
📝 이 포스트는 2012년에 발표된 AlexNet의 논문인 "ImageNet Classification with Deep Convolutional Neural Network" 에 대해 알아보겠습니다.
논문 순서와 다르게
📗저는 AlexNet 모델에 사용된 기술들을 설명하고 그다음 마지막으로 Architecture를 Layer 별로 특징들을 설명하겠습니다.
배경
AlexNet은 'Alex Krizhevsky' 저자의 2012년 ImageNet Large Scale Visual Recognition Competition (ILSVRC)를 우승했던 CNN 모델에 대한 논문입니다.
AlexNet은 깊고 더 많은 뉴런을 가진 네트워크로 발전하는 계기가 되었습니다.
'Introduction' 에서 객체 인식을 하기 위해 머신러닝 기법을 필수적으로 사용한다고 합니다.
머신러닝 성능을 향상시키기 위한 방법으로
- 더 많은 데이터셋을 수집한다.
- 더 강력한 모델을 학습시킨다.
- 과적합을 방지하기 위한 더 나은 기법을 사용한다.
이 신경망의 depth를 달리하여 이미지를 올바르게 assumption할 수 있습니다.
📘 따라서 CNN은 과거의 이미지 인식 방법과 다르게 더 적은 connection과 파라미터로 보다 쉽게 높은 성능을 보일 수 있다고 합니다.
하지만 이런 CNN의 매력적인 성질과 상대적으로 효율적인 아키텍쳐를 가졌음에도 불구하고 문제점이 있습니다.❗️
❗️바로 큰 스케일의 고해상도 이미지를 학습하기 위해서는 엄청난 비용이 따른다는 것입니다.
📘 이 엄청난 비용의 연산량을 감당하기 위한 해결책으로 GPU(Graphic Process Unit)이 사용되었습니다.
GPU는 합성곱 연산에 고도로 최적화되어 큰 CNN 모델을 학습시키기 충분히 가능하게 한다.
그리고 ImageNet 데이터셋은 라벨링이 되어 있어 과적합 없는 훈련을 가능하게 했습니다.
그리고 ImageNet 이미지들은 해상도가 각각 다양해서 이미지들을 256X256 사이즈로 down-sampling을 하여 통일시켰습니다.
그리고 이미지의 중요한 부분을 center crop을 수행하였습니다.
ReLU
이 전 다른 연구자들은 activation function으로 함수와 함수와 같은 saturating nonlinearity 를 사용했었습니다.
경사 하강법을 사용한 훈련 시간 측면에서 saturating nonlinearity가 non-saturating nonlinearity보다 훨씬 느린 속도를 보이는 것을 확인하였습니다.
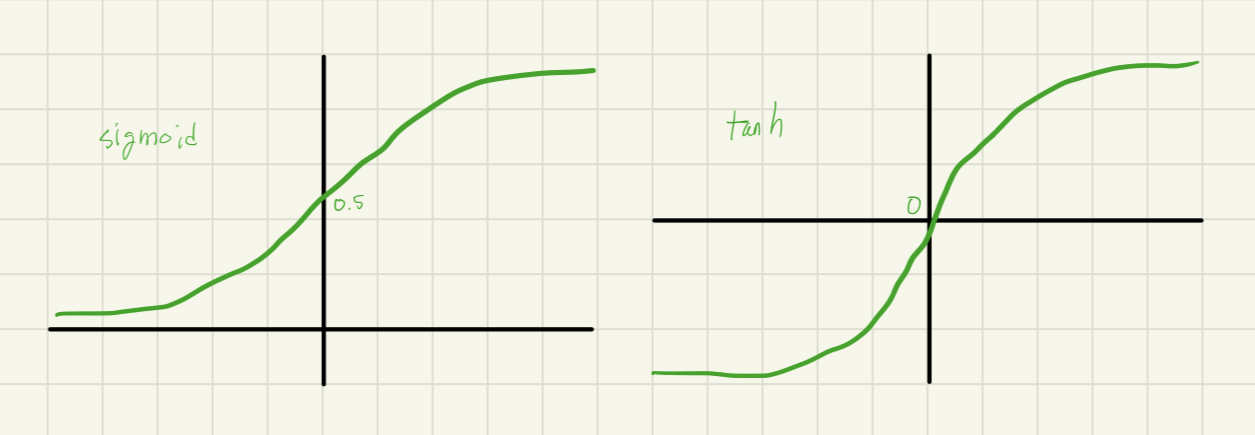
saturating nonlinearity는 와 같은 포화 비선형성 함수를 뜻하는데요.
