
📝 이번 포스트는 GoogLeNet 혹은 Inception v1으로 유명한 "Going deeper with convolutions"논문에 대해 알아보도록 하겠습니다.
Abstract와 Introduction은 이해하기 쉬우니 직접 읽어보시기 바랍니다.
2. Related Work
이 논문을 연구할 때 참고한 관련 지식을 설명합니다.
Convolutional Neural Network(CNN)
Conv layer를 여러번 쌓고 FC layer 배치하는 CNN모델을 이 논문을 연구하는데 참고하였다고 합니다.
Neuroscience
영장류 시각피질에 대한 신경 과학 모델에서 영감을 받았다고 합니다.
Serre의 "Robust object recognition with cortex-like mechanisms" 논문에서 고정된 Gabor filter를 사용하여 다양한 스케일의 이미지를 처리했습니다.
Network In Network
저자는 Lin의 "Network In Network" 논문을 참고하였습니다.
이 논문은 1x1 필터를 중요하게 다룹니다.
이 논문은 신경망의 representation 능력을 증가시키는 것을 목표로 하였는데요,
Conv layer가 적용될 때, 이 논문의 방법은 1x1 Conv layer을 ReLU 함수 뒤에 적용합니다.
저자의 아키텍쳐는 1x1 Conv layer를 dimension을 줄이는 모듈로 사용하고, 병목현상을 제거하는 데 사용됩니다.
1x1 Conv layer를 통해 신경망의 깊이와 너비를 성능 저하 없이 증가시킬 수 있게 하였습니다.
R-CNN
R-CNN은 detection 문제를 두개의 하위 문제로 나눕니다.
- 색상 및 슈퍼픽셀 일관성과 같은 저수준의 단서를 사용하여 category에 무관하게 potential object proposal을 찾는 것.
- CNN classifier를 사용하여 그 object proposal에서 category를 식별하는 것.
이러한 R-CNN 연구의 배경으로 사용하였다고 합니다.
ILSVRC 2014 Detection Challenge 대회에서 참고하였습니다.
3. Motivation and High Level Considerations

DNN의 성능을 향상시키는 가장 간단한 방법은 신경망의 크기를 증가시키는 것입니다.
하지만 이 방법에는 두가지 단점이 있습니다.
- 더 큰 신경망은 더 많은 파라미터를 뜻하며, 네트워크가 과적합되기 쉬워집니다.
그리고 높은 퀄리티의 학습데이터셋을 만드는 것은 까다롭고 비용이 많이 들기 때문에 병목현상이 될 수 있습니다.
Figure 1과 같이 ImageNet같은 세밀한 카테고리를 구별하려면 전문가의 평가가 필요할 수 있습니다. - 신경망의 크기를 증가시키면 컴퓨터 자원의 사용량이 증가합니다.
메모리, CPU, GPU등 컴퓨터 자원은 한정되어 있습니다.
따라서 신경망의 성능을 향상시키는 것이 메인 목표라 할지라도 신경망의 크기를 무작정 증가시키기보다는 컴퓨터 자원을 효율적으로 배분하는 것이 더 좋은 방법일 수 있습니다.
이 두가지 문제점들의 해결하는 근본적인 방법은 완전한 연결구조의 아키텍쳐에서 벗어나 sparse한 연결 구조의 아키텍쳐로 바꾸는 것입니다.
그 당시 컴퓨터 인프라는 non-uniform한 sparse한 데이터 구조에서 산술연산을 수행할 때 비효율적이였습니다.
산술연산의 수가 100배 줄어든다고 해도, lookup과 cache miss의 오버헤드가 너무 커서 sparse matric으로 큰 이익을 주지 못했습니다.
그리고 CPU 나 GPU의 세부사항을 이용하는 극도로 최적화된 연산 라이브러리들을 사용하여 CNN의 연산을 매우 빠르게 수행하고 있습니다.
또한 non-unfiorm sparse 모델은 더 정교한 모델링과 컴퓨터 자원 접근을 필요로 합니다.
