`
Persistence Layer
Persistence Layer(영속성 계층)는 소프트웨어 아키텍처에서 애플리케이션 데이터가 데이터베이스 또는 파일 시스템과 같은 영구 저장소에 저장되고, 필요 시 이를 검색하거나 수정하는 계층을 말합니다. Persistence Layer는 비즈니스 로직과 데이터 저장소 간의 중간 다리 역할을 하며, 데이터 접근과 관리를 책임집니다.
1. Persistence Layer의 역할
Persistence Layer는 데이터 저장소와 애플리케이션의 다른 계층 간의 분리와 추상화를 제공합니다. 주요 역할은 다음과 같습니다:
- 데이터 저장 및 검색
- 데이터베이스에 데이터를 저장하거나 불러오는 작업을 담당합니다.
- 데이터 접근 로직 캡슐화
- 데이터베이스의 구조와 접근 방식을 추상화하여 애플리케이션 코드에서 직접적으로 의존하지 않도록 만듭니다.
- 비즈니스 계층과 데이터 계층 분리
- 데이터 접근 로직을 Persistence Layer로 이동함으로써 비즈니스 로직과 데이터 로직을 분리합니다.
- 데이터 무결성 유지
- 트랜잭션 처리와 같은 작업을 통해 데이터의 일관성을 보장합니다.
- ORM (Object-Relational Mapping) 지원
- 객체지향 언어(Java 등)와 관계형 데이터베이스 간의 데이터 매핑을 처리합니다.
2. Persistence Layer의 구성 요소
Persistence Layer는 주로 다음 요소들로 구성됩니다:
-
DAO (Data Access Object)
- 데이터베이스와 상호작용하는 인터페이스.
- SQL 쿼리나 저장 프로시저를 실행하여 데이터를 저장, 수정, 삭제, 검색.
예시:
public interface UserDao { void saveUser(User user); User getUserById(int id); } -
Repository
- Spring Data JPA 등에서 자주 사용되는 접근 방식으로, DAO보다 추상화된 계층.
- 주로 JPA를 사용해 CRUD 작업을 제공합니다.
예시:
public interface UserRepository extends JpaRepository<User, Long> {} -
ORM (Object-Relational Mapping)
- 객체지향 프로그래밍 언어와 관계형 데이터베이스 간의 데이터 변환을 처리.
- Hibernate, JPA(Java Persistence API) 등이 대표적인 ORM 기술.
예시 (JPA 사용):
@Entity public class User { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id; private String name; private String email; } -
Data Source
- 데이터베이스 연결을 설정하고 관리.
- JDBC 또는 JNDI를 사용하여 데이터 소스를 정의.
예시 (Spring Boot 설정):
spring: datasource: url: jdbc:mysql://localhost:3306/mydb username: user password: pass -
Transaction Management
- 트랜잭션을 관리하여 데이터 무결성을 보장.
- Spring Framework의
@Transactional어노테이션을 자주 사용.
예시:
@Transactional public void updateUser(User user) { userRepository.save(user); }
3. Persistence Layer의 기술 및 도구
Persistence Layer는 다양한 기술 및 도구를 활용해 구현할 수 있습니다:
| 기술/도구 | 설명 |
|---|---|
| JDBC | Java에서 데이터베이스와 직접 상호작용하는 저수준 API. |
| Hibernate | Java의 대표적인 ORM 프레임워크. |
| JPA | Java에서 ORM을 위한 표준 인터페이스. Hibernate로 구현 가능. |
| Spring Data JPA | JPA를 더욱 간단하게 사용할 수 있는 Spring Framework 모듈. |
| MyBatis | SQL Mapper 프레임워크로, SQL과 매핑된 객체 간의 상호작용을 제공. |
| Dapper | .NET 환경에서 경량 ORM으로 사용. |
4. Persistence Layer 설계 시 고려사항
- 성능 최적화
- 적절한 캐싱 메커니즘 사용 (e.g., Hibernate의 1차/2차 캐시).
- 복잡한 쿼리를 실행하기 전에 필요한 데이터만 가져오는 전략 필요.
- 데이터 무결성
- 트랜잭션 관리 및
동시성문제 해결. - 데이터베이스 레벨의
무결성제약(Unique, Foreign Key 등)을 활용.
- 트랜잭션 관리 및
- 확장성
- DAO와 Service 계층 간 인터페이스를 통해 유연한 설계.
- 데이터 저장소 변경 시에도 최소한의 수정으로 대응 가능하도록 추상화.
- 테스트 가능성
- Mock 데이터베이스 또는 In-Memory 데이터베이스(H2)를 사용해 유닛 테스트 구현.
- 보안
- SQL 인젝션 방지 (PreparedStatement 또는 ORM 사용).
- 민감한 데이터 암호화 및 접근 제어 설정.
5. Persistence Layer 구현 예제
(1) DAO 패턴
public class UserDaoImpl implements UserDao {
private JdbcTemplate jdbcTemplate;
public UserDaoImpl(JdbcTemplate jdbcTemplate) {
this.jdbcTemplate = jdbcTemplate;
}
@Override
public User getUserById(int id) {
String sql = "SELECT * FROM users WHERE id = ?";
return jdbcTemplate.queryForObject(sql, new Object[]{id}, new BeanPropertyRowMapper<>(User.class));
}
}
(2) JPA를 활용한 Repository
@Repository
public interface UserRepository extends JpaRepository<User, Long> {
User findByEmail(String email);
}
(3) Service와 연계
@Service
public class UserService {
@Autowired
private UserRepository userRepository;
public User getUserById(Long id) {
return userRepository.findById(id).orElseThrow(() -> new RuntimeException("User not found"));
}
}
1. JPA란?
- JPA(Java Persistence API)는 Java에서 객체를 관계형 데이터베이스에 매핑(ORM: Object-Relational Mapping)하기 위한 표준 인터페이스입니다.
- JPA는
데이터베이스 작업을 객체지향적으로 처리할 수 있도록 도와주며, SQL의 직접 작성 필요성을 줄이고 생산성을 높입니다.
2. JPA의 주요 특징
| 특징 | 설명 |
|---|---|
| ORM(Object-Relational Mapping) | 자바 객체와 데이터베이스 테이블 간의 자동 매핑을 제공. |
| 표준 인터페이스 제공 | Hibernate, EclipseLink 등 다양한 구현체에서 동작하도록 표준화된 API를 제공. |
| JPQL(Java Persistence Query Language) | SQL과 유사한 문법을 가진 객체 중심의 질의 언어. |
| 트랜잭션 관리 | 트랜잭션을 간단히 관리할 수 있는 기능을 제공. |
| 캐싱 지원 | 1차 캐시(EntityManager)와 2차 캐시(Cache Provider)를 통한 성능 최적화. |
| Lazy/Eager Loading | 데이터 로드 전략 설정 (지연 로딩 / 즉시 로딩). |
| DB 독립성 | 특정 DBMS에 종속되지 않고 다수의 데이터베이스에서 사용할 수 있음. |
3. JPA의 동작 원리
JPA에서 데이터 저장 및 조회 과정
- Entity 객체 생성: 데이터를 표현하는 객체(Entity)를 정의.
- EntityManager:
- JPA의 핵심 인터페이스로, Entity의 상태를 관리.
- 데이터베이스와의 연결 및 CRUD 작업 처리.
- Persistence Context:
EntityManager에서 관리하는 객체들의 집합.- 1차 캐시를 활용하여 같은 트랜잭션 내에서 동일 객체 재사용.
!https://velog.velcdn.com/images/gudonghee2000/post/03891a93-b797-4bd6-983a-89954382f449/image.png
4. JPA의 구조
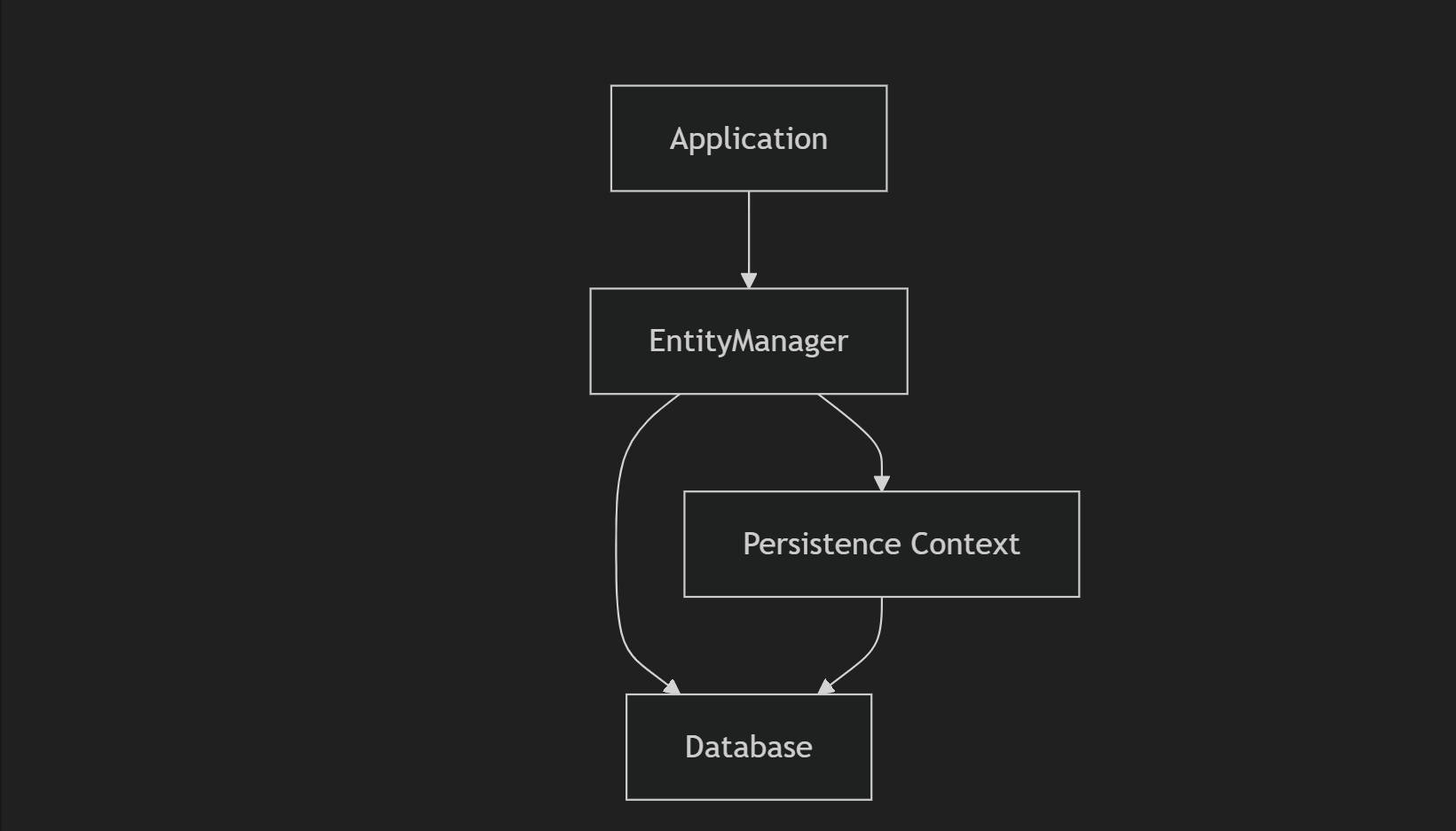
- EntityManager: JPA의 핵심 역할, 애플리케이션과 데이터베이스 간 데이터 접근을 중재.
