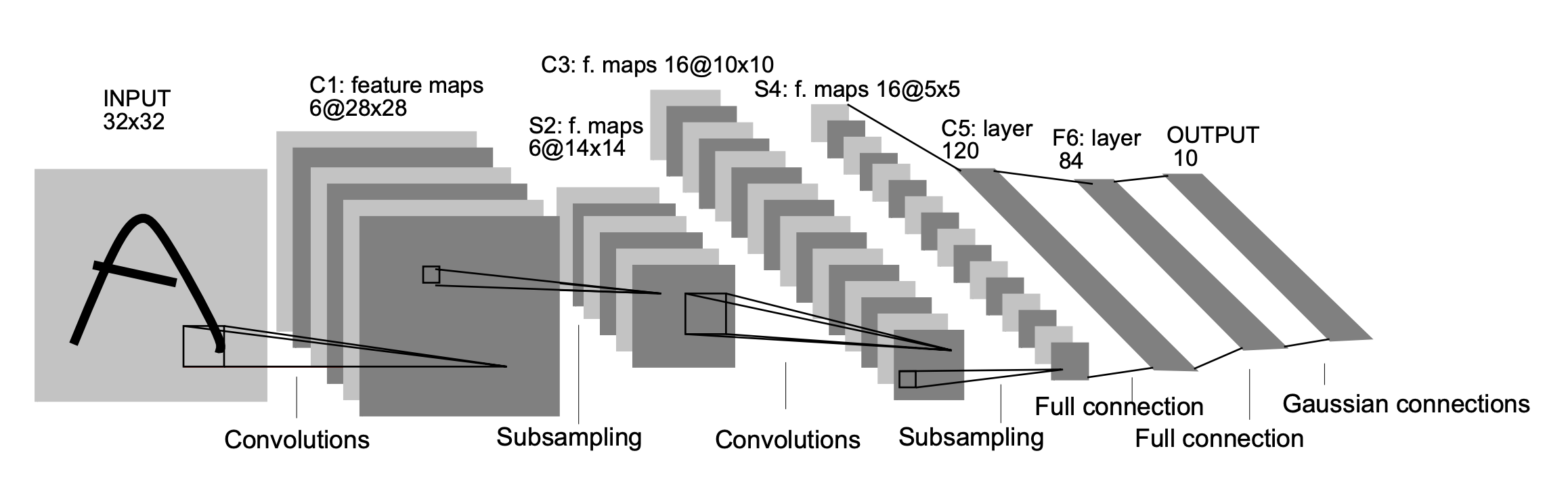
LeNet-5 는 입력층을 제외한 학습가능한 파리미터인 weight를 포함한 7개의 Layer로 구성되었습니다.
Convolutional layer는 라 하고, Sub-sampling layer는 , Fully-connected layer는 라고 명칭을 정의했습니다.
는 Layer의 인덱스입니다.
논문에서 각 층별로 파라미터의 개수가 몇개인지 정의했습니다.
파라미터의 개수를 어떻게 구하였는지는 나와있지 않아서 저는 어떻게 하여 파라미터 개수가 도출되었는지 설명도 할 겁니다.
따라서 파라미터의 개수를 구하는 공식을 아래에 적어놓을 것이니 파라미터 개수 구하는 법을 모르시는 분들은 아래의 공식을 이용하여 한 번 씩 계산해보시는 것을 추천드리겠습니다✅.
Convolutional Layer 파라미터 개수 구하기
convolution 적용할 필터의 한 변의 크기 :
convolution 적용할 필터의 채널 수 :
적용할 필터의 개수(=다음 층의 채널 수) :
:
-
Fully-conneted Layer 파라미터 개수 구하기
직전 층이 Convolutional Layer일 경우
: 입력 이미지의 한 변의 크기
: 입력 이미지의 수
: 입력 이미지의 채널 수
: 현재 층의 노드(뉴런) 수
: 1직전 층이 Fully-connected Layer일 경우
현재 층의 노드(뉴런) 수 :
직전 층의 노드(뉴런) 수 :
:
Input Layer
크기의 이미지를 입력합니다.
