
📝 이번 포스트는 "YOLO9000: Better, Faster, Stronger"논문에 대해 알아보도록 하겠습니다.
Abstract
일단 모델 이름이 YOLO9000인 이유는 9000개의 클래스를 탐지할 수 있는 SOTA이기 때문에 이름을 YOLO9000이 되었습니다.
YOLOv2모델은 다양한 사이즈의 이미지를 학습할 수 있다고 합니다.
YOLOv2는 67FPS에서 76.8mAP를, 40FPS에서 78.6mAP를 VOC 2007 데이터셋을 사용했을 때 이러한 성능을 보여준다고 합니다.
ResNet과 SSD모델을 사용하는 Faster R-CNN 모델보다 뛰어난 동시에 엄청난 속도를 보여준다고 합니다.
1. Introduction
저자는 많은 classification 데이터를 활용하여 현재 detection의 범위를 확장하는 새로운 방법을 고안했습니다.
객체 classification의 hierarchical view를 활용하여 서로 다른 데이터셋을 결합할 수 있게 했습니다.
저자의 방법론은 detection image를 학습하여 정교허게 객체를 localize하고, classification 이미지를 이용하여 vocabulary와 robustness를 증가시킵니다.
2. Better
YOLO의 error를 Fast R-CNN와 비교하여 분석해보았을 때, YOLO는 localization error가 상당히 많은 편입니다.
게다가 YOLO는 region proposal 기반 모델들보다 상대적으로 낮은 recall을 갖습니다.
따라서 저자는 classification accuracy를 유지함과 동시에 recall과 localization을 향상시키는 것에 초점을 맞췄습니다.
최근 트렌드가 모델이 커지고, 깊어지는 경향이 있는데, 좋은 성능은 더 큰 네트워크를 학습하거나, 여러 모델을 하나로 앙상블하는 것에 달려있다.
저자는 모델을 깊게 변형하지 않고 단순화하여 representation을 더 쉽게 학습할 수 있도록 하였다.
이전 연구 자료들에서부터 얻은 아래 개념들이 YOLO의 성능을 향상시킨 주요 개념들이다.
Batch Normalization
Batch Normalization을 YOLO 속 모든 Convolution layer들에 연산을 추가함으로써 mAP가 2% 향상된 결과를 도출했습니다.
또한 Batch Normalization을 사용하면 overfitting 없이 모델에서 dropout을 제거할 수 있습니다.
High Resolution Classifier
당시 모든 SOTA 방법론들은 ImageNet에서 pre-trained된 classifier를 사용하였습니다.
YOLO는 224X224 사이즈의 이미지들을 학습하고 detection 때에는 448X448로 증가합니다.
YOLOv2는 ImageNet 데이터셋으로 10 epoch을 448X448 해상도로 Classification network을 파인튜닝합니다.
이는 모델에 필터들이 높은 해상도의 입력에 대해서 잘 탐지할 수 있도록 조정할 시간을 줍니다.
그 다음 detection시 fine tuning을 합니다.
Convolutional With Anchor Boxes
저자는 fully-connected layer를 제거하고 anchor box라는 개념을 도입했습니다.
먼저 신경망의 convolutional layer의 output을 높은 해상도로 만들기 위해 pooling layer 하나를 제거합니다.
그리고 신경망의 입력 이미지를 448X448 에서 416X416으로 줄였습니다.
왜냐하면 홀수개의 피쳐맵을 갖기 위해서 했고 따라서 가운데에는 한개의 셀이 존재하게 됩니다.
객체는 이미지의 중심을 차지하려는 경향이 있어서 하나의 셀이 가운데에 위치하는 것이 4개의 셀이 중심에 위치하는 것보다 객체를 탐지하는 데 좋습니다.
YOLO의 합성곱 신경망은 32의 배수로 다운샘플링하기 때문에 입력이미지를 416으로 갖음으로써 output feature map을 13X13으로 갖을 수 있다.
그리고 모든 anchox에 대해서 class와 bounding box를 예측합니다.
YOLO의 경우는 이미지 당 98개 박스를 예측하지만 앵커박스는 이미지 당 1000개 이상의 박스를 탐지합니다.
Dimension Clusters
YOLO를 anchor box와 사용하면 2가지 문제점이 있습니다.
