
힙
- 힙(Heap) 자료구조는 다른 자료구조를 구현하는 기술 중 하나로 쓰인다.
- 힙 자료구조는 크게 2가지가 존재한다.
- 최소 힙 자료구조 : 최대값을 구하기 위해서 부모노드의 값을 자식노드의 값보다 항상 크게 트리를 만든다.
- 최대 힙 자료구조 : 최솟값을 구하기 위해서 부모노드의 값을 자식노드의 값보다 항삭 작게 트리를 만든다.
최대 힙
-
최대 힙(Max Heap)의 특징은 다음과 같다.
- 최대 힙은 부모노드가 자식노드보다 값이 큰 완전 이진트리를 의미한다(완전 이진트리란 자식노드의 최대 개수가 2개이며 리프 노드 간의 레벨 차이가 최대 1인 트리이다.)
- 부모노드의 모든 값이 자식노드보다 커야 한다.
- 최대 힙의 루트노드는 항상 최댓값을 가진다.
-
최대 힙의 루트노드는 항상 최댓값임을 보장한다.
-
트리구조를 사용하여 데이터를 추가하거나 삭제할 때 , 최댓값을 찾는 데 이 소요되는 매우 빠른 자료구조이다.
-
즉 최대 힙은 데이터의 삽입/삭제가 많을 때 최댓값을 정말 빠른 속도로 찾을 수 있는 자료구조이다.
-
최대 힙의 데이터 추가 모습을 보면,
- 처음 원소는 루트노드에 삽입한다.

- 그 후 노드는 완전 이진트리를 유지하는 형태로 데이터를 추가하면 된다.
- 3을 추가하면 다음과 같다.
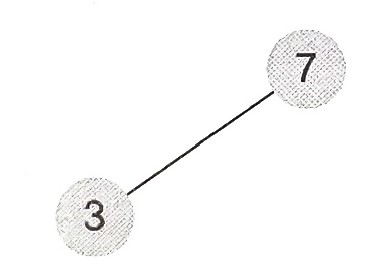
- 6을 추가하면 다음과 같다.

- 1, 2, 4까지 추가하면 다음과 같다.
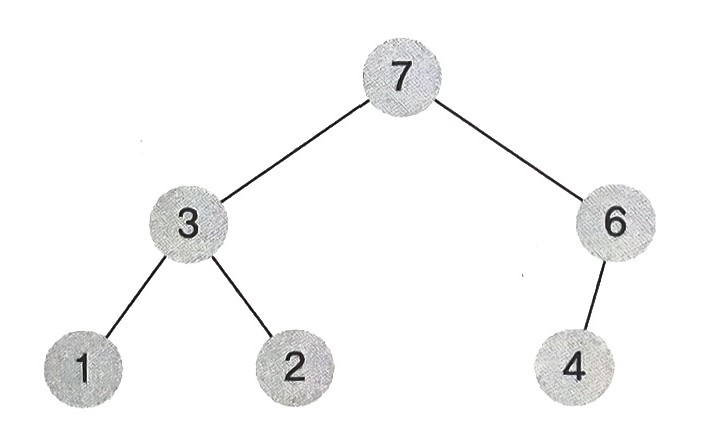
- 삽입할 원소가 8일 때, 완전 이진트리를 유지하는 형태로 8을 삽입한다.
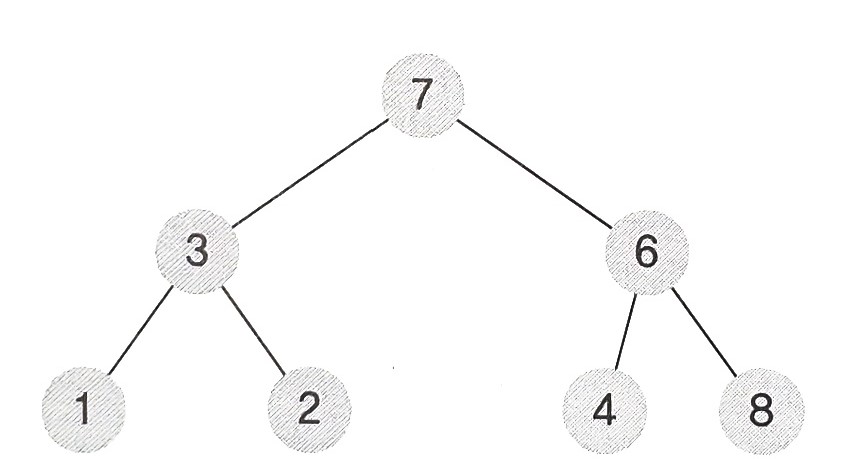
- 이때 삽입한 원소의 노드값보다 부모노드의 값이 크다면 모든 부모노드가 자식노드보다 값이 커야 한다는 최대 힙의 정의에 따라 부모노드와 삽입한 원소의 노드 위치를 바꾸어주어야 한다.