- Persistence Context:
1차 캐시역할로, 동일 객체를 반복적으로 데이터베이스에서 조회하지 않음. - Database: 실제 데이터가 저장되는 관계형 데이터베이스.

Hibernate란?
- Hibernate는 JPA(Java Persistence API)의
구현체 중 하나로, 객체지향 프로그래밍과 관계형 데이터베이스 간의 매핑을 지원하는 강력한 ORM(Object-Relational Mapping) 프레임워크입니다. - 데이터베이스와의 상호작용을 객체 중심으로 처리할 수 있도록 하며, JPA 표준을 기반으로 추가적인 기능과 성능 최적화를 제공합니다.
Hibernate의 주요 특징
| 특징 | 설명 |
|---|---|
| JPA 구현체 | JPA 표준 API를 구현하여 JPA 기능을 사용할 수 있음. |
| HQL (Hibernate Query Language) | 객체를 기반으로 한 SQL 유사 질의 언어 제공. |
| 캐싱 지원 | 1차 캐시(세션)와 2차 캐시(Ehcache, Hazelcast 등) 제공. |
| 데이터베이스 독립성 | SQL Dialect를 사용하여 다양한 데이터베이스 지원. |
| Lazy/Eager Loading | 연관된 데이터를 지연 로딩(Lazy Loading) 또는 즉시 로딩(Eager Loading) 설정 가능. |
| Auto Schema Generation | 애플리케이션 실행 시 데이터베이스 테이블 생성 및 업데이트 자동화. |
| 추상화된 데이터 접근 | 데이터 접근 코드의 중복을 줄이고 객체 중심으로 설계 가능. |
Hibernate와 JPA의 관계
- Hibernate는 JPA의 구현체로, JPA 표준에서 제공하는 기능 외에도 Hibernate 고유의 확장 기능을 제공합니다.
- JPA 표준만 사용하는 경우 다른 JPA 구현체로 쉽게 교체 가능하지만, Hibernate 고유의 기능을 사용하면 특정 구현체에 종속될 수 있습니다.
| 항목 | JPA | Hibernate |
|---|---|---|
| 표준 여부 | Java EE 표준 API | JPA의 구현체 |
| 쿼리 언어 | JPQL(Java Persistence Query Language) | HQL(Hibernate Query Language) |
| 기능 | 표준화된 기능 제공 | 캐싱, 데이터베이스 다이얼렉트 등 고유 기능 제공 |
| 사용성 | 독립적인 추상화 계층 | JPA 기능 외의 확장된 기능 사용 가능 |
Hibernate의 주요 구성 요소
| 구성 요소 | 설명 |
|---|---|
| Configuration | Hibernate 설정을 담당하며, 데이터베이스 연결 정보 및 매핑 정보를 정의. |
| Session | 데이터베이스와의 연결을 관리하며, 객체의 영속성 상태를 유지하는 인터페이스. |
| SessionFactory | 세션을 생성하는 팩토리 역할, 애플리케이션당 하나만 생성. |
| Transaction | 트랜잭션 관리 및 작업의 원자성을 보장. |
| Query | HQL 또는 SQL을 실행하는 객체. |
Hibernate의 동작 과정
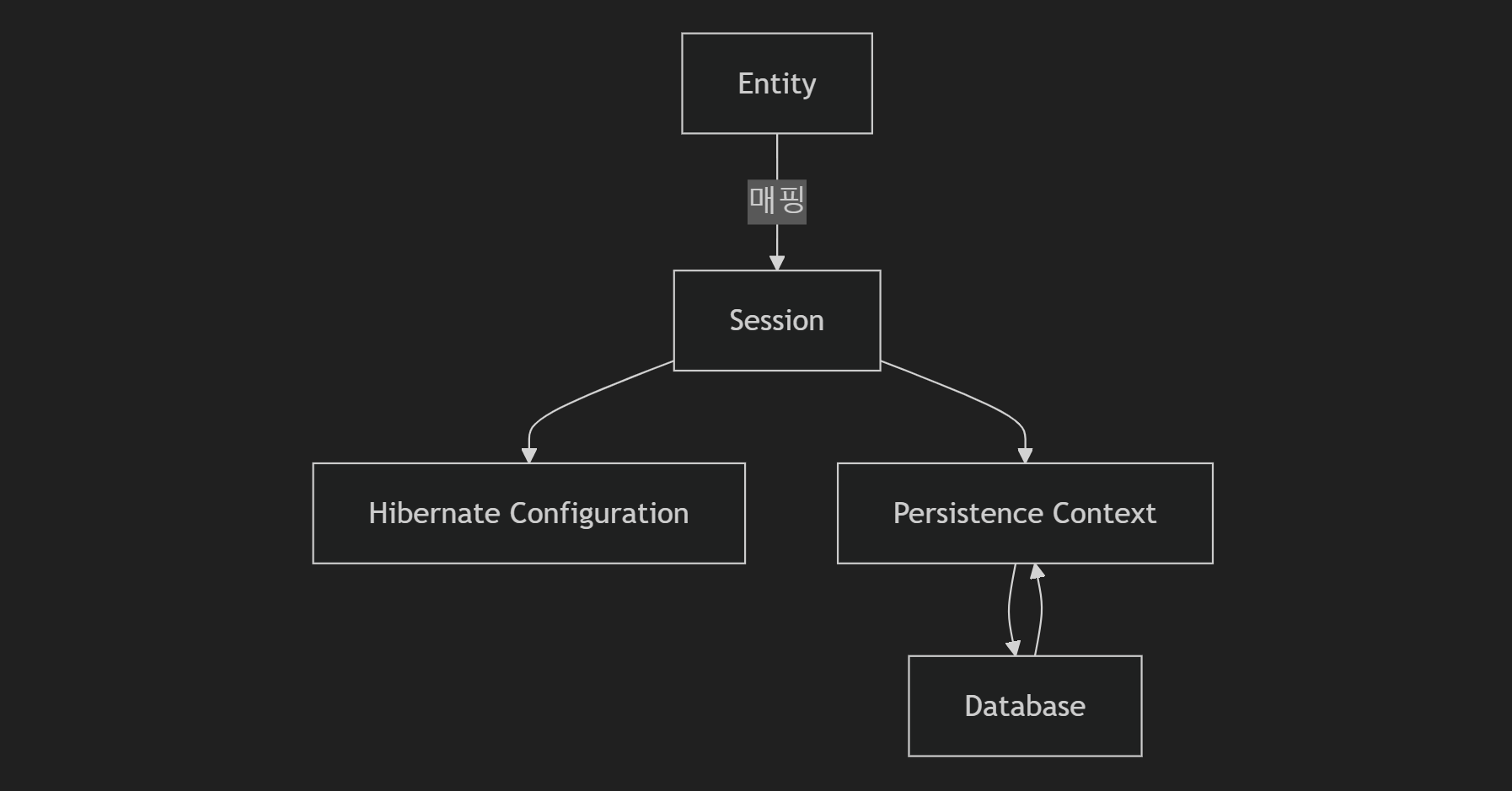
- Entity: 객체와 데이터베이스 테이블 간의 매핑을 정의.
- Session: Hibernate와 데이터베이스 간의 연결 및 작업을 수행.
- Persistence Context: 세션이 관리하는 1차 캐시 영역.
- Database: 실제 데이터를 저장하는 관계형 데이터베이스.
Hibernate의 핵심 개념
(1) Entity
- 데이터베이스 테이블에 매핑되는 클래스.
@Entity
@Table(name = "users")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false)
private String name;
@Column(unique = true)
private String email;
}
(2) Session
- Hibernate의 단일 데이터베이스 작업 단위.
- CRUD 작업 수행:
Session session = sessionFactory.openSession();
Transaction tx = session.beginTransaction();
User user = new User();
user.setName("홍길동");
user.setEmail("hong@example.com");
session.save(user);
tx.commit();
session.close();
(3) HQL
- SQL과 유사하지만, 테이블 대신 엔티티 객체를 사용.
String hql = "FROM User WHERE email = :email";
User user = session.createQuery(hql, User.class)
.setParameter("email", "hong@example.com")
.uniqueResult();
Hibernate 설정 파일
(1) persistence.xml 설정
Spring Data JPA를 사용할 때 persistence.xml은 JPA 표준 방식의 설정 파일로 사용할 수 있지만, Spring Boot에서는 보통 application.properties 또는 application.yml을 사용해 설정을 간소화합니다. 그러나 프로젝트 환경에 따라 persistence.xml 파일이 필요할 때도 있습니다.
- JPA 표준에서 정의된 설정 파일로, JPA에서 사용하는 Entity 클래스, 데이터베이스 연결 정보, JPA 구현체(Hibernate 등) 설정 등을 정의합니다.
META-INF/persistence.xml경로에 위치해야 합니다.