그 당시 대부분의 컴퓨터비전 지향 머신러닝 시스템은 convolution을 사용함으로써 spatial domain 속 sparsity 활용했습니다.
전통적으로 합성곱 신경망은 학습을 향상시키고 대칭을 깨기 위해 feature dimension에서 랜덤하고 sparse한 연결을 사용해왔지만, 트렌드는 병렬 컴퓨팅을 더 잘 최적화하기 위해서 full한 연결로 돌아왔습니다.
Inception 아키텍쳐는 sparse 구조를 근사하려는 정교한 신경망 구축 알고리즘의 가설적 결과를 평가하기 위한 연구로 시작되었습니다.
4. Architectural Details
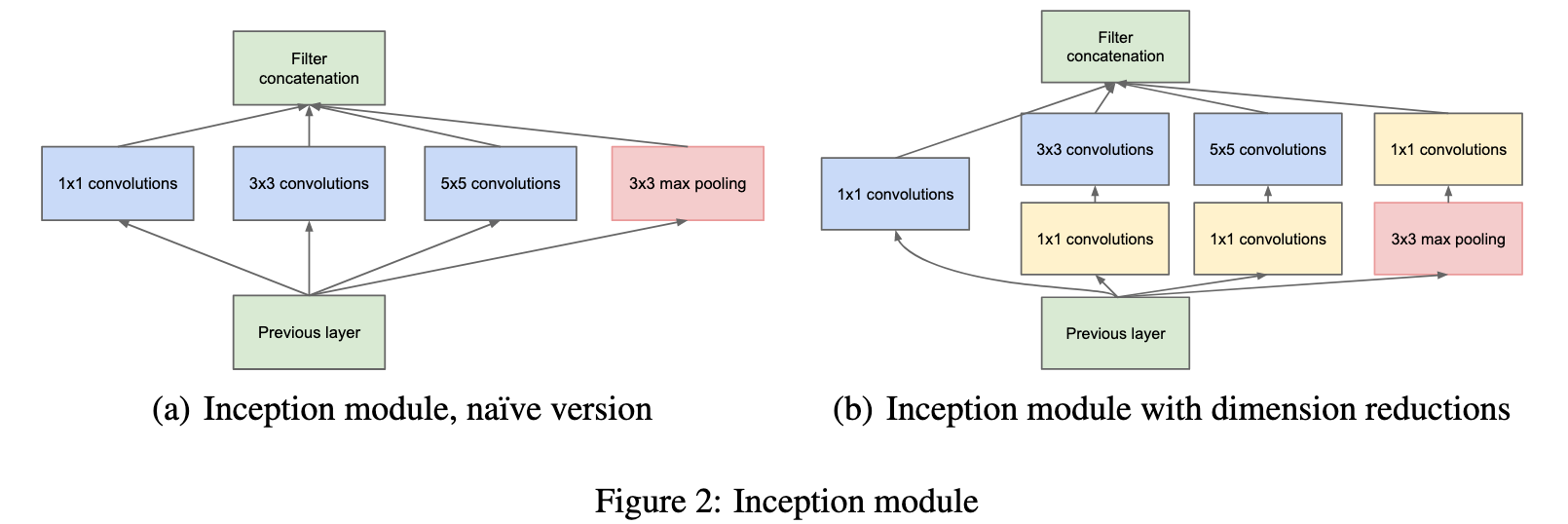
Figure 2의 (a) naive version을 보면 개념을 이해할 수 있습니다.
저자는 하나의 layer가 filter bank(1x1, 3x3, 5x5 Conv)로 그룹으로 묶여질 수 있다고 가정합니다.
그 이유는 filter bank속 각 유닛들이 상관관계를 가진다는 관련 연구가 있었기 때문이었습니다.
그러면 상관관계를 갖는 각 유닛들은 local 영역에 집중할 수 있게 됩니다.
하나의 filter bank에 더 많은 유닛을 구성할 수도 있었지만, 1x1, 3x3, 5x5 이 3개의 Conv 유닛을 사용하였습니다.
하지만 이 naive version은 큰 단점이 있습니다.
naive version에서 많은 수의 필터가 있는 Conv 유닛에서 비용이 지나치게 높아질 수 있다는 점이다.
