[논문리뷰] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Machine Learning

📝 이번 포스트는 ViT로 널리 알려져있는 "An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale" 논문에 대해 알아보도록 하겠습니다.
2. RELATED WORK
이 논문은 NLP(Natural Language Processing) 분야의 트랜스포머 기반 모델에서 영감을 받아 CV(Computer Vision) 분야에 적용한 모델을 다루는 논문입니다.
self-attention을 이미지에 적용하면 각 픽셀이 다른 모든 픽셀에 attention해야 하므로 픽셀 수의 제곱에 비례하는 연산 비용이 발생할 것입니다.
이전에도 트랜스포머를 이미지 처리 분야에 적용시키려 했었던 연구들이 있었습니다.
이전 연구들은 ImageNet 데이터셋으로 실험을 하였지만, 이 논문은 ImageNet-21k 와 JFT-300M 같은 large scale 데이터셋에서 트랜스포머를 훈련시켰습니다.
3. METHOD
저자는 NLP 분야의 첫 트랜스포머 모델의 Attention Is All You Need와 매우 유사하게 모델링하였습니다.
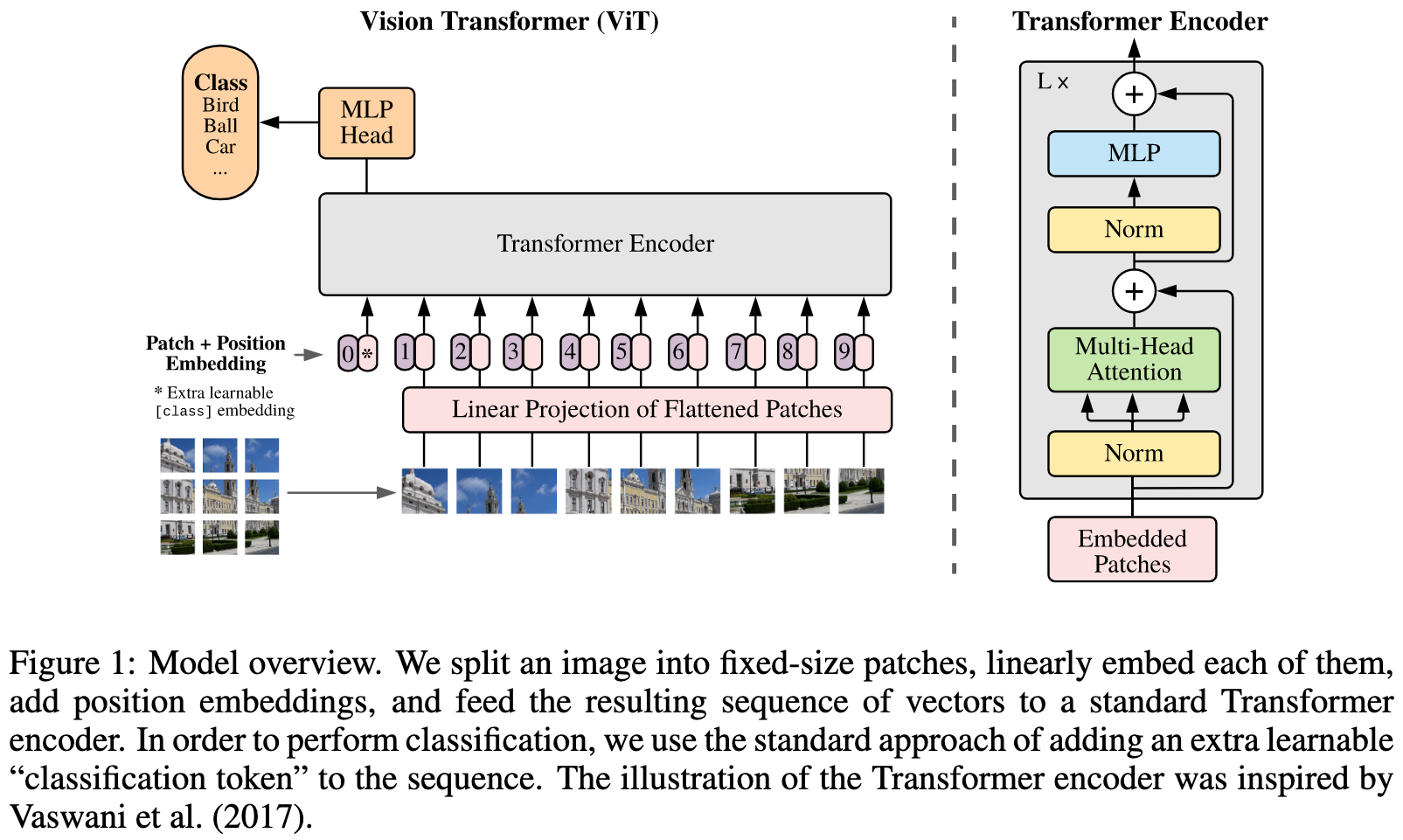
3.1. VISION TRANSFORTMER
ViT는 3D 이미지를 2차원의 flatten된 2D 패치의 sequence로 재구성합니다.