- 8의 부모노드 6은 8보다 작으므로 위치를 바꾼다.
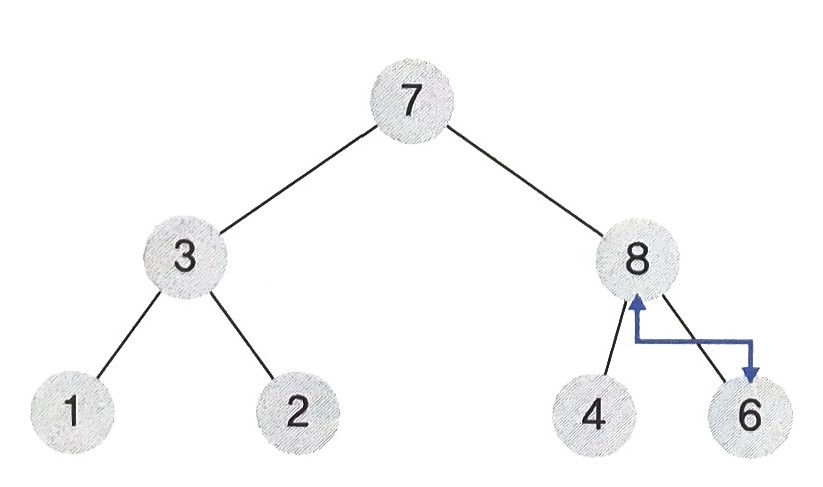
- 8의 부모노드 7은 8보다 작으므로 위치를 바꾼다.
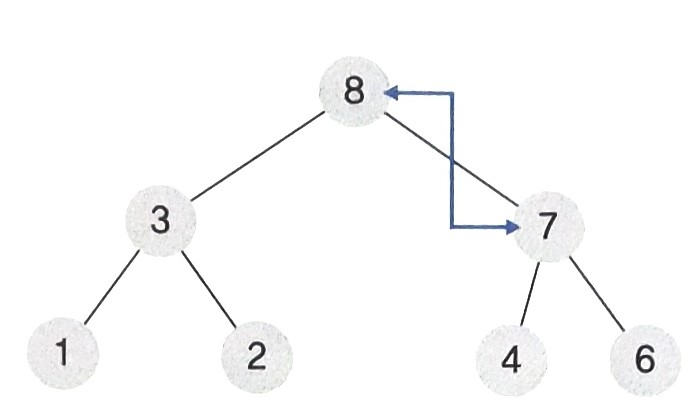
-
결과적으로 루트노드의 값은 8로, 8이 모든 노드 중에서 가장 큰 값임을 볼 수 있다.
-
데이터를 추가하고 원소의 값을 교체하는 데 소요되는 시간복잡도는 - (위 그림에서는 의 내림수=2) 인 반면에 최댓값을 (1)로 찾아낼 수 있다.
-
이를 통해 힙은 이러한 빠른 시간복잡도를 이용하여 우선순위 큐에 사용된다.
-
최대 힙의 데이터 삭제 모습을 보면,
-
최대 힙에서 데이터 삭제는 데이터값이 가장 큰 루트노드를 삭제함을 의미한다.
