
📝 이번 포스트는 Inception v2로 알려진 "Rethinking the Inception Architecture for Computer Vision" 논문에 대해 알아보도록 하겠습니다.
1. Why : 논문의 연구 배경
CNN은 여러 연구 분야에서 성공적인 결과를 보여주었습니다.
그리고 2014년부터 네트워크의 깊이와 너비를 확장하는 방향으로 크게 좋은 결과를 보여주었습니다.
대표적으로 네트워크의 깊이를 증가시킨 VGGNet과 네트워크의 너비를 증가시킨 GoogleNet(Inception-v1)이 ILSVRC 2014에서 높은 성능을 보였습니다.
VGGNet은 간단한 구조로 설계되었지만, 높은 연산 비용이라는 단점이 있었습니다.
반면 Inception 모듈을 사용한 GoogLeNet은 연산 비용과 메모리 사용량을 효율적으로 관리하면서도 뛰어난 성능을 보였지만, Inception 모듈의 복잡성이라는 단점이 있었습니다.
Inception 아키텍처는 네트워크를 확장하거나 변경하는 것이 어려웠습니다.
Inception-v1(=GoogLeNet)은 필터 크기를 단순히 두 배로 늘리면 연산 비용과 파라미터 수를 4배로 증가시키는 단점이 있었습니다.
따라서 이 논문에서는 이러한 한계를 극복하기 위해 Inception 아키텍처를 유연하게 변경하여 성능을 개선하는 방법을 연구하였습니다.
2. How : 연구 방법론
2.1. General Design Principles
CNN의 아키텍처를 개선하기 위해 네 가지 일반적인 design 원칙을 제안합니다.
-
네트워크의 초기 단계에서 representational bottleneck현상을 피해야 한다.
전형적인 순방향으로 이미지 벡터가 흘러가는 피드포워드 네트워크는 입력에서 출력으로 정보가 흐르는데, 지나친 병목현상은 정보가 손실될 수 있습니다.
따라서 네트워크의 representation 크기는 입력에서 출력 방향으로 점진적으로 감소하도록 디자인해야합니다. -
고차원의 representation을 활용하면 특징 분리를 용이하게 하고, 네트워크의 학습 속도를 향상시킬 수 있습니다.
고차원 표현이 local한 process를 더 효과적으로 수행할 수 있기 때문입니다. -
spatial aggregation(≒Convolution)을 수행하기 전에 입력으로 들어오는 representation(=Feature map)의 dimension reduction(≒1×1필터)은 정보 손실 없이 효율성을 높이는 데 기여할 수 있습니다.
이는 인접한 벡터간 강한 상관관계가 정보 손실을 최소화하기 때문입니다. -
네트워크의 필터 수와 레이어수를 균형 있게 증가시키면 더 높은 성능의 네트워크를 구축할 수 있다.
저자는 위 4가지 원칙을 잘 따르도록 새로운 Inception-v2와 Inception-v3 아키텍쳐를 개발하였습니다.
2.2. Factorizing Convolutions with Large Filter Size
저자는 GoogLeNet(Inception-v1)의 성능 향상은 차원 축소 방법이 큰 영향을 미쳤다고 주장합니다.
이를 확장하여 합성곱을 더욱 효율적으로 팩터라이징하는 방법을 연구하였습니다.
큰 크기의 합성곱 필터의 연산 비용을 줄이기 위한 2가지 팩터라이징 방법을 제시합니다.
2.2.1. Factorization into smaller convolutions
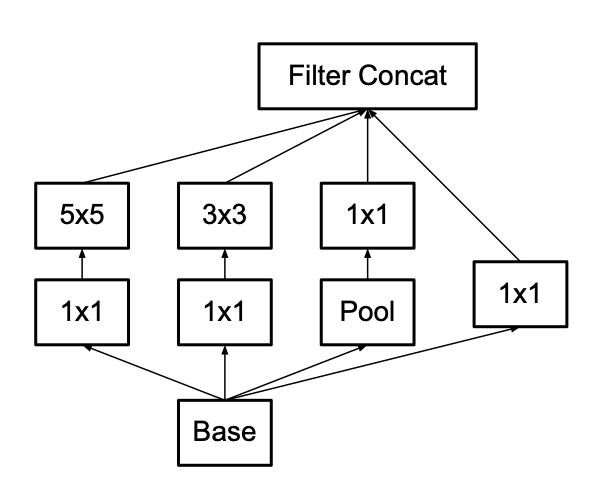
큰 합성곱 필터의 높은 연산 비용을 줄이기 위해서 작은 합성곱 필터로 분해하는 방법을 고안하였습니다.