<?xml version="1.0" encoding="UTF-8"?>
<persistence xmlns="http://xmlns.jcp.org/xml/ns/persistence" version="2.2">
<persistence-unit name="jpabegin" transaction-type="RESOURCE_LOCAL">
<class>com.example.jpa.domain.User</class>
<exclude-unlisted-classes>true</exclude-unlisted-classes>
<properties>
<!-- 필수 속성 -->
<property name="jakarta.persistence.jdbc.driver" value="org.mariadb.jdbc.Driver"/>
<property name="jakarta.persistence.jdbc.url" value="jdbc:mariadb://localhost:3306/sample"/>
<property name="jakarta.persistence.jdbc.user" value="root"/>
<property name="jakarta.persistence.jdbc.password" value="!123456"/>
<!-- 옵션 속성 -->
<!-- hikari pooling 환경 설정 -->
<property name="hibernate.hikari.poolName" value="pool"/>
<property name="hibernate.hikari.maximumPoolSize" value="10"/>
<property name="hibernate.hikari.maximumIdle" value="10"/>
<property name="hibernate.hikari.connectionTimeout" value="1000"/>
<!-- JPA 기본 환경 : 기본값 -->
</properties>
</persistence-unit>
</persistence>
(2) application.properties (Spring Boot 사용 시)
spring.datasource.driver-class-name=org.mariadb.jdbc.Driver
spring.datasource.url=jdbc:mariadb://localhost:3306/sample
spring.datasource.username=root
spring.datasource.password=!123456
spring.jpa.hibernate.ddl-auto=update
spring.jpa.properties.hibernate.dialect=org.hibernate.dialect.MySQL8Dialect
Spring Data JPA 개요
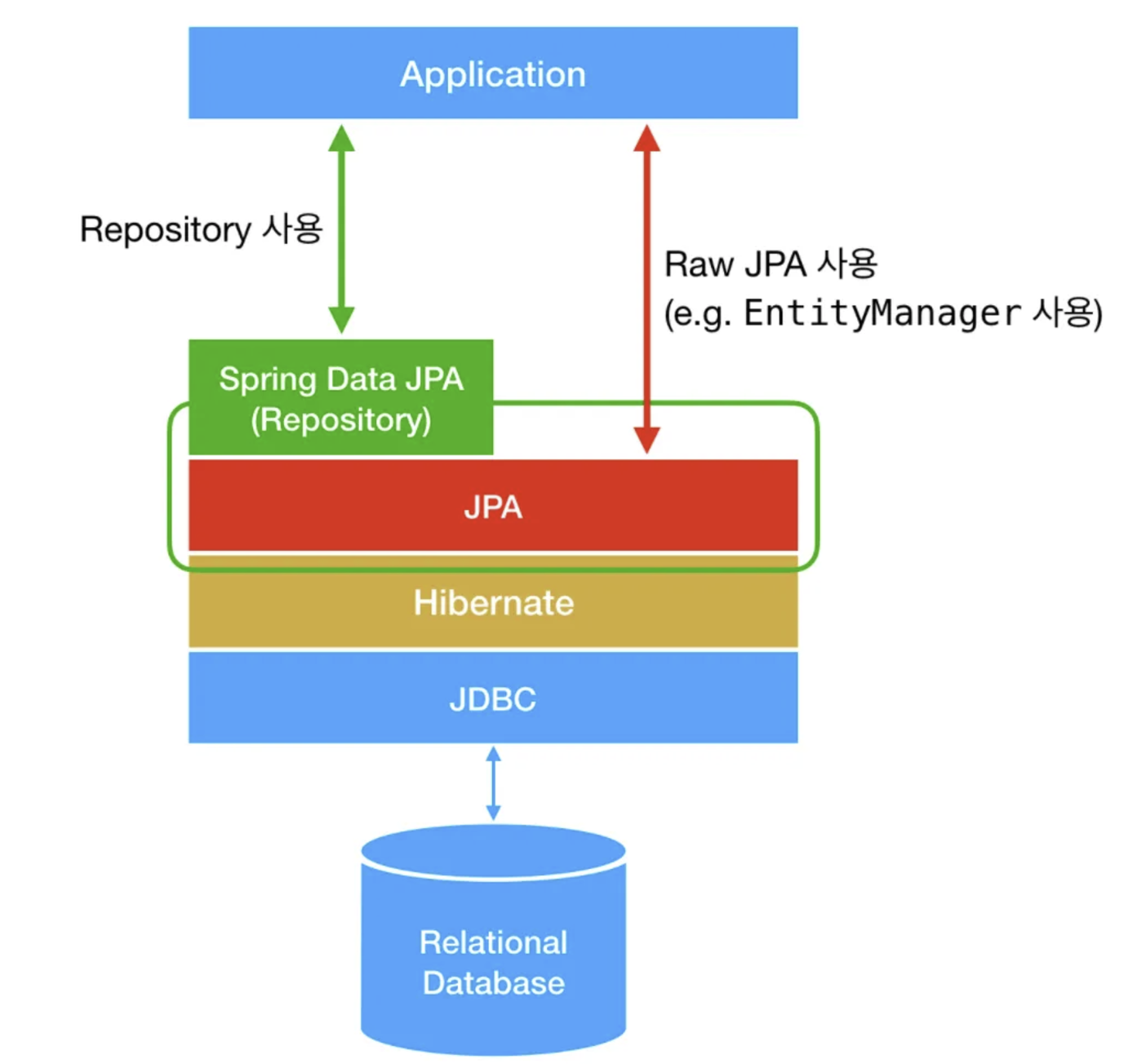
Spring Data JPA는 Spring Framework의 데이터 접근 계층 모듈로, JPA(Java Persistence API)를 더 쉽고 간단하게 사용할 수 있도록 추상화한 도구입니다. 기존 JPA를 사용할 때 반복적인 코드를 줄이고, Repository 인터페이스와 간단한 메서드 이름만으로 CRUD, 페이징, 정렬 등을 쉽게 구현할 수 있습니다.
!https://kha0213.github.io/assets/images/study/spring-data-jpa-ex.png
1. Spring Data JPA의 특징
| 특징 | 설명 |
|---|---|
| 간단한 데이터 접근 | JpaRepository 인터페이스를 통해 CRUD와 페이징, 정렬을 자동화. |
| 쿼리 메서드 | 메서드 이름만으로 동작하는 쿼리를 자동 생성. |
| JPQL 및 네이티브 SQL 지원 | 복잡한 쿼리의 경우 JPQL(Java Persistence Query Language) 또는 네이티브 SQL을 사용 가능. |
| 페이징 및 정렬 지원 | 페이징(Pageable)과 정렬(Sort)을 기본 제공. |
| JPA 구현체 독립성 | Hibernate, EclipseLink 등 다양한 JPA 구현체와 호환 가능. |
| 트랜잭션 관리 통합 | Spring의 @Transactional을 통해 트랜잭션을 간단히 관리 가능. |
Spring Data JPA의 구조
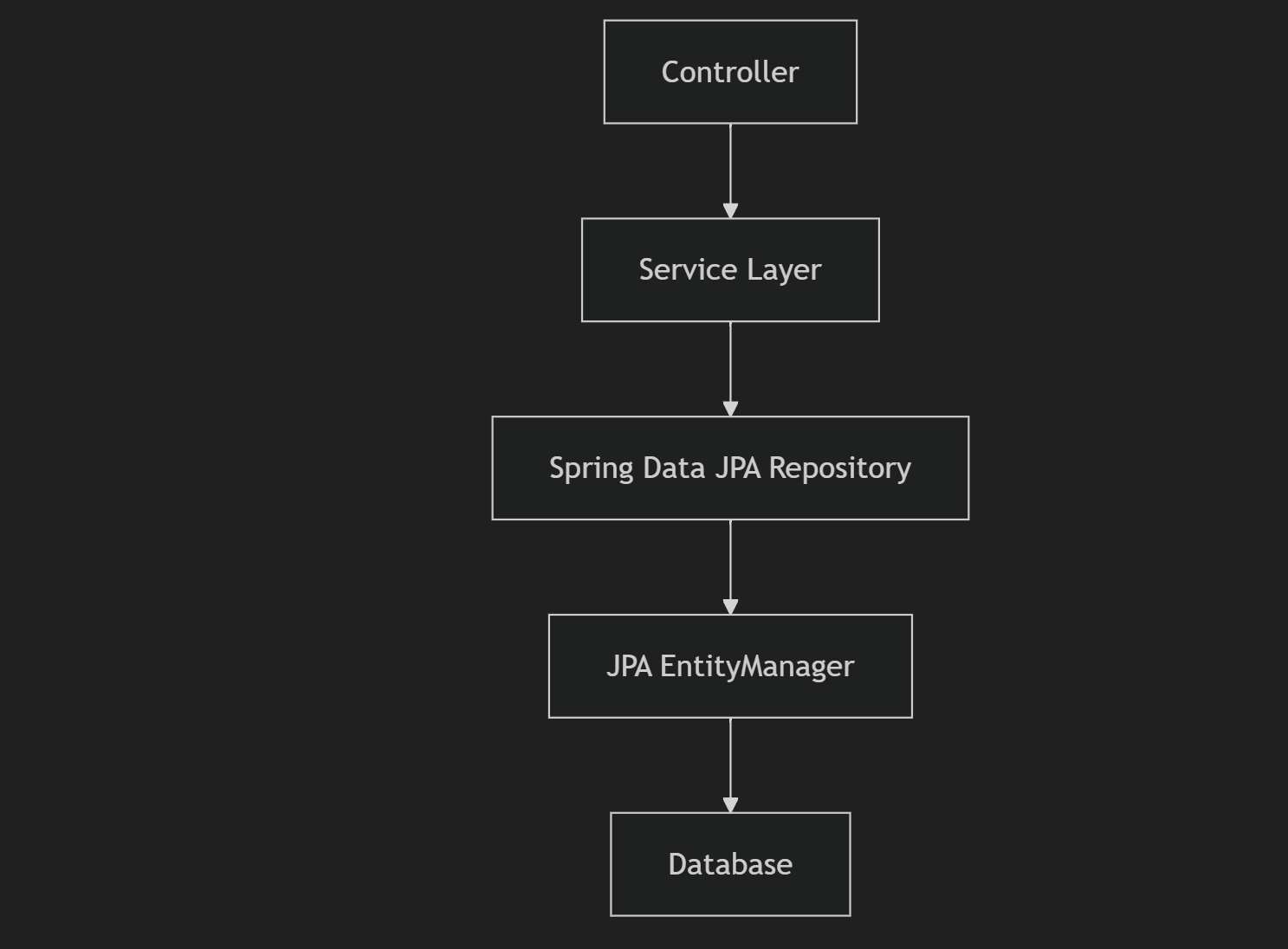
- Controller: 사용자 요청을 처리하고, 서비스 계층으로 전달.
