[논문리뷰] ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
Deep Learning

📝 이번 포스트는 ShuffleNet으로 알려진 "ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices" 논문에 대해 알아보도록 하겠습니다.
1. Why : 논문의 연구 배경
저자가 논문을 발표하던 시기는 딥러닝 분야에서는 깊고 큰 CNN을 구축하는 것이 일반적인 추세였습니다.
ResNet이나 Inception 모델들은 파라미터 수가 상당히 큰 모델에 속합니다.
하지만 드론, 로봇, 스마트폰과 같은 모바일 플랫폼에서는 제한된 연산 비용 내에서 높은 정확도를 유지해야하는 CNN모델을 필요로 합니다.
기존 연구들은 주로 "basic" 네트워크 아키텍쳐에 pruning, compressing, low-bit representating하는 방식으로 연산량을 줄이는 데 집중하였습니다.
Xception과 ResNext 같은 그 당시 SOTA 아키텍쳐들은 비용이 많이 드는 1×1 합성곱으로 인해 매우 작은 네트워크에 대해서는 효율적이지 못했습니다.
저자는 1×1 합성곱의 연산 복잡도를 줄이기 위해 pointwise group convolution과 group convolution의 부작용을 극복하기 위해 피쳐 채널 간의 정보를 교환할 수 있는 channel shuffle 연산을 연구하였습니다.
2. How : 연구 방법론
2.1. Channel Shuffle for Group Convolutions
기존 연구들(Xception & ResNeXt)은 depthwise separable convolution이나 group convolution을 통해 연산 비용과 표현력 사이에서 trade-off를 하였습니다.
하지만 이 두 모델은 1×1 합성곱의 높은 연산 비용을 고려하지 않고 설계되었습니다.
cardinality=32인 ResNeXt 경우 1×1 합성곱이 총 연산 비용의 93.4%를 차지한다고 합니다.
크기가 작은 네트워크에서는 이러한 1×1 합성곱이 연산 비용이 높아 채널 수를 제한해야 하며, 이는 정확도를 저하할 수도 있습니다.
이 문제를 해결하기 위해 저자는 1×1 합성곱에 group convolution를 구현하는 channel sparse convolution을 연구하였습니다.
그러나 많은 group convolution을 연속적으로 쌓으면 출력 피쳐가 특정 그룹의 채널에만 국한된다는 부작용이 따르게 됩니다.
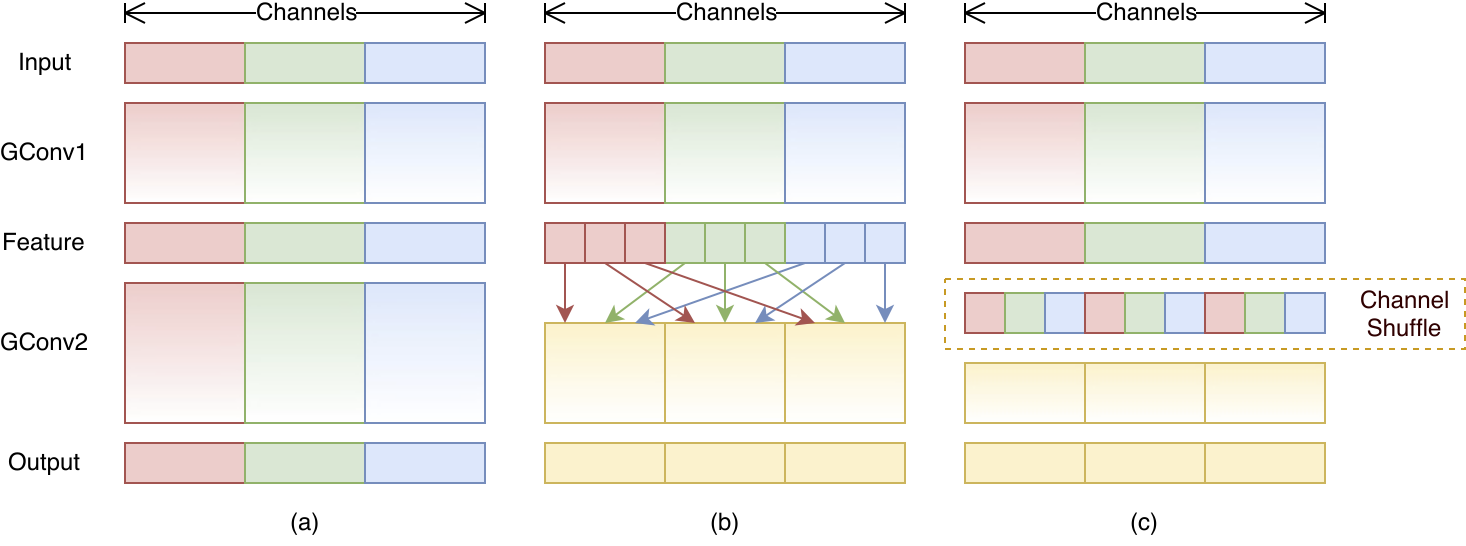
위 그림의 (a)가 방금 언급한 문제점입니다.