위 그림은 Inception-v1의 Inception 모듈입니다.
Inception-v1의 5×5 합성곱을 동일한 입력 크기와 출력 깊이를 유지하면서 두 개의 3×3 합성곱으로 대체하면서 계산 비용을 줄일 수 있는 아이디어를 고안합니다.
이 아이디어을 반영하여 저자는 새로운 Inception 모듈을 만들었습니다.
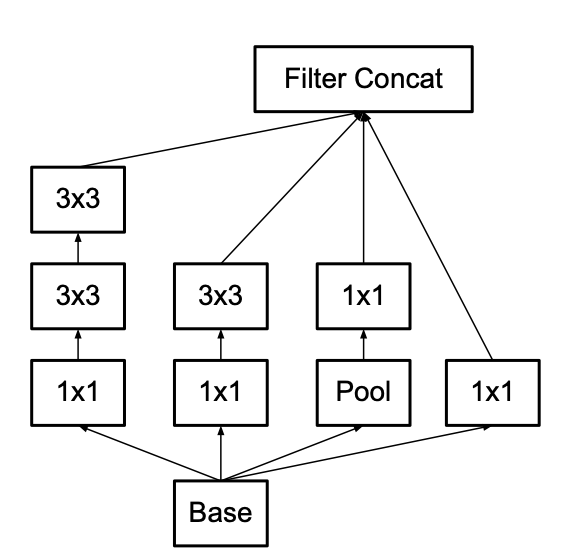
위 그림과 같이 5×5 합성곱을 2개의 3×3 합성곱으로 대체한 새로운 Inception 모듈을 만들었습니다.
큰 합성곱을 작은 합성곱으로 대체하면 representation 능력을 손실될 수 있다는 우려가 있었지만, 실험 결과 이 새로운 Inception 모듈은 representation을 유지하면서도 연산비용을 줄인다는 것을 확인하였습니다.
그리고 ReLU를 사용하고 배치 정규화를 적용했을 때 네트워크의 학습 및 성능이 개선되었다고 합니다.
2.2.2. Spatial Factorization into Asymmetric Convolutions
저자는 n×n 크기의 대칭적인 합성곱을 더 작은 비대칭적인 합성곱으로 분해하여 계산 비용을 줄이는 방법을 고안하였습니다.
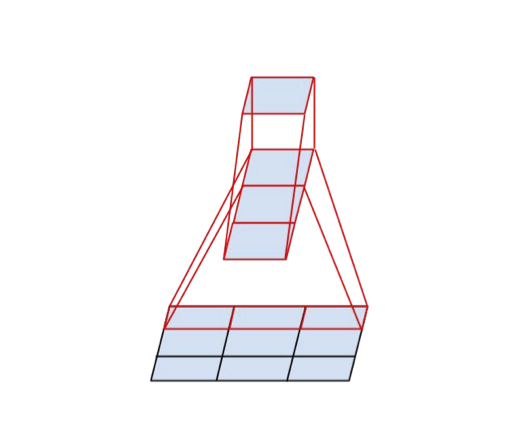
예를 들어 3×3 합성곱을 3×1 합성곱과 1×3 합성곱을 분해하여사용하는 것은 동일한 receptive field를 갖는 2-layer 네트워크를 슬라이딩하는 셈입니다.
레이어 수는 2로 늘어났지만, 연산 비용이 33% 감소하였습니다.
반면 3×3 합성곱을 두 개의 2×2 합성곱으로 대체하였을 때는 연산 비용이 11%밖에 감소하지 않았습니다.
따라서 n×n 합성곱은 1×n과 n×1 합성곱으로 대체하는 것이 연산 비용 감소 면에서 효율적임을 알 수 있었습니다.
추가로, n이 커질수록 연산비용은 반비례하여 감소한다고 합니다.
