
📝 이 포스트는 2014년에 발표된 VGGNet의 논문인 "VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION" 에 대해 알아보겠습니다.
배경
연구팀은 신경망의 깊이가 정확도에 얼마나 영향을 주는지 연구를 하였습니다.
연구팀은 ILSVRC(ImageNet Large-Scale Visual Recognition Challenge) 2014에 참가하고 VGGNet은 localization 부문에서 1등, classification 부문에서 2등을 수상하였습니다.
classification 부문 1등은 GoogLeNet이 차지하였죠.
(다음 논문 분석으로 GoogLeNet을 할 예정입니다)
VGGNet은 비교적으로 구현은 간단합니다.
Convolution, Pooling, Normalization 등의 기본 concept으로 구현됬지만, 다른 모델들과의 차이점은 DEPTH입니다✅.
AlexNet의 발표 이후 많은 연구자들이 신경망의 DEPTH를 깊게 만드는 시도들은 많았지만 과적합 문제를 해결하지 못하였습니다.
AlexNet : Krizhevsky, A., Sutskever, I., and Hinton, G. E. ImageNet classification with deep convolutional neural networks. In NIPS, pp. 1106-1114, 2012.
어떻게 VGGNet 연구팀은 이 문제를 해결하고 신경망을 깊게 쌓을 수 있었는지 알아보겠습니다.
저는 이 논문을 읽고 3X3 합성곱 필터의 중요성과 1X1 합성곱 필터의 기능, Image cropping의 기능이 핵심이라 생각하여 이에 대해서 깊이 있게 다룰 것입니다.✏️
아키텍쳐
아키텍쳐가 어떻게 이루어졌다는 것은 이 논문의 핵심이 아닌 것 같아 얕게 설명하겠습니다.
따라서 아키텍쳐 부분은 가볍게 읽고 넘어가시고 뒤의 3X3 합성곱 필터의 중요성과 1X1 합성곱 필터의 기능, Image cropping의 기능 설명으로 넘어가시면 되겠습니다.