이 클러스터에 pooling 유닛이 추가되는 것도 문제입니다.
pooling 유닛은 이전 레이어의 필터 수와 같은 수의 필터를 결과로 갖기 때문입니다.
pooling layer과 Conv layer을 합치면 출력되는 필터 수의 증가를 피할 수 없게 됩니다.
이 단점을 보완할 아이디어가 Figure 2의 (b)에 나와있습니다.
이 문제의 해결책은 1x1 Conv 유닛을 적용하여 dimension reduction과 projection을 할 수 있었습니다.
어떻게 적용이 되냐하면, 1x1 Conv 유닛을 3x3과 5x5 Conv 유닛 앞에 배치하여 필터수를 줄입니다.
이러한 inception module에 종종 stride=2인 max pooling layer를 사용하였는데, 그 이유는 해상도를 절반으로 줄이기 위해서 사용했다고 합니다.
학습 중 메모리 효율성을 고려하여, 높은 layer(output과 가까운 layer)에서 Inception module사용하고 낮은 layer(input과 가까운 layer)에서는 전통적인 convolution을 사용하는 것이 유리하다고 판단하여 아키텍쳐를 구성했다고 합니다.
이 보완된 아키텍쳐의 주요 이점 중 하나는 dimension의 증가로 계산량이 증가하는 것을 방지할 수 있다는 점이다.
그리고 각 단계의 너비와 레이어 수를 증가시켜도 컴퓨터 비용적인 문제가 발생하지 않는다는 점이다.
5. GoogLeNet
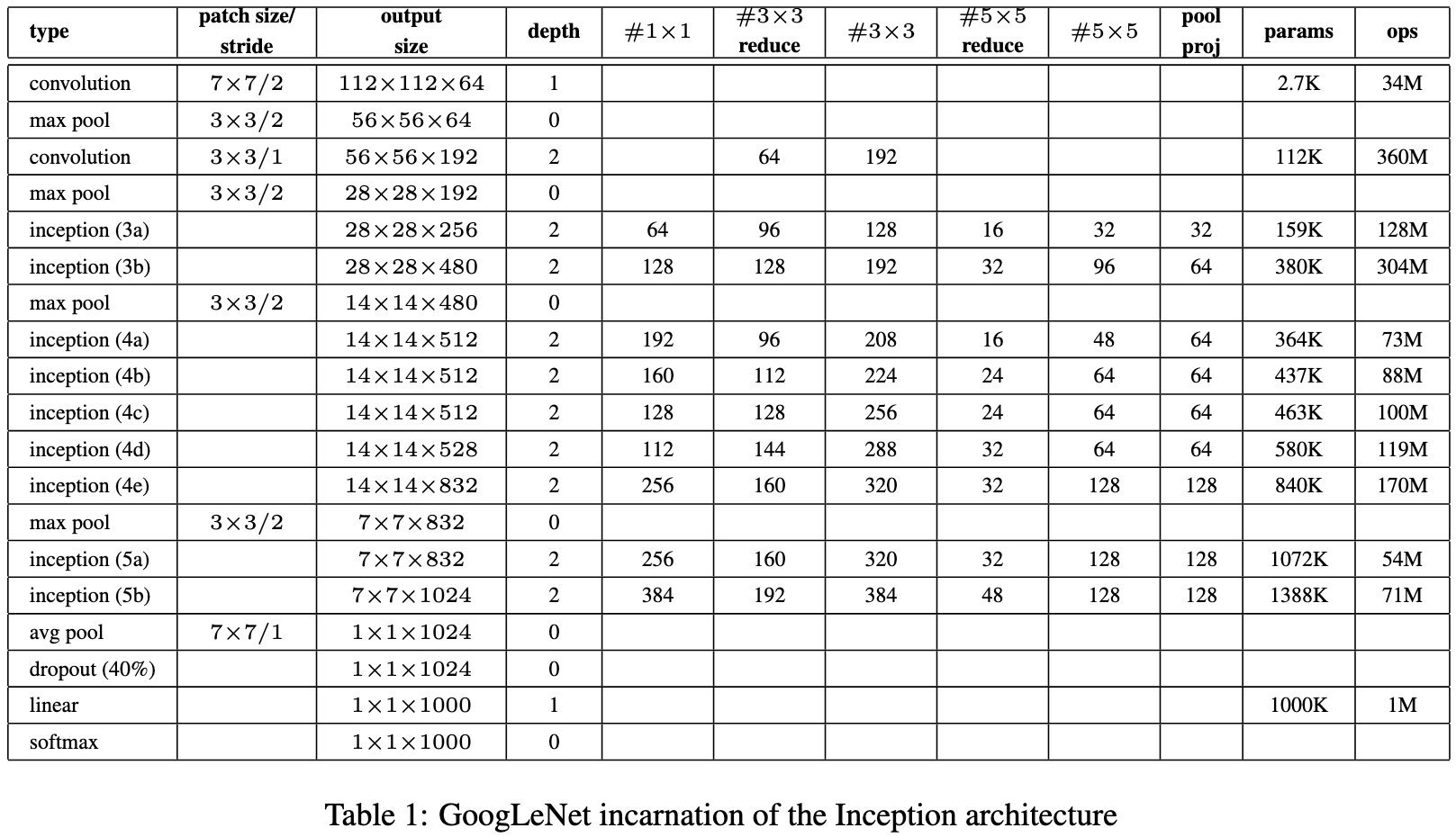
위 Table 1은 Inception을 사용한 GoogLeNet을 어떻게 모델링하였는지 보여주는 표입니다.
어떻게 모델을 구성했는지 표를 보시며 이해하시면 되겠습니다.
모델의 input은 224x224x3 이미지에 평균을 뺀 값이 모델에 input으로 들어옵니다.