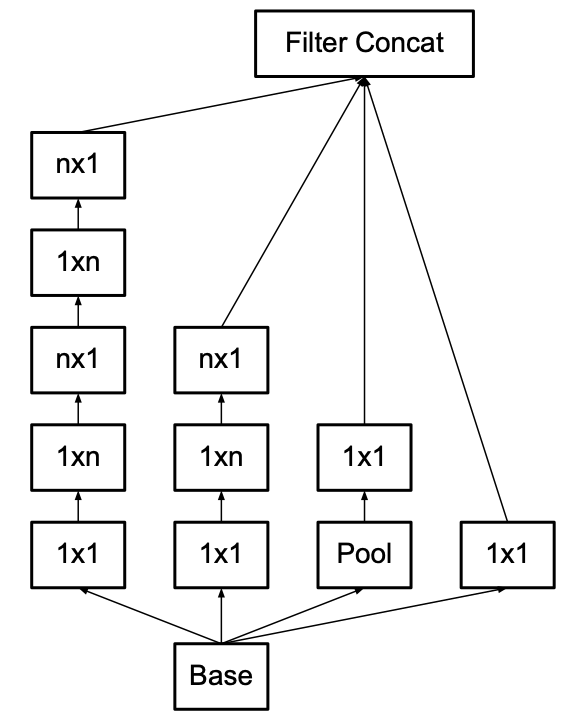
위 그림은 비대칭 합성곱으로 기존 Inception 모듈을 factorize한 모듈을 그린 것입니다.
모듈을 구축할 때 위 그림 속 모듈대로 설계하면 됩니다.
중간 크기(12<=m<=20)의 m×m 피처맵에서 비대칭 factorization이 매우 효과적이었다고 합니다.
하지만 이 비대칭 factorization을 구현한 모듈을 초기 레이어에서 구현하면 기대했던 효과를 보지 못했다고 합니다.
2.3. Utility of Auxiliary Classifiers
Inception-v1에서는 보조 분류기(Auxiliary Classifier)가 매우 깊은 네트워크에서 기울기 소실 문제를 해결하고, 하위 레이어로 기울기를 전달하여 학습 수렴 속도를 높이는 데 기여하였다고 생각했지만, 이 논문에서는 새로운 실험 결과를 바탕으로 보조 분류기의 역할이 Inception v1의 가설과 다를 수 있음을 설명합니다.
저자는 보조 분류기를 추가한 네트워크와 그렇지 않은 네트워크를 비교하여 실험을 하였습니다.
학습 초기 단계에서는 수렴 속도와 정확도 면에서 거의 동일한 성능을 보였습니다.
저자는 Inception-v1에서의 보조분류기 역할에 대한 가설이 잘못되었음을 말하고, 정규화처럼 작동한다고 새로운 가설을 제시합니다.
2.4. Efficient Grid Size Reduction
전반적으로 CNN은 feature map의 그리드 크기를 줄이기 위해 풀링 연산을 수행합니다. 하지만 이러한 풀링 과정에서 representation bottleneck현상이 발생할 수 있습니다.
이 현상을 방지하기 위해 풀링 연산과 합성곱을 결합하는 방법을 고안하였습니다.
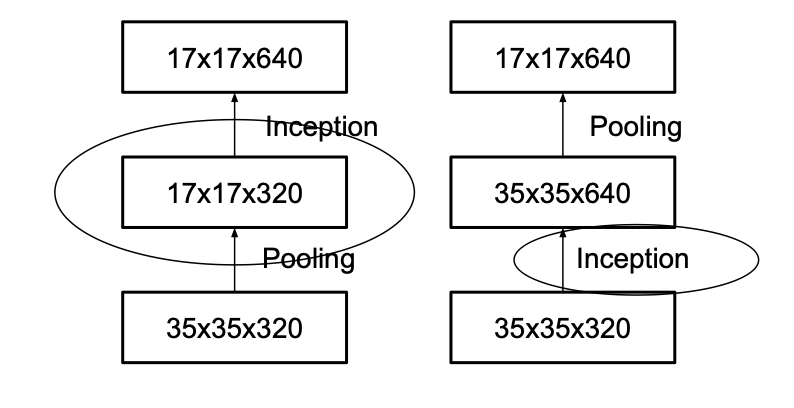
순차적인 방법으로 풀링과 합성곱을 직렬연결한다면 문제가 발생합니다.
위 그림을 보면 왼쪽은 풀링이 먼저 연산되고 그 다음 인셉션 모듈이 연산되는 순서인데, 이 같은 경우는 병목현상이 발생합니다.
반대로 오른쪽은 인셉션 모듈이 먼저 연산되고 그 다음 풀링이 연산되는 순서인데, 이 순서는 엄청난 연산 비용이 발생합니다.