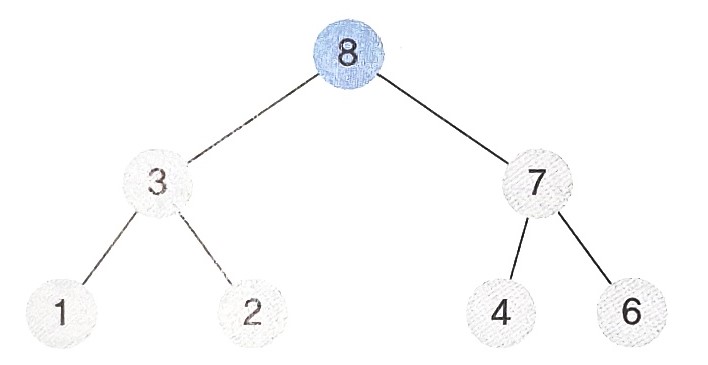
- 먼저 루트노드인 8을 삭제한다.
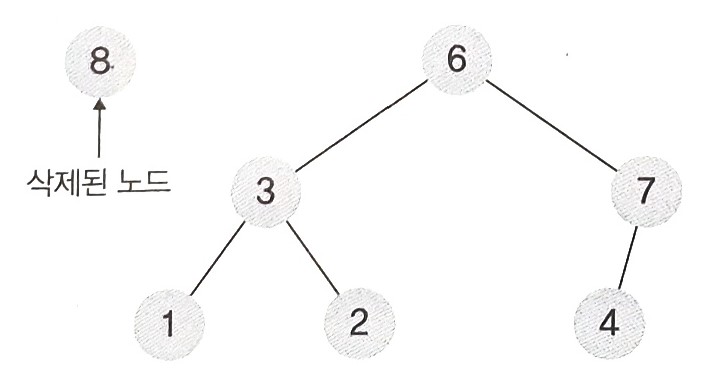
- 그 후 가장 밑에서 오른쪽에 있는 노드(가장 마지막에 삽입한 원소)를 루트노드에 위치시킨다.
- 위그림에서는 8을 제거하고 가장 밑에서 오른쪽에 있는 노드 6을 루트노드에 위치시켰다.
- 교체된 루트노드부터 시작하여 현재 노드보다 자식노드가 크다면 가장 큰 자식노드와 위치를 바꿔가며 위치를 바꿔준다.
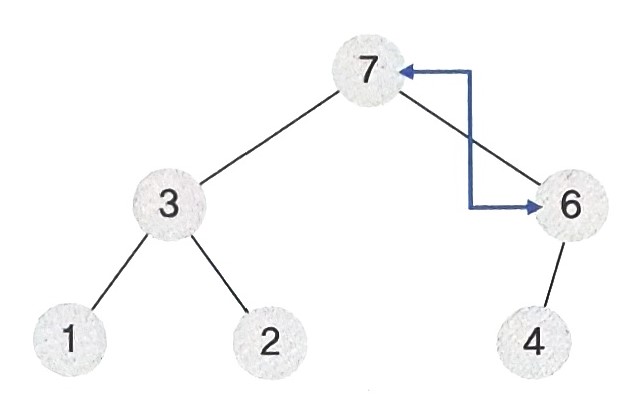
- 6의 자식노드 3, 7 중 7은 6보다 크기 때문에 위치를 바꿔준다.
- 6의 자식노드 4는 6보다 작으므로 위치를 바꿀 필요가 없다.
- 결과적으로 루트노드의 값은 7로, 7이 모든 노드 중에서 가장 큰 값임을 볼 수 있다.
-
데이터를 삭제할 때에도 소요되는 시간복잡도는 - (위 그림에서는 의 내림수 = 2)로 배열을 삭제할 때 에 비해 매우 빠른 효율성을 나타내며 삭제 시에도 루트노드는 최댓값을 가지는 특징이 있다.
최소 힙
-
최소 힙(Min Heap)의 특징은 다음과 같다.
- 최소 힙은 부모노드의 값이 자식노드보다 작은 완전 이진트리를 의미한다.
- 부모노드의 모든 값이 자식노드보다 작아야 한다.
- 최소 힙의 루트노드는 항상 최솟값을 가진다.
-
최소 힙의 데이터 추가 모습을 보자. => 최대 힙의 반대라고 생각하면 된다.
- 데이터 2를 먼저 루트노드에 넣은 후 완전 이진트리에 맞게 데이터를 삽입하면 아래 그림과 같아진다.
