
2021년 06월 05일 15:00 ~ 22:00 스터디 진행 내용을 정리한 글입니다.
0. 스터디 공지 사항
참석자
49 명
서기 및 공유
서기: 김현우님, 김성원님
공유: 이민욱님
진도
리눅스 커널 내부구조 (백승재, 최종무 저) 82g.
1. 프로세스, 쓰레드, 그리고 태스크
각각의 용어는 아래와 같은 의미를 가진다.
- 프로그램 (
Program): 디스크에 저장되어 있는 실행 가능한 형태의 파일. - 프로세스 (
Process): 동작 중인 프로그램 - 쓰레드 (
Thread): 프로세스 내에서 세분되어지는 실행 흐름. - 태스크 (
Task): 작업의 최소 단위. 리눅스에선 프로세스와 쓰레드 모두를 태스크로 관리함.
2. 사용자 입장에서 프로세스 구조
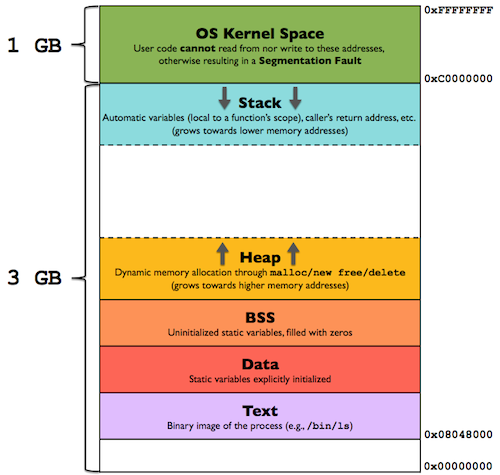
32bit CPU 의 경우 리눅스 커널은 총 4 GiB 크기의 가상 주소 공간을 할당하고 이중 0 ~ 3 GiB 를 사용자 공간으로, 나머지 3 ~ 4 GiB 를 커널 공간으로 사용한다.
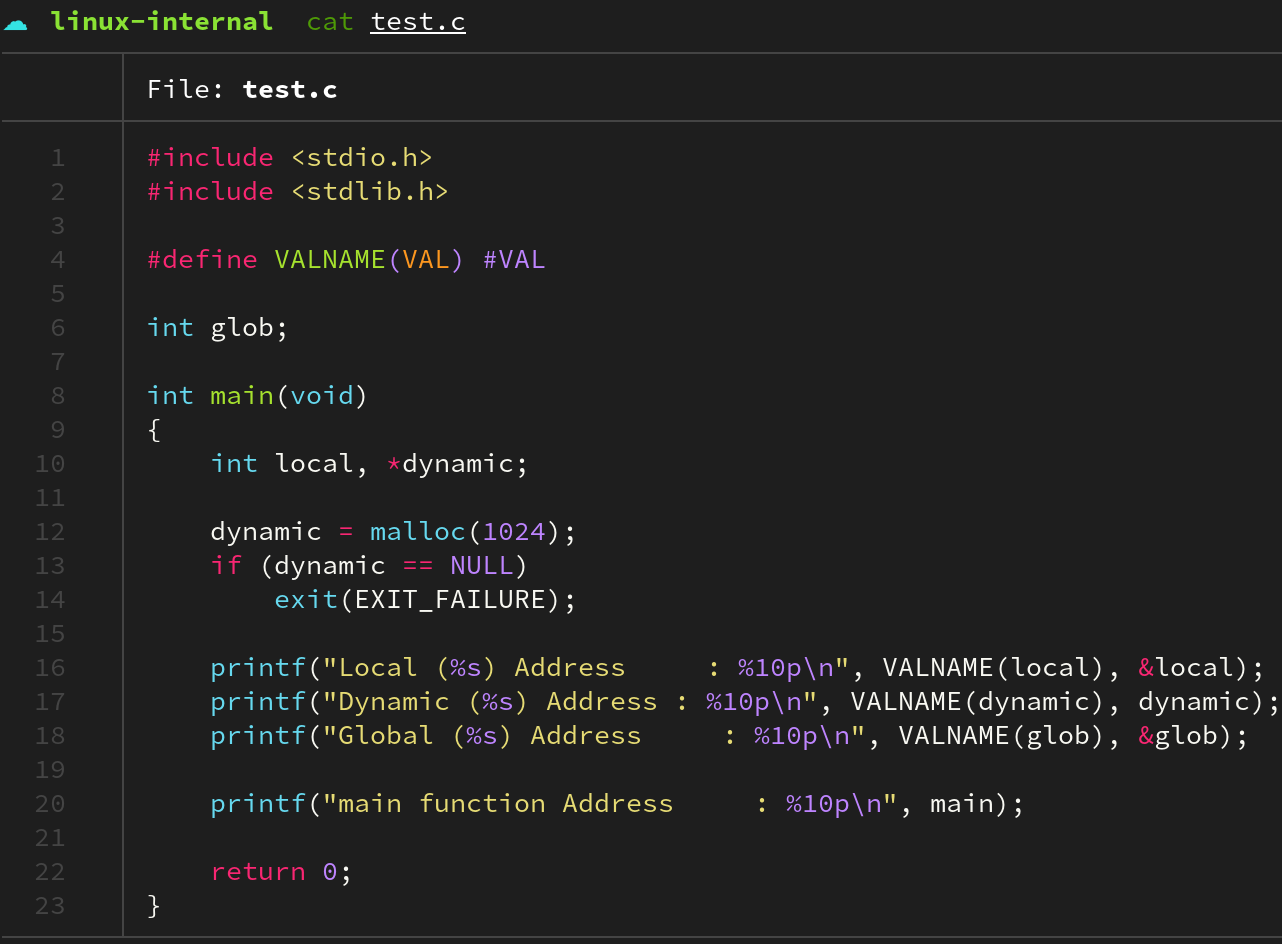
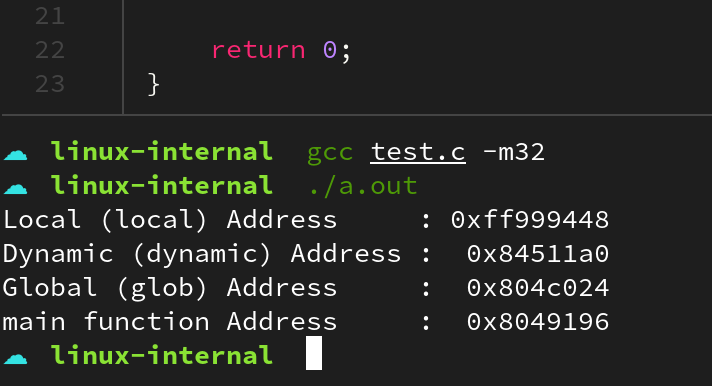