C1 Layer
크기의 데이터를 입력받아 크기의 필터를 6개로 , 을 적용하여 합성곱을 수행하여 크기의 Feature map을 출력하는 층을 의미합니다.
-
파라미터 개수
여기서 는 적용한 필터의 크기를 뜻하고, 은 필터의 개수를 뜻합니다.
. 여기서 잠깐! 위의 공식에는 채널 수를 곱하여줬는데 왜 채널 수는 계산에 누락된 것일까요?
. 이 모델의 학습에 쓰인 데이터셋은 gray scale이라 RGB 3채널이 아닌 단일 채널이므로 이 누락된 것입니다.
그리고 뒤의 를 더해준 것은 를 필터의 개수에 맞게 더해준 연산입니다.
-
뉴런의 연결 개수
connection의 수를 도출한 방법은
로 뉴런과 뉴런 사이의 가능한 모든 연결 개수를 뜻합니다.
-
출력 데이터 크기
입력 데이터의 크기는 () 이고, () 의 Convolution 필터를 적용하면
로 크기의 Feature map을 6개를 생성합니다.
Feature map을 6개 생성한 이유는 Convolutional Layer에 적용된 필터의 개수에 맞게 output으로 Featue map을 생성하기 때문입니다.
이렇게 합성곱을 수행한 는 이미지의 Low-Level Feature(특성)를 추출하는 역할을 합니다.
S_2 Layer
크기의 데이터를 입력받아 크기의 receptive field 즉, 2X2 filter를 overlapping되지 않도록 , 을 적용하여 Average Pooling을 수행하여 크기의 Feature map을 출력하고 활성화 함수로 시그모이드 함수를 적용한 층을 의미합니다.
-
파라미터 개수
여기서 앞의 괄호에 은 Average Pooling의 수행 결과 반환한 값 1개를 뜻하고, 뒤의 괄호에 은 를 뜻합니다.
을 곱한 이유는 적용한 필터의 개수가 6개이기 때문입니다.
Pooling Layer의 결과로 직전 Layer의 Feature map의 개수와 동일한 개수의 Feature map을 갖습니다.
따라서 파라미터의 개수는 개가 됩니다. -
뉴런의 연결 개수
-
출력 데이터 크기
입력 데이터의 크기는 이고, 의 Avrage Pooling 필터를 적용하면
로 크기의 Feature map을 6개를 생성합니다.
Feature map을 6개 생성한 이유는 Average Pooing Layer에 적용된 필터의 개수와 맞게 ouput으로 Feature map을 생성하기 때문입니다.
이렇게 Pooling을 수행한 는 C1 층에서 추출된 특성 맵에 대해 정보를 간추리고 차원을 축소하는 역할을 합니다.
이러한 풀링 연산은 이미지의 공간 정보를 유지하면서 계산량을 줄이고, 위치 불변성을 제공하여 모델의 성능을 향상시킵니다.
C_3 Layer
크기의 데이터를 입력받아 크기의 필터를 16개로 , 을 적용하여 합성곱을 수행하여 크기의 Feature map을 출력하는 층을 의미합니다.
-
파라미터 개수
여기서 는 적용한 필터의 크기를 뜻하고, 16은 필터의 개수를 뜻합니다.
. 위의 공식에 60은 어떻게 나온 숫자일까요?
.