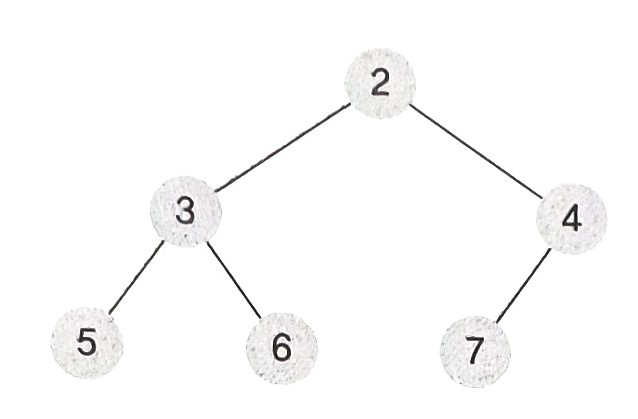
- 삽입할 원소가 1일 때, 완전 이진트리를 유지하는 형태로 1을 삽입한다(자식노드의 수가 최대 2개가 되며, 리프노드 간의 레벨 차이가 최대 1이 되도록 데이터를 삽입한다).
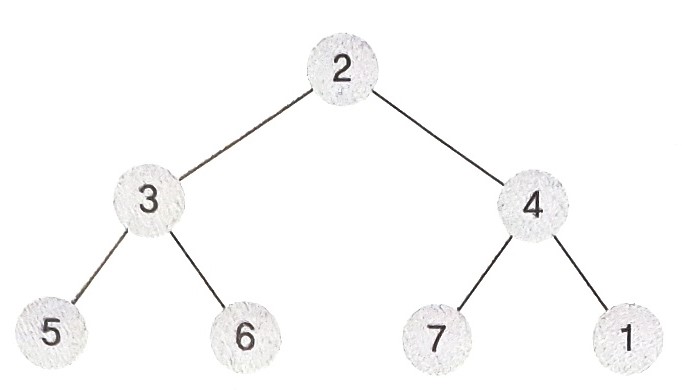
- 1은 부모노드인 4보다 값이 작으므로 최소 힙 규칙(모든 부모노드의 값이 자식노드보다 작아야 한다)에 따라 노드의 위치를 바꾸어 주어야 한다.
- 이후에는 루트노드까지 거슬로 올라가면서 최소 힙 규칙에 맞게 구성하면 된다.
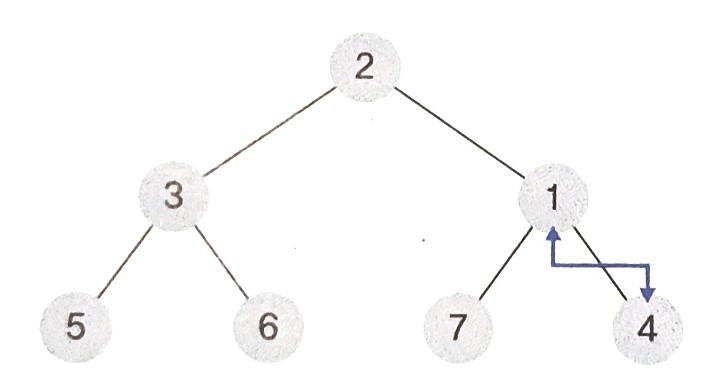
- 1의 부모노드는 4는 1보다 크므로 위치를 바꿔준다.
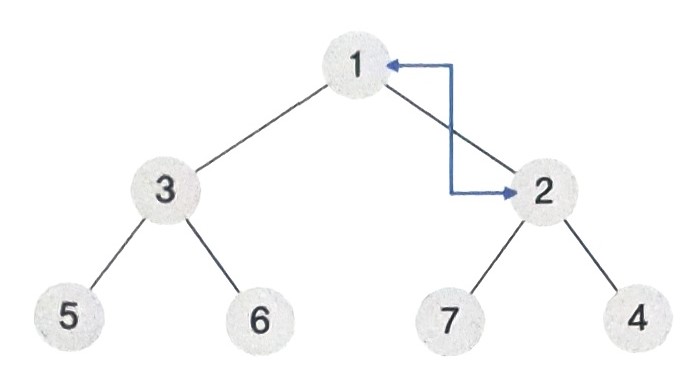
- 1의 부모노드 2는 1보다 크므로 위치를 바꿔 준다.