📖'saturate'는 사전적인 의미로 '포화시키다'를 뜻합니다.
즉 수학적인 의미로 어떤 값에 수렴함을 뜻합니다.
예를 들어 함수 가
으로 수렴하고
으로 수렴하는 형태의 함수들을 'saturating nonlinearity' 라고 합니다.
반대로 'non-saturating nonlinearity'는 앞의 'non-'이 붙은 그대로 반대의 의미를 지닙니다.
수렴하지 않는 조건을 말하는 거죠.
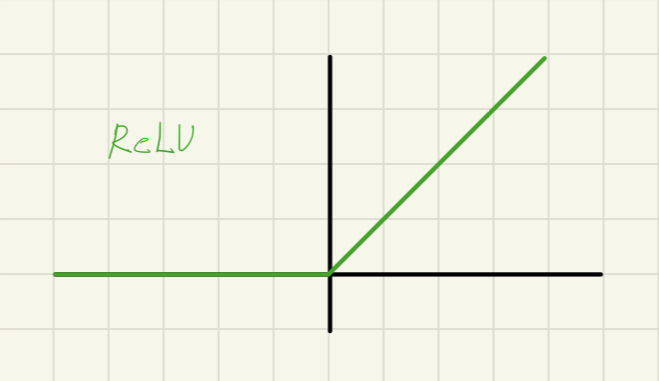
예를 들어 함수 를 보면
이지만
로 양의 방향에서는 특정 어느 값에 수렴하지 않는 것을 보실 수 있습니다.
함수의 경우에는 가 양의 방향으로 증가할 경우 로 증가하죠.
V. Nair and G. E. Hinton. Rectified linear units improve restricted boltzmann machines. In Proc. 27th
International Conference on Machine Learning, 2010.
위 논문에 따르면
이러한 'saturating nonlinearity(, )'보다 Rectified Linear Unit이 합성곱 신경망을 동일한 조건에서 학습시킬 때 (saturating nonlinearity) 보다(non-saturating nonlinearity) 함수가 학습속도 측면에서 몇 배 더 빠른 것을 증명하였습니다.
AlexNet 연구팀은 위 논문을 바탕으로 four-layer CNN를 CIFAR-10 데이터셋으로 학습해보았더니 실제로 활성화 함수 이외에 모든 파라미터들을 동일한 조건으로 하였을 때, 활성화 함수를 사용하였을 때 보다 훨씬 빠른 학습속도를 보였습니다.
를 활성화 함수로 사용하였을 때 단 6번의 iteration으로 훈련 에러율 25%에 도달하는 실험을 입증하였습니다.
는 모든 Convolutional Layer, Fully-connected Layer에 적용됩니다.
GPU parallelization
❗️연구팀은 GTX 580 3GB GPU 하나로 엄청난 크기의 네트워크를 훈련시키는 것에 한계를 느꼈습니다.
신경망을 훈련시키기에 120만 개의 고해상도 이미지가 GPU에게 너무 과한 부담이였습니다.
📘 따라서, 연구팀은 GPU 두개가 서로의 메모리를 직접 읽어오고 쓸 수 있게 병렬 연결하여 훈련시켰습니다
병렬처리 방법으로는 각 층별 총 커널의 개수를 반으로 나눠 각 GPU가 처리할 수 있게 하였습니다.
GPU 두개가 서로의 메모리를 직접 읽어오고 쓸 수 있다고 했지만 모든 층에서 각 GPU가 맡은 커널을 공유하지 않습니다.
특정 층에서만 각 GPU가 맡은 커널을 공유합니다.
특정 층이 어디인지는 뒤에 AlexNet 아키텍쳐를 설명할 때 상세히 언급하겠습니다.
Local Response Normalization
함수를 정규화하여 네트워크의 일반화 능력을 향상시키는 데 사용됩니다.