첫 번째, box의 dimension이 미리 결정한다는 것입니다.
일반적으로 k-mean clustering은 Euclidean distance를 centroid들을 통해 구하지만 저자는 IoU를 통해서 k-mean clustering을 하였습니다.
왜냐하면 Euclidean distance의 경우는 centroid가 완전히 똑같지만 박스의 크기 차이가 커도 Euclidean distance는 0을 가리킬 것이므로 예측했다고 하겠지만 틀린 예측이겠죠.
따라서 centroid(무게중심)으로 구하는 방법말고 두 박스 사이의 넓이를 통해 구하는 IoU를 사용하였습니다.
(box, centroid) = 1 - (box, centroid)
Direct location prediction
두 번쨰 문제로는 모델의 초기 iteration에서 나타나는 불안정성입니다.
위 공식은 RPN에서의 예측한 박스의 위치 구하는 공식인데 문제점은 제약이 없어서 앵커박스가 이미지의 아무 곳이나 위치할 수 있다는 점입니다.
그래서 YOLO는 offset을 예측하지 않고 grid cell의 위치를 기반으로 좌표를 예측합니다.
용어 정리
& : grid cell의 top left 좌표
: sigmoid함수
& : 사전 정의된 width와 height
& & & : 모델이 예측한 좌표
의 방식으로 각 그리드셀을 기준으로 앵커박스들의 위치 좌표를 구합니다.x
Fine-Grained Features
이 YOLO는 13X13 피쳐맵으로 예측합니다.
이 피쳐맵은 큰 객체에는 충분할 수 있지만 작은 물체에는 미세한 피쳐맵이 필요할 것입니다.
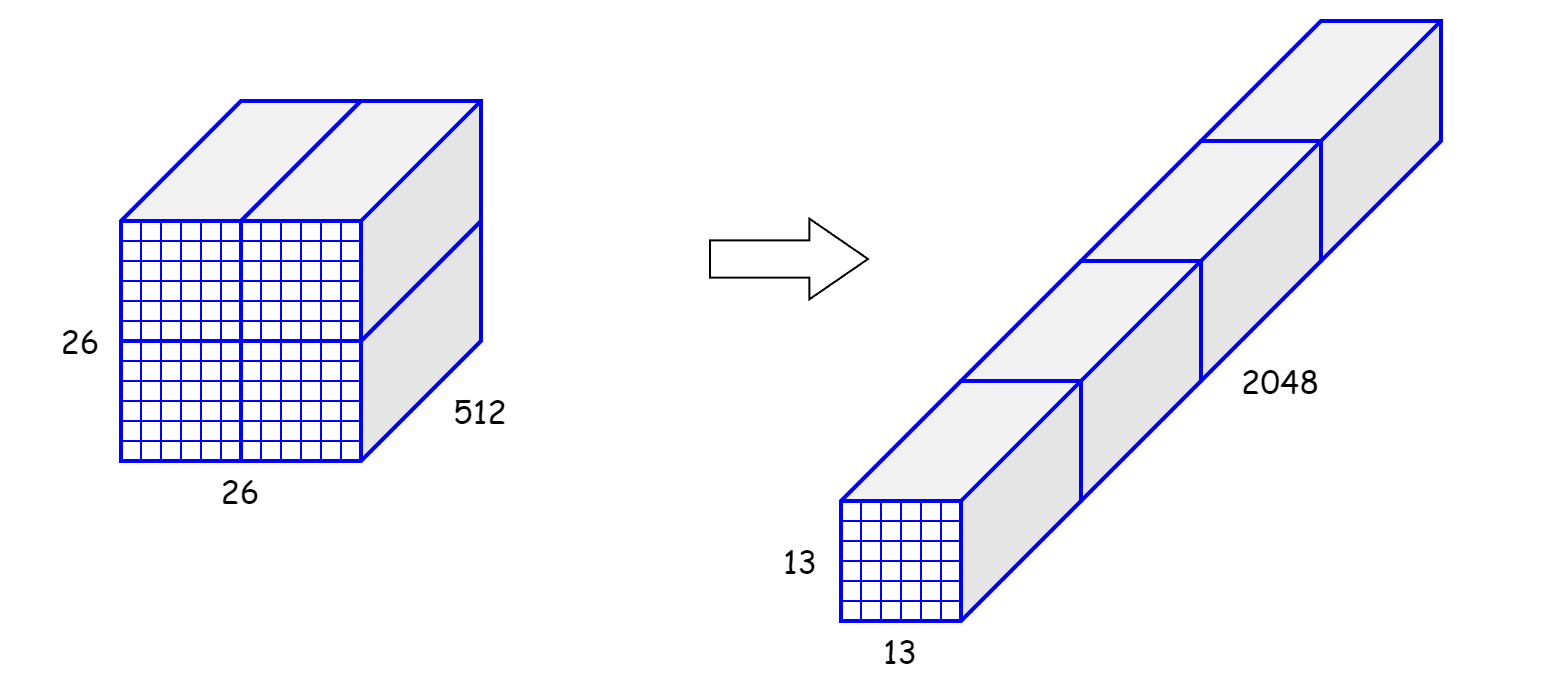
이러한 어려움 때문에 저자는 passthrough layer를 추가하여 이전 layer에서 26X26 해상도의 피쳐맵을 갖고오는 기능을 갖습니다.