프로세스는 크게 텍스트(text), 데이터(data), 스택(stack), 힙(heap)이라는 네 영역으로 구분되어 진다. 텍스트 영역에는 직접 수행되는 명령어(instruction), 데이터 영역에는 전역 변수(global variable), 스택 영역에는 지역 변수(local variable)과 인자 (arguments), 마지막으로 힙 영역에는 동적 할당(dynamic allocation)한 객체가 존재한다.
3. 프로세스와 쓰레드의 생성과 수행
프로세스 생성
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
int g = 2;
int main(void)
{
pid_t pid;
int l = 3;
int ret;
printf("PID(%d): Parent g = %d, l = %d\n",
getpid(), g, l);
switch (pid = fork()) {
case -1:perror("failed to fork(): ");
exit(EXIT_FAILURE);
case 0: g++; l++;
break;
default:if (wait(&ret) == -1)
perror("failed to wait(): ");
break;
}
printf("PID(%d): g = %d, l = %d\n",
getpid(), g, l);
return 0;
}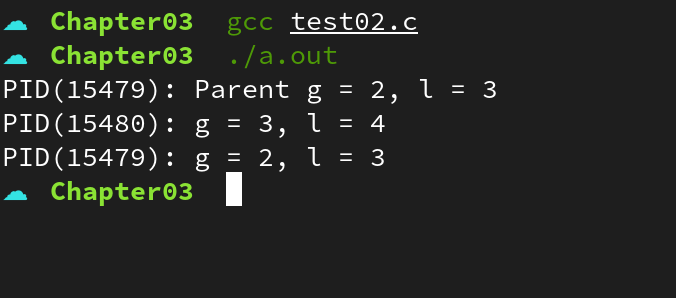
리눅스에서 fork() 함수를 통해 새로운 프로세스를 생성할 수 있다. 위 예제를 통해 프로세스는 독립적인 메모리 공간을 가지는 것을 확인할 수 있다.