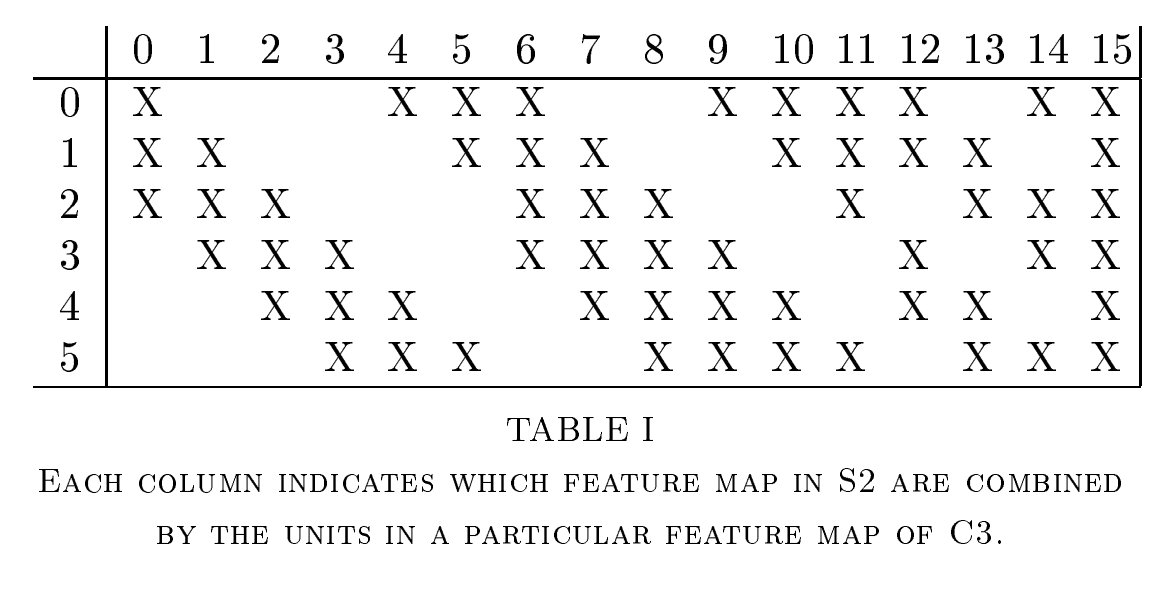
위 테이블에 표시가 S2 층와 C3 층의 연결 수 를 뜻합니다.
표시의 개수를 세어보면 60개입니다.
즉, 이 60개의 연결 수를 곱한 것을 의미합니다.
. 왜 모든 Feature map을 연결하지 않았을까요?.
논문 8페이지 첫 번째 문단 중
"More importantly, it forces a break of symmetry in the network"논문에서 말하길 symmetry(대칭성)을 깨기 위해서 저렇게 불연속적인 연결을 유지하기 위함입니다.
따라서 필터의 개수에 맞게 16개의 bias를 더해줘서 총 1516개의 파라미터 개수를 갖습니다.
-
뉴런의 연결 개수
connection의 수는
이 공식을 따르지 않습니다❌.
왜냐하면 non-symmetry 이기 떄문에 위 공식을 적용하지 못합니다.그렇다면 필터()가 개 만 연결되어 Feature map() 16개를 생성하고 편향()을 필터의 개수()를 Feature map()에 맞게 더해줘야 한다고 생각해보면
-
출력 데이터 크기
입력 데이터의 크기는 이고, 의 Convolution 필터를 적용하면
로 크기의 Feature map 16개를 생성합니다.
Feautre map을 6개 생성한 이유는 Convolutional Layer에 적용된 필터의 개수에 맞게 output으로 Feature map을 생성하기 때문입니다.
이렇게 합성곱을 수행한 는 C1 층에서 추출된 특성 맵에 대해 다시 한 번 합성곱 연산을 수행하여 더 복잡한 패턴과 특징을 추출하는 역할을 합니다.
S_4 Layer
크기의 데이터를 입력받아 크기의 filter를 overlapping되지 않도록 , 을 적용하여 Average Pooling을 수행하여 크기의 Feature map을 출력하는 층을 의미합니다.
-
파라미터 개수
여기서 앞의 괄호에 은 Average Pooling의 수행 결과 반환한 값 1개를 뜻하고, 뒤의 괄호에 은 를 뜻합니다.
을 곱한 이유는 적용한 필터의 개수가 16개이기 때문입니다.
Pooling Layer의 결과로 직전 Layer의 Feature map의 개수와 동일한 개수의 Feature map을 갖습니다.
