
📝 이번 포스트는 DenseNet으로 알려진 "Densely Connected Convolutional Networks" 논문에 대해 알아보도록 하겠습니다.
1. Why : 논문의 연구 배경
CNN은 근래에 들어 Object Recognition에서 우월한 성능을 보이며 LeNet-5(5개 레이어)를 시작으로 VGGNet(19개 레이어), 그리고 Highway Network 및 ResNet(100개 이상의 레이어)와 같은 깊은 네트워크로 발전하고 있습니다.
그러나 네트워크가 깊어질수록 입력 정보나 기울기가 점점 소실되는 문제가 발생합니다.
이를 해결하기 위해 이전 모델인 ResNet은 레이어 간의 identity mapping을 통해 벡터를 더 깊은 층으로 전달하게 합니다.
DenseNet은 이러한 접근법을 단순화하면서도 레이어 간의 효과적인 연결을 제공하는 구조를 연구한 모델입니다.
2. How : 연구 방법론
방법론을 설명하기에 앞서 용어설명부터 짚고 넘어가겠습니다.
: 입력 이미지
: 네트워크의 레이어 수
: 레이어의 인덱스
: 비선형 변환(non-linear transformation)
: 번째 층의 출력
2.1. ResNets
전통적인 합성곱의 feed-forward는 으로 표현할 수 있습니다.
반면 ResNet의 skip connection을 고려한 idenity mapping은
로 표현할 수 있습니다.
ResNet의 장점은 -1번째 층의 출력을 번째 출력으로 직접 전달할 수 있다는 점입니다.
저자는 이러한 skip connection을 DenseNet에 활용하였습니다.
2.2. Dense connectivity
저자는 레이어 간의 정보 흐름을 극대화하기 위해 ResNet과 다른 연결 패턴을 고안하였습니다.
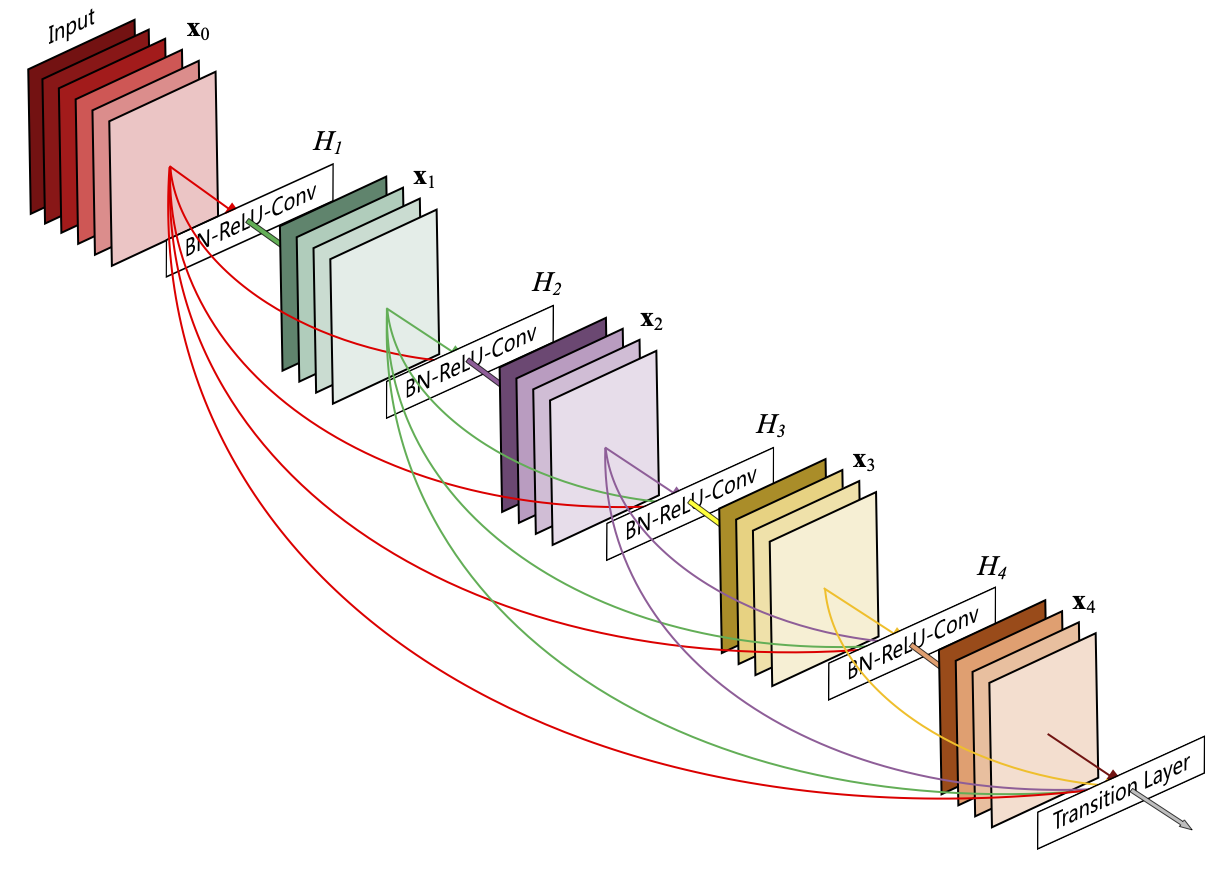
위 그림과 같이, 저자는 각 층이 모든 이전 층의 출력을 입력으로 받는 Dense connectivity를 고안하였습니다.
즉, 번째 층은 으로 표현되는 모든 이전층의 피쳐맵을 입력으로 사용합니다.
식으로는 위와 같이 표현할 수 있습니다.
위 식의 는 한 Dense 블록 내의 이전 층들에서 생성된 피쳐맵들의 concatenation을 뜻합니다.