- Service Layer: 비즈니스 로직을 처리하며 Repository와 통신.
- Repository: JPA를 통해 데이터베이스와의 상호작용을 추상화.
- JPA EntityManager: JPA 구현체(Hibernate 등)를 통해 데이터 작업 수행.
- Database: 실제 데이터가 저장되는 관계형 데이터베이스.
참조
JPA/Hibernate 관련 설정 (application.properties)
# MariaDB setting
spring.datasource.driver-class-name=org.mariadb.jdbc.Driver
spring.datasource.url=jdbc:mariadb://localhost:3306/sample
spring.datasource.username=root
spring.datasource.password=!123456
# Hibernate setting
spring.jpa.database-platform=org.hibernate.dialect.MariaDBDialect
spring.jpa.hibernate.ddl-auto=create
spring.jpa.show-sql=trueSQL Dialect
spring.jpa.database-platform=org.hibernate.dialect.MariaDBDialect
- Hibernate에서 사용할
SQL 방언(Dialect)을 지정합니다. MariaDBDialect는 MariaDB 데이터베이스와 호환되는 SQL을 생성하기 위한 Hibernate 방언입니다.- MySQL과 유사하지만 MariaDB 고유의 최적화나 기능을 지원하는 쿼리를 생성합니다.
- 다른 방언 예시:
- MySQL 8.x:
org.hibernate.dialect.MySQL8Dialect - PostgreSQL:
org.hibernate.dialect.PostgreSQLDialect - Oracle 12c:
org.hibernate.dialect.Oracle12cDialect
- MySQL 8.x:
spring.jpa.hibernate.ddl-auto=create
- 애플리케이션 시작 시 Hibernate가
데이터베이스 테이블과 엔티티 간의 매핑을 어떻게 처리할지를 결정합니다. spring.jpa.hibernate.ddl-auto:- Hibernate가 테이블 스키마를 처리하는 방식.
- 주요 옵션:
none: 아무 작업도 하지 않음. 운영 환경에서 사용 권장. 즉, 직접 table을 생성해서 사용함.validate: 스키마를 검증하지만 변경하지 않음.update: 기존 스키마를 유지하며 `필요한 경우 업데이트.create: 기존 테이블 삭제 후 새로 생성.create-drop:create처럼 테이블 생성 후, 애플리케이션 종료 시 삭제.- 개발/운영 환경별 추천 값:
- 개발 환경:
update또는create - 운영 환경:
validate또는none
- 개발 환경:
- 주의: 운영 환경에서 사용 시 기존 데이터가 모두 삭제되므로 위험합니다.
| 설정 값 | 설명 | 적용 시점 및 환경 |
|---|---|---|
none | Hibernate가 DDL 작업을 하지 않음. | - 운영 환경에서 추천. |
| - 스키마는 수동으로 관리되며, Hibernate가 변경하지 않음. | ||
validate | 엔티티와 데이터베이스 테이블의 스키마 일치 여부를 검증 (변경은 하지 않음). | - 운영 환경에서 권장. |
| - 애플리케이션 배포 전 스키마가 엔티티와 일치하는지 확인 가능. | ||
update | 기존 스키마를 유지하면서 필요한 경우 변경. | - 개발 환경에서 유용. |
| - 반복적으로 스키마를 초기화할 필요가 없는 경우. | ||
create | 기존 스키마를 삭제하고 새로 생성. | - 초기 개발 환경에서 추천. |
| - 데이터가 없어도 되는 경우. | ||
create-drop | 애플리케이션 종료 시 생성된 테이블을 삭제. | - 테스트 환경에서 유용. |
| - 데이터베이스 상태를 매번 초기화해야 할 때. |
- 운영 환경에서는 데이터 손실 위험이 있는
create,create-drop사용을 지양해야 합니다. - 대신 스키마를 명확히 검증할 수 있는
validate나 변경을 하지 않는none을 사용하는 것이 일반적입니다.
spring.jpa.show-sql=true
- 실행된 SQL 쿼리를 애플리케이션 로그에 출력합니다.
- SQL 쿼리 디버깅과 성능 분석에 유용합니다.
- 더 나아가 바인딩 파라미터까지 출력하려면 추가 설정이 필요합니다:
logging.level.org.hibernate.SQL=DEBUG logging.level.org.hibernate.type.descriptor.sql.BasicBinder=TRACE
추가적으로 많이 쓰이는 설정
SQL 출력 및 포맷
spring.jpa.show-sql: SQL 쿼리를 출력.spring.jpa.properties.hibernate.format_sql=true: 출력되는 SQL을 포맷팅하여 보기 좋게 만듦.logging.level.org.hibernate.SQL=DEBUG: SQL 로그 레벨 설정.logging.level.org.hibernate.type.descriptor.sql.BasicBinder=TRACE: 쿼리 바인딩 값 출력.
JPA의 @GeneratedValue 전략
@GeneratedValue는 JPA에서 기본 키 값을 자동으로 생성하는 데 사용되며, 키 생성 전략을 결정하는 4가지 옵션을 제공합니다:
GenerationType.IDENTITY- AUTO_INCREMENT를 사용해 키를 생성합니다.
- 각 INSERT마다 새로운 키를 생성합니다.
- 트랜잭션과 독립적으로 동작하므로 배치 INSERT에 제약이 있을 수 있습니다.
- MariaDB에서는 주로 IDENTITY 사용
GenerationType.SEQUENCE- Sequence 객체를 사용해 키를 생성합니다.
- 더 유연하고 배치 처리에 유리합니다.
GenerationType.TABLE- 별도의 키 생성 테이블을 만들어 키를 관리합니다.
- Sequence를 지원하지 않는 데이터베이스에서도 사용 가능.
- 하지만 성능이 낮고, 잘 사용되지 않습니다.
GenerationType.AUTO- 데이터베이스의 기본 키 생성 전략을 JPA가 자동으로 선택합니다.
2. @GeneratedValue(strategy = GenerationType.IDENTITY)
MariaDB 기본 설정:
- AUTO_INCREMENT를 통해 키 값을 자동으로 생성합니다.
- 예제:
@Entity public class Member { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id; private String name; // Other fields and methods... } - MariaDB는 AUTO_INCREMENT 컬럼으로 동작:
CREATE TABLE member ( id BIGINT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(255) );
3. @GeneratedValue(strategy = GenerationType.SEQUENCE)
MariaDB에서 Sequence 사용 설정:
- MariaDB 10.3 이상부터 Sequence 기능을 지원합니다.
- Sequence를 사용하려면 먼저 Sequence를 생성해야 합니다:
CREATE SEQUENCE member_seq START WITH 1 INCREMENT BY 1; - JPA 엔티티 예제:
@Entity public class Member { @Id @GeneratedValue(strategy = GenerationType.SEQUENCE, generator = "member_seq_gen") @SequenceGenerator(name = "member_seq_gen", sequenceName = "member_seq", allocationSize = 1) private Long id; private String name; // Other fields and methods... }
설명:
@SequenceGenerator:name: 사용할 Sequence Generator의 이름.sequenceName: 실제 데이터베이스 Sequence의 이름.allocationSize: 키 값을 미리 생성해 메모리에 로드하는 크기(성능 최적화에 도움).
- SQL 생성:
INSERT INTO member (id, name) VALUES (NEXT VALUE FOR member_seq, '홍길동');
Sequence와 IDENTITY의 차이
| 항목 | IDENTITY | SEQUENCE |
|---|---|---|
| MariaDB 지원 여부 | 기본 지원 (AUTO_INCREMENT) | 10.3 이상에서 수동으로 Sequence 생성 필요 |
| 키 생성 방식 | 테이블마다 AUTO_INCREMENT | 데이터베이스의 Sequence 객체 |
| 배치 처리 | 비효율적 (INSERT 후 키 값 생성됨) | 효율적 (키를 미리 생성 가능) |
| 트랜잭션과의 통합 | 트랜잭션과 독립적 | 트랜잭션과 통합 가능 |
| 성능 최적화 | 기본적이지만 확장성 부족 | allocationSize로 키 생성 성능 최적화 가능 |
5. 실무에서의 선택 가이드
- MariaDB에서 기본적으로 IDENTITY 전략 사용:
- 설정 없이 간단히 사용하려면
@GeneratedValue(strategy = GenerationType.IDENTITY)를 선택하세요. - 테이블에 AUTO_INCREMENT 컬럼이 자동 생성됩니다.
- 설정 없이 간단히 사용하려면
- 배치 성능을 높이고 싶다면 SEQUENCE 사용:
- 특히 대규모 데이터 삽입 작업(배치 처리)이 많은 경우 적합합니다.
- 운영 환경에서는 성능을 검토:
- SEQUENCE는 키 생성 전략에서 더 많은 유연성과 확장성을 제공합니다.
- IDENTITY는
설정이 간단하지만배치 작업 성능이 떨어질 수있습니다.
6. 관련 예제
IDENTITY 전략 예제
@Entity
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
}
SEQUENCE 전략 예제
MariaDB에서 Sequence 생성 후:
CREATE SEQUENCE member_seq
START WITH 1
INCREMENT BY 1;
JPA 설정:
@Entity
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE, generator = "member_seq_gen")
@SequenceGenerator(name = "member_seq_gen", sequenceName = "member_seq", allocationSize = 1)
private Long id;
private String name;
}
jpa column사용하기
@Column 애너테이션은 JPA 엔티티 필드를 데이터베이스 컬럼과 매핑할 때 사용하는 애너테이션입니다. 기본적으로 엔티티의 필드 이름과 동일한 컬럼 이름으로 매핑되지만, 세부적인 설정을 통해 컬럼 속성을 지정할 수 있습니다.