- : 정규화된 결과로, i번째 피쳐 맵에서 위치 (x, y)의 값
- : (x,y) 위치에서 i번째 커널을 적용하여 계산된 뉴런의 값. 즉, (x, y) 위치의 i번째 피쳐 맵의 원소 값
- : Layer내에 사용되는 총 커널 맵의 개수
- : 동일한 층 내에 인접한 커널 맵 개수
- : 하이퍼 파라미터 (직접 입력하는 값)
- : 상수
커널맵의 순서는 random하고 학습 전에 결정되는 값이다.
주의 해야할 것은 우리는 평균을 빼는 정규화 과정이 아니라는 것이다.
해당 값에서 평균을 빼는 연산을 수행하지 않는다.(배치 정규화 같은...)
📘 LRN의 효과로 큰 값이 더 커지도록 조절하여 네트워크가 더 민감한 활성화를 보다 강조하게 되고, 모델의 일반화 능력이 향상될 수 있습니다.
Response-normalization layers follow the first and second convolutional layers.
-출처- 논문속 page 4
LRN(Local Response Normalization) 이 Convolution 연산을 따른다고 논문에 언급이 되었습니다.
❗️LRN 연산은 정규화로써 출력되는 Feature map의 크기가 달라지지는 않습니다.
1번째와 2번쨰 Convolutional Layer에서 연산을 수행합니다..
Overlapping Pooling
전통적인 Pooling 방식은 non-Overlapping한 방식을 따랐습니다.
즉, Pooling Filter의 번째 receptive field(필터의 연산이 수행되는 영역)가 번째 receptive field와 겹치지 않도록 Pooling을 연산하는 방식을 말합니다.
크기를 라 하고, 크기의 Pooling Filter를 적용한다고 하면
-
일 경우
non-Overlapping한 Pooling이 이루어집니다. -
일 경우
Overlapping한 Pooling이 이루어집니다.
이 논문에서는 Overlapping 방식을 수행하였습니다.
📘 Overlapping을 하는 이유는 더 많은 중요한 Feature를 유지하고 이미지의 세부적인 특징을 보존할 수 있도록 해줍니다.
AlexNet은 모든 층에서 Pooling 연산을 수행하지 않고, 특정 층에서만 수행합니다.
Max-pooling layers of the kind described in Section3.4, follow both response-normalization layers as well as the fifth layer.
-출처- 논문속 page 4
라고 논문에 언급이 되었습니다.
LRN 연산이 나온 1번째, 2번째 Convolutional Layer와 추가적으로 5번째 Convolutional Layer에서 Max Pooling 연산이 수행됩니다.
❗️LRN 연산과는 다르게 Max Pooling 연산은 출력되는 Feature map의 크기를 변환시킵니다.
이 논문에서는 Overlapping Pooling을 수행하는 모든 층이 stride = 2, filter length = 3 으로 하여 Overlapping Pooling을 수행하였다고 합니다.
Data Augmentation
이 논문에서 Overfiiting을 방지하기 위해 데이터 증강이라는 방법을 사용하였다.
데이터를 증강하는 방법으로
- 크기의 이미지를 크기로 resize합니다.
- RGB 픽셀값에 PCA(주성분 분석)을 수행하여 이미지의 intensity 를 바꿉니다.: 번째 공분산행렬의 고유 벡터
: 번째 공분산행렬의 고유값
: 번쨰 공분산행렬의 평균은 0, 표준편차는 0.1인 가우시안 랜덤 변수
Dropout
큰 신경망을 학습하기 위해서 몇일이 걸리는 모델 학습이 필요했습니다.
이 문제를 해결하기 위해 전체 뉴런 중 50%을 값을 0 으로 만들어주는 작업을 수행합니다.
Dropout은 1st, 2nd Fully-connected Layer에서 수행합니다.
Detail of learning
모델을 훈련시킬 때 optimizer로 Stochastic Gradient Descent를 사용하였습니다.
- : batch size = 128
- momentum : 0.9
- weight decay : 0.0005
- initialized wieght : 0.01( 가우시안 분포의 표준편차로부터 나온 값이다)
- : initial learning rate = 0.01
- cycle(=epoch) : 90(roughly)
를 적용하여
위 수식을 통해 SGD를 수행하여 역전파를 수행합니다.