쓰레드 생성
#define _GNU_SOURCE
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sched.h>
int g = 2;
int sub_func(void *arg)
{
g++;
printf("PID(%d): Child g = %d\n", getpid(), g);
sleep(2);
return 0;
}
int main(void)
{
int pid;
int child_stack[4096];
int l = 3;
printf("PID(%d): Parent g = %d, l = %d\n",
getpid(), g, l);
if (clone(sub_func, (void *) (child_stack + 4095),
CLONE_VM | CLONE_THREAD | CLONE_SIGHAND, NULL) == -1)
perror("failed to clone(): ");
sleep(1);
printf("PID(%d): Parent g = %d, l = %d\n",
getpid(), g, l);
return 0;
}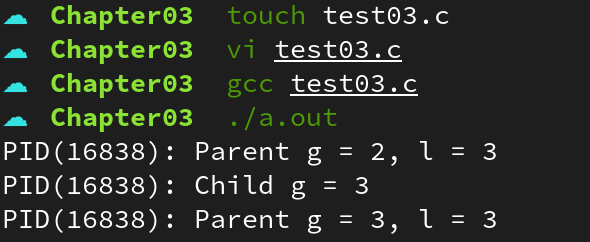
위 예제를 통해 쓰레드는 메모리를 공유하는 것을 볼 수 있다. (동일한 프로세스이므로 프로세스 내 메모리 접근에 대한 제한이 없다. 따라서 서로 다른 쓰레드의 스택에 접근하는 것도 가능하다)
프로세스 실행
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <unistd.h>
int main(void)
{
pid_t pid;
int exit_status;
switch (pid = fork()) {
case -1:perror("failed to fork(): ");
exit(EXIT_FAILURE);
break;
case 0: printf("before exec\n");
execl("./fork", "fork", NULL);
printf("After exec\n");
break;
default:pid = wait(&exit_status);
break;
}
printf("parent \n");
return 0;
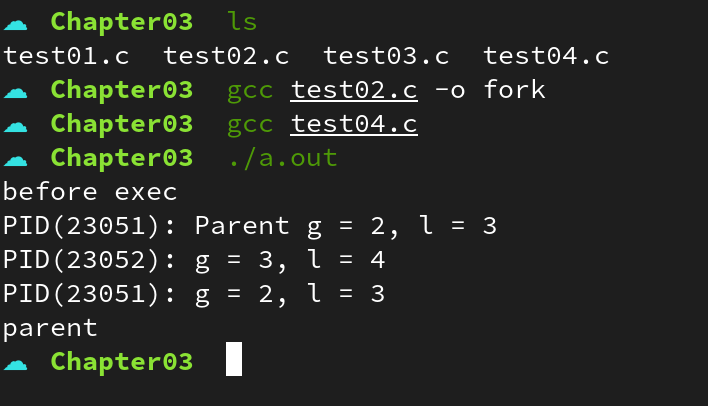
}
+ fork() 와 vfork() 의 차이점
fork() 함수는 앞서 보았던 것처럼 프로세스를 복제하는 함수이다. vfork() 역시 프로세스를 복제(?) 하지만 다음의 기묘한 특징을 가진다.
- 부모 프로세스의 주소 공간을 공유한다. 그것도 완벽히 동일하게.
vfork()를 통해 생성된 자식 프로세스가_exit()이나exec()류 함수를 호출하기 전까지 부모 프로세스는 실행을 멈추고 대기 상태에 들어간다.
그럼 vfork() 는 대체 왜 사용하는걸까? 바로 새로운 자식 프로세스의 생성에 쓰인다.
fork 후 exec하면 되는거 아닌가? 굳이vfork()를 왜 사용해야 하죠?
라고 생각할 수도 있으나 vfork() 함수는 fork() 와 달리 새로운 새로운 프로세스를 위한 메모리 공간을 할당하지 않는다. fork() 함수 역시 COW(Copy-on-Write) 기법을 사용하지만 그 이전에 COW 를 위한 아주 기본적인 자료구조 등은 할당한다. 그러나 vfork() 는 완벽하게 부모 프로세스의 메모리를 공유하기 때문에 메모리 관리에 필요한 기본적인 자료구조 조차 할당하지 않는다.
따라서 vfork() 이후에는 절대 다른 함수를 호출해선 안되고, vfork() 를 호출한 함수를 탈출해선 안되며, vfork() 에서 반환된 pid 를 제외한 그 어떠한 메모리도 써선(write) 안된다.
+ COW : Copy on Write 란 무엇인가?
COW 는 쓰기-시-읽기 기법으로 자원이 수정되었을 때 복사를 하는 컴퓨터 프로그래밍 기법이다. 만일 데이터가 복제 되었지만 수정되지 않았다면, 굳이 새로운 자원을 할당할 필요가 없다. 당연히 복제 되었으니까 새로운 자원을 할당해야 하는거 아닌가? 라 생각할 수 있지만 복제된 데이터가 수정되지 않았다면, 동일한 자원을 참조하기만 하면 된다. 이후에 수정이 발생하면 그때 새로운 자원을 할당하여 복사하는 과정을 진행한다.
