
📝 이번 포스트는 "YOLOv3: An Incremental Improvement"논문에 대해 알아보도록 하겠습니다.
2. The Deal
저자는 대부분의 기술을 다른 사람들의 좋은 아이디어에서 빌려와 구현하였습니다.
아래 하위 항목들에서 구현한 기술들을 소개할 것입니다.
2.1 Bounding Box Prediction
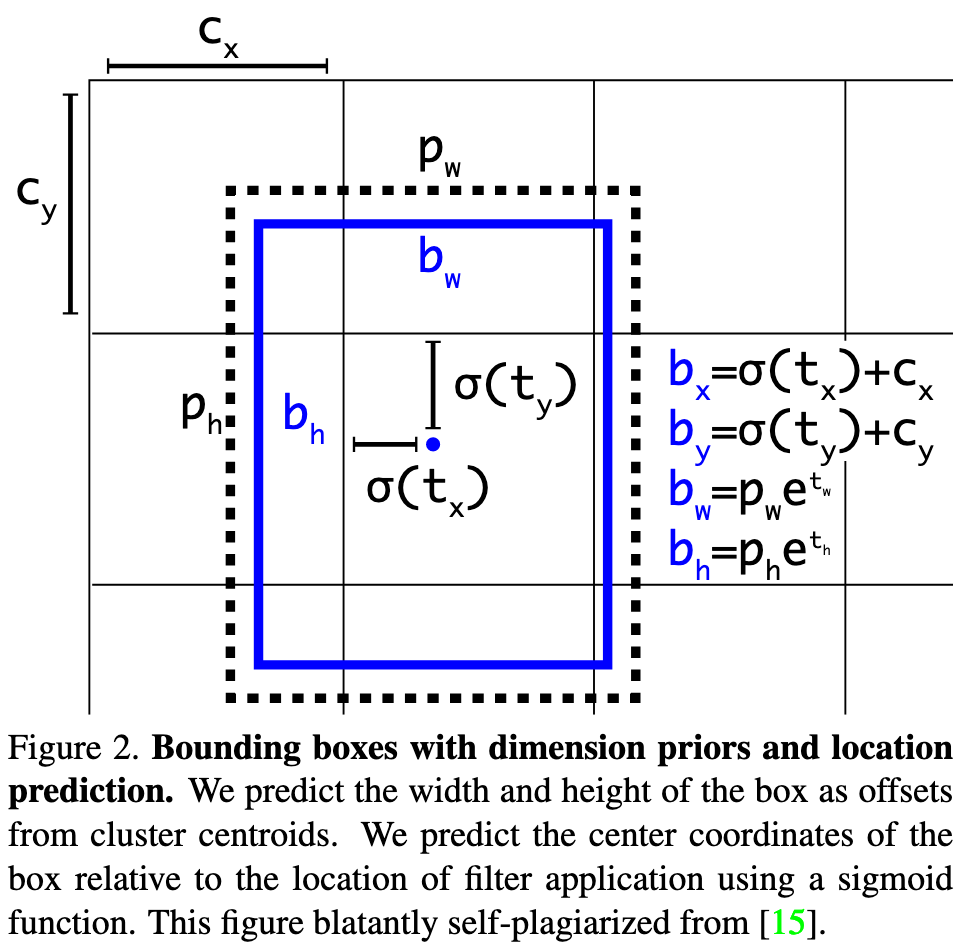
저자의 이전 논문의 모델인 YOLO9000에서 Anchor Box를 이번 모델에도 사용하였습니다.
Anchor Box는 , , , 이렇게 총 4개의 좌표를 사용합니다.
그리고 각 셀의 최상단최좌측 좌표인 top left좌표인 (, )와 바운딩 박스의 길이와 높이인 , 를 사용히여 Anchor Box를 표현하자면
위와 같습니다.
는 시그모이드 함수를 뜻합니다.
학습의 손실함수는 SSE(Sum of Squared Error)를 사용하였습니다.
2.2 Class Prediction
이전에는 예측된 각 Bounding Box의 Class Probability를 결정힐 때 Softmax를 사용하여 클래스를 결정하였습니다.
하지만 복잡한 도메인을 갖는 데이터셋의 경우에는 클래스를 단 하나로 정하지 못하는 경우가 있습니다.
계층적 관계의 클래스를 갖는 데이터셋의 경우(ex, Woman & Person) Softmax로 분류하기엔 역부족입니다.
따라서 Binary Cross-Entropy를 사용하여 클래스 확률을 결정합니다.
각 클래스별로 독립적인 확률을 계산합니다.
2.3 Prediction Across Scales
YOLOv3는 3개의 다른 스케일의 박스를 예측합니다.
이 시스템은 FPN(Feature Pyramid Network)에서 feature map을 얻는 방법과 비슷합니다.
모델은 를 출력합니다.