- 결과적으로 루트노드의 값은 1로, 1이 모든 노드 중에서 가장 작은 값임을 볼 수 있다.
-
이제 최소 힙의 데이터 삭제 모습을 보자.
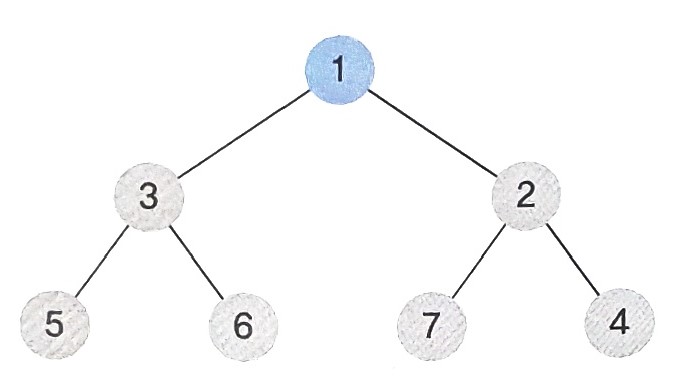
- 최소 힙에서 데이터 삭제는 데이터값이 가장 작은 루트노드를 삭제하는 것을 의미한다.
- 먼저 루트노드인 1을 삭제한다.
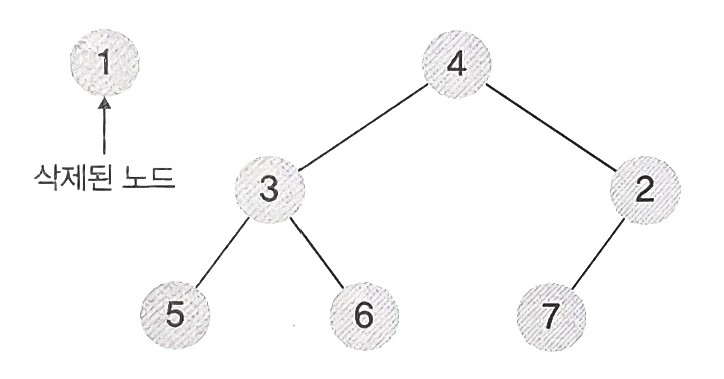
- 그 후 가장 밑에서 오른쪽에 있는 노드(가장 마지막에 삽인한 원소)를 루트노드에 위치시킨다.
- 교체된 류트노드부터 시작하여 현재 노드보다 자식노드가 작다면 가장 작은 자식노드와 위치를 바꿔가며 위치를 바꿔준다.
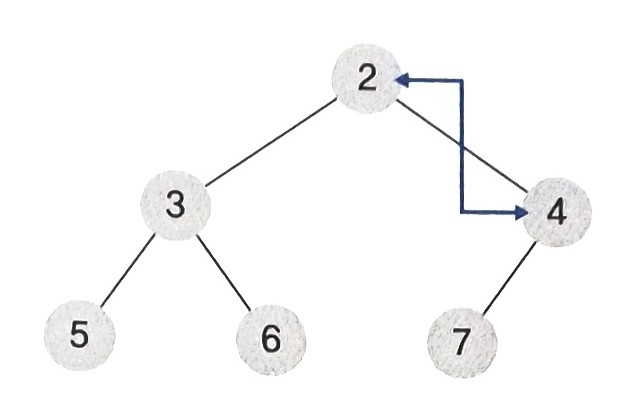
- 4의 자식노드 2, 3 중 3은 4보다 작기 때문에 위치를 바꿔준다.
- 4의 자식노드 7은 4보다 크므로 위치를 바꿀 필요가 없다.
- 결과적으로 루트노드의 값은 2로, 2가 모든 노드 중에서 가장 작은 값임을 볼 수 있다.
-
힙의 최솟값, 최댓값을 찾을 때 시간복잡도는 루트노드를 확인하면 되므로 이다.