이 방식은 각 층이 이전 층의 출력뿐만 아니라 한 블록 안의 모든 레이어의 출력을 축적하여 이용함을 뜻합니다.
2.3. Composite function
비선형 변환 은 배치 정규화(BN)과 ReLU와 3x3 합성곱 순으로 3개의 연속적인 연산으로 구현하였습니다.
2.4. Pooling layers

위 단락에서 사용한 식에서 사용하는 concatenation 연산을 수행하기 위해서는 피쳐맵의 크기를 맞춰줘야합니다.
저자는 피쳐맵의 크기가 맞지 않는 문제를 해결하기 위해서 down sampling을 이용하기로 하였습니다.
이를 구현하기 위해 DenseNet은 여러 Dense Block으로 나누고 각 Dense Block 사이에 transition layer를 배치하면 됩니다.
transition layer는 배치 정규화와 1x1 Conv와 2x2 average pooling으로 순차적으로 구성된 레이어입니다.
배치 정규화는 피쳐맵의 분포를 정규화하여 학습의 안정성을 증가시키는 역할을 하는 것으로 유명하죠.
1x1 합성곱은 주로 피쳐맵의 채널 수를 줄이는 역할을 하며 연산량을 줄이는 것으로 유명하고요.
2x2 Average pooling은 피쳐맵의 크기를 줄이면서 피쳐를 요약하는 역할을 합니다.
이 transition layer를 Dense 블록들 사이에 구현함으로서 신경망을 더 깊이 구현할 수 있게 해주었습니다.
2.5. Growth rate
저자는 growth rate라는 파라미터 k를 사용합니다.
는 신경망의 각 레이어가 출력으로 생성하는 새로운 피쳐맵의 개수를 뜻합니다.
번째 레이어의 출력을 로 표현할 수 있죠, 은 입력층의 초기 채널 수입니다.
다른 신경망 아키텍쳐들과 차별되는 DenseNet의 장점은 성장률(출력 채널 수)이 작아도 높은 성능을 보일 수 있다는 점이다.
2.6. Bottleneck layers
DenseNet은 각 레이어가 개의 출력 피쳐맵을 생성하지만, 입력 피쳐맵의 수는 네트워크가 깊어지면 깊어질수록 점진적으로 증가할 수 밖에 없습니다.
이로 인해 계산 비용이 증가하는 문제점을 피할 수 없게 됩니다.
따라서 저자는 1 1 합성곱을 3 3 합성곱 앞에 배치하여 입력 피쳐맵의 수를 줄이는 방법을 고안하였습니다.
