
📝 이번 포스트는 "Network In Network"논문에 대해 알아보도록 하겠습니다.
2. Convolutional Neural Networks
클래식한 CNN은 convolutional layer과 spatial pooling layer(max pooling, average pooling, etc...)을 교차로 쌓아 구성됩니다.
convolutional layer가 선형 합성곱 필터와 뒤에 비선형 활성화 함수를 함께 사용함으로써 피쳐맵을 생성합니다.
선형적인 합성곱은 latent concept의 객체들이 선형적으로 분리되어있을 때 abstraction하기 충분하다.
좋은 abstraction에 달성하는 representation은 입력 데이터의 비선형적이여야 한다.
abstraction이란?
모델이 데이터를 처리하고 학습하면서 점차 고차원적인 Feature를 학습하는 과정을 의미합니다.representation이란?
모델이 데이터를 해석하고 처리하기 위해 학습하는 피쳐를 의미합니다.
전통적인 CNN에서는 latent concepts의 모든 변형을 포괄하기 위해 over-complete?한 필터를 활용함으로써 보상할 수 있습니다.
즉 개별적인 선형 필터는 다양한 같은 개념의 변형을 탐지하도록 학습할 수 있다.
하지만 많은 필터를 갖는 것은 다음 층에 부담이 될 수 있습니다.
그리고 maxout network에 대한 설명도 헙나더. 설명이 아마 max pooling layer와 똑같은게 max pooling layer를 뜻하는 것 같다.
3 Network In Network
3.1 MLP Convolution Layers
latent concept의 분포에 대한 사전 지식이 없는 경우, local patch의 특징 추출에 일반적인 function approximater를 사용하는 것이 바람직하다고 합니다.
latent concept의 abstraction representation에 더 가까워지는 것이 가능하게 하기 때문입니다.
Radial basis network와 multilayer perceptron은 일반적인 function approximator로 잘 알려졌습니다.
저자는 multilayer perceptron을 이 연구에 사용한 두 가지 이유가 있습니다.
- multilayer perceptron은 역전파를 갖는 학습되는 CNN 구조와 호환될 수 있기 때문이다.
- MLP는 그 자체로 일관되게 feature를 재사용할 수 있는 deep model이기 때문이다.
이 논문에서 새로운 layer를 mlpconv라고 한다. 이 것이 GLM를 MLP로 대체할 것이다.
3.2 Global Average Pooling
전통적인 CNN은 네트워크의 하위 layer에서 convolution을 수행합니다.
classification에서 convolution layer의 feature map을 벡터화하여 FC layer에 입력한 후 softmax로 연결됩니다.
이 구조는 convolution 구조와 전통적인 classifier를 연결하는 다리 역할을 합니다.
그러나 FC layer는 overfitting이 발생하기 쉬워 전체 신경망의 일반화 능력을 저해할 수 있습니다.
Dropout이라는 정규화 기법이 FC layer의 활성화 값을 무작위로 절반을 0으로 만드는 기법입니다.
이를 통해 일반화 능력이 향상되었고, overfitting이 방지되었습니다.
이 논문에서는 FC layer를 대체하기 위해 Global Average Pooling이라는 전략을 제안합니다.
이 방법은 마지막 mlpconv layer에서 분류 작업의 각 카테고리에 해당하는 하나의 feature map을 생성하는 아이디어에 기반합니다.
FC layer를 feature map 위에 추가하는 대신, 각 feature map의 평균을 구하고, 그 결과 벡터를 소프트맥스 층에 직접 입력합니다.
Global Average Pooling이 FC layer에 비해 가지는 장점은 feature map과 카테고리 사이의 대응 관계를 강제함으로써 convolution 구조에 더 적합하다는 점입니다.
또 다른 장점은 Global Average Pooling에는 최적화할 파라미터가 없기 때문에 overfitting이 발생하지 않는다는 점입니다.