는 번째 배치 의 평균을 말합니다.
Overall Arhitecture
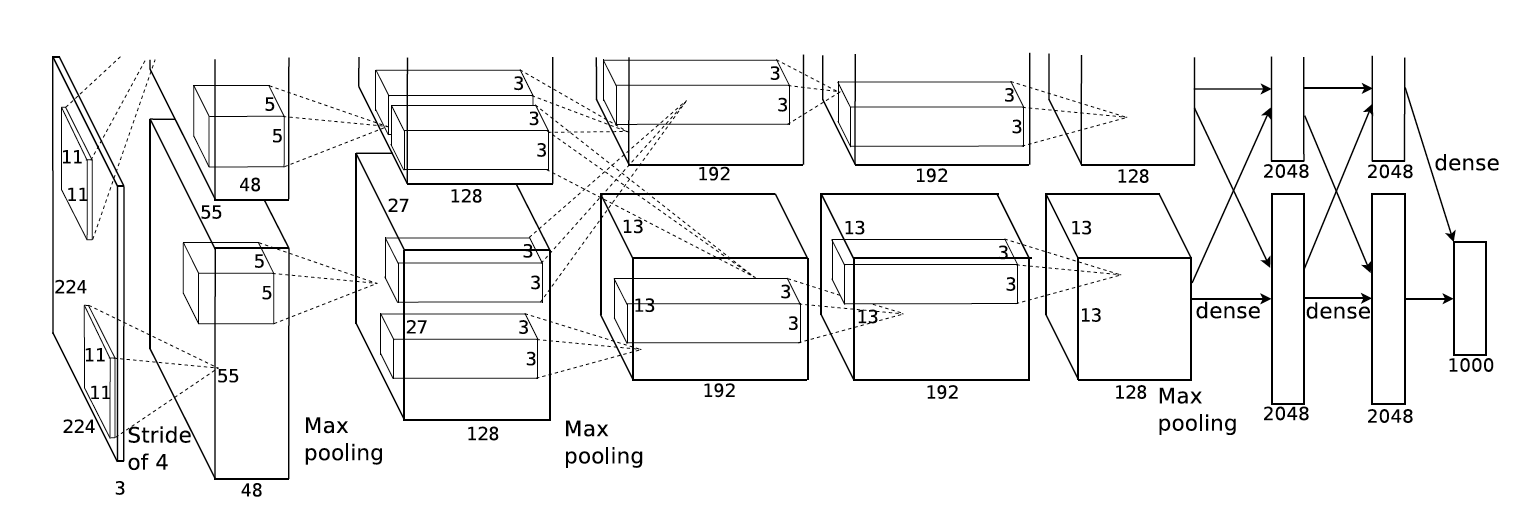
AlexNet 아키텍쳐는 총 8개의 층으로 이루어져있습니다. 아키텍처의 앞 5층은 Convolutional Layer이고, 나머지 3개층은 Fully-connected Layer입니다.
Input Layer
크기의 이미지를 입력받습니다.
1st Convolutional Layer
- 두 GPU가 서로 communicate 하지 않음 ❌
즉, 이전 층에서 출력한 커널맵을 GPU가 공유하지 않는다.
-
Convolution
- Input : 크기의 이미지
- Kernel : 96개의 Kernel map(GPU 두개가 절반씩 나누어가짐)
- stride : 4
- padding : 0
논문에서 padding이 몇인지 언급이 없어서 직접 출력 이미지 크기 구하는 공식을 통해 계산을 해보니
를 풀어보면
가 나옵니다.
❗️ 패딩 폭이 1.5라는게 이상합니다.
그래서 저는 입력 이미지 크기가 224가 아닌 것 같다는 생각이 들어서 입력 이미지 크기를 미지수 라 두고 다시 공식을 써보았습니다.식이 나옵니다.
저는 패딩 없이 입력 이미지 크기가 227일 것이라고 생각하였습니다.
AlexNet 연구팀이 추후에 은 오류가 맞고, 이라고 발표했습니다.