feature map을 channel은 유지하면서 4개로 분할한 후 concat하여 13X13X2048크기의 feature 맵으로 바꿉니다.
이러한 feature map은 작은 객체에 대한 정보를 함축합니다.
Multi-Scale Training
저자는 다양한 사이즈의 입력 이미지를 사용하고 싶었습니다. 그렇게 한다면 모델이 robust할 것이라고 생각하였습니다.
따라서 이미지의 입력사이즈를 고정시키는 것보다는 매 10 batch마다 입력 이미지 크기를 32의 배수인 {320, 352, ..., 608} 중에서 골라 설정합니다.
이렇게 하면 신경망이 다양한 입력의 이미지를 학습하므로서 robust해질 수 있습니다.
이 Multi-Scale Training 시에는 anchor box와 같이 사용하지 못하는 것 같다. 만약 32의 짝수 배의 입력이미지 크기를 갖는다면 anchorbox는 중앙에 홀수개의 grid cell을 갖을 수 없기 때문이다.
3. Faster
이전 다른 모델들은 detection framework로 VGG-16을 사용하였다.
VGG-16은 강력하고 정확한 classification network지만 불필요하게 복잡하다. 224X224 이미지 한 개를 처리하는데 30.69B 개의 floating point를 갖는다.
YOLOv1은 GoogLeNet을 사용했는데 속도는 빠른 반면 accuracy가 VGG-16보다 낮았다.
Darknet-19
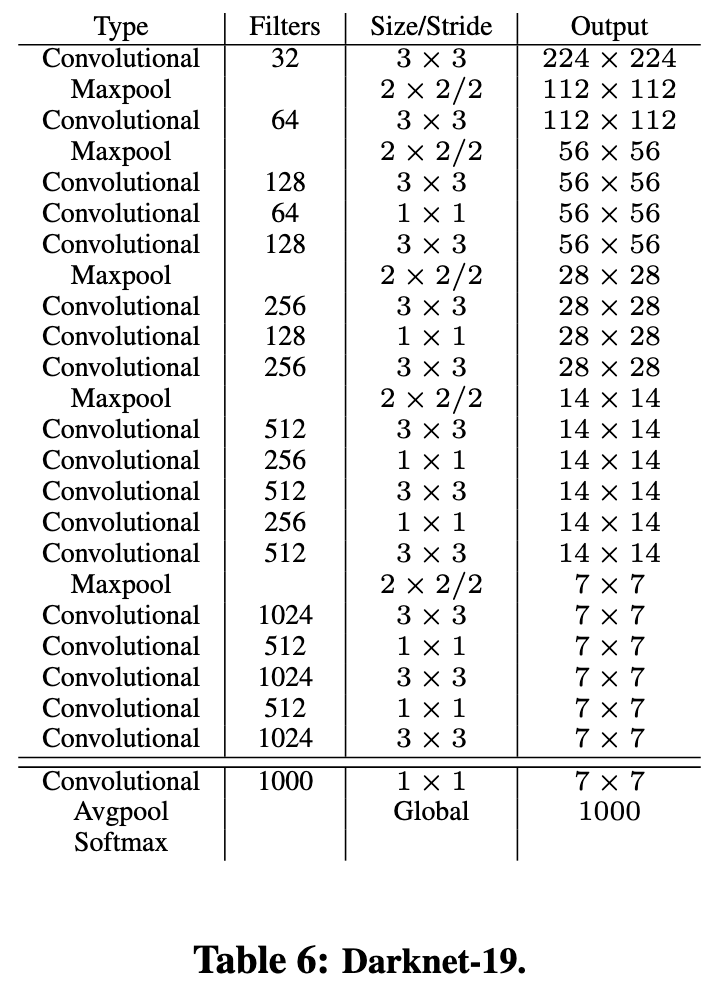
그래서 고안한 것이 Darknet-19 아키텍쳐다.