이를 해결하기 위해 저자는 channel shuffle 방법을 적용하였습니다.
channel shuffle은 각 그룹의 출력을 다른 그룹의 출력으로 제공하여 채널 간 정보 교환을 활성화하는 것입니다.
이것을 그림으로 보면 (c)에 해당합니다.
구체적인 방법은 아래와 같습니다.
- 출력 채널의 차원을 g × n으로 reshape을 합니다.
(g=현재 그룹의 개수, n=하위 그룹에서 한 그룹이 갖는 채널 수) - 채널 차원을 transpose하여 서로 다른 그룹과 연결
- flatten하여 다음 레이어의 입력 피쳐로 이동
이를 통해 채널 간 데이터의 흐름을 원활하게 유지하면서도 group convolution을 효과적으로 사용할 수 있다고 합니다.
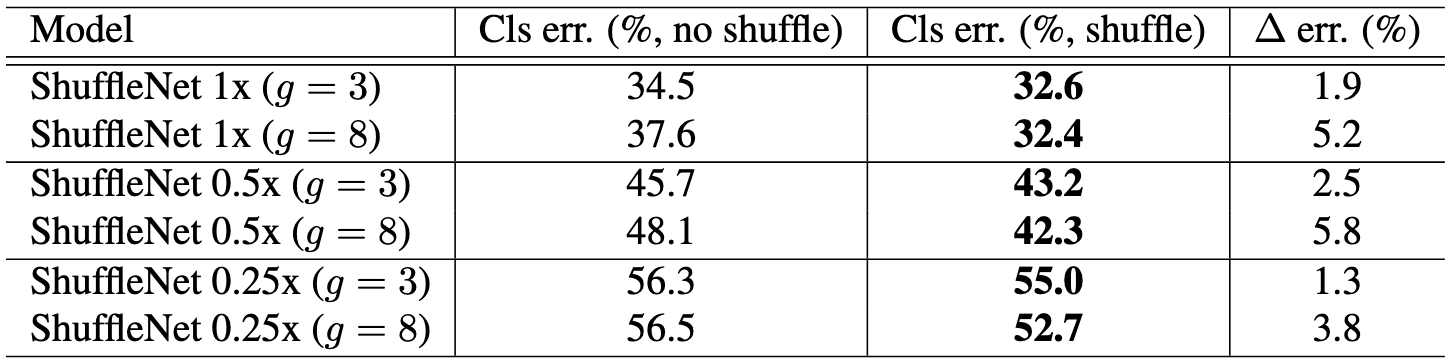
위 실험은 channel shuffle 유무에 따른 classification error 비교실험입니다.
그룹 수는 3과 8일 때로 분리하여 실험을 진행했는데, channel shuffle 방법을 사용했을 때 더 낮은 에러율을 보였음을 알 수 있습니다.