저자는 실험에서 1 1 합성곱이 4k개의 피쳐맵으로 줄이도록 하였습니다.
저자는 추가적으로 파생된 아키텍쳐 DenseNet-B를 소개합니다.
DenseNet-B는 Conv(1 1)-Conv(3 3) 대신 BN-ReLU-Conv(1 1)-BN-ReLU-Conv(3 3)으로 구성된 아키텍쳐이며 bottleneck 레이어를 포함한 파생된 아키텍쳐입니다.
추후 DenseNet과 비교하는 실험에서 사용합니다.
2.7. Compression
저자는 모델의 컴팩트함을 향상시키기 위해 transition layer에서 출력 피쳐맵의 수를 줄이는 compression을 구현하였습니다.
어떠한 Dense 블록이 m개의 피쳐맵을 생성했다고 가정하자, 해당 블록 뒤에 위치한 transition layer m개의 피쳐맵만 출력하도록 설정합니다.
여기서 \theta는 compression 계수로 0 < 1의 값을 가질 수 있습니다.
계수가 1인 경우 transition layer의 출력 피쳐맵의 수는 변하지 않으며 기본 DenseNet과 동일한 구조입니다.
만약 < 1이면 출력 피쳐맵의 수가 감소하여 네트워크의 크기를 줄일 수 있습니다.
이러한 방식으로 계산 비용과 메모리 사용량을 줄일 수 있습니다.
이렇게 Compression으로 파생된 아키텍쳐를 DenseNet-C라고 부릅니다.
저자는 = 0.5로 사용하여 실험하였습니다.