N = 13, 26, 52이고, 4는 바운딩박스의 x, y, w, h좌표를 뜻하고, 1은 objetness prediction, 80은 클래스 확률을 뜻합니다.
피쳐맵을 2배 업샘플링하여 이전 신경망의 피쳐맵과 결합합니다.
이 방법은 업샘플링한 feature map로부터 semantic한 정보와 이전 feature map으로부터 fine-grained한 정보를 얻을 수 있게 합니다.
2.4 Feature Extractor
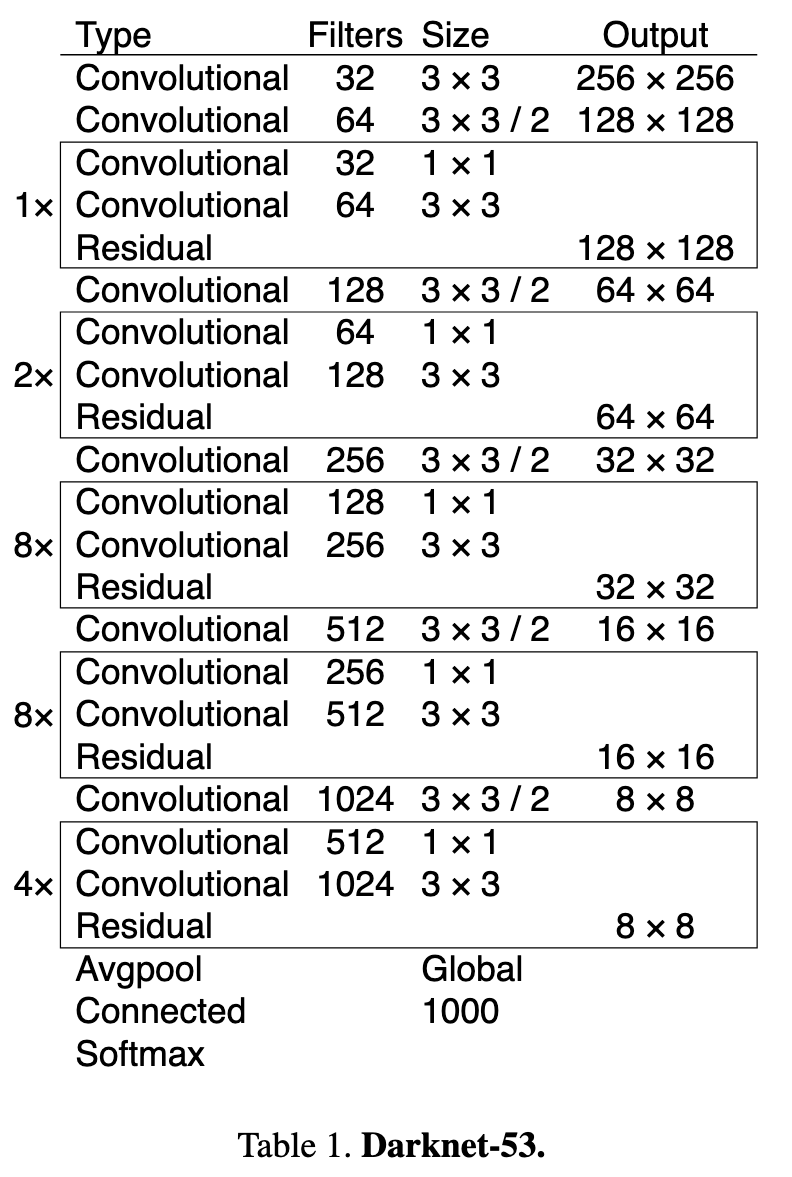
저자는 feature extractor를 새롭게 고안하였습니다.
이전 논문에서 Darknet-19를 사용하였는데, 이 모델에서 비롯하여 Darknet-53을 사용하였습니다.
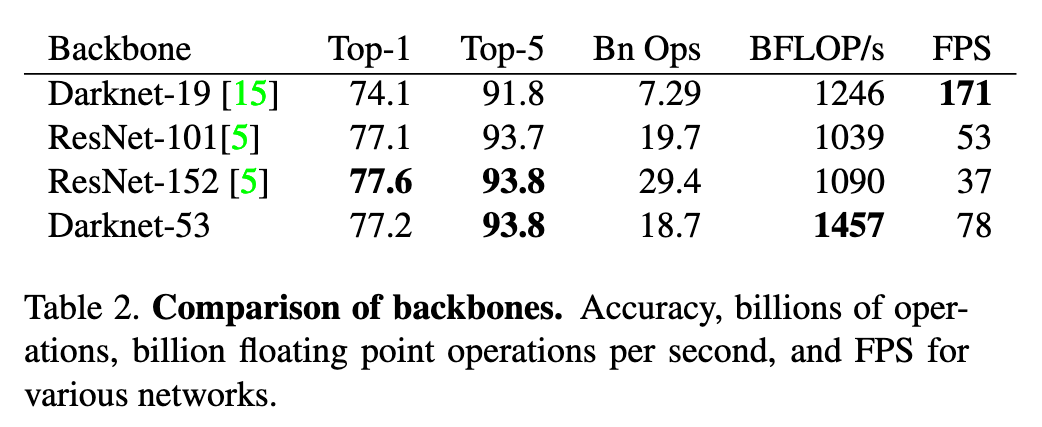
Darknet-53은 ResNet-101보다 1.5배 빠르고, ResNet-152보다 2배 빠릅니다.