VGG 모델과 유사하게 3X3 필터를 사용합니다.
그리고 global average pooling을 사용하여 FC layer를 제거하였습니다.
Darknet-19는 19개의 Convolutional layer와 5개의 max pooling layer로 구성되었습니다.
Training for classification
Darknet을 ImageNet 1000개 클래스에서 classification 학습하였습니다.
학습 할 때 random crop, rotation, hue, saturation, exposure를 변화주는 데이터 증강 기법을 사용하였습니다.
그리고 초기 10 epoch에는 learning rate를 으로 하고 이 후에는 으로 하였습니다.
Training for detection
저자는 Darknet-19를 수정하여 detection 하는데에도 학습하였습니다.
저자는 마지막 convolutional layer를 제거하고 대신 각각 1024개의 필터가 포함된 3개의 3×3 convolutional layer를 추가한 다음 detection에 필요한 출력 수를 포함하는 1×1 convolutional layer를 추가하였습니다.
VOC에서 5개의 박스에 5개(의 prediction 결과와 20개의 class에 대한 prediction을 포함하여 5X(5+20)개를 예측한다.
또한 passthrough layer를 추가하여 미세한 특징들을 탐지하도록 하였다.
detection 시에는 random crop, color shifting 등의 데이터 증강 기법을 사용하였다.
4. Stronger
이 부분은 YOLO9000에 해당하는 부분입니다.
저자는 classification 데이터셋과 detection 데이터셋을 합쳐서 모델을 학습하는 방법을 고안했습니다.
신경망이 detection 데이터셋을 학습할 차례가 되면 YOLOv2 손실함수를 구하고, 신경망이 classification 데이터셋을 학습할 차례가 되면 아키텍쳐의 classification 특정 부분에서만 손실 함수를 구합니다.
하지만 이 joint training에는 몇 가지 문제가 있습니다.
detection 데이터셋은 몇 개 안되는 일반적인 클래스들만 있는 반면에 classification 데이터셋에는 깊고 넓은 범위의 클래스를 갖는다는 점입니다.
다시 말해서, 클래스 범위의 불일치를 말합니다.
이것을 해결하기 위해 WordTree 아이디어를 만들어냅니다.
WordNet이란?
자연어 처리(NLP)의 데이터셋으로, 주로 영어 단어의 의미와 그들 간의 관계를 탐색하고 연구하기 위해 개발된 대규모 데이터베이스(DB)
- WordNet은 각 단어를 개별적으로 다루기보다는 동의어 집합(synsets)으로 묶어 의미를 표현합니다. 예를 들어, "자동차"라는 개념을 표현할 때, "car", "automobile"과 같은 단어들이 동일한 동의어 집합에 포함됩니다.
WordTree는 WordNet의 directed graph 구조에서 생각해낸 Hierarchical graph구조로 클래스를 분류한 structure입니다.
계층적인 그래프 구조를 만들되 최대한 얕게 만듭니다.