2.2. ShuffleNet Unit
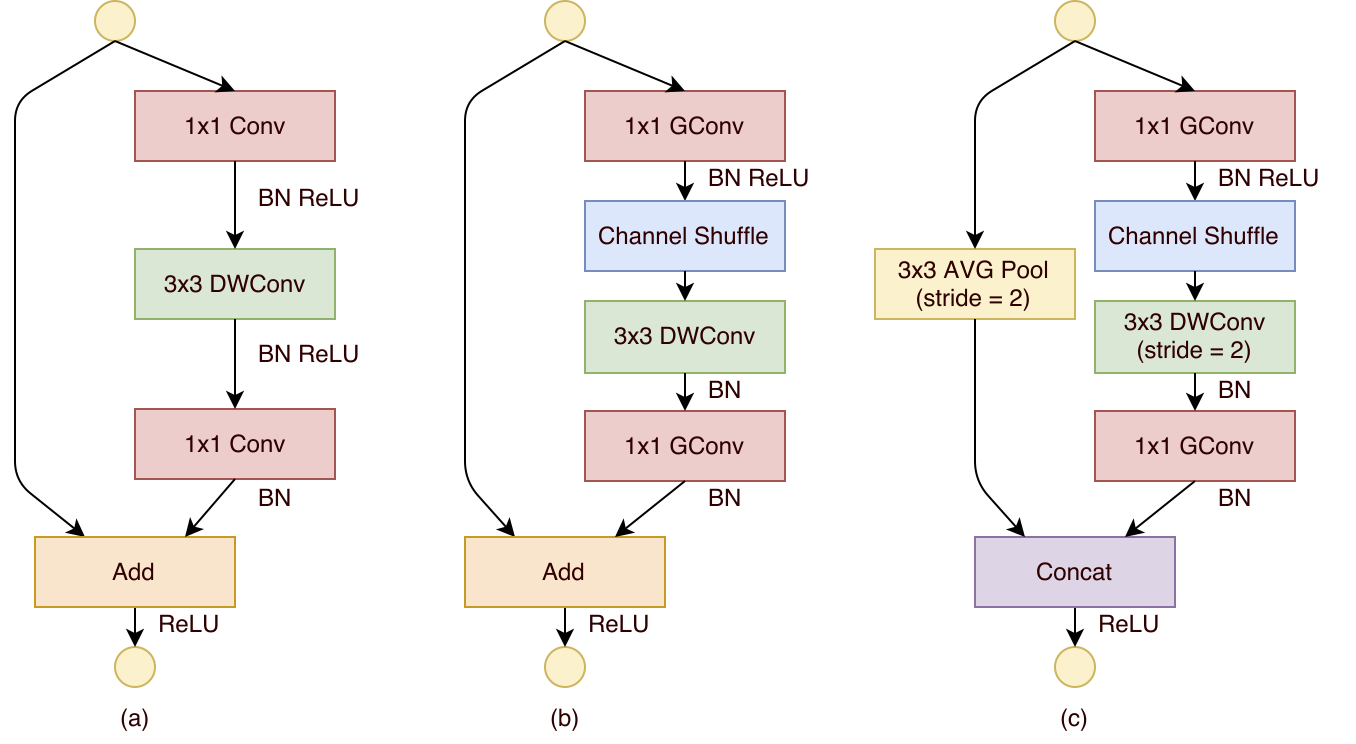
저자는 연산 비용을 낮추기 위해 channel shuffle 방법을 구현한 ShuffleNet 유닛을 연구하였습니다.
저자는 ResNet에서 사용된 병목 구조를 기반으로 3×3 합성곱을 depthwise convolution으로 대체하였습니다.
이 말을 그림으로 표현하면 위 그림의 (a)와 같습니다.
유닛 속의 1×1 합성곱은 1×1 group convolution으로 변경하였습니다.
그리고 첫 번째 1×1 합성곱을 pointwise group convolution과 channel shuffle로 변경하였습니다.
이 변환으로써 연산 비용을 낮출 수 있습니다.
그리고 두 번째 1×1 합성곱은 채널 수를 변환 전으로 돌리기 위한 것입니다.
하지만 두 번째 1×1 합성곱에서는 channel shuffle을 추가하지 않았습니다.