표 용어정리
- #1X1 : 1x1 Conv layer
- #3x3 reduce : 3x3 Conv layer 앞에 적용되는 차원을 축소하는 1x1 Conv layer
- #3x3 : 3x3 Conv layer
- #5x5 reduce : 5x5 Conv layer 앞에 적용되는 차원을 축소하는 1x1 Conv layer
- #5x5 : 5x5 Conv layer
- pool proj : pooling layer 후에 적용되는 1x1 Conv layer
모든 layer들 뒤에는 ReLU가 활성화함수로 따라옵니다.
신경망은 22층이고 pooling layer까지 포함한다면 27층이라고 할 수 있습니다.
각각의 유닛들을 세면 이 GoogLeNet에 100개의 유닛이 사용되었습니다.
그리고 저자는 Network In Network(NIN) 논문을 참고하여 FC layer 대신 Average Pooling layer를 구현하였다고 합니다.
실제로 Average Pooling을 사용함으로써 top-1 accuracy가 0.6 향상되었다고 합니다.
그런데 저자는 한가지 걱정되는 점이 하나 있었습니다.
그것은 네트워크의 큰 깊이로 인해 모든 계층을 통해 효과적으로 gradient를 전파하는 것이였습니다.
이것은 auxiliary classifier를 중간 layer에 추가함으로써, classifier의 식별능력을 하위 layer에서 도와줍니다.
표를 보면 Inception (4a)와 (4d) module이 있는데 이 module 뒤에 auxiliary classifier를 추가하였습니다.
그리고 특이한 점은 training 중에는 auxiliary classifier의 loss를 total loss의 0.3으로 적용합니다.
inference시에는 auxiliary classifer가 비활성화됩니다.