따라서 파라미터의 개수는 32개가 됩니다. -
뉴런의 연결 개수
connection의 수는
-
출력 데이터 크기
입력 데이터의 크기는 이고, 의 Average Pooling 필터를 적용하면
로 크기의 Feature map을 16개 생성합니다.
Feature map을 16개 생성한 이유는 Average Pooling Layer에 적용된 필터의 개수와 맞게 output으로 Feature map을 생성하기 때문입니다.
이렇게 Pooling을 수행한 는 C3 층에서 추출된 고수준의 특성을 더 간결하게 표현하고, 중요한 특징을 보존하면서 입력 이미지의 크기를 줄이는 역할을 합니다.
크기를 줄인 특성 맵은 다음으로 연결된 C5 층으로 전달되어 최종적인 분류를 수행하는데에 활용됩니다.
C_5 Layer
크기의 데이터를 입력받아 크기의 필터를 120개로 , 을 적용하여 합성곱을 수행하여 크기의 Feature amp을 출력하는 Fully-connected 층을 의미합니다.
-
파라미터 개수
여기서 는 적용한 필터의 크기를 뜻하고,
는 Fully-connected Layer 이므로 모든 뉴런이 연결되있을 경우의 수를 뜻합니다.
뒤에 더해진 은 를 뜻합니다. -
뉴런의 연결 개수
Fuuly-connected Layer는 모든 노드가 연결된 층을 말합니다.
고로 뉴런(노드)의 연결 개수는 파라미터랑 똑같다고 보면 됩니다.
뉴런의 연결 개수와 파라미터가 같은 의미를 지녀, 파라미터 개수에서 계산된 결과인 가 됩니다. -
출력 데이터 크기
입력 데이터의 크기는 이고, 의 Convolution 필터를 적용하면
로 크기의 Feature map 120개를 생성합니다.
는 높은 수준의 추상적인 특성을 학습하고, 이를 기반으로 입력 이미지의 클래스를 분류하는 역할을 합니다.
F_6 Layer
크기의 Feature map 데이터를 입력받아 함수를 활성화 함수로 사용하여 크기의 84개 Feature map을 출력하는 Fully-connected 층을 의미합니다.
-
파라미터 개수
Fully-connected Layer이므로 직전 노드의 개수 현재 노드의 개수 편향 현재 노드의 개수로 이다.
-
뉴런의 연결 개수
Fuuly-connected Layer의 뉴런의 연결 개수와 파라미터와 같은 의미를 지닌다.

출력 Feature map이 84개인 이유는 ASCII set이 크기의 비트맵이기 때문에 84개의 Feature map을 출력하였습니다.
Output Layer
크기의 Feature map을 입력받아 최종 10개 Euclidean Radial Basis Function(RBF) unit을 출력합니다.
가중치 합(weighted sum) :
시그모이드 함수를 적용 :
논문에서 시그모이드 함수가 scaled된 함수라고 하네요.
RBF :
로 Euclidean Distance를 구하는 방식과 유사한 함수입니다.
이렇게 하여 최종 10개의 클래스(RBF unit)으로 최종적으로 이미지가 속한 클래스를 알 수 있습니다.
결과 분석
저자는 이 가설을 증명하기 위해 60,000개의 original pattern과 540,000개의 distorted pattern을 학습했습니다.
distortion의 종류는 수평 이동, 수직 이동, 크기 변환, squeezing(상하좌우 압축, 팽창), 자르기를 사용했다고 합니다.

위의 그림이 distortion 이미지 입니다.

위의 그림은 모델이 잘못 분류한 예입니다.