따라서 Convolution 연산 결과로- Convolution Output : 크기의 Feature map
-
Activation Function
Convolution 연산 후 Activation Function으로 ReLU를 적용해줍니다.
ReLU의 연산 결과로 Feature map의 크기가 달라지지는 않습니다. -
Local Response Normalization
Activation Function 적용 후 LRN(Local Response Normalization)을 수행합니다.
LRN 연산 결과로 Feature map의 크기가 달라지지는 않습니다. -
Max Pooling
Local Response Normalization 연산 후- stride : 2
- Filter size =
- padding : 0
로 Overlapping Max Pooling을 수행하면
한 변의 크기가 27인 Feature map이 출력됩니다.
- Max Pooling Output : 크기의 Feature map
최종적으로 1st Convolutional Layer에서 크기의 Feature map을 출력합니다.
2nd Convolutional Layer
- 두 GPU가 서로 communicate 하지 않음 ❌
즉, 이전 층에서 출력한 커널맵을 GPU가 공유하지 않는다.
-
Convolution
- Input : 크기의 Feature map
- Kernel : 256개의 크기의 Kernel map(GPU 두개가 절반씩 나누어가짐)
- stride : 1
- padding : 2
논문에서 padding은 몇으로 주었는지, stride는 몇인지 언급이 없어서 직접 출력 이미지 크기 구하는 공식을 통해 계산을 해보니
를 풀어보면
로 , 임을 알 수 있습니다.
-
Activation Function
Convolution 연산 후 Activation Function으로 ReLU를 적용해줍니다.
ReLU의 연산 결과로 Feature map의 크기가 달라지지는 않습니다. -
Local Response Normalization
Activation Function 적용 후 LRN(Local Response Normalization)을 수행합니다.
LRN 연산 결과로 Feature map의 크기가 달라지지는 않습니다. -
Max Pooling
Local Response Normalization 연산 후- stride : 2
- Filter size =
- padding : 0
로 Overlapping Max Pooling을 수행하면
한 변의 크기가 13인 Feature map이 출력됩니다.
- Max Pooling Output : 크기의 Feature map
최종적으로 2nd Convolutional Layer에서 출력되는 Feature map은 입니다.
3rd Convolutional Layer
- 두 GPU가 서로 communicate 함 ⭕️
즉, 이전 층에서 출력한 커널맵을 GPU가 공유하여 모든 커널맵을 연산에 포함한다.
-
Convolution
- Input : 크기의 Feature map
- Kernel : 384개의 크기의 Kernel map(GPU 두개가 절반씩 나누어가짐)
- stride : 1
- padding : 1
논문에서 padding은 몇으로 주었는지, stride는 몇인지 언급이 없어서 직접 출력 이미지 크기 구하는 공식을 통해 계산을 해보니
를 풀어보면
로 , 임을 알 수 있습니다.
- Convolution Output : 크기의 Feature map
-
Activation Function
그 다음 Activation Function으로 ReLU를 적용해줍니다.
ReLU의 연산 결과로 Feature map의 크기가 달라지지는 않습니다.
❗️ 3번째 합성곱 층은 LRN과 Max Pooling이 수행되지 않습니다.
최종적으로 3rd Convolutional Layer에서 출력되는 Feature map은 입니다.
4th Convolutional Layer
- 두 GPU가 서로 communicate 하지 않음 ❌
즉, 이전 층에서 출력한 커널맵을 GPU가 공유하지 않는다.
-
Convolution
- Input : 크기의 Feature map
- Kernel : 384개의 크기의 Kernel map(GPU 두개가 절반씩 나누어가짐)
- Stride : 1
- Padding : 1
논문에서 padding은 몇으로 주었는지, stride는 몇인지 언급이 없어서 직접 출력 이미지 크기 구하는 공식을 통해 계산을 해보니
를 풀어보면
로 , 임을 알 수 있습니다.
- Convolution Output : 크기의 Feature map
-
Activation Function
그 다음 Activation Function으로 ReLU를 적용해줍니다.
ReLU의 연산 결과로 Feature map의 크기가 달라지지는 않습니다.
❗️ 3번째 합성곱 층은 LRN과 Max Pooling이 수행되지 않습니다.