1. @Column의 주요 속성
| 속성 | 설명 | 기본값 |
|---|---|---|
name | 매핑할 데이터베이스 컬럼 이름 | 필드 이름과 동일 |
nullable | 컬럼에 NULL 값 허용 여부 | true |
unique | 해당 컬럼에 유니크 제약 조건을 설정 | false |
length | 문자열 컬럼의 길이 설정 (VARCHAR와 CHAR에만 적용) | 255 |
precision | BigDecimal 타입에서 전체 자리수 설정 (숫자형에만 적용) | 0 |
scale | BigDecimal 타입에서 소수점 자리수 설정 | 0 |
insertable | INSERT 쿼리에 포함 여부 | true |
updatable | UPDATE 쿼리에 포함 여부 | true |
columnDefinition | DDL 생성 시 컬럼의 데이터 타입이나 제약 조건을 직접 명시 | 자동 생성된 값 |
table | 해당 컬럼이 매핑될 테이블 이름 (멀티 테이블 매핑에 사용) | 기본 테이블 이름 |
2. 주요 속성 사용 예제
2.1 name
컬럼 이름을 엔티티 필드 이름과 다르게 설정:
@Column(name = "user_name")
private String name;
- 필드
name은 데이터베이스 컬럼user_name으로 매핑됩니다.
2.2 nullable
NULL 허용 여부 설정:
@Column(nullable = false)
private String email;
nullable = false는 DDL 생성 시NOT NULL제약 조건을 추가합니다.
2.3 unique
유니크 제약 조건 설정:
@Column(unique = true)
private String username;
- 주의:
unique = true는 DDL에서 유니크 제약 조건을 생성하지만, 여러 컬럼을 조합한 유니크 제약 조건은@Table의uniqueConstraints를 사용해야 합니다.
2.4 length
문자열 필드 길이 제한:
@Column(length = 50)
private String firstName;
length = 50은 DDL에서 해당 컬럼의 길이를VARCHAR(50)으로 생성합니다.
2.5 precision과 scale
BigDecimal 또는 숫자형 필드의 전체 자리수와 소수점 자리수 설정:
@Column(precision = 10, scale = 2)
private BigDecimal price;
precision = 10, scale = 2는 최대 자리수 10, 소수점 아래 2자리로 제한합니다.- 예를 들어,
12345678.91은 허용되지만123456789.91은 허용되지 않습니다.
2.6 insertable와 updatable
컬럼이 INSERT 또는 UPDATE 쿼리에 포함될지 여부 설정:
@Column(insertable = false, updatable = false)
private String createdAt;
insertable = false:INSERT쿼리에서 제외.updatable = false:UPDATE쿼리에서 제외.
2.7 columnDefinition
DDL 생성 시 데이터 타입과 제약 조건 명시:
@Column(columnDefinition = "TEXT NOT NULL")
private String description;
- Hibernate가 기본으로 생성하는 타입 대신 명시적으로 타입과 제약 조건을 지정합니다.
2.8 table
컬럼이 특정 테이블에 매핑되도록 설정:
@Column(table = "user_details")
private String address;
- 엔티티가 여러 테이블로 매핑될 때 사용합니다.
3. 사용 시 주의할 점
- DDL 자동 생성과 스키마 관리
@Column은 Hibernate가 DDL을 자동 생성할 때만 유효합니다.- 운영 환경에서는 DDL 자동 생성을 비활성화(
ddl-auto=none)하고, 스키마 관리 도구(Flyway, Liquibase)를 사용하는 것이 안전합니다.
nullable과 애플리케이션 유효성 검사nullable = false는 데이터베이스 제약 조건만 추가하며, 애플리케이션의 입력값 유효성 검사는 별도로 구현해야 합니다.- Spring Validation을 활용해
@NotNull같은 애너테이션을 함께 사용하세요.
- 유니크 제약 조건
- 단일 컬럼의 유니크 제약 조건은
unique = true로 설정 가능하지만, 다중 컬럼 조합 유니크 제약 조건은@Table의uniqueConstraints를 사용해야 합니다:@Table(uniqueConstraints = @UniqueConstraint(columnNames = {"username", "email"}))
- 단일 컬럼의 유니크 제약 조건은
columnDefinition사용 주의- 데이터베이스에 종속적인 정의를 포함하면 다른 DBMS로 마이그레이션할 때 문제가 발생할 수 있습니다.
- 가능한 Hibernate의 기본 매핑을 사용하는 것이 좋습니다.
precision과scale- 숫자 타입 매핑 시, 데이터베이스의 기본 동작이 상이할 수 있으므로 직접 테스트 후 사용하는 것이 좋습니다.
- 데이터 크기와 인덱스 주의
- 길거나 큰 데이터(예:
TEXT,BLOB)는 인덱스 생성에 제약이 있을 수 있으므로 적절히 설계해야 합니다.
- 길거나 큰 데이터(예:
4. 실무 적용 예제
@Entity
@Table(name = "users")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "user_name", nullable = false, length = 50, unique = true)
private String username;
@Column(nullable = false)
private String email;
@Column(precision = 10, scale = 2)
private BigDecimal balance;
@Column(insertable = false, updatable = false, columnDefinition = "TIMESTAMP DEFAULT CURRENT_TIMESTAMP")
private LocalDateTime createdAt;
@Transient
private String tempData; // 매핑하지 않을 필드
}
Snake Case와 Camel Case 규칙 주의할 점
- Snake Case: 단어 사이를
_로 구분하며, 모든 문자를 소문자로 작성합니다.- 예:
first_name,created_at - SQL과 친화적이며 가독성이 좋습니다.
- 예:
- Camel Case: 첫 단어는 소문자, 이후 단어는 첫 글자를 대문자로 작성합니다.
- 예:
firstName,createdAt - Java에서 변수명, 필드명을 작성할 때 일반적으로 사용합니다.
- 예:
SQL 표준과의 호환성
- SQL은 대소문자를 구분하지 않는 경우가 많지만, 일부 DBMS(MariaDB, MySQL 등)는 설정에 따라 대소문자를 구분합니다.
- Snake Case는 모든 문자가 소문자이므로 SQL 표준과 잘 호환됩니다.
- Camel Case를 사용할 경우 데이터베이스에서 자동으로 소문자로 변환될 수 있으므로 주의가 필요합니다.
JPA와의 매핑 문제
- JPA는 엔티티의 필드 이름(보통 Camel Case)을 기본적으로 컬럼 이름으로 매핑합니다.
- 데이터베이스 컬럼명이 Snake Case일 경우 자동 매핑이 실패할 수 있습니다.
- 예: 필드
first_name→ 컬럼firstName(Camel Case)로 매핑 시 문제 발생. - 데이터베이스 컬럼은
first_name(Snake Case)로 설정된 경우가 일반적.
- 예: 필드
대소문자 민감성
- 일부 데이터베이스(MariaDB, MySQL 등)는 설정에 따라 테이블 이름과 컬럼 이름의 대소문자를 구분합니다.
- Camel Case를 사용할 경우 대소문자 구분으로 인해 쿼리 실행 시 오류가 발생할 수 있습니다.
database와 enitity 사이를 hibernate가 mapping할 때 naming 전략을 설정해줄 수도 있습니다.
jpa:
hibernate:
naming:
physical-strategy:컨벤션 혼합 사용 문제
- 테이블/컬럼 이름에 Snake Case와 Camel Case를 혼용하면 가독성과 유지보수성이 떨어집니다.
- 일관된 규칙을 정해 사용하는 것이 중요합니다
JPA의 @Column 애너테이션으로 컬럼 이름을 명시하면 Snake Case와 Camel Case를 명확히 구분할 수 있습니다.
@Entity
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "first_name")
private String firstName;
@Column(name = "created_at")
private LocalDateTime createdAt;
}참고
Column (Java(TM) EE 7 Specification APIs)
Column (Jakarta EE Platform API)
1. 엔티티 클래스 관련 애너테이션
| 애너테이션 | 설명 | 주요 속성 | 예시 |
|---|---|---|---|
@Entity | 클래스를 JPA 엔티티로 선언. | 없음 | @Entity public class User { } |
@Table | 엔티티와 데이터베이스 테이블을 매핑. | name(테이블 이름), schema, uniqueConstraints | @Table(name = "users", schema = "public") |
1.1. @Entity
- 클래스가 JPA 엔티티임을 나타냅니다.
- 반드시
기본 생성자(파라미터 없는 생성자)가 있어야 합니다.
@Entity
public class User {
// 엔티티 클래스
}
1.2. @Table
- 엔티티와 데이터베이스 테이블 이름을 매핑합니다.
- 생략하면 엔티티 클래스 이름이 테이블 이름으로 사용됩니다.
- 추가 속성:
name: 테이블 이름schema: 스키마 이름catalog: 카탈로그 이름uniqueConstraints: 테이블에 대한 유니크 제약 조건 설정
@Entity
@Table(name = "users", schema = "public")
public class User {
// 테이블 users에 매핑
}2. 필드 매핑 관련 애너테이션
| 애너테이션 | 설명 | 주요 속성 | 예시 |
|---|---|---|---|
@Id | 기본 키(Primary Key)를 지정. | 없음 | @Id private Long id; |
@GeneratedValue | 기본 키 생성 전략 지정. | strategy(키 생성 방식) | @GeneratedValue(strategy = GenerationType.IDENTITY) |
@Column | 필드와 테이블 컬럼 매핑. | name, nullable, unique, length | @Column(name = "user_name", nullable = false, length = 100) |
@Lob | 대용량 데이터(BLOB, CLOB) 매핑. | 없음 | @Lob private String description; |
@Temporal | 날짜/시간 데이터 매핑. | TemporalType(DATE, TIME, TIMESTAMP) | @Temporal(TemporalType.TIMESTAMP) private Date createdAt; |
@Enumerated | Enum 타입 매핑. | EnumType(ORDINAL, STRING) | @Enumerated(EnumType.STRING) private UserRole role; |
@Transient | 필드를 데이터베이스에 매핑하지 않음. | 없음 | @Transient private String tempData; |
2.1. @Id
- 해당 필드가 엔티티의 기본 키(Primary Key)임을 나타냅니다.
@Id
private Long id;
2.2. @GeneratedValue
- 기본 키 값의 생성 전략을 지정합니다.