아래 그림은 연구팀이 연구한 모델들은 아래와 같습니다.
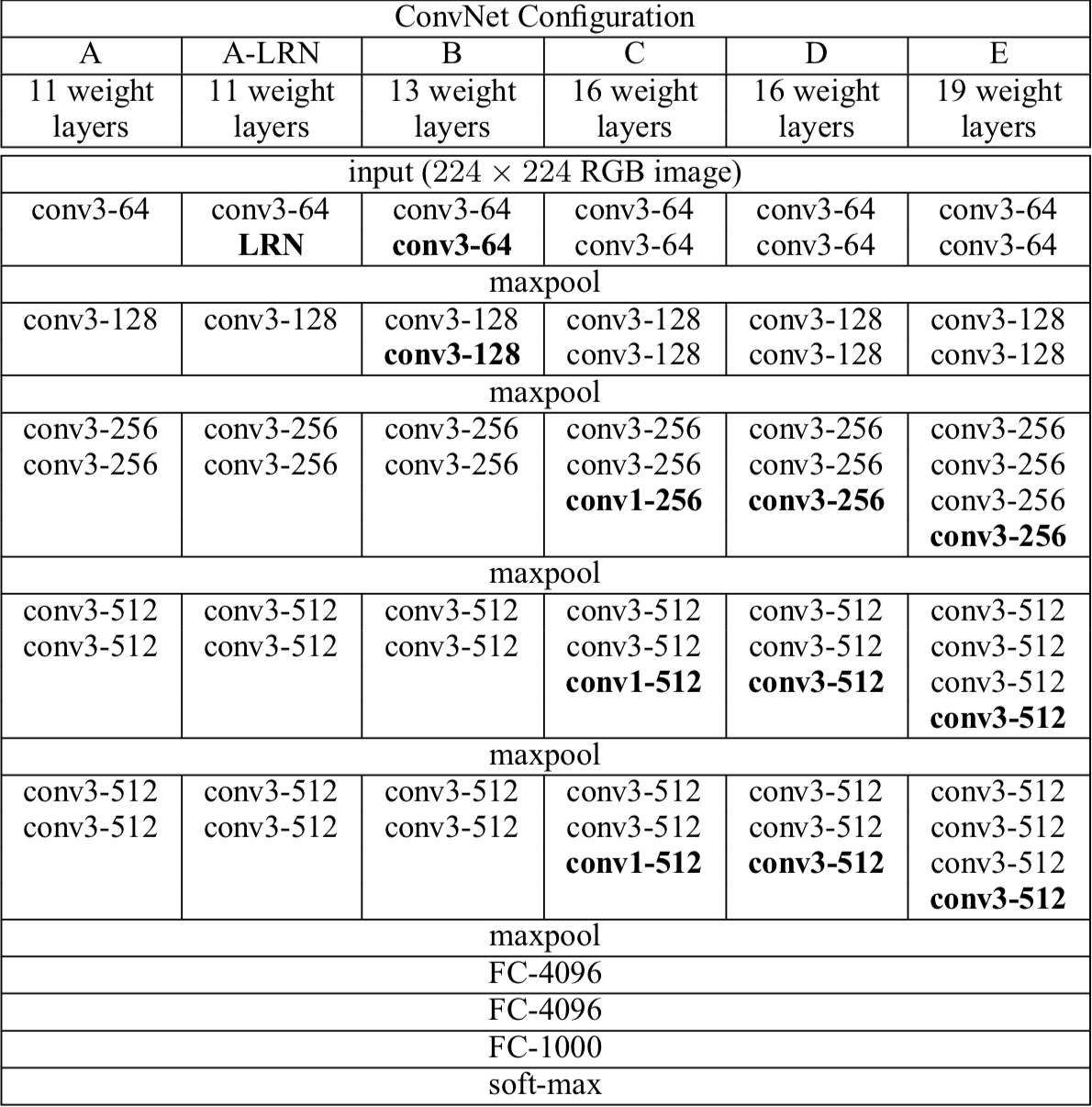
연구팀은 11 Layer 모델부터 시작하여 19 Layer 모델까지 층을 쌓아가면서 실험을 해보았다고 합니다.
이 6개 모델들은 공통적으로 아래와 같은 특징들을 같습니다.
-
Input Layer
- 크기의 RGB 이미지
// - 전처리 : 훈련셋 이미지에 RGB 평균값 빼주기
- 크기의 RGB 이미지
-
Convolutional Layers
- A, A-LRN, B, C, D, E 모델들의 Convolutional Layer 개수 차이로 각 모델별로 상이하지만 공통적으로 3X3 커널을 사용해 합성곱을 수행합니다. (C모델의 경우 non-linearity를 위해 1X1필터도 사용함(뒤에서 1X1필터에 대해서 자세히 다룰거임)
-
Fully-connected Layers
- A, A-LRN, B, C, D, E 모델 모두 공통적으로 1st FC Layer, 2nd FC Layer가 VGGNet 4096개의 채널을 갖고 3rd FC Layer는 1000개의 채널을 갖습니다.
-
Softmax Layer
- A, A-LRN, B, C, D, E 모델 모두 공통적으로 마지막 층으로 Softmax 함수를 수행하는 층을 갖습니다.
- 이 연구팀은 Softmax를 특정 층으로 분류하였네요.
-
ReLU
- Input Layer와 Output Layer를 제외한 Hidden Layer에서 ReLU를 activation function으로 적용합니다.
-
Normalization
- 오직 A모델만 (Local Response Normalization)LRN을 수행한다.
- LRN이란 매우 높은 하나의 픽셀값이 주변 픽셀에 영향을 주는 것을 방지하기 위해 다른 Feature map의 같은 위치에 있는 픽셀끼리 정규화합니다.