COW 를 확인하는 예제 프로그램을 작성해보았다:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(void)
{
char *data;
data = malloc(1024 * 1024 * 1024);
if (data == NULL) {
perror("failed to malloc(): ");
exit(EXIT_FAILURE);
}
printf("Allocate memory\n");
sleep(10);
printf("Modifying data...\n");
for (int i = 0; i < 1024 * 1024; i++)
data[i * 1024] += 1;
printf("all data is modified\n");
sleep(10);
return 0;
}1 GiB 메모리를 동적할당하고 메모리를 1024 byte 씩 뛰어넘어 해당 원소의 값을 1 만큼 증가시키는 예제이다. 필자는 아래와 같이 실행결과를 확인해보았다:
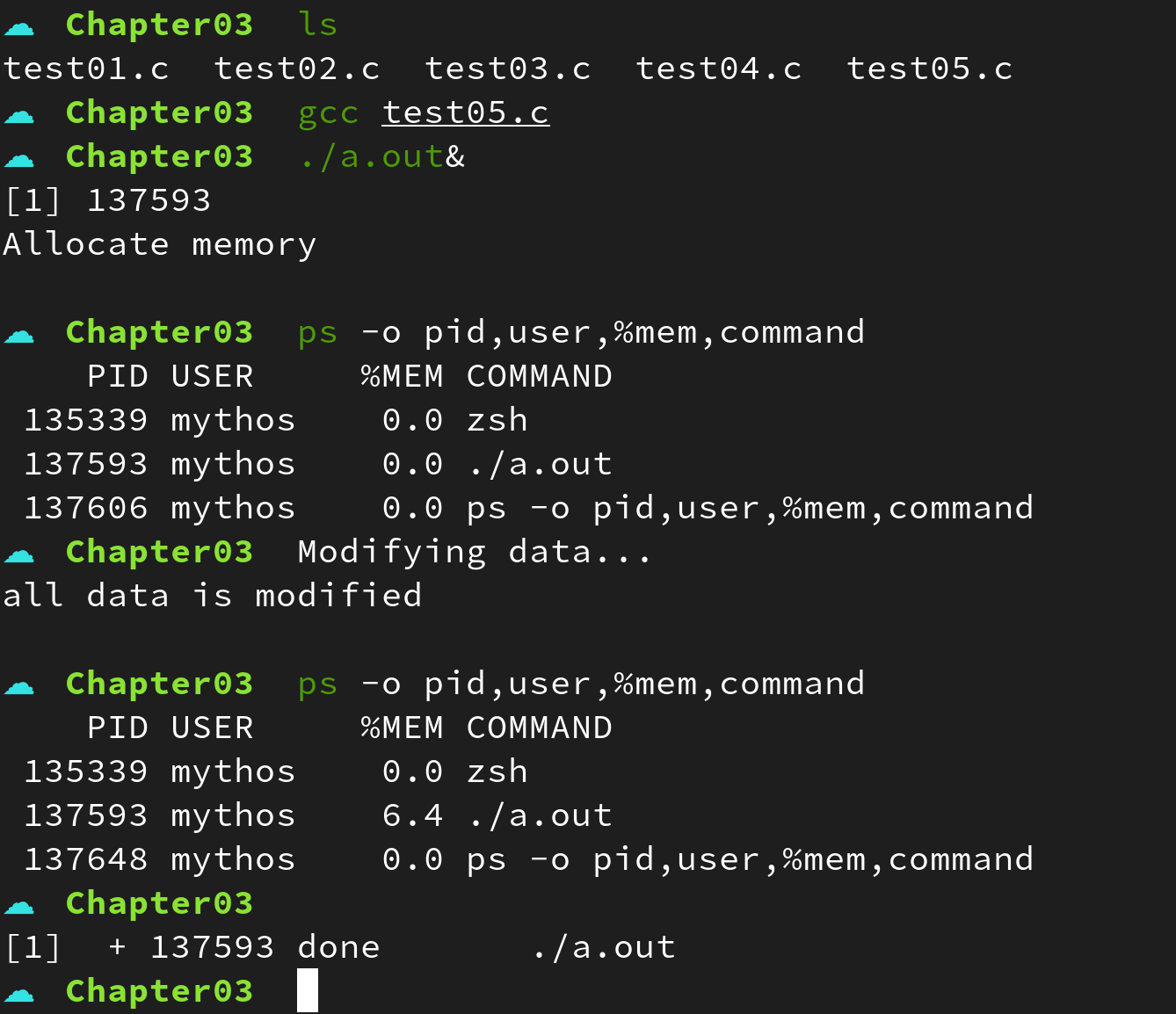
보는 것과 같이 Allocate memory 문자열이 출력된 이후의 메모리 사용량은 0.0 % 였는데 all data is modified 문자열이 출력된 이후에 비로소 메모리 사용량이 6.4 % 로 증가한 모습을 볼 수 있다.