게다가 Global Average Pooling은 spatial 정보를 합치므로 입력의 spatial translation에 더 robust합니다.
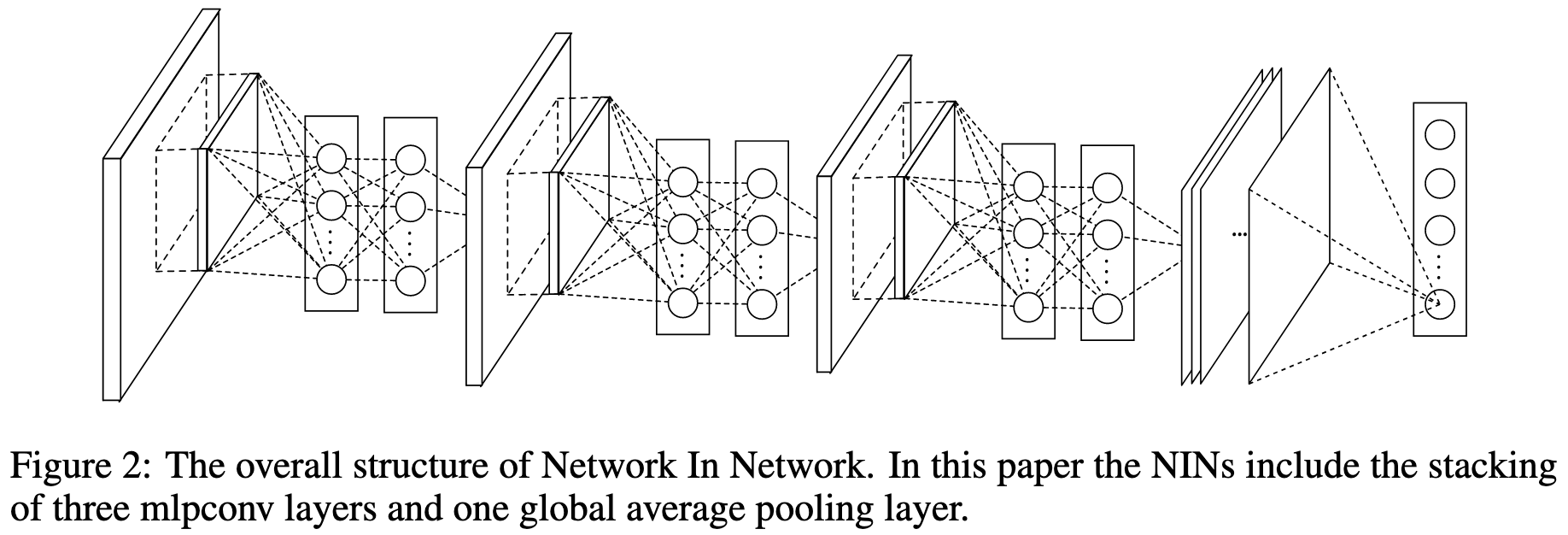
3.3 Network In Network Structure
NIN의 전체 구조는 mlpconv layer의 스택으로 구성되어 있습니다.
그 위에 global average pooling과 object cost layer이 위치합니다.
sub-sampling layer는 CNN이나 maxout 신경망처럼 mlpconv layer 사이에 추가될 수 있습니다.
Figure 2는 3개의 mlpconv layer로 구성된 NIN 구조를 보여줍니다.
각 mlp conv layer 내부에는 세 개의 layer로 이루어진 퍼셉트론이 존재합니다.
NIN과 micro network의 layer 수는 유연하며, 특정 작업에 맞게 조정할 수 있습니다.
4 Experiments
CIFAR-10, CIFAR-100, SVHN, MNIST 데이터셋에 대한 실험 결과를 보여줍니다.
실험 결과 자신의 아이디어가 좋은 성능을 보였다는 단서들이기 때문에 넘어가도록 하겠습니다.