-
Dropout
- 1st FC Layer, 2nd FC Layer에서 Dropout을 수행합니다.
- dropout 비율은 0.5로 수행합니다.
-
batsize = 256 배치단위로 학습합니다.
-
momentum = 0.9 Stochastic
-
L2 penalty = 0.0005
-
learning rate는 0.01로 초기화합니다.
저는 이 논문에서 연구한 A,A-LRN, B, C, D, E 모델 아키텍쳐가 어떤 구성을 갖는지는 이렇게까지만 분석하고 말겠습니다.
왜냐하면 이 논문으로부터 알아볼 중요한 점은 모델의 각 층이 어떻게 구성되었는지가 아닙니다.
이 논문의 주요 핵심은 아키텍쳐의 층별 구성이 아니고 깊이입니다.
저는 깊이를 어떻게 하면 깊게 쌓을 수 있었는지 이 논문을 분석해보았습니다.
3X3 Filter
이 논문에서는 층을 깊게 쌓을 수 있었던 주 원인은 3X3 합성곱 필터라고 합니다.
층을 깊게 쌓으면 쌓을수록 당연히 파라미터 수가 증가하고 연산량이 증가하면서 실행속도 면에서 저하되게 됩니다.❗️
파라미터 수만 해결할 수 있다면 층을 깊게 쌓을 수 있다는 게 주요 핵심입니다.
소주제 (1. Stack of 3X3 Filter), (2. Stride = 1, Padding = 1), (3. Parameter) 로 나누어 이해를 도울 수 있게 설명하겠습니다.
1. Stack of 3X3 Filter
이전 AlexNet 논문과 비교해보면 AlexNet에서는11X11, 5X5 합성곱 필터를 사용했었는데요.
VGGNet에서는 AlexNet과 같이 크기가 큰 합성곱 필터를 사용하지 않습니다.
연구팀은 7X7 합성곱 필터를 사용하는 대신에 3개의 3X3 Convolution 필터를 사용하여 표현했습니다.
3개의 3X3 Convolution 필터를 3개 쌓아서 스택으로 사용하는 이유는 7X7 합성곱 필터를 사용하였을 때 보다 파라미터 수를 감소시킬 수 있기 때문입니다.
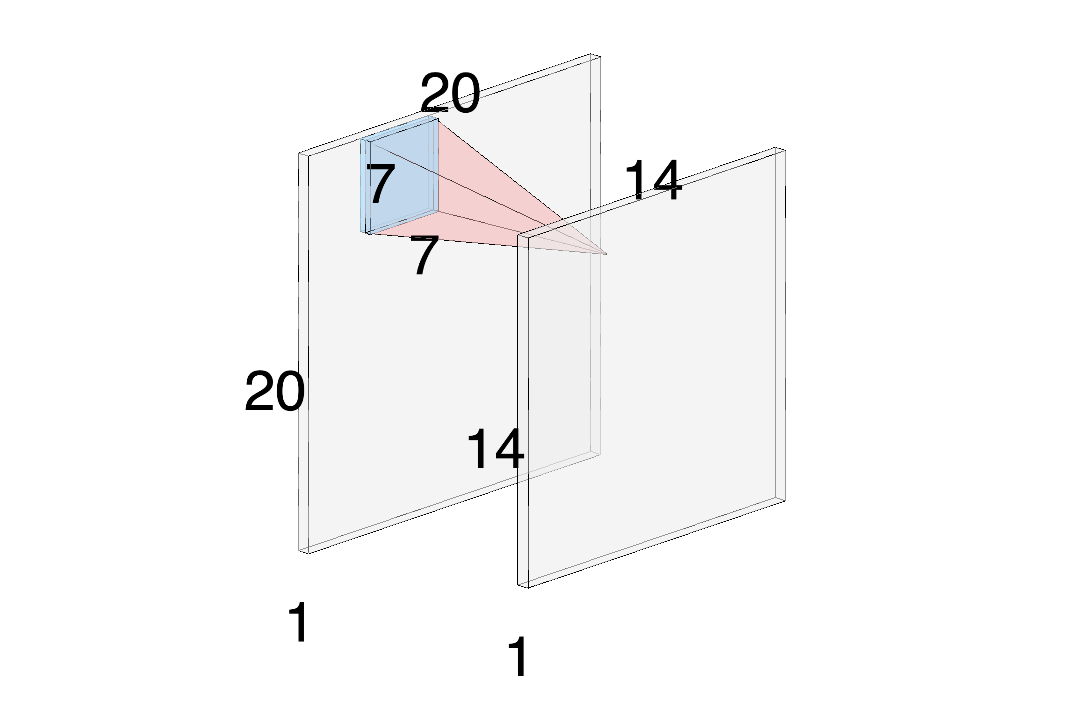
크기의 입력 이미지를 커널을 사용하면 위의 그림과 같이 크기의 Feature Map을 출력합니다.