-
데이터를 추가하거나 삭제할 때는 이진트리의 특성을 이용하여 부모노드와 자식노드를 바꾸는 과정을 번 반복한다.
-
노드의 자식은 최대 2개이므로 부모노드와 자식노드를 바꾸는 횟수가 1/2씩 줄어든다.
따라서 의 시간복잡도가 된다.
우선순위 큐
- 우선순위 큐(Priority Queue)는 데이터의 최댓값 혹은 최솟값을 삭제하는 경우가 번번하며 삭제를 해도 최댓값 혹은 최솟값을 로 확인하기 위한 자료구조이다.
- 입력과 삭제에는 가 소요되며 이때 데이터를 추가하든 삭제하든 항상 최댓값 혹은 최솟값을 로 확인할 수 있다는 장점이 있다.
- 스택과 큐, 우선순위 큐의 차이점을 살펴보면,
- 스택 : 가장 최근에 입력된 데이터가 가장 먼저 출력된다.
- 큐 : 가장 처음에 입력된 데이터가 가장 먼저 출력된다.
- 우선순위 큐 : 입력된 순서와 상관없이 우선순위가 높은 값이 가장 먼저 출력된다.
- 값이 큰 수에 우선순위를 높게 매긴다면, 최대 힙을 이용하여 항상 가장 큰 수를 루트노드에 오게 한다.
- 값이 작은 수에 우선순위를 높게 매긴다면, 최소 힙을 이용하여 가장 작은 수를 루트노드에 오게 한다.
- 힙 자료구조를 이용하여 우선순위 큐를 구현한다면 최댓값과 최솟값을 찾는데 의 시간복잡도가 소요된다.
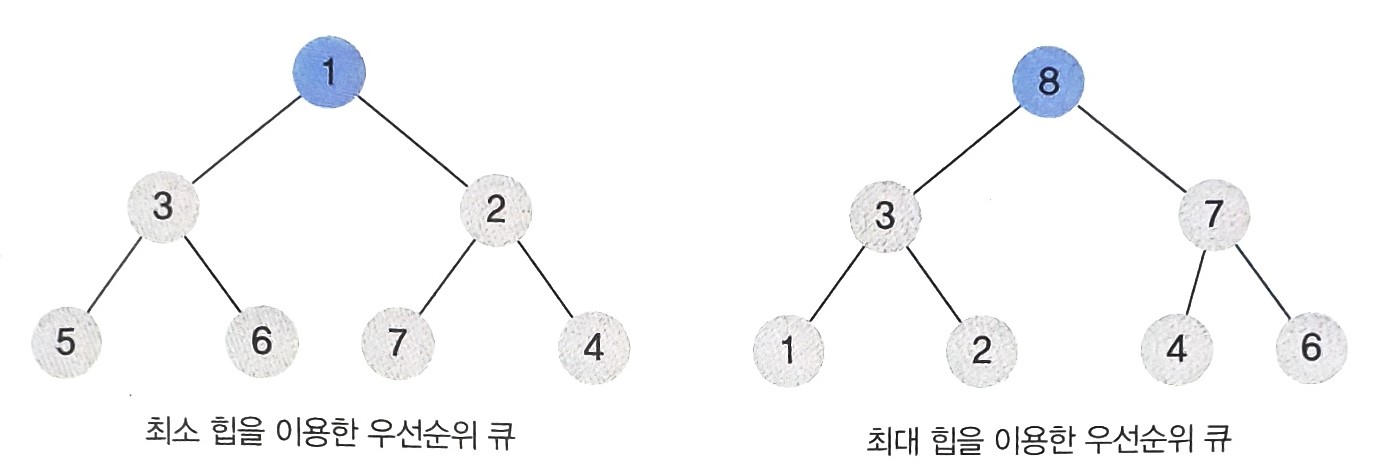
- 그리고 데이터를 추가하거나 삭제할 때에는 이진트리의 특성을 이용하여 부모노드와 자식 노드를 바꾸는 과정을 번 반복한다.
- 따라서 의 시간복잡도가 소요된다.
우선순위 큐를 사용하는 예제 1 - 최대 힙
- 우선순위 큐에서 주로 사용하는 기능은 3가지이다.