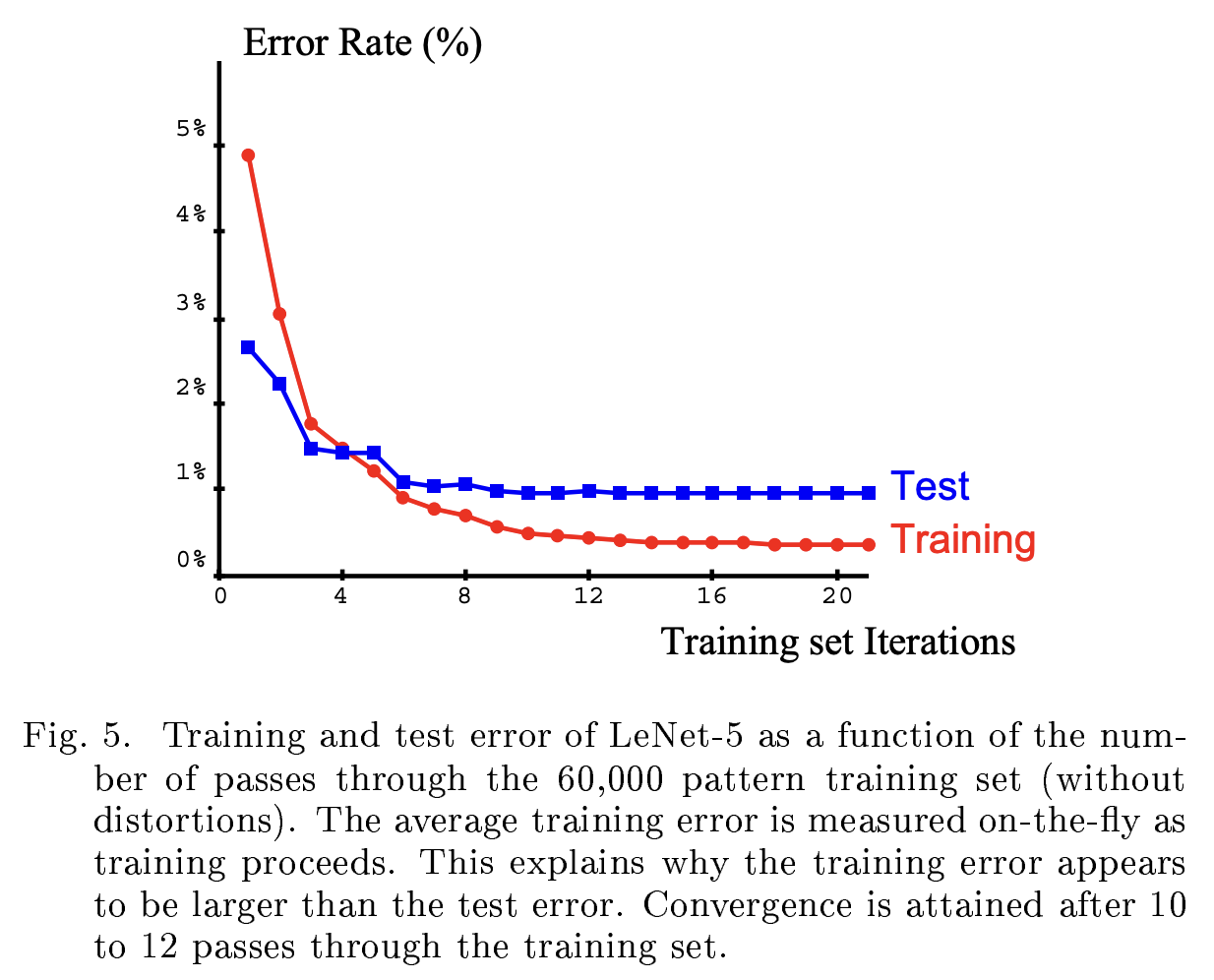
Modified NIST(MNIST) 데이터 셋을 distortion 데이터 없이 60,000 장을 학습시킨 결과입니다.
테스트 시 에러가 6 epoch 만에 1%에 근접한 것을 확인할 수 있습니다.
전통적인 이미지 분류 방법과 차원이 다른 학습 효율을 보여줬습니다.
요약 및 정리
✏️이 논문은 이미지 인식에 우수한 성능을 보여주며, 이미지 인식의 패러다임을 바꾼 논문입니다.
Convolution의 개념을 도입하여 메모리 효율을 늘리고, 연산량을 줄여 높은 성능을 보여줬습니다.