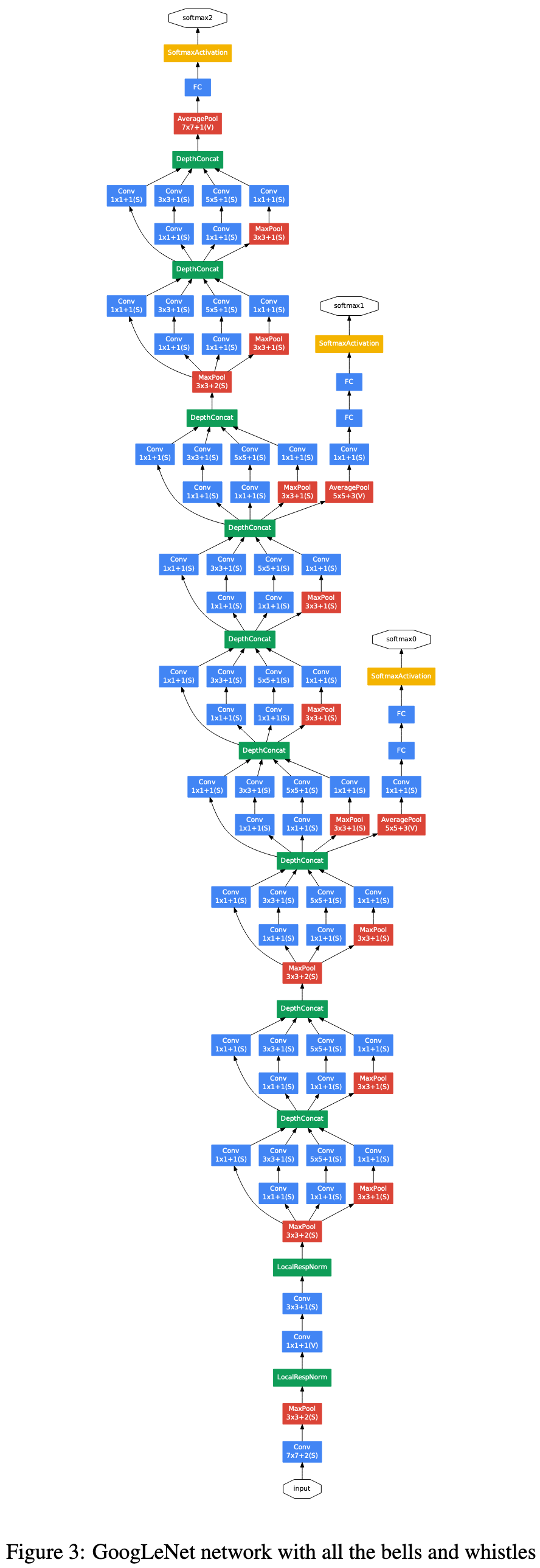
Auxiliary classifier의 과정은 아래와 같습니다.
- stride = 3인 5x5크기의 average pooling layer가 적용된다.
- dimension reduction을 위해 1x1 크기의 Conv layer + ReLU가 적용된다.
- 1x1024 크기의 FC layer + ReLU 적용된다.
- 70% 비율의 Dropout layer가 적용된다.
- main classifer와 같이 1000개의 클래스를 예측하는 softmax loss를 구한다.(inference시에는 비활성화)
전체적인 GoogLeNet 모델은 이와 같습니다.
6 Training Methodology 는 하이퍼파라미터 설정값에 대해 설명하고, 추가로 특정 데이터증강기법을 사용하였다고 하는데, 사용한 방법이 최종 결과에 긍정적인 영향을 미쳤는지는 잘 모르겠다고 한다...?? 그래서 넘어가도록 하겠습니다.
7. ILSVRC 2014 Classification Challenge Setup and Results
이 부분에서는 실험에 사용한 데이터 증강 방법을 소개합니다.
- 동일한 GoogLeNet 모델의 버전을 독립적으로 훈련시키고 이 모델들로 앙상블 예측을 수행했습니다. 이 모델들은 같은 초기화 방법과 학습률을 사용했으며, 샘플링 방법론과 입력이미지의 순서만 달랐습니다.