왜냐하면 적용하지 않아도 성능이 비슷하였기 때문에 적용하지 않았다고 합니다.
ReLU는 depthwise convolution 이후에서는 사용하지 않았다고 합니다.
만약 모델에 stride를 적용한다면 아래와 같은 변형이 필요합니다.
- shortcut 경로에 3×3 average pooling을 추가하여 크기를 줄인다.
- element-wise addition을 channel concatenation으로 대체하여, 연산 비용은 최소화하면서 채널 차원을 쉽게 확장할 수 있다.
그림으로 이해하면 위 그림의 (c)와 같습니다.
위 두 규칙을 따름으로써 stride를 적용할 수 있습니다.
2.3. Network Architecture
네트워크의 전반적인 구조는 다음 표와 같습니다.
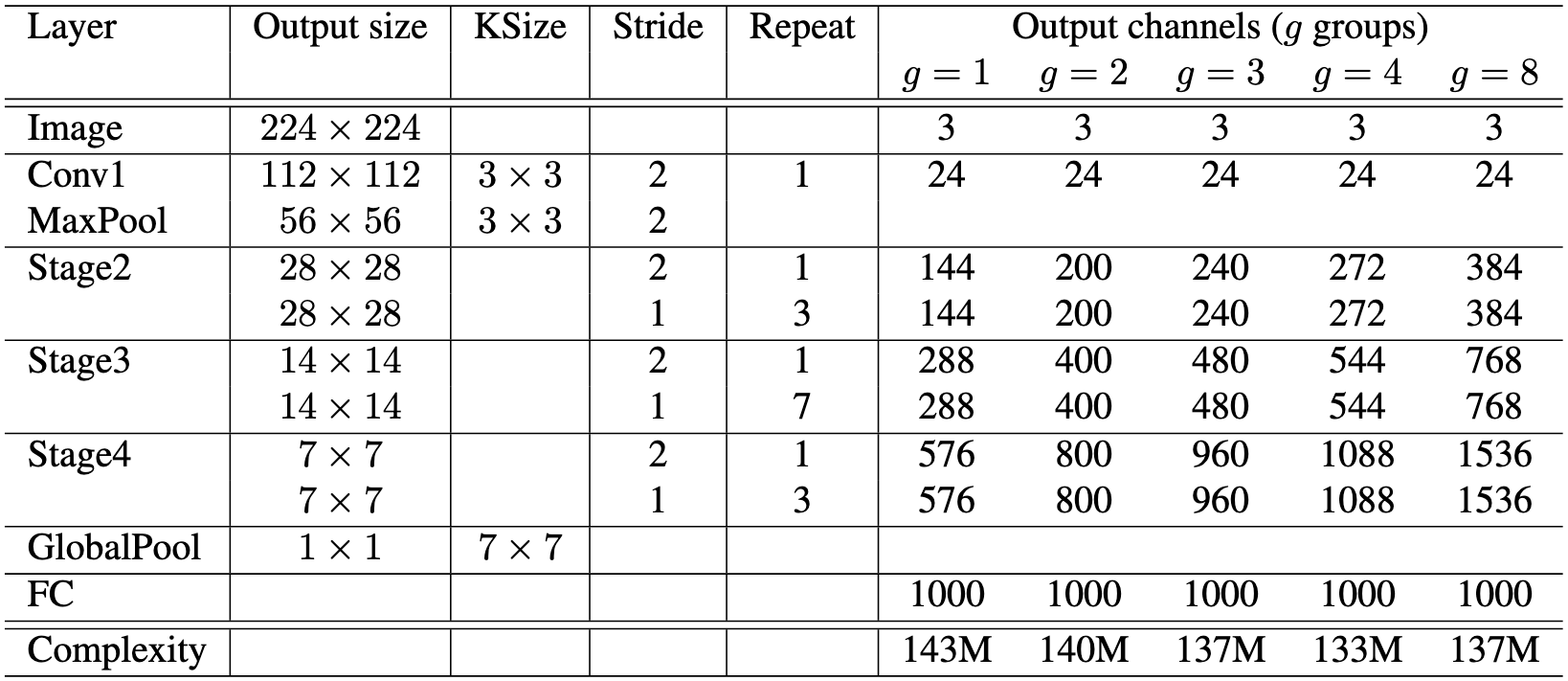
ShuffleNet은 3개의 주요 스테이지로 구성됩니다.