N은 패치의 수를 뜻하며, 트랜스포머의 유효 입력 시퀀스 길이를 뜻하기도 합니다.
트랜스포머는 모든 레이어에서 상수 latent 벡터 사이즈 D를 사용하기 때문에, 식(1)을 보면 패치를 평탄화하고 학습 가능한 선형 projection을 통해 D차원으로 매핑합니다.
이 projection의 출력을 패치 임베딩이라고 합니다.
용어정리
: 이미지의 높이
: 이미지의 너비
: 이미지의 채널 수
: 패치의 수,
: 패치의 한 변의 길이
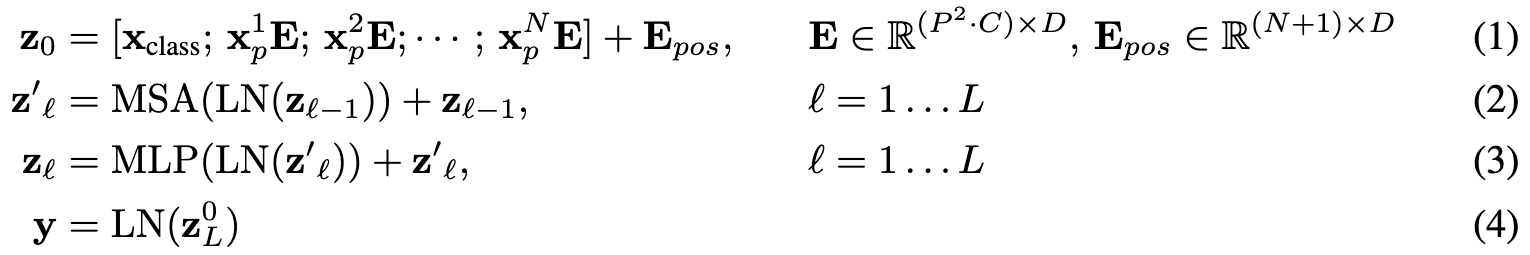
학습 가능한 임베딩()을 임베딩된 패치 시퀀스의 맨 앞에 추가하고, 트랜스포머 인코더의 출력에 이 임베딩의 state ()는 이미지 represetation (y)에 사용됩니다.(Eq (4))
pre-training과 fine-tuning 동안에 classification 헤드가 에 연결됩니다.
pre-training 시 classification 헤드는 하나의 hidden layer가 있는 MLP로 구현되고 fine-tuning 시에는 single linear layer로 구현됩니다.
patch 임베딩에 position 임베딩을 추가하여 위치 정보를 유지합니다.
그리고 학습 가능한 1D 임베딩을 사용하였습니다.
임베딩 벡터의 시퀀스 결과는 인코더의 입력으로 사용됩니다.
MSA(Multihead Self-Attention)
qkv self-attention(Attention is all you need)은 신경망 아키텍쳐에서 널리 사용되는 방법입니다.
입력 시퀀스 의 각 element에 대해 시퀀스 내 모든 값 v의 가중 합을 계산합니다.
attention weight 는 시퀀스 내 두 element , 사이의 similarity와 이들 query 와 key representation을 바탕으로 결정됩니다.NLP의 self-attention의 공식은 아래와 같습니다.