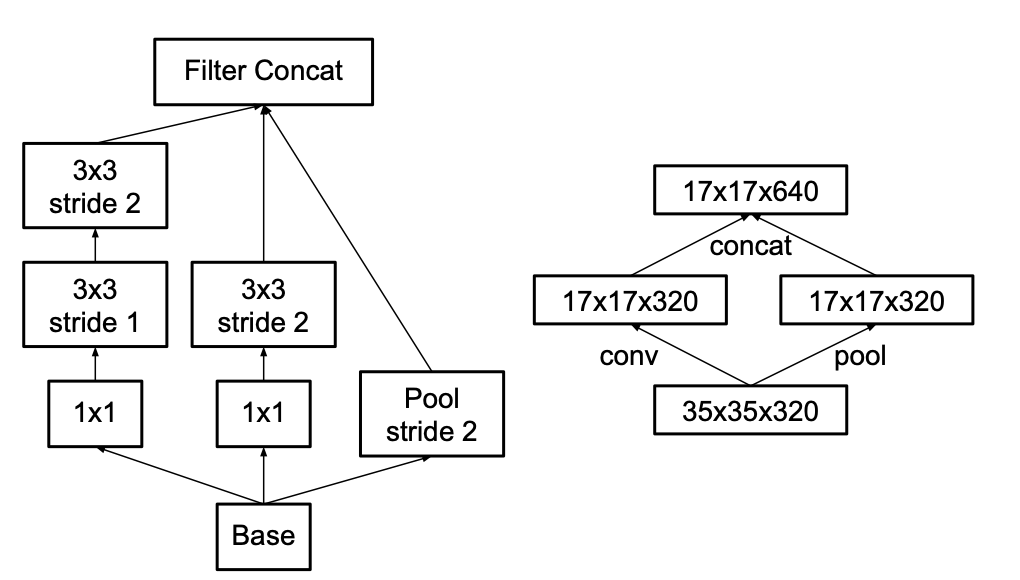
따라서 저자는 풀링 연산과 합성곱 연산을 병렬로 연결하여 그리드 사이즈를 줄이는 방법을 제시합니다.
위 그림의 오른쪽을 보면 stride가 2인 풀링 연산(P블록)과 stride가 2인 합성곱연산(C블록)을 사용하여 두 연산 결과 벡터를 병렬로 연결(concatenate)하는 방법을 고안하였습니다.
이 방법은 연산 비용을 줄이는 동시에 representation bottleneck현상을 제거하는 효과 얻을 수 있었습니다.
2.6. Inception-v2
저자는 위에 소개된 방법들을 이용하여 Inception-v2를 개발하였습니다.
Inception-v1에서 사용되던 7x7 합성곱은 3개의 3x3 합성곱으로 factorize하여 계산 효율성을 극대화하였다고 합니다.
기타 등등 위에서 소개한 방법들을 이용하여 아래와 같이 모델을 구축하였습니다.
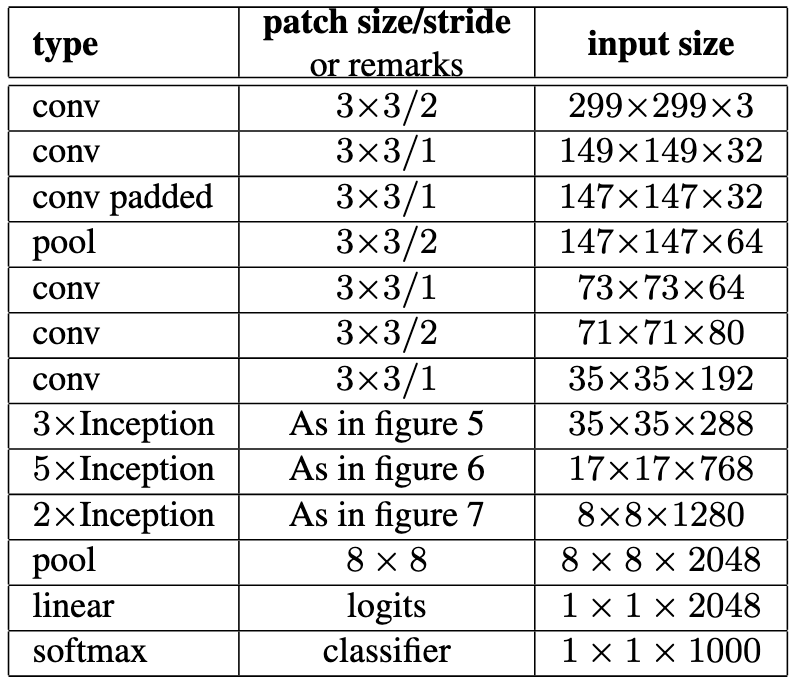
Inception-v2는 총 42개의 레이어로 구성되었으며, GoogLeNet(=Inception-v1)에 비해 계산 비용이 약 2.5배 증가했지만 에러율과 성능은 VGGNet보다 훨씬 좋았다고 합니다.