공식으로 검토↓
: Length of Input Image
: Length of padding
: Length of filter
: Stride
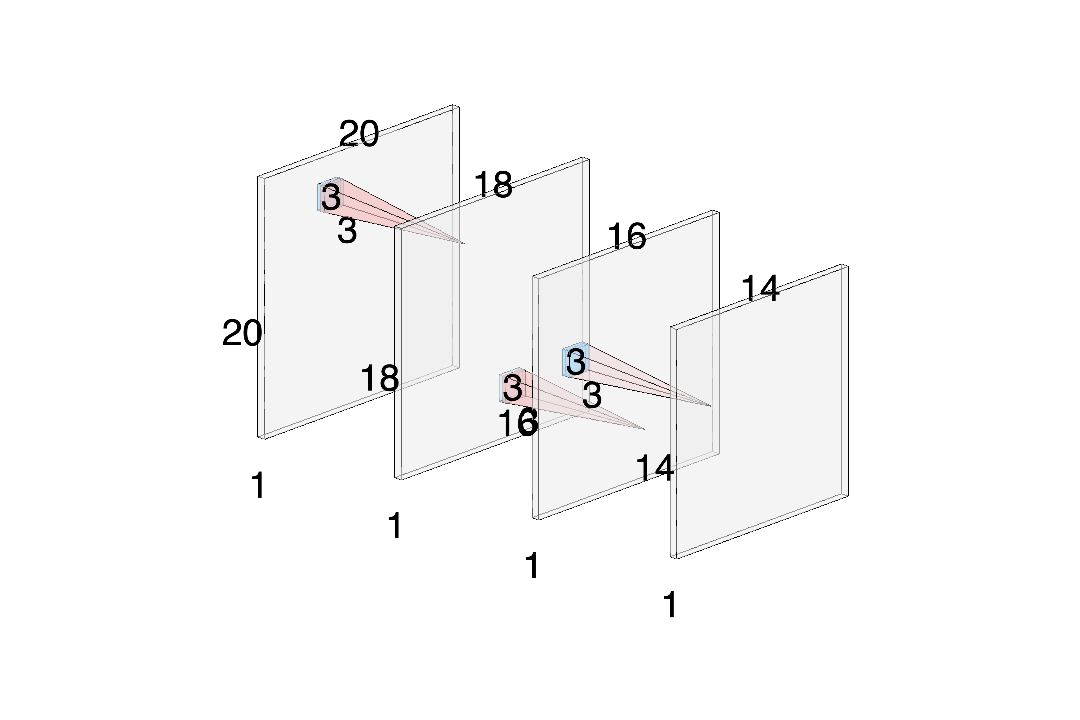
이번에는 크기의 입력 이미지를 연속된 3개의 커널을 이용하여 합성곱을 수행하여 Feature Map을 출력하는 것을 확인할 수 있습니다.