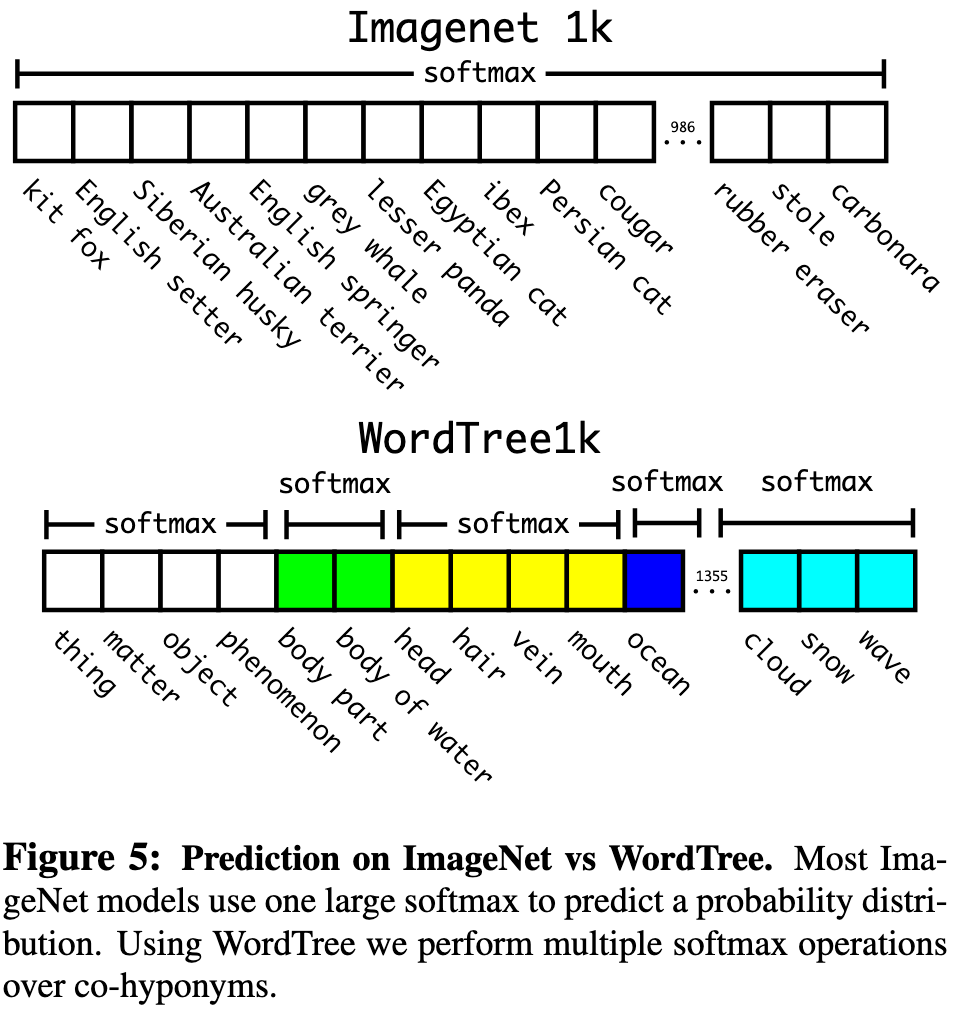
Figure 5를 보면 클래스 확률을 어떻게 구하는지 이해하실 수 있습니다.
ImageNet은 flat한 directed graph구조였는데 변경하여 hierarchical graph구조인 WordTree로 변경하였습니다.
이렇게 하면 하위 레이블별로 softmax를 구하게 됩니다.
위와 같이 terrier 클래스 아래에 Norfolk, Yorkshire, Bedlington이 있다면 이 3개로만 softmax를 구합니다.
만약 absolute probability를 구하고 싶다면
와 같이 Norfolk terrer에서부터 root node까지의 모든 확률을 다 곱해서 구하면 된다.
Dataset combination with WordTree
WordTree구조를 이용하여 ImageNet과 COCO 데이터셋을 결합하였습니다.