2.7. Model Regularization via Label Smoothing
신경망의 마지막에서 소프트맥스로 클래스를 예측하는데, 예측된 레이블과 정답 레이블을 cross entropy로 loss를 구할 때, 모델이 지나치게 자신있는 예측이 오히려 학습을 저해할 수 있다고 합니다,
원래 정답 레이블은 원핫 레이블로써 정답 클래스는 1로 표기되고, 나머지 오답 클래스는 0으로 표기되는 one-hot 레이블입니다.
이 one-hot 레이블은 모델이 지나치게 자신있는 예측을 하도록 유도하며, 과적합을 유도하며 학습의 유연성을 저해할 수 있다고 합니다.
따라서 정답에 대한 확신을 줄이기 위해 Label Smoothing 정규화 기법을 사용했다고 합니다.
Label Smoothing의 수식은 아래와 같습니다.
은 smoothing 계수이며, 는 클래스의 개수를 뜻하고, 는 레이블분포(0 or 1)을 뜻합니다.
예를들어 4개의 클래스에 대해 원핫레이블이 [0, 0, 0, 1]이 있다고 가정해보면,
위 공식의 파라미터 , 라고 가정했을 때, 레이블은 [0.025, 0.025, 0.025, 0.925]로 스무딩된 레이블로 바꿀 수 있습니다.
위 레이블 스무딩 기법을 적용하여 cross entropy 손실 함수를 재정의해보면
와 같고, 기존 cross entropy 손실함수랑 형태는 같습니다.
저자는 레이블 스무딩을 정규화 기법을 이용하여, 모델이 지나치게 자신있는 예측을 갖는 것을 억제하며 일반화 성능을 향상시켰다고 합니다.
3. Experiments
3.1. Performance on Lower Resolution Input
이 당시에는 2-stage Detector가 객체 탐지 분야에서 지배적이였고, 1-stage Detector인 YOLO가 발표되기 전 시대였습니다.
2-stage Detector는 물체가 있을 법한 위치를 짐작하고 패치로 추출하여 작은 사이즈인 패치에서 classification을 적용하는 방식입니다.
이 논문의 저자는 2-stage Detector에서 사용하는 원본 이미지보다 작은 크기인 이미지 패치를 활용할 방법으로 저해상도 이미지에서도 Inception 네트워크를 적용할 방법을 연구했습니다.
저자는 ImageNet 2012 데이터셋으로 실험을 진행했습니다.
저자는 세가지 변형된 모델로 실험을 진행했으며 변형된 모델은 아래와 같습니다.
- 299x299 크기의 입력 이미지에 stride=2를 갖는 첫번째 레이어(합성곱) 이후 맥스 풀링을 갖는 Inception-v2
- 151x151 크기의 입력 이미지에 stride=1를 갖는 첫번째 레이어 이후 맥스 풀링을 갖는 Inception-v2
- 79x79 크기의 입력 이미지에 stride=1를 갖는 Inception-v2 (맥스풀링 없음)
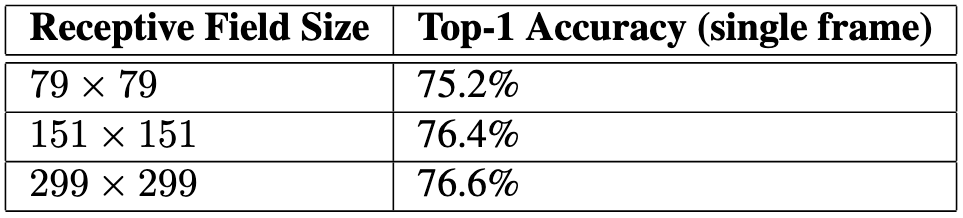
세 네트워크의 연산 비용은 동일하게 구성하였습니다.