공식으로 검토↓
와 같이 필터와 3개의 필터를 사용하였을 떄 출력하는 Feature Map의 크기가 같은 것을 확인할 수 있습니다.
2. Stride = 1, Padding = 1
이번에 다룰 소주제는 stride와 padding입니다.
직전에 설명했던 소주제에서
필터를 사용하면 사용할수록 출력 Feature Map의 크기가 작아지는 것을 확인할 수 있었습니다.
연구팀은 출력 Feature Map의 크기를 유지하면서 Convolution을 수행하기 위해 매 필터의 convolution을 수행할 때마다 stride=1, padding=1를 적용하여 피쳐맵 크기의 감소를 방지하였습니다.
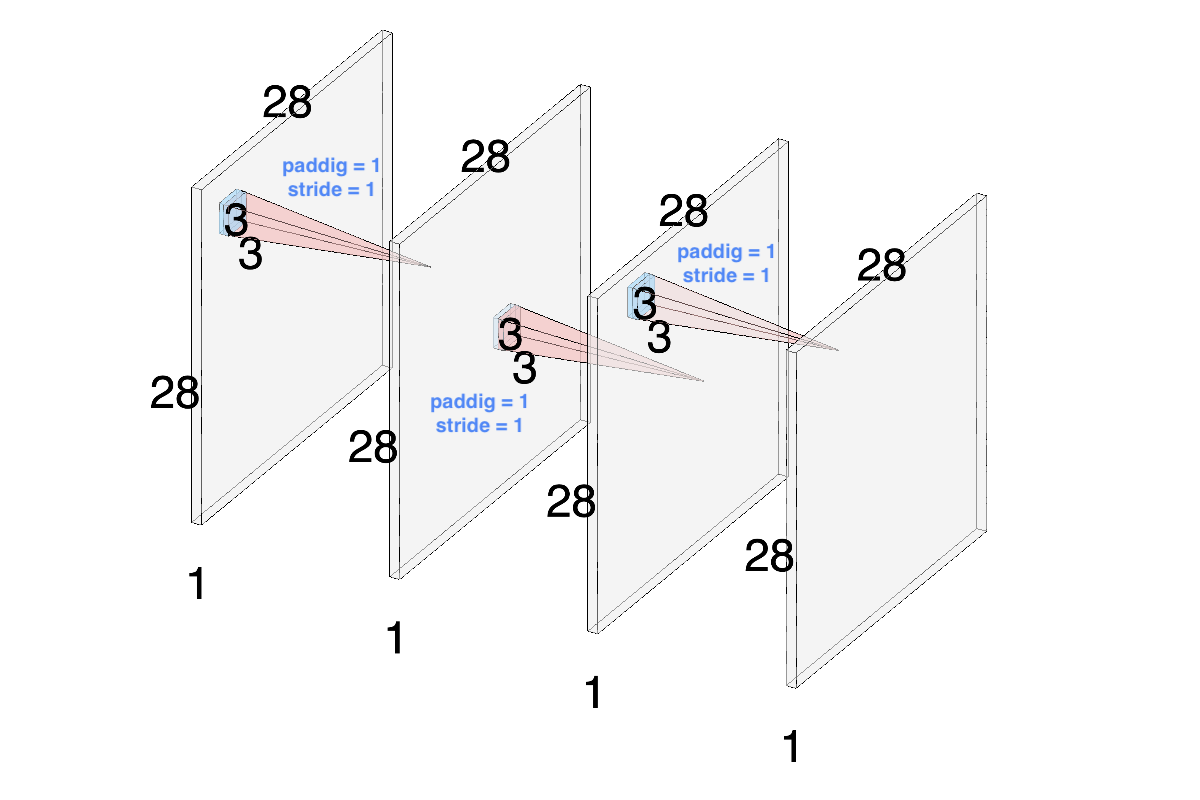
로 Feature Map의 크기를 유지할 수 있습니다.