4. 태스크 구조체
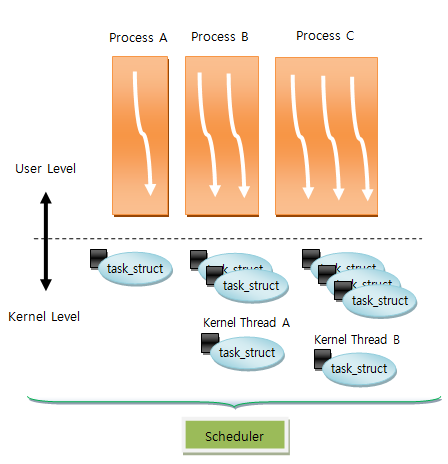
각 프로세스는 화살표 기호의 실행 흐름(쓰레드)을 가진다. 리눅스에서는 이러한 쓰레드 관리를 위해 각 쓰레드 별로 task_struct 구조체를 생성한다. 위 자료구조를 보면 알 수 있듯이 리눅스는 프로세스와 쓰레드를 구분하지 않는다. 쓰레드를 생성하던, 프로세스를 생성하던 동일한 구조체(struct task_struct) 를 통해 관리한다.
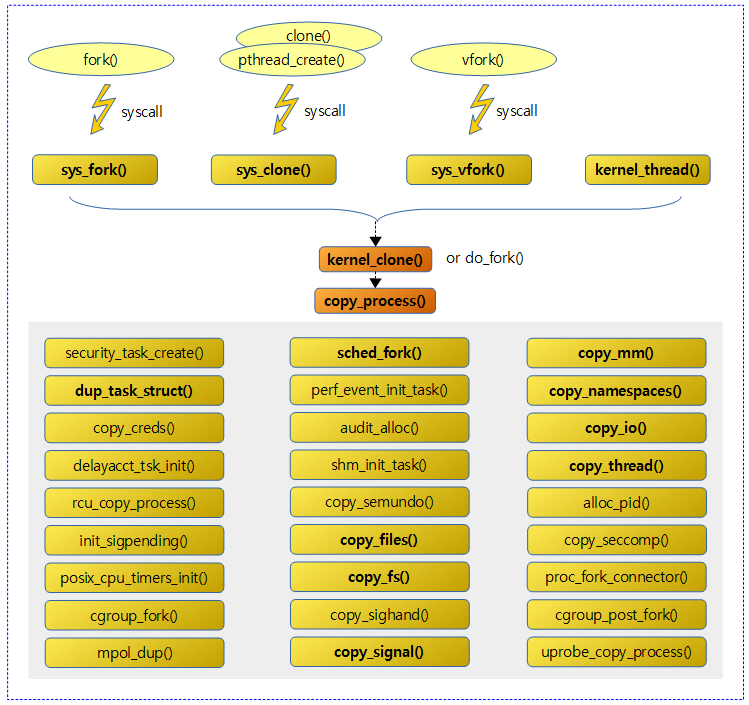
실제 구현에서도 이러한 특징이 나타난다. 프로세스를 복제하는 fork() 함수, 쓰레드를 생성하는 clone() 과 pthread_create() 함수 모두 최종적으로 kernel_clone() 혹은 do_fork() 함수를 호출한다. 커널 입장에선 프로세스 생성과 쓰레드 생성이 모두 태스크 생성 이기 때문에 가능한 일이다.
태스크 성능 분석
앞에서 설명한 것처럼 쓰레드와 프로세스를 구분짓지 않는 방식은 그다지 경량 으로 보이지 않을 수 있다. 그러나 실제로는 그렇지 않다.