- 주요 옵션:
GenerationType.IDENTITY: 데이터베이스에 기본 키 생성을 위임.GenerationType.SEQUENCE: 데이터베이스의 시퀀스를 사용.GenerationType.TABLE: 별도의 키 생성용 테이블을 사용.GenerationType.AUTO: 데이터베이스 방언에 맞는 전략을 자동으로 선택.
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;2.3. @Column
- 엔티티 필드와 테이블 컬럼 간 매핑을 정의합니다.
- 추가 속성:
name: 컬럼 이름nullable:null허용 여부unique: 유니크 제약 조건length: 문자열 길이precision,scale: 숫자 데이터 타입의 소수점 자릿수 정의
@Column(name = "user_name", nullable = false, length = 100)
private String name;
2.4. @Lob
- 필드를 BLOB 또는 CLOB 데이터 타입으로 매핑합니다.
- 대용량 데이터(텍스트, 바이너리)를 처리할 때 사용합니다.
@Lob
private String description;
2.5. @Temporal
- 날짜/시간 데이터 매핑에 사용.
- 옵션:
TemporalType.DATE: 날짜만 저장 (yyyy-MM-dd).TemporalType.TIME: 시간만 저장 (HH:mm:ss).TemporalType.TIMESTAMP: 날짜와 시간 저장 (yyyy-MM-dd HH:mm:ss).
@Temporal(TemporalType.TIMESTAMP)
private Date createdAt;
2.6. @Enumerated
- Enum 타입을 데이터베이스에 저장할 때 사용.
- 옵션:
EnumType.ORDINAL: Enum의 순서값 저장.EnumType.STRING: Enum 이름을 문자열로 저장(권장).
@Enumerated(EnumType.STRING)
private UserRole role;
2.7. @Transient
- 해당 필드는 데이터베이스에 저장되지 않습니다.
- JPA가 관리하지 않는 필드를 정의할 때 사용.
@Transient
private String tempData;
3. 관계 매핑 관련 애너테이션
| 애너테이션 | 설명 | 주요 속성 | 예시 |
|---|---|---|---|
@OneToOne | 엔티티 간 1:1 관계 매핑. | mappedBy, cascade, fetch | @OneToOne @JoinColumn(name = "profile_id") private UserProfile profile; |
@OneToMany | 엔티티 간 1:N 관계 매핑. | mappedBy, cascade, fetch | @OneToMany(mappedBy = "department", cascade = CascadeType.ALL) private List<Employee> employees; |
@ManyToOne | 엔티티 간 N:1 관계 매핑. | cascade, fetch | @ManyToOne @JoinColumn(name = "department_id") private Department department; |
@ManyToMany | 엔티티 간 N:M 관계 매핑. | mappedBy, cascade, fetch | @ManyToMany @JoinTable(name = "student_course") private List<Course> courses; |
@JoinColumn | 외래 키를 매핑. | name, referencedColumnName | @JoinColumn(name = "department_id") |
@JoinTable | 중간 테이블을 정의. | name, joinColumns, inverseJoinColumns | @JoinTable(name = "student_course") |
3.1. @OneToOne
- 엔티티 간 1:1 관계를 매핑합니다.
@JoinColumn으로외래 키를 지정합니다.- 외래키를 사용하는 쪽에서 지정해줄 수 있습니다.
@OneToOne
@JoinColumn(name = "profile_id")
private UserProfile profile;
3.2. @OneToMany
- 엔티티 간 1:N 관계를 매핑합니다.
- 기본적으로 지연 로딩(Lazy Loading)이 설정됩니다.
- 1 쪽에 속한 엔티티에서 설정합니다.
@OneToMany(mappedBy = "department", cascade = CascadeType.ALL)
private List<Employee> employees;
3.3. @ManyToOne
- 엔티티 간 N:1 관계를 매핑합니다.
- 외래 키를 사용하는 다대일 관계를 정의합니다.
@ManyToOne
@JoinColumn(name = "department_id")
private Department department;
3.4. @ManyToMany
- 엔티티 간 N:M 관계를 매핑합니다.
- 중간 테이블(
@JoinTable)을 통해 매핑합니다.
@ManyToMany
@JoinTable(
name = "student_course",
joinColumns = @JoinColumn(name = "student_id"),
inverseJoinColumns = @JoinColumn(name = "course_id")
)
private List<Course> courses;
4. 고급 매핑 애너테이션
| 애너테이션 | 설명 | 주요 속성 | 예시 |
|---|---|---|---|
@MappedSuperclass | 공통 엔티티 속성을 상속받도록 정의. | 없음 | @MappedSuperclass public abstract class BaseEntity { } |
@Embeddable | 값 타입 클래스를 정의. | 없음 | @Embeddable public class Address { } |
@Embedded | 값 타입 필드를 엔티티에 포함. | 없음 | @Embedded private Address address; |
@Inheritance | 상속 매핑 전략 정의. | strategy(SINGLE_TABLE, JOINED, TABLE_PER_CLASS) | @Inheritance(strategy = InheritanceType.JOINED) |
4.1. @MappedSuperclass
- 공통적으로 사용되는 엔티티 속성을 상속받을 수 있도록 정의.
- 데이터베이스에는
별도의 테이블이 생성되지 않음.
@MappedSuperclass
public abstract class BaseEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Temporal(TemporalType.TIMESTAMP)
private Date createdAt;
}
4.2. @Embeddable / @Embedded
- 값 타입을 객체로 매핑할 때 사용.
@Embeddable: 내장될 클래스에 사용.@Embedded: 내장 필드에 사용.
@Embeddable
public class Address {
private String city;
private String street;
}
@Entity
public class User {
@Embedded
private Address address;
}
즉, Entity 내부의 속성 값을 더 응집시켜 객체로 데이터를 표현합니다. @Embeddable이 붙은 class 자체가 또 다른 entity를 생성하는 것이 아니라, 위 class를 예시로 들면, User entity에 존재하는 city와 street이라는 각각의 attribute 들을 spring 측에서 객체화해 사용할 수 있습니다. @Embeddable이 붙으면 database에 해당 class가 별도의 enity가 아님을 알릴 수 있습니다.
4.3. @Inheritance
- 상속 구조를 매핑.
- 옵션:
InheritanceType.SINGLE_TABLE: 단일 테이블 전략(기본값).InheritanceType.JOINED: 정규화된 테이블 전략.InheritanceType.TABLE_PER_CLASS: 클래스마다 테이블 생성.
@Entity
@Inheritance(strategy = InheritanceType.JOINED)
public class BaseEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
}
5. 기타 유용한 애너테이션
5. 기타 유용한 애너테이션
| 애너테이션 | 설명 | 주요 속성 | 예시 |
|---|---|---|---|
@Version | 낙관적 락(Optimistic Lock)을 위한 버전 관리. | 없음 | @Version private int version; |
@Access | 필드 또는 프로퍼티 접근 방식 지정. | AccessType(FIELD, PROPERTY) | @Access(AccessType.FIELD) |
5.1. @Version
- 엔티티의 버전을 관리하여 낙관적 락(Optimistic Locking)을 구현할 때 사용.
@Version
private int version;
잠깐만!!!! Lock 넘겨짚고 가기
lock?
여러 개의 트랜잭션이 동시에 접근했을 때, 데이터의 일관성이 깨질 수 있기 때문에 락(잠금)을 걸고 이를 관리하는 것을 Locking이라고 합니다.
예를 들어, 3000원이 있는 계좌에 A와 B가 3000원을 입금했는데 이 과정이 동시에 이루어져서 A와 B가 동시에 3000원을 읽어서 3000원을 더해버리는 바람에 최종 금액이 9000원이 아니라 6000원이 되버리는 현상을 막기 위해 필요합니다.
실제 서비스를 운영하다 보면, 이러한 데이터베이스 고립에 있어서 서로 다른 트랜잭션 간 접근 문제로 데이터의 일관성 상호배제성이 위반되는 경유가 많이 있을 것 같습니다.
낙관적 락(optimistic lock)
자원에 락을 걸지 않고, 동시성 문제가 발생하면 그때 처리 합니다.
- 데이터를 읽을 때는 다른 트랜잭션이 데이터를 수정하지 않을 것으로 가정하고 락을 걸지 않습니다.
- 데이터를 업데이트할 때 실제로 락을 확인하고 충돌이 발생하면 롤백 또는 충돌을 해결하는 방법을 적용합니다.
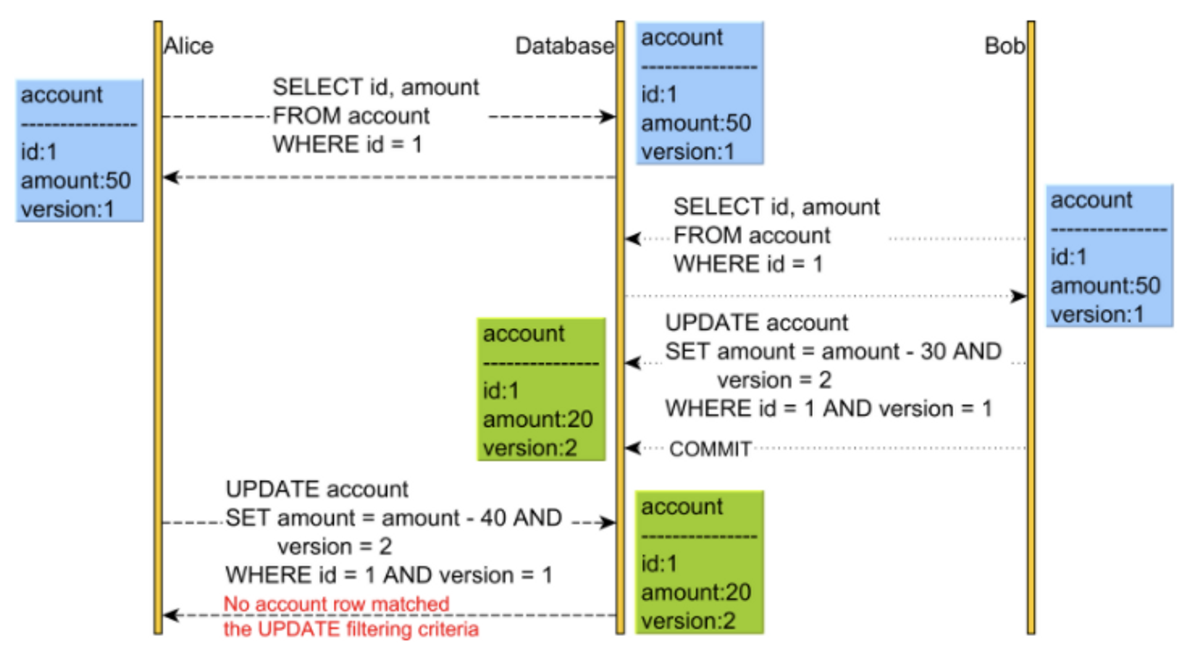
낙관적인 락은 Version을 사용해 관리합니다.