3. Parameter
이렇게 유지되면서 출력되는 피쳐맵을 3개의 3X3 합성곱 필터 스택을 사용하여 7X7필터의 효과를 보면서도 파라미터 수는 7X7 필터보다 작게 유지할 수 있습니다.
파라미터 수를 구하는 공식으로 알아보면
이지만 뒤의 편향()은 이번 간략한 예시에서 무시하고 설명하겠습니다.
3개의 필터를 사용한다면 입니다.
반면 필터를 사용한다면 로 필터 3개를 사용할 때보다 81% 더 많은 파라미터 수를 갖게 됩니다🚨.
마찬가지로 5X5 필터 대신 2개의 3X3 필터 스택으로 표현하여 5X5 필터의 효과를 보면서도 파라미터 수도 감소할 수 있는거죠.
5X5 필터를 사용하여 합성곱을 수행하면 25의 파라미터를 갖고 3X3필터 2개를 사용한다면 18의 파라미터를 갖습니다.
5X5 필터가 3X3필터 2개를 사용할 때보다 39% 더 많은 파라미터를 갖습니다.
Stack of 필터로 인해 파라미터 수를 줄일 수 있으므로 연산량도 줄일 수 있고, 실행시간도 단축시킬 수 있어 층을 깊게 쌓을 수 있었던 원인이 됩니다.
1X1 필터
모델 C의 경우에는 필터의 convolution이 수행됩니다.
Convolution 필터는 출력 Feature Map에 대해서는 영향을 주지 않고 뒤이어 수행되는 ReLU로 decision function의 non-linearity 특성을 증가시킵니다.
Classification Framework
연구팀은 Convolution의 단순함에서도 성능을 높이기 위해 traing 과 testing에 다양한 방법으로 성능을 높이는 방법을 찾았습니다.
Training
모델을 Training 시에 입력 이미지의 크기를 크기로 고정하여 훈련했습니다.
논문에서
Training scale :
Testing scale :
라고 하였습니다.
- Single scale training
를 256 아니면 384로 두 개로 고정합니다. - Multi scale training
를 [] 사이의 값으로 랜덤하게 결정합니다.
은 256이고 은 512 입니다.
이렇게 훈련 이미지를 다양한 크기로 변환하고 그 중 객체이 일부가 포함된 크기의 이미지를 cropping합니다.
이렇게 샘플링하여 얻을 수 있는 장점으로는
- 한정적인 데이터의 수를 늘릴 수 있다.
이러한 방법을 Data augmentation이라고 한다. 여러 Data augmentation 방법 중 cropping을 수행한 것이다. - 하나의 오브젝트에 대한 다양한 측면을 학습 시 반영시킬 수 있다. 변환된 이미지가 작을수록 객체의 전체적인 측면을 학습할 수 있고, 변환된 이미지가 클수록 객체의 특정한 부분을 학습에 반영할 수 있습니다.
위 두 가지 모두 Overfitting을 방지해줍니다.
Testing
테스트 시에는 Fully-connected Layer를 Convolutional Layer로 변환해줍니다.
- 1st Fully-connected Layer 크기의 필터로 Convolution을 수행하는 Convolutional Layer로 변환합니다.
- 2nd Fully-connected Layer 크기의 필터로 Convolution을 수행하는 Convolutional Layer로 변환합니다.
- 3rd Fully-connected Layer 크기의 필터로 Convolution을 수행하는 Convolutional Layer로 변환합니다.
이렇게 변환된 층을 Fully-convolutional Net이라고 합니다.
그리고 이렇게 Fully-convolutional Net으로 변환하면 모든 크기의 이미지 테스트가 가능하게 됩니다.
입력 이미지를 다양한 스케일로 사용한 결과들을 테스트하여 이미지 분류 정확도를 개선하는 것도 가능하게 했습니다.

훌륭한 글 감사드립니다.