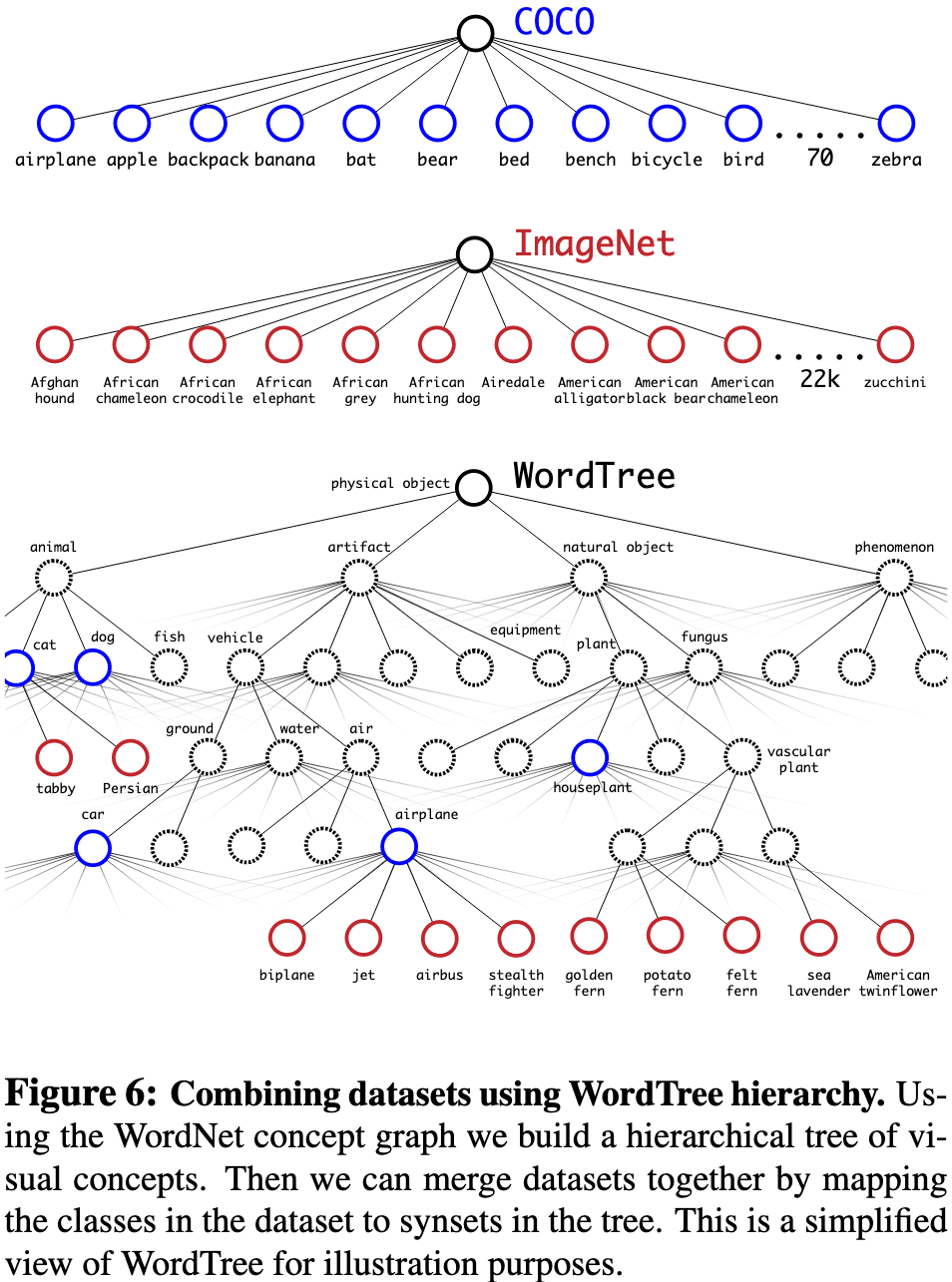
Joint classification and detection
COCO데이터셋과 9000개의 클래스를 갖는 ImageNet release에 ImageNet detection callenge를 추가하여 WordTree를 구성하였습니다. 그 클래스 수는 9418개이고, ImageNet의 클래스 수가 더많기 때문에 COCO : ImageNet 의 비율을 4:1로 하였습니다.
이것은 detection 작업을 위해서 COCO의 비율을 증가시킨 것입니다.
그리고 실험을 진행하였습니다.
실험 결과는 따로 설명하지 않겠습니다.
5. Conclusion
이 논문에서는 YOLOv2와 YOLO9000 두 가지 모델을 소개했습니다.
YOLOv2는 better와 faster한 모델을 뜻하고, YOLO9000은 stronger한 모델을 뜻합니다.
이 논문을 통해 YOLOv2의 anchor box를 파악하고, WordTree의 동작원리를 파악하면 좋을 것 같다.