논문의 Multihead Self-Attention(MSA)는 Self-Attention(SA)의 확장버전으로 헤드 수 개의 Self-Attention을 병렬로 실행합니다.
그리고 그 output을 concatenate하면 MSA의 결과가 됩니다.
MSA 식은 아래와 같습니다.
트랜스포머 인코더는 Multihead Self-Attention(MSA)와 MLP 블록들을 교대로 레이어를 쌓은 형태가 됩니다.
Layer Norm(LN)은 각 블록의 앞에 적용되고, residual connection은 각 블록의 뒤에 적용됩니다.
참고로 MLP는 GELU를 사용한 2개의 layer로 구성되었습니다.
GELU(Gaussian Error Linear Unit)란?
GELU는 dropout, zoneout, ReLU 함수들의 특성을 조합한 함수입니다.
: 표준 정규분포의 CDF(Cumulative Distribution Function)을 뜻함.
특징
1. 입력값의 크기에 따라 활성화 확률이 다르다. 양수 값은 값을 유지할 수 있지만, 음수는 0에 유사한 값을 갖게 된다.
2. ReLU와 달리 부드러운 곡선을 갖는다. 왜냐하면 가 sigmoid와 비슷한 형태이기 때문에 부드러운 비선형 활성화 함수가 된다.
Inductive Bias
Inductive Bias란?
보지 못한 데이터에 대해서도 귀납적 추론이 가능하도록 하는 알고리즘이 가지고 있는 가정의 집합.
일반적으로 모델이 갖는 일반화의 오류는 불안정하다는 것(Brittle)과 겉으로만 그럴싸 해 보이는 것(Spurious)이 있다.
모델이 주어진 데이터에 대해서 잘 일반화한 것인지, 혹은 주어진 데이터에만 잘 맞게 된 것인지 모르기 때문에 발생하는 문제다.
ViT에는 CNN에 비해 이미지에 대한 귀납적 편향이 적습니다.
CNN에서는 locality, two-dimensional neighborhood 구조, translation equivariance가 모델 전체의 모든 레이어에 내재되어 있습니다.
그러나 ViT에서는 MLP 레이어만이 locality와 transaltion equivariance를 가지며, two-dimensional neighborhood 구조는 아주 조금만 사용됩니다. 모델의 시작 시 이미지 패치를 나눌 때와 다른 해상도의 이미지를 위해서 position 임베딩을 조정하는 fine-tuning 시에만 제한적으로 사용됩니다.
initialization할 때 position 임베딩은 어떠한 패치의 2D position 정보를 갖지 않고 모든 패치 사이의 spatial relation은 처음부터 학습해야 합니다.
Hybrid Architecture
원본 이미지 패치 대신에 입력 시퀀스는 CNN의 피쳐맵으로 구성할 수 있습니다.
패치 임베딩 projection은 CNN 피처 맵에서 추출한 패치에 적용됩니다.
패치를 1x1 크기로 설정하여도 됩니다.
입력 시퀀스는 피처맵의 spatial dimension을 flatten하고 Transformer dimension을 project하여 얻을 수 있습니다.
3.2. FINE-TUNING AND HIGHER RESOLUTION
저자는 ViT를 large dataset으로 pre-train한 후 비교적 작은 downstream task에 fine-tuning하여 사용했다고 합니다.
downstream할 때는 pre-train된 prediction head를 제거하고 zero-initialized feedforward 레이어를 연결했습니다.
높은 해상도의 이미지를 입력할 때, 패치의 크기는 동일하게 유지합니다. 패치크기를 동일하게 하면 시퀀스의 길이가 커지게 됩니다.
ViT는 메모리 제약 내에서 임의의 시퀀스 길이를 처리할 수 있지만, pre-train된 position 임베딩이 더 이상 의미가 없을 수 있습니다.
왜냐하면 패치의 크기가 5x5로 pre-train했는데 9x9 패치로 downstream한다면 크기가 않맞게 되어 활용할 수 없게 되는 것입니다.
따라서 원본 이미지의 위치에 따라 pre-train된 position 임베딩을 2D interpolation(보간법)합니다.
이 downstream task와 patch 추출이 ViT에 이미지의 2D 구조에 대한 inductive bias를 수동으로 주입하는 유일한 것입니다.