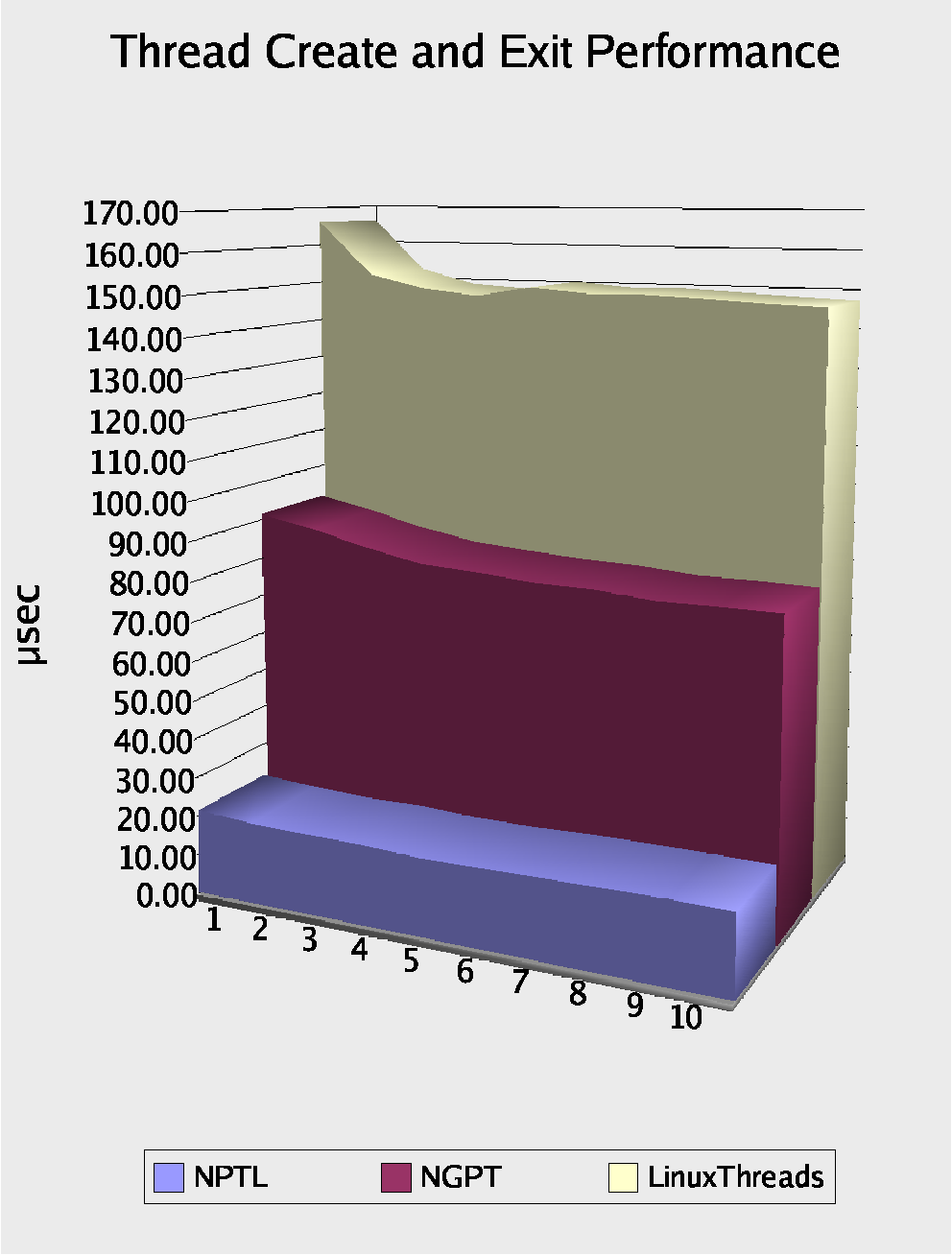
리눅스 커널 2.6 에서 소개된 NPTL(Native POSIX Thread Library) 은 기존 2.4 의 Linux Thread 나 2.5 에서 도입되었던 NGPT(Next Generation POSIX Threads) 에 비해 매우 뛰어난 성능을 보인다.
위 자료는 쓰레드의 생성과 소멸에 따른 성능 분석 표인데 그 크기가 작을수록 빨리 동작함을 의미한다. 가장 바닥에 깔려있는 청색 그래프가 NPTL 이다.
PID, TID, 그리고 TGID
앞서 설명한 것처럼 리눅스는 프로세스와 쓰레드, 심지어 커널 내부에서 사용하는 커널 쓰레드마저도 모두 태스크로 처리한다고 했다. 그럼 사용자 입장에서 프로세스와 쓰레드는 어떻게 구분되어질까?
당연히 각 태스크를 구분하기 위해서는 태스크 고유의 ID 가 필요할 것이다. 리눅스는 이를 모두 TID 라는 이름으로 부른다. 그런데 POSIX 표준에선 하나의 프로세스 내 쓰레드는 같은 PID (Process ID) 를 가져야 한다고 명시되어 있다. 리눅스는 이를 위해 TGID(Thread group ID) 라는 개념을 도입했다.