각 스테이지의 첫 번째 블록에서 stride=2를 적용하여 피쳐맵의 크기를 줄이는 역할을 합니다.
각 스테이지 내에서 하이퍼파라미터는 일정하게 유지됩니다.
다음 스테이지로 넘어갈 때는 출력 채널 수를 2배로 증가시킵니다.
그룹 수 는 pointwise group convolution의 연결 희소성을 결정합니다.
그룹 수 가 증가할수록 정해진 연산량 내에서 더 많은 출력 채널 수를 갖기 때문에 더 많은 피쳐를 가질 수 있습니다.
추가로 scaling factor 를 적용하여 채널 수를 조절할 수 있습니다.
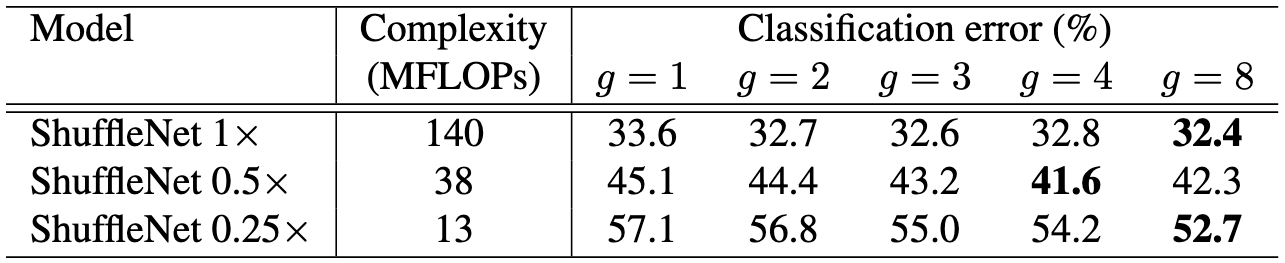
위 테이블을 보면 기본 모델을 "ShuffleNet 1×"으로 정의하고, 채널 수를 s배 곱한 모델을 "ShuffleNet s×"라고 정의하였습니다.
0.5배, 0.25배로 갈수록 classification error가 증가하는 것을 볼 수 있습니다.
또한 위 테이블에서 그룹 수 의 변화에 따른 classification의 변화도 확인할 수 있습니다.
그룹 수가 증가할수록 classification error가 감소함을 알 수 있는데, 이 감소는 그룹 수가 증가함으로 인해 channel shuffle할 그룹 수가 증가하여 channel shuffle이 더 적극적으로 일어나서 가능한 것입니다.
이라는 말은 channel shuffle이 일어나지 않음을 뜻합니다.
이 모델의 연산 비용은 대략 배입니다.
3. Experiments
저자는 VGGNet, ResNet, Xception, ResNeXt 모델들과 비교실험을 하였습니다.
이러한 complexity가 큰 모델들을 complexity가 작은 ShuffleNet과 비교하기 위해 모델들을 수정하여 complexity가 최대한 비슷하게 맞춰주어 같은 조건에서 비교하게 하였습니다.

위 테이블에서 볼 수 있듯, 같은 complexity일 때, classification error가 가장 낮음을 알 수 있습니다.
4. Conclusion
본 논문에서는 모바일 및 저전력 디바이스에서 높은 효율성을 갖춘 새로운 모델을 소개하였습니다.
ShuffleNet의 주요 기요는 pointwise group convolution을 사용하여 1×1 합성곱의 연산량을 줄였습니다.
또한 channel shuffle 방법을 사용해 group convolution의 채널 간 피쳐 교환을 활성화했습니다.
이러한 기여를 바탕으로 ShuffleNet은 연산 비용을 줄임으로써 모바일 및 저전력 디바이스에서 최적의 성능을 발휘할 수 있도록 하였습니다.