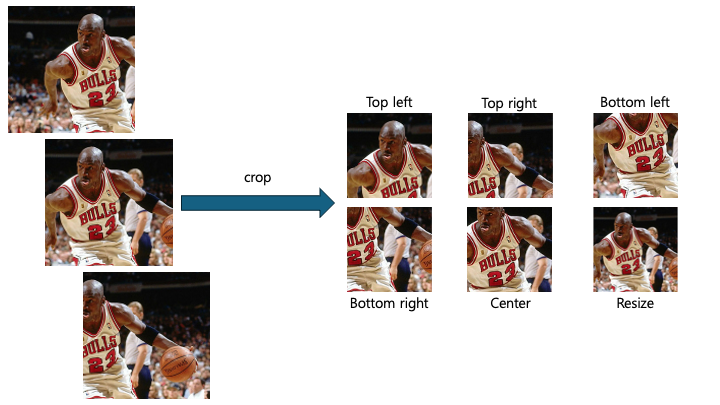
- 이미지의 높이와 너비 중 짧은 쪽이 256, 288, 320, 352 이 4가지 크기로 4번 다 resize를 합니다.
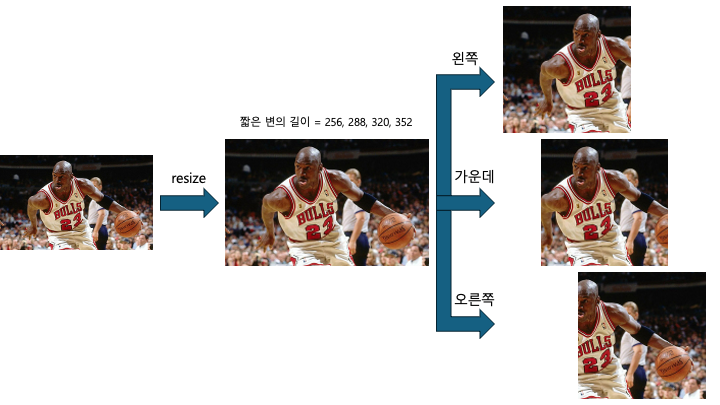
그리고 224x224사이즈로 top left, top right, bottom left, bottom right, center, resize하여 새로운 이미지를 생성합니다.
그 후 미러링된 이미지도 생성합니다.
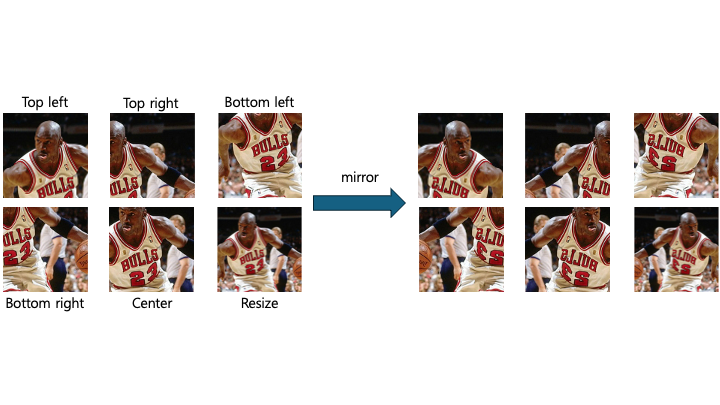
이렇게 한 장의 이미지에서 4x3x6x2번 즉, 144번 데이터를 증강하여 얻습니다.
그리고 이 것을 실험에 사용하였다고 합니다. - 모든 개별 classifier에서 softmax 확률을 더하여 평균을 구했습니다. crop과 평균을 구하는 방식을 validation data에도 적용하는 방식을 사용해보았는데 성능은 단순 평균을 구하는 방식보다 떨어졌다고 합니다.
8 ILSVRC 2014 Detection Challenge Setup and Results 부분은 비교적 읽기 쉬우니 직접 읽어보시기를 권합니다.
9. Conclusions
이 논문을 읽고 Inception 모듈을 이해하시면 됩니다.
이 논문의 요지는 깊은 신경망을 쌓을 때
- 1x1 Conv 유닛이 막대한 커널의 증가를 방지하다는 것
- Inception 모듈이 non-uniform한 sparse한 데이터 구조를 갖음으로써 상관관계를 갖는 각 유닛들이 local한 정보를 갖을 수 있었다는 것
- Auxiliary Classifier가 깊은 신경망에게 효과적으로 gradient를 전파하였다는 것
이렇게 기억하시면 됩니다.✅