하지만 ResNet보다 층 수가 더 줄어들었습니다.
2.5 Training
저자는 multi-scale training, 다량의 데이터 증강, 배치 정규화 등 다양한 방법으로 training과 testing을 사용하여 학습하였습니다.
3. How We Do
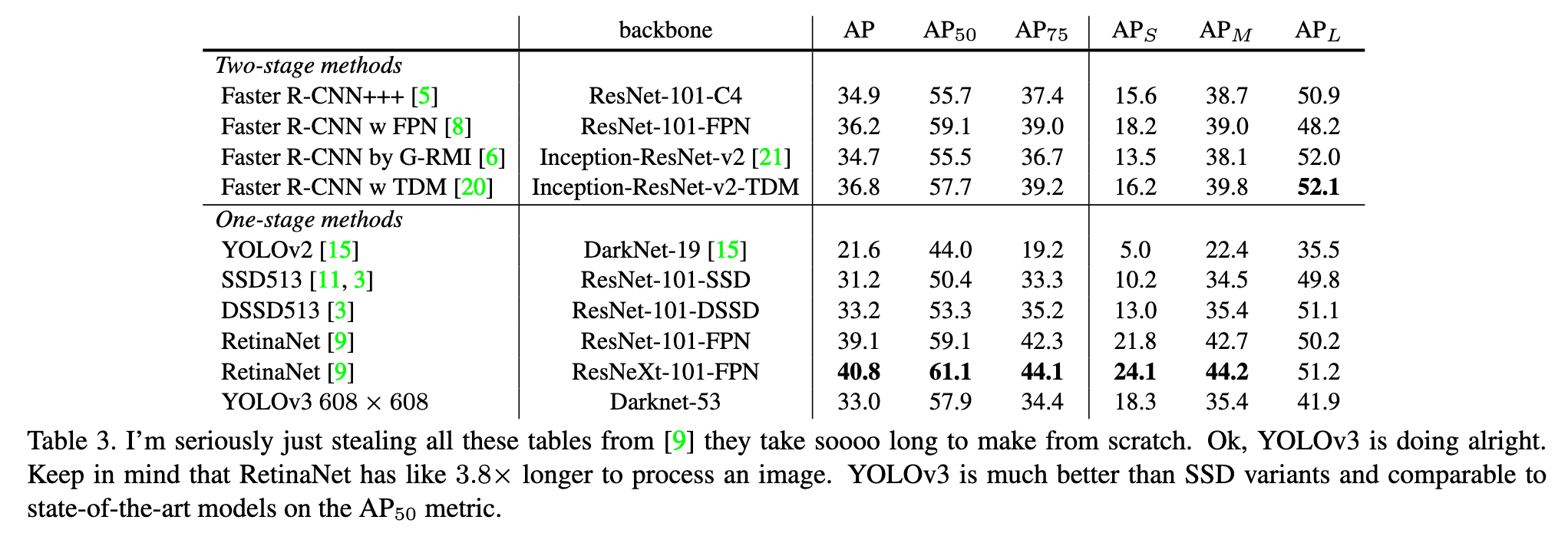
여러 모델들과 각 종 평가 지표를 비교하면서 YOLOv3의 Darknet-53이 좋은 결과를 도출하였다는 것을 보여줍니다.
4. Things We Tried That Didn't Work
-
Anchor box , offset predictions
sigmoid함수 대신 linear activation을 사용하여 바운딩 박스의 , 의 좌표를 구하면 모델의 stability를 감소시켰다고 합니다. -
Linear , predictions instead of logisitic
logistic activation 대신 , 의 좌표를 직접 구하려 했으나 mAP를 감소시켰다고 합니다. -
Focal loss
focal loss를 구하려 했을 때도 mAP가 감소하였다고 합니다. -
Dual IoU thresholds and truth assignment
Faster R-CNN은 학습 중에 IoU threshold를 2개 사용하였습니다.
예를 들어 IoU >= 0.7이면 positive이고 0.3 < IoU < 0.7 이면 무시하고, IoU <= 0.3이면 negative로 표시합니다.
이 방법은 좋은 결과를 도출할 수 없었다고 합니다.
5. What This All Means
저자는 이 논문을 마지막으로 연구를 중단하겠다고 합니다.
저자가 상상하지 못했던 군사목적으로 자신의 기술을 사용하는 것을 보고, 연구를 중단해야겠다고 생각이 들었다고 합니다.🥲