- Alice와 Bob이 같은 데이터를 읽어 Version1 값을 가져갑니다.
-> 값을 읽어들일 때는 version은 수정하지 않습니다. - 이후 Bob이 먼저 업데이트 커밋을 보내게 되면서 Version이 2로 올라갑니다. 여기까지는 문제가 없습니다.
- Alice도 업데이트 커밋을 날리면서 Version을 2로 올립니다.
이미 Version 2가 존재하는데 또 version을 2로 올리기 때문에 Optimistic Lock Exception이 터집니다. 이것을 충돌이 발생한 상황이라고 볼 수 있습니다. 이 때 롤백 또는 충돌을 해결하는 방법을 적용합니다.
낙관적 락은 데이터베이스가 제공하는 락이 아닌 애플리케이션 레벨에서 락을 구현하게 됩니다. JPA에서는 버전 관리 기능(@Version)을 통해 구현할 수 있습니다.
JPA는 낙관적 락을 위해 @Version 어노테이션을 제공하고 있습니다. 해당 어노테이션이 붙은 필드를 포함하는 엔티티를 정의하면, 해당 엔티티 테이블을 읽는 각 트랜잭션은 업데이트를 수행하기 전에 버전의 속성을 확인하게 됩니다. 만약 데이터를 읽고 업데이트를 하기 이전에 버전 값이 변경되어있다면 OptimisticLockException을 발생 시키며 해당 업데이트를 취소합니다.
@Version 필드를 선언할 때에는 아래의 규칙을 따라야 합니다.
- 각 엔티티 클래스에는 한 개의 버전 필드만 있어야 한다.
- 여러 테이블에 매핑된 엔티티의 기본 테이블에 배치해야 한다.
- 버전 유형은 int, Integer, long, Long, short, Short, java.sql.Timestamp 중 하나여야 한다.
- 엔티티를 통해 버전이 어떠한지 필드를 탐색할 수는 있지만 우리가 직접 수정해서는 안 된다.
비관적 락
비관적인 락은 데이터를 읽을 때부터 락을 걸고, 업데이트가 완료될 때까지 락을 유지하는 방식입니다. 기본적으로 데이터 갱신시 충돌이 발생할 것 으로 보고 미리 잠금을 하는 방식을 Pessimistic Lock(비관적인 락)이라고 합니다.
데이터를 읽을 때 락을 걸기 때문에 다른 트랜잭션이 해당 데이터를 읽거나 수정할 수 없습니다.
비관적인 락은 데이터 충돌을 최소화하지만, 동시성이 낮아질 수 있고, 락 경합이 발생할 경우 성능 저하가 발생할 수 있습니다.
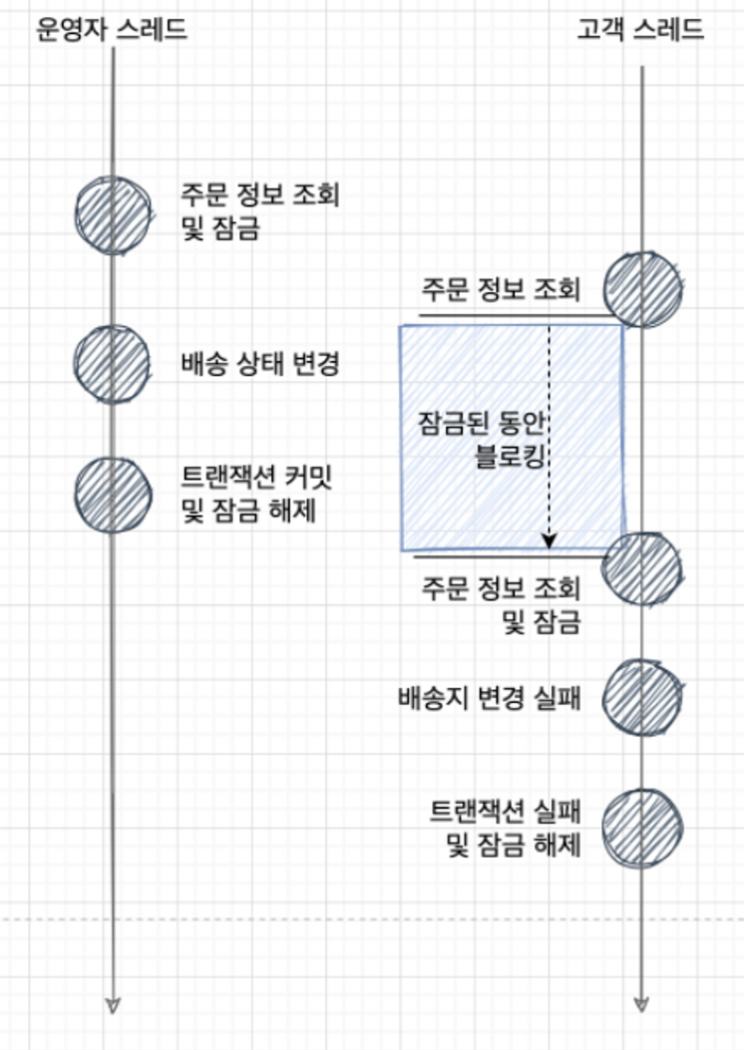
- 운영자가 주문 정보를 조회합니다. 이 순간 데이터에 락이 걸리게 됩니다.
- 고객이 같은 주문 정보를 조회하지만 락이 걸려있기에 해당 데이터를 읽거나 쓸 수 없습니다. 따라서 대기합니다.
- 운영자가 작업을 끝내고 잠금을 해제하면 이때, 고객의 로직이 수행됩니다.
무결성에 장점이 있지만 데드락의 위험성이 존재합니다.
5.2. @Access
jpa가 엔티티에 접근하는 방식을 지정해주는 어노테이션입니다.
객체에 접근하기 위한 방법으로 간단히 2가지 방법이 있습니다.
예를 들어 User라는 객체가 있고, name이라는 속성을 가지고 있다고 가정해보겠습니다.
- user.name
- user.getName()
1번 방법을 필드접근이라 하고, 2번 방법을 프로퍼티 접근이라고 합니다.
@Access가 설정되어 있지 않은 경우 @Id annotation의 위치를 보고 파악합니다.
@Id annotation이 필드에 붙어있으면 필드접근, getter method에 붙어있으면 프로퍼티 접근입니다.
필드접근
@Access(AccessType.FIELD)
private String name;
프로퍼티 접근
@Access(AccessType.PROPERTY)
private String name;
영속성 컨텍스트란?
- 영속성 컨텍스트(Persistence Context)는 JPA(Java Persistence API)에서 핵심적인 개념으로, 엔티티(Entity) 객체를 관리하고 데이터베이스와의 상호작용을 조정하는 역할을 합니다.
영속성 컨텍스트는 메모리 내에서 엔티티를 관리하며, 데이터베이스와 직접적인 CRUD 작업을 효율적으로 처리합니다.
이 과정에서 엔티티의 상태(생명 주기)가 어떻게 변화하는지 이해하는 것이 중요합니다.
간단히 말해, 엔티티의 상태를 추적하고 데이터베이스와 동기화하는 역할을 합니다.
영속성 컨텍스트의 주요 특징
- 1차 캐시
- 영속성 컨텍스트는
1차 캐시로 동작하며, 데이터베이스에서 조회된 엔티티를 캐시에 저장합니다. - 동일한 엔티티를 여러 번 조회하더라도 데이터베이스를 다시 조회하지 않고
캐시된 엔티티를 반환합니다.
- 영속성 컨텍스트는
- 변경 감지(Dirty Checking)
- 엔티티 객체의 상태가 변경되었는지 감지하고, 변경된 데이터를 기반으로 필요한 SQL을 생성합니다.
- 이 과정에서 엔티티와 스냅샷(초기 상태)을 비교합니다.
- 쓰기 지연
- 데이터 변경 시 즉시 SQL을 실행하지 않고, SQL 저장소에 SQL을 쌓아두었다가
flush()또는commit시점에 일괄 실행합니다.
- 데이터 변경 시 즉시 SQL을 실행하지 않고, SQL 저장소에 SQL을 쌓아두었다가
- 동일성(identity) 보장
- 동일한 영속성 컨텍스트 내에서는 같은 식별자를 가진 엔티티는 항상 동일한 객체로 관리됩니다.
flush() 메커니즘
flush()는 영속성 컨텍스트의 내용을 데이터베이스와 동기화하는 역할을 합니다. 하지만 트랜잭션이 끝나는 시점에 commit과 함께 동작하므로, 즉시 데이터베이스에 저장하지는 않습니다.
- flush() 호출
- 개발자가 명시적으로 호출하거나, 트랜잭션의
commit시점에 자동으로 호출됩니다.
- 개발자가 명시적으로 호출하거나, 트랜잭션의
- 변경 감지
- 영속성 컨텍스트의 엔티티와 스냅샷을 비교하여 변경된 엔티티를 찾습니다.
- 변경된 데이터를 기반으로 SQL을 생성합니다.
- SQL 생성 및 저장
- 변경된 엔티티에 대해 필요한 SQL(INSERT, UPDATE, DELETE)을 생성하고, 쓰기 지연 저장소에 저장합니다.
- SQL 실행
저장소에 쌓인 SQL을 데이터베이스에 전달하여 실행합니다.
- 트랜잭션 커밋
- 데이터베이스의 커밋이 이루어져 변경 사항이 최종적으로 반영됩니다.