- 우선순위가 가장 높은 데이터값을 확인한다.
- 우선순위가 가장 높은 데이터값을 삭제한다(이때 2번째로 우선순위가 높은 데이터가 가장 높은 우선순위로 바뀌게 된다).
- 우선순위 큐에 데이터를 삽입한다.
[문제]
널리 잘 알려진 자료구조 중 최대 힙이 있다. 최대 힙을 이용하여 다음과 같이 연산을 지원하는 프로그램을 작성하시오.1. 배열에 자연수 x를 집어넣는다. 2. 배열에서 가장 큰 값을 출력하고, 그 값을 배열에서 제거한다.프로그램은 처음에 비어있는 배열에서 시작하게 된다.
[입력]
첫째 줄에 연산의 개수 이 주어진다. 다음 N개의 줄에는 연산에 대한 정보를 나타내는 정수 가 주어진다. 만약 가 자연수라면 배열에 라는 값을 넣는(추가하는) 연산이고, 가 0이라면 배열에서 가장 큰 값을 출력하고 그 값을 배열에서 제거하는 경우이다. 입력되는 자연수는 보다 작다.
[출력]
입력에서 0이 주어진 회수만큼 답을 출력한다. 만약 배열에 비어 있는 경우인데 가장 큰 값을 출력하라고한 경우에는 0을 출력하면 된다.
예제 입력 1 예제 출력 1 13 0 0 2 1 1 2 3 0 2 0 1 3 0 2 0 1 0 0 0 0 0
문제설명
번의 입력이 들어올 때 해당 입력이 자연수라면 우선순위 큐(최대 힙 이용)에 데이터를 삽입하고, 해당 입력이 0이라면 배열에서 가장 큰 값을 출력하고 그 값을 우선순위 큐(최대 힙 이용)에서 삭제하면 되는 문제이다.
- 일단 의 최댓값이 100,000이라고 했다.
1) 50,000 동안 자연수를 입력받아 배열에 차례대로 넣고
2) 50,000 동안 0을 입력받아 배열에서 가장 큰 값을 출력한 후, 그 값을 지운다면
- 우선순위 큐와 함께 위 문제를 해결한다면
1)의 과정에서 번의 연산이 필요하다.
2)의 과정에서 우선순위 큐의 크기 50,000중에서 최댓값을 찾고 삭제하는 데 의 연산이 필요하고 그것을 50,000번 반복하니 시간복잡도는 이 된다.
해답코드
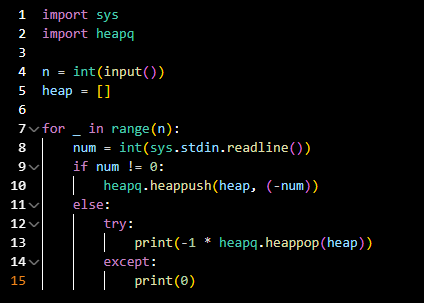
- 코드라인 2: 파이썬에서는 우선순위 큐 사용을 위해 heapq 라이브러리를 이용한다.
- 코드라인 5: heap 배열을 하나 만든다.
- 코드라인 8: 각각의 입력에 대하여
- 코드라인 9~10: 입력 데이터의 값이 자연수라면 우선순위 큐에 데이터를 추가한다. 파이썬의 경우 우선순위 큐를 이용하여 데이터를 삽입할 때
heapq.heappush(배열, 데이터값)의 형식으로 데이터를 추가한다. 위 코드에서는 num이 아닌 -num을 넣어줬는데 heapq 자체는 최소 힙을 기반으로 구현되어 있으므로 -num을 넣어줌으로써 가장 낮은 값을 힙의 루트에 위치해줬다. 이 후에 이 값을 다시 반전된 값인 -num을 통해 출력하면 된다. - 코드라인 11: 입력 데이터의 값이 0이라면
- 코드라인 12~13: 배열이 비어있지 않다면 가장 큰 값을 출력하고 우선순위 큐에서 삭제한다. 우선순위 큐를 이용하여 우선순위가 가장 높은 데이터를 삭제할 때
heapq.heappop(배열)의 형식을 이요한다. 이때 출력할 때는 -1을 곱하여 출력했는데, 코드라인 9~10에서 말했듯이 최소 힙에서 최대 힙을 사용하기 위해 반전화해 둔 값을 다시 원상으로 복귀한 것이다. - 코드라인 14~15: 배열이 비어 있는 경우 0을 출력한다.