최종적으로 4th Convolutional Layer에서 출력되는 Feature map은 입니다.
5th Convolutional Layer
- 두 GPU가 서로 communicate 하지 않음 ❌
즉, 이전 층에서 출력한 커널맵을 GPU가 공유하지 않는다.
-
Convolution
- Input : 크기의 Feature map
- Kernel : 256개의 크기의 Kernel map(GPU 두개가 절반씩 나누어가짐)
- stride : 1
- padding : 1
논문에서 padding은 몇으로 주었는지, stride는 몇인지 언급이 없어서 직접 출력 이미지 크기 구하는 공식을 통해 계산을 해보니
를 풀어보면
로 , 임을 알 수 있습니다.
- Convolution Output : 크기의 Feature map
-
Activation Function
그 다음 Activation Function으로 ReLU를 적용해줍니다.
ReLU의 연산 결과로 Feature map의 크기가 달라지지는 않습니다.
❗️5번째 Convolutional Layer는 LRN 연산을 수행하지 않는다.
- Max Pooling
Activation Function 적용 후- stride : 2
- Filter size =
- padding : 0
한 변의 크기가 6인 Feature map이 출력됩니다.- Max Pooling Output : 크기의 Feature map
최종적으로 5th Convolutional Layer에서 출력되는 Feature map은 입니다.
1st Fully-connected Layer
-
Flatten
Convolutional Layer에서 Fully-connected Layer로 이동할 때 평탄화 과정이 필요합니다.
따라서 을 Flatten 하여 9216개의 입력 뉴런을 4096개의 출력 뉴런 벡터를 변환합니다. 이러한 구성은 뉴런 수를 줄여 모델의 파라미터 수를 감소시키고 계산량을 줄이기 위함입니다.그 후에 0.5 비율의 Dropout을 수행합니다.
2nd Fully-connected Layer
0.5 비율의 Dropout을 수행합니다.
3rd Fully-connected Layer
vector의 개수를 1000으로 소프트맥스를 수행하여 최종 1000개의 클래스를 도출합니다.
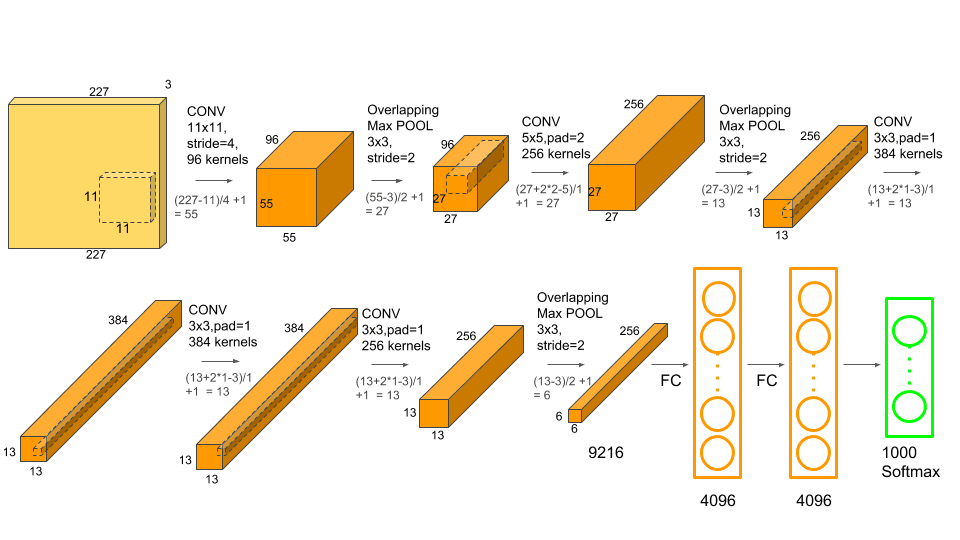
위 그림은 아키텍쳐를 Convolutional Layer와 Max Pooling Layer를 분리하여 도식한 아키텍쳐입니다.
위 아키텍쳐를 보면 이해가 쉬울 수 있습니다.
이로하여 ImageNet Classification with Deep Convolutional Neural Networks 논문 분석을 마치겠습니다.