태스크가 생성되면 커널은 이 태스크를 위한 고유의 PID 를 할당한다. 그런 뒤 사용자가 프로세스를 생성한 경우라면 생성된 태스크의 TGID 를 PID 로 설정한다. 만일 프로세스가 아닌 쓰레드를 생성한 경우라면, 고유의 PID 를 할당하고 TGID 를 부모 프로세스의 PID 로 초기화한다.
따라서 하나의 프로세스의 속해 있는 모든 쓰레드들은 동일한 TGID 를 가지게 되며, 각 프로세스 혹은 쓰레드는 고유의 PID 를 소유하게 된다. 이제 프로그램을 작성하여 PID 와 TID, 그리고 TGID 를 출력하는 간단한 예제 프로그램을 작성해보겠다.
예제: fork() 함수 (프로세스 생성)
#include <stdio.h>
#include <stdlib.h>
#include <sys/wait.h>
#include <unistd.h>
#include <linux/unistd.h>
int main(void)
{
int pid, ret;
switch (pid = fork()) {
case -1:perror("failed to fork(): ");
exit(EXIT_FAILURE);
case 0: printf("[Child] TGID: %d, PID: %ld\n",
getpid(), syscall(__NR_gettid));
break;
default:printf("[Parent] TGID: %d, PID: %ld\n",
getpid(), syscall(__NR_gettid));
if (waitpid(pid, &ret, 0) == -1) {
perror("failed to waitpid(): ");
exit(EXIT_FAILURE);
} else printf("return from the child: %d\n", ret);
break;
}
return 0;
}실행 결과
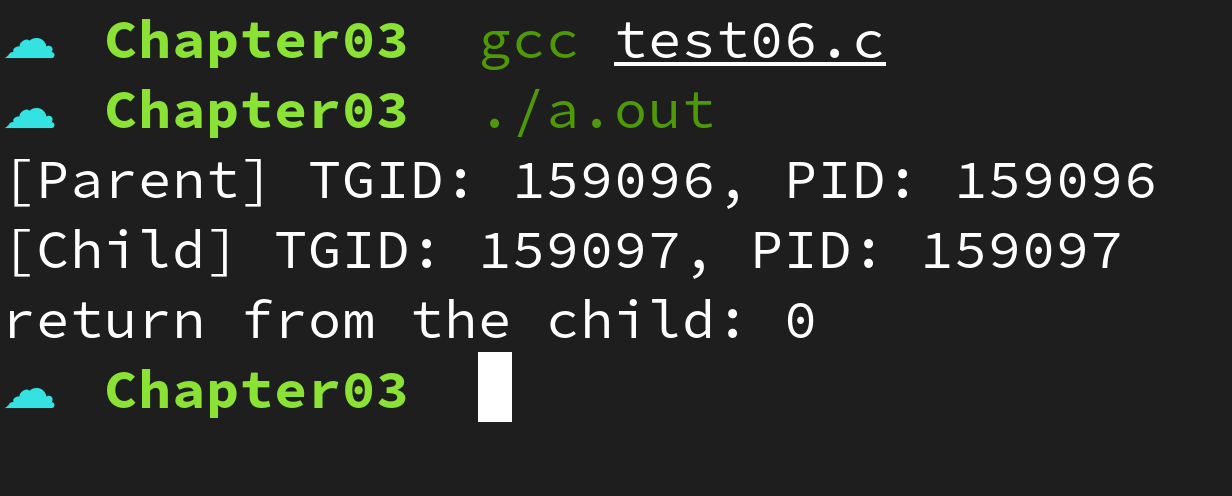
위 예제는 fork() 함수를 호출하여 자식 프로세스와 부모프로세스의 TGID 와 PID 를 호출한 결과를 출력한 것이다. 서로 다른 프로세스이므로 서로 다른 TGID 와 서로 다른 PID 를 가지는 것을 확인할 수 있다.