- 코드라인 12~13: 배열이 비어있지 않다면 가장 큰 값을 출력하고 우선순위 큐에서 삭제한다. 우선순위 큐를 이용하여 우선순위가 가장 높은 데이터를 삭제할 때
우선순위 큐를 사용하는 예제 2 - 카드 정렬하기
[문제]
정렬된 두 묶음의 숫자 카드가 있다고 하자. 각 묶음의 카드의 수를 A, B라 하면 보통 두 묶음을 합쳐서 하나로 만드는 데에는 ㅁA+B번의 비교를 해야 한다. 이를테면, 20장의 숫자 카드 묶ㅁ음과 30장의 숫자 카드 묶음을 합치려면 50번의 비교가 필요하다.매우 많은 숫자 카드 묶음이 책상 위에 놓여 있다. 이들을 두 묶음씩 골라 서로 합쳐나간다면, 고르는 순서에 따라서 비교 횟수가 매우 달라진다. 예를 들어 10장, 20장, 40장의 묶음이 있다면 10장과 20장을 합친 뒤, 합친 30장 묶음과 40장을 합친다면 (10+20)+(30+40)=100번의 비교가 필요하다. 그러나 10장과 40장을 합친 뒤, 합친 50장 묶음을 20장을 합친다면 (10+40)+(50+20)=120번의 비교가 필요하므로 덜 효율적인 방법이다.
N개의 숫자 카드 묶음의 각각의 크기가 주어질 때, 최소한 몇 번의 비교가 필요한지를 구하는 프로그램을 작성하시오.
[입력]
첫째 줄에 N이 주어진다. 이어서 N개의 줄에 걸처 숫자 카드 묶음의 각각의 크기가 주어진다. 숫자 카드 묶음의 크기는 1,000보다 작거나 같은 양의 정수이다.
[출력]
첫째 줄에 최소 비교 횟수를 출력한다.
예제 입력 1 예제 출력 1 3 100 10 20 40
문제설명
n개의 정수가 입력으로 들어오며, 두 정수 A, B를 합치는데 A+B의 비교가 필요하다. n개의 정수를 합쳐 1개로 만드는 데 피룡한 최소 비교횟수를 구하는 문제이다.
- 예제의 n=3이고 정수가 10, 20, 40일 때
-
10과 40을 합치고
10 + 40 = 50
합친 값과 20을 합친다면
50 + 20 = 70
총 120번의 비교를 하게 된다. -
10과 20을 합치고
10 + 20 = 30
합친 값과 40을 합친다면
30 + 40 = 70
총 100번의 비교를 하게 된다.
- 계속 다른 비교횟수가 나오는 이유는 정수를 합치는 과정에서 이전에 합한 값이 다시 사용되기 때문이다.
해답코드
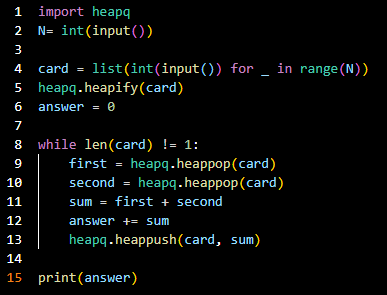
- 코드라인 1: 우선순위 큐 사용을 위해 heapq 모듈을 import하여 이용한다.
- 코드라인 2~4: n개의 카드를 입력받는다.
- 코드라인 5: n개의 카드를 힙으로 변환한다.
- 코드라인 8: 조심해야 할 부분으로 카드의 개수가 1이 아닐 때까지 반복문을 돌린다(n이 1이라면 answer=0이 된다).
- 코드라인 9~10: 우선순위 큐에서 가장 작은 값 2개를 꺼낸다.
- 코드라인 11~12: 합친 값을 정답 answer에 더해준다.
- 코드라인 13: 합친 값을 우선순위 큐에 다시 넣어준다.
- 코드라인 15: 정답을 출력한다.