저해상도 네트워크는 학습 시간이 오래 걸리지만, 성능은 많이 감소하지 않음을 보였습니다.
3.2. Experimental Results and Comparisons
이 단락에서는 주요 성능 비교 실험을 다룹니다.
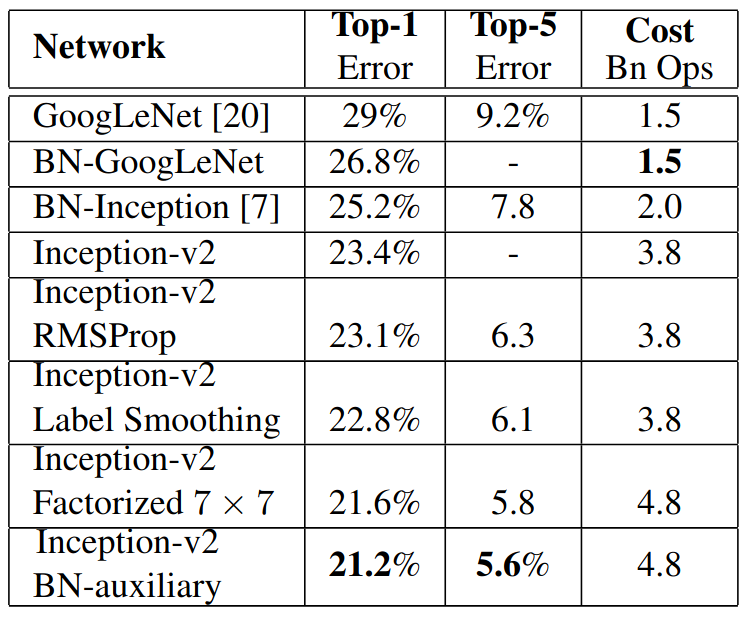
위 표는 다른 모델들과 Inception-v2와 그의 앙상블 모델들을 비교하여 에러율을 비교하였습니다.
이렇게 새로운 방법을 추가한 앙상블 모델들이 더 좋은 성능을 보였습니다.
다음으로 Inception-v3모델도 포함시켜 실험을 진행하였습니다.
Inception-v3는 Inception-v2에 RMSProp + Label Smoothing + Factorized 7x7 + BN-auxiliary를 앙상블한 모델입니다.
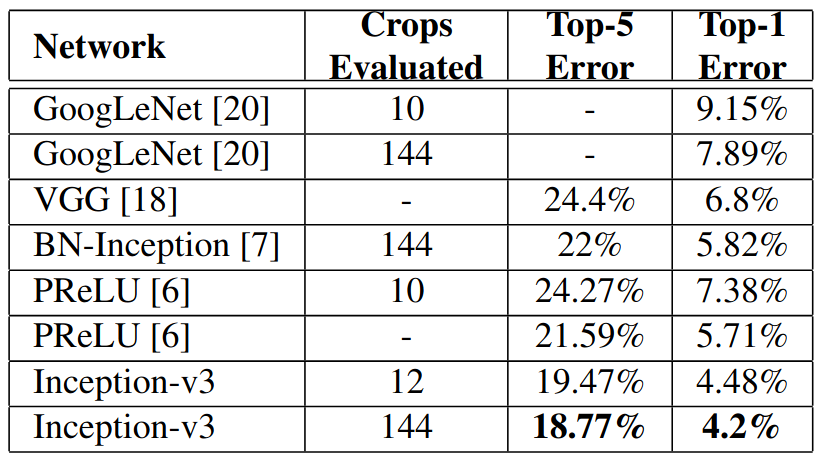
앞부분에서 설명한 모든 아이디어를 앙상블한 Inception-v3가 Top-1 에러율과 Top-5 에러율에서 가장 낮은 에러율을 보였습니다.
4. Conclusion
Inception-v2, Inception-v3는 연산 효율성과 성능 간의 균형을 성공적으로 맞춘 아키텍처로, 파라미터 수와 계산 비용을 줄이면서도 당시 SOTA를 달성하였습니다.
특히, 작은 해상도 입력 이미지와 높은 성능을 유지할 수 있는 가능성을 보여주었으며, 이는 다양한 실세계 애플리케이션에서 활용될 수 있는 아키텍쳐임을 보였습니다.