주요 메서드와 특징
| 메서드 | 설명 | 실행 시점 |
|---|---|---|
persist() | 엔티티를 영속성 컨텍스트에 저장합니다. | 즉시 (쓰기 지연 저장소에 저장) |
flush() | 영속성 컨텍스트의 내용을 데이터베이스와 동기화합니다. | 명시적 호출 또는 트랜잭션 commit 시점 |
commit() | 트랜잭션을 커밋하고 데이터베이스 변경 사항을 확정합니다. | 트랜잭션 종료 시점 |
clear() | 영속성 컨텍스트를 초기화하여 관리 중인 모든 엔티티를 분리(detach)합니다. | 즉시 실행 |
detach() | 특정 엔티티를 영속성 컨텍스트에서 분리합니다. | 즉시 실행 |
merge() | 준영속(detached) 상태의 엔티티를 다시 영속성 컨텍스트에 병합합니다. | 즉시 실행 |
1. CRUD와 영속성 컨텍스트
- CRUD (Create, Read, Update, Delete):
데이터베이스에 데이터를 삽입, 조회, 수정, 삭제하는 작업입니다. - EntityManager와 Persistence Context:
- EntityManager는 JPA에서 영속성 컨텍스트를 관리하는 주요 인터페이스입니다.
- CRUD 작업은 EntityManager가 영속성 컨텍스트를 통해 처리합니다.
- 영속성 컨텍스트는 메모리 내에 엔티티를 저장하고, 데이터베이스와의 동기화를 담당합니다.
2. 엔티티의 생명 주기
엔티티는 JPA 환경에서 4가지 상태로 구분됩니다.
| 상태 | 설명 | 특징 |
|---|---|---|
| 비영속(new) | - 영속성 컨텍스트와 관계없는 상태. | |
- 단순히 new로 생성된 객체. | 데이터베이스와 전혀 연결되지 않음. | |
| 영속(managed) | - 영속성 컨텍스트에 등록된 상태. | |
| - EntityManager가 관리 중. | 변경 사항이 자동으로 데이터베이스에 반영됨 (flush 시). | |
| 준영속(detached) | - 영속성 컨텍스트에서 분리된 상태. | |
| - EntityManager가 더 이상 관리하지 않음. | 변경 사항이 더 이상 데이터베이스에 반영되지 않음. | |
| 삭제(removed) | - 영속성 컨텍스트에서 제거된 상태. | |
| - 데이터베이스에서 삭제될 예정. | EntityManager.remove() 호출 시 이 상태로 전환됨. |
3. CRUD 작업 흐름과 엔티티 상태 변화
1) INSERT (Create)
- 새로운 엔티티 객체 생성 → 비영속 상태.
EntityManager.persist(entity)호출 → 영속 상태로 전환.- 영속성 컨텍스트에 등록 → 데이터베이스에 INSERT SQL 전송.
2) SELECT (Read)
EntityManager.find()또는JPQL실행 시영속성 컨텍스트에서 먼저 조회.- 영속성 컨텍스트에 없으면 데이터베이스에서 SELECT 실행 후 영속 상태로 관리.
3) UPDATE
- 영속 상태의 엔티티에서 속성 값을 수정.
EntityManager.update()대신 변경 감지(Dirty Checking)가 자동으로 수행.- 트랜잭션 종료 시점에
flush()호출 → 데이터베이스에 UPDATE SQL 전송.
4) DELETE
EntityManager.remove(entity)호출 → 삭제 상태로 전환.- 영속성 컨텍스트와 데이터베이스에서 엔티티 삭제.
4. Persistence Context의 중요성
- 1차 캐시:
- 동일한 트랜잭션 내에서 같은 엔티티 조회 시
데이터베이스를 반복적으로 호출하지 않음. 메모리에서 바로 데이터를 조회.
- 동일한 트랜잭션 내에서 같은 엔티티 조회 시
- 변경 감지(Dirty Checking):
- 영속 상태의 엔티티 변경 사항을 자동으로 감지하고 데이터베이스에 반영.
- 쓰기 지연(Write-Behind):
- 트랜잭션 커밋 시점에
일괄적으로 SQL 실행. - 성능 최적화를 위해 INSERT/UPDATE/DELETE를 지연 처리.
- 트랜잭션 커밋 시점에
- 동기화:
- 영속성 컨텍스트와 데이터베이스를 항상 일치시키는 역할.
비유를 통한 이해
영속성 컨텍스트를 JPA의 내부 메모리 저장소로 생각할 수 있습니다.
- 비영속 상태: 책이 작성된 초안 상태 → 아직 출판사(영속성 컨텍스트)에 보내지 않음.
- 영속 상태: 출판사에 등록된 책 → 변경 및 수정 사항이 자동으로 반영되어 최종 출판됨.
- 준영속 상태: 출판사에서 계약이 종료된 책 → 출판사에서 더 이상 관리하지 않음.
- 삭제 상태: 출판사에서 삭제된 책 → 서점에서도 더 이상 찾을 수 없음.
엔티티 상태(생명주기)의 이해
JPA에서 엔티티는 다음과 같은 네 가지 상태를 가집니다:
- New (비영속)
- 엔티티 객체가 생성된 상태로, 영속성 컨텍스트에 등록되지 않았습니다.
- 데이터베이스와 연결되지 않으며, 트랜잭션과도 관련이 없습니다.
new키워드로 생성된 엔티티 객체가 여기에 해당합니다.- 상태 변경 메서드:
EntityManager.persist()
- Managed (영속)
- 엔티티가 영속성 컨텍스트에 등록된 상태입니다.
- 영속성 컨텍스트는 이 엔티티를 관리하며, 변경 사항을 감지(Dirty Checking)하여 트랜잭션 종료 시 데이터베이스에 반영합니다.
find()또는 JPQL 쿼리로 조회된 엔티티도 이 상태에 해당합니다.- 주요 메서드:
persist(),find(), JPQL,flush()
- Detached (준영속)
- 엔티티가 영속성 컨텍스트에서 분리된 상태입니다.
- 이 상태의 엔티티는 더 이상 영속성 컨텍스트에서 관리되지 않으며, 데이터베이스와 동기화되지 않습니다.
- 주로 트랜잭션 종료 또는 명시적인
detach(),clear(),close()호출로 전환됩니다. - 상태 복구 메서드:
merge()
- Removed (삭제)
- 엔티티가 영속성 컨텍스트에서 삭제된 상태입니다.
- 삭제 상태는 데이터베이스에서도 제거되도록 준비된 상태를 나타냅니다.
EntityManager.remove()호출로 삭제 상태가 됩니다.- 삭제는
flush()를 통해 데이터베이스에 반영됩니다.
영속성 컨텍스트에서 상태 전환
각 상태 간 전환을 다음과 같은 메서드로 나타냅니다:
- New → Managed (비영속 → 영속)
EntityManager.persist(entity)메서드 호출.- 영속성 컨텍스트에 엔티티 등록 후 데이터베이스에 저장 준비.
- Managed → Detached (영속 → 준영속)
EntityManager.detach(entity)를 호출하여 특정 엔티티를 영속성 컨텍스트에서 제거.EntityManager.clear()로 전체 컨텍스트 초기화.EntityManager.close()로 영속성 컨텍스트 종료.
- Detached → Managed (준영속 → 영속)
EntityManager.merge(entity)호출.- 준영속 상태의 엔티티를 영속성 컨텍스트로 복원하며, 새로운 영속 상태의 엔티티 반환.
- Managed → Removed (영속 → 삭제)
EntityManager.remove(entity)호출.- 트랜잭션 커밋 또는
flush()호출 시 데이터베이스에서 삭제.
- Managed 상태에서 데이터베이스로의 동기화
EntityManager.flush()를 호출하거나 트랜잭션 커밋 시점에 자동 호출.- 변경된 엔티티 상태를 데이터베이스에 반영 (INSERT, UPDATE, DELETE).
예제 코드
@Entity @Getter @Setter
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
private String email;
// 기본 생성자
public Member() {}
// 생성자
public Member(String name, String email) {
this.name = name;
this.email = email;
}
}
import jakarta.persistence.*;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
@Service
public class MemberService {
@PersistenceContext
private EntityManager entityManager;
@Transactional
public void demonstrateEntityLifecycle() {
// 1. 비영속 상태 (Transient)
// 영속성 컨텍스트와 전혀 연관되지 않은 상태
Member member = new Member("홍길동", "hong@example.com");
System.out.println("1. 비영속 상태: " + member);
// 2. 영속 상태 (Managed)
// 엔티티를 persist()로 영속성 컨텍스트에 저장
entityManager.persist(member);
System.out.println("2. 영속 상태: ID가 아직 할당되지 않음 -> ID는 flush 시점에 할당됨");
// flush()는 SQL 저장소에 쌓인 쿼리를 실행 (INSERT 발생)
entityManager.flush();
System.out.println("영속 상태 이후: ID = " + member.getId());
// 3. 변경 감지 (Dirty Checking)
// 영속 상태의 엔티티 값을 변경 -> 자동으로 UPDATE 쿼리가 생성됨
member.setName("강감찬");
System.out.println("3. 변경 감지: 이름 변경 -> 강감찬");
entityManager.flush(); // UPDATE SQL 실행
// 4. 준영속 상태 (Detached)
// 엔티티를 영속성 컨텍스트에서 분리(detach)
entityManager.detach(member);
System.out.println("4. 준영속 상태: 더 이상 변경 감지되지 않음");
member.setName("이순신"); // 변경하더라도 UPDATE SQL 실행되지 않음
entityManager.flush(); // SQL 실행 안 됨
// 5. 삭제 상태 (Removed)
// 엔티티를 영속성 컨텍스트에서 제거
entityManager.merge(member); // 다시 영속 상태로 전환
entityManager.remove(member); // 삭제 예약
System.out.println("5. 삭제 상태: DELETE SQL 실행 예정");
entityManager.flush(); // DELETE SQL 실행
// 6. 트랜잭션 종료 // commit 시점에 flush()가 자동으로 호출됨
System.out.println("6. 트랜잭션 종료: 데이터베이스에 변경 사항 반영 완료");
}
}
참고
- https://hongchangsub.com/basicjpa2/
- 자바 ORM 표준 JPA 프로그래밍(김영한)

{kind=link}
{kind=link}
{kind=link}