또한 bottleneck layer와 compression을 함께 사용한 DenseNet인 DenseNet-BC를 소개합니다.
2.8. Implementation Details
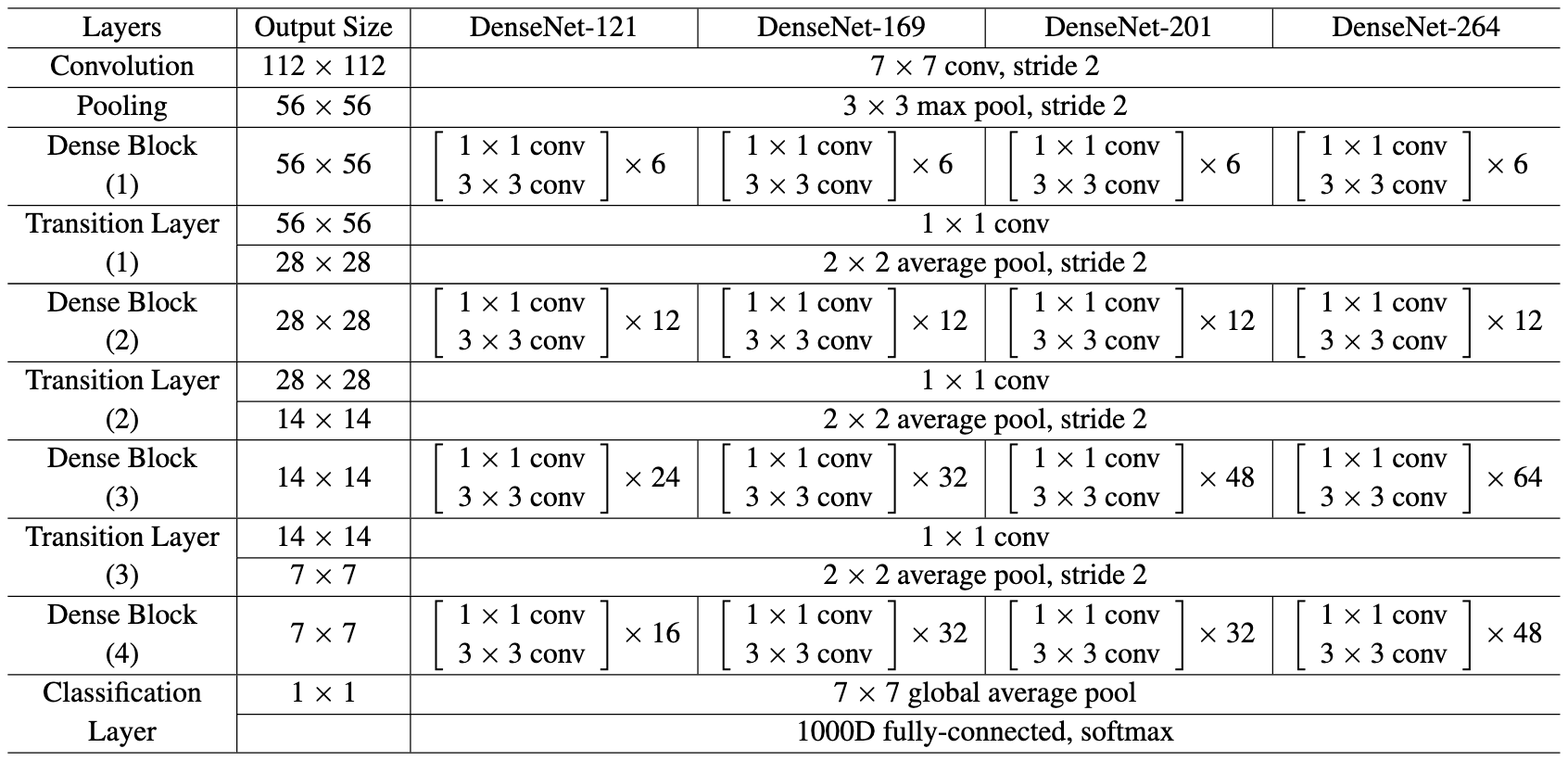
저자는 ImageNet 데이터셋을 제외한 모든 데이터셋에 대해서는 Dense 블록을 3개로 구성하였습니다.
입력이미지에 대해 16개의 출력을 갖는 합성곱을 수행한 다음 첫 번째 Dense 블록으로 피쳐를 전달합니다.
모든 3 3 Conv는 1픽셀의 제로패딩으로 패딩하여 커볼루션을 수행하여 피쳐맵의 크기를 동일하게 갖을 수 있습니다.
그리고 transition layer은 1 1 conv와 2 2 average pooling으로 구성됩니다.
그리고 각 Dense 블록은 32 32, 16 16, 8 8 크기의 피쳐맵을 갖습니다.
이미지넷 데이터셋의 경우 DenseNet-BC 모델을 사용하였습니다.
224 224 크기의 입력 이미지를 입력받아 첫번째 Conv는 7 7 합성곱 연산에 stride=2로 2의 피쳐맵을 갖도록 합니다.
모든 레이어의 피쳐맵의 개수는 개로 동일하게 하였습니다.
3. Experiments
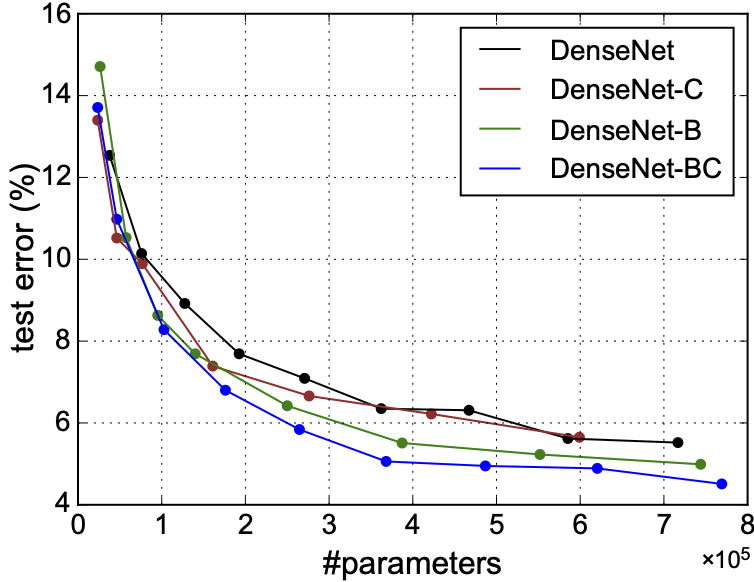
위 그래프는 DenseNet과 파생모델들간의 비교실험의 결과입니다.
실험은 CIFAR10으로 진행하였으며, 파라미터가 증가함에 따라 test error가 어떻게 변화하는지 비교하는 실험입니다.
가장 낮은 test error를 보이는 것은 Compression과 Bottleneck layer를 구현한 DenseNet-BC임을 알 수 있습니다.
위 실험에서 DenseNet-BC가 가장 낮은 test error를 보임을 알 수 있었습니다.
그렇다면 다른 아키텍쳐들과 비교해서는 성능이 어떻게 차이나는지도 봐야합니다.
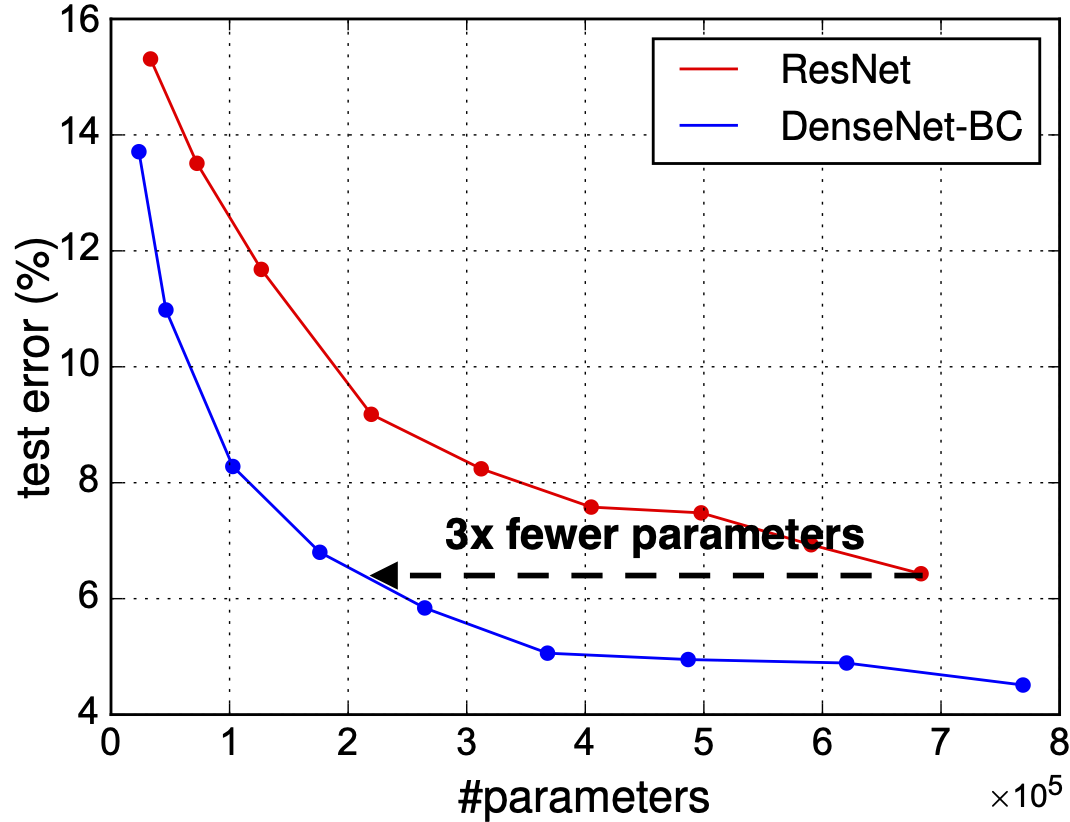
위 그래프는 ResNet과 DenseNet-BC의 비교실험입니다.
ResNet과 비교했을 때 상당히 낮은 test error를 갖음을 볼 수 있습니다.
DenseNet과 비교해서도 ResNet보다 DenseNet이 test error가 낮을 것 같습니다.
4. Conclusion
DenseNet은 동일한 피쳐맵 크기를 갖는 레이어 간에 직접적인 연결을 함으로써 레이어를 깊게 쌓을 수 있음을 가능하게 하였습니다.
이러한 디자인은 네트워크의 피쳐 흐름을 극대화하였습니다.
또한 identity mapping, deep supervision의 특징을 자연스럽게 합쳐, 네트워크 전체에 걸쳐 피쳐 재사용을 가능하게 하였습니다.