예제: pthread() 함수 (쓰레드 생성)
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <errno.h>
#include <unistd.h>
#include <pthread.h>
#include <linux/unistd.h>
void *func(void *data)
{
int id;
int i;
pthread_t tid;
id = *((int *) data);
printf("[Child] TGID: %d, PID: %ld, pthread_self: %lu\n",
getpid(), syscall(__NR_gettid), pthread_self());
sleep(2);
return (void *) 10 + id;
}
#define ERROR_HANDLING(STR, ...) \
fprintf(stderr, STR, ## __VA_ARGS__), exit(EXIT_FAILURE)
#define SIZE(X) (sizeof(X) / sizeof(*X))
int main(void)
{
int pid, status;
int a = 1;
int b = 2;
void *ret;
pthread_t tid[2];
printf("before pthread_create\n");
if ((pid = pthread_create(&tid[0], NULL, func, (void *) &a)) != 0)
ERROR_HANDLING("failed to pthread_create(): %s", strerror(pid));
if ((pid = pthread_create(&tid[1], NULL, func, (void *) &b)) != 0)
ERROR_HANDLING("failed to pthread_create(): %s", strerror(pid));
for (int i = 0; i < SIZE(tid); i++) {
pthread_join(tid[i], &ret);
printf("pthread_join(): %p\n", ret);
}
printf("[Parent] TGID(%d), PID(%ld)\n",
getpid(), syscall(__NR_gettid));
return 0;
}실행결과
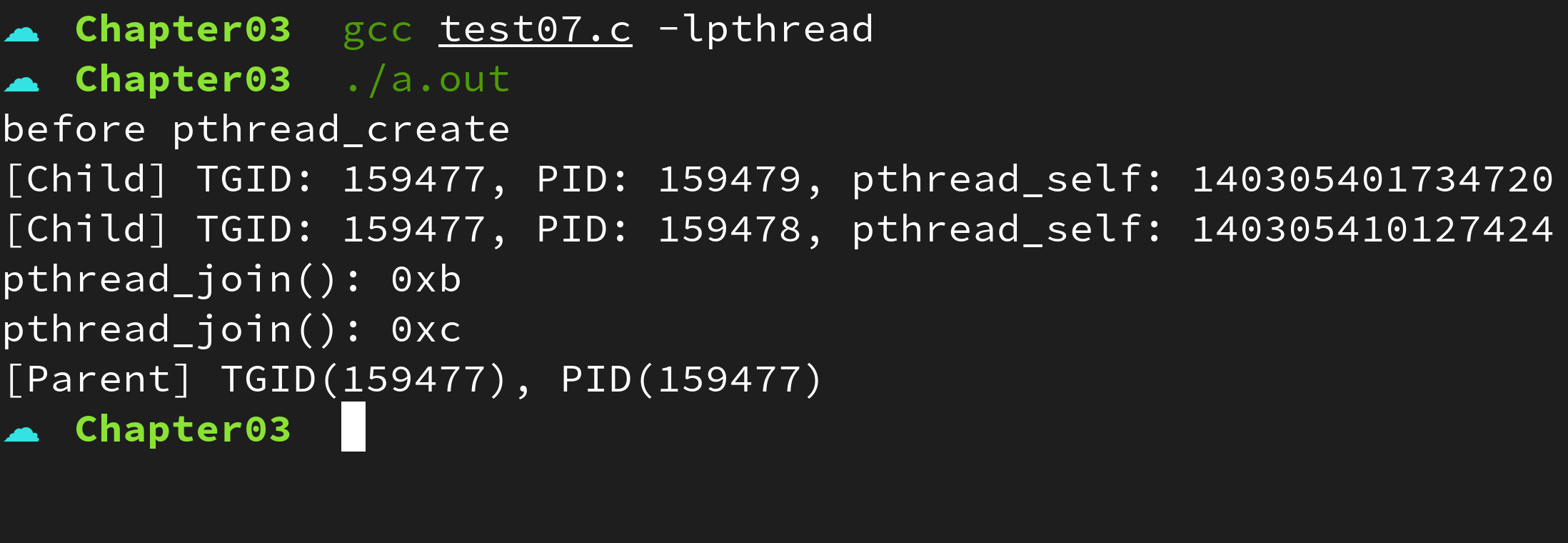
pthread_create() 함수로 생성된 쓰레드의 TGID 는 부모 프로세의 TGID (159477) 로 동일하지만 PID 는 각기 다름을 확인할 수 있다.
예제: clone() 함수 (프로세스와 쓰레드 생성)
#define _GNU_SOURCE
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sched.h>
#include <linux/unistd.h>
int func(void *arg)
{
printf("[Chid] TGID: %d, PID: %ld\n",
getpid(), syscall(__NR_gettid));
sleep(2);
return 0;
}
int main(void)
{
int pid;
int child_stack1[4096];
int child_stack2[4096];
printf("before clone\n");
printf("[Parent] TGID: %d, PID: %ld\n",
getpid(), syscall(__NR_gettid));
clone(func, (void *) child_stack1 + 4095,
CLONE_CHILD_CLEARTID | CLONE_CHILD_SETTID, NULL);
clone(func, (void *) child_stack2 + 4096,
CLONE_VM | CLONE_THREAD | CLONE_SIGHAND, NULL);
sleep(1);
printf("after clone\n");
return 0;
}실행결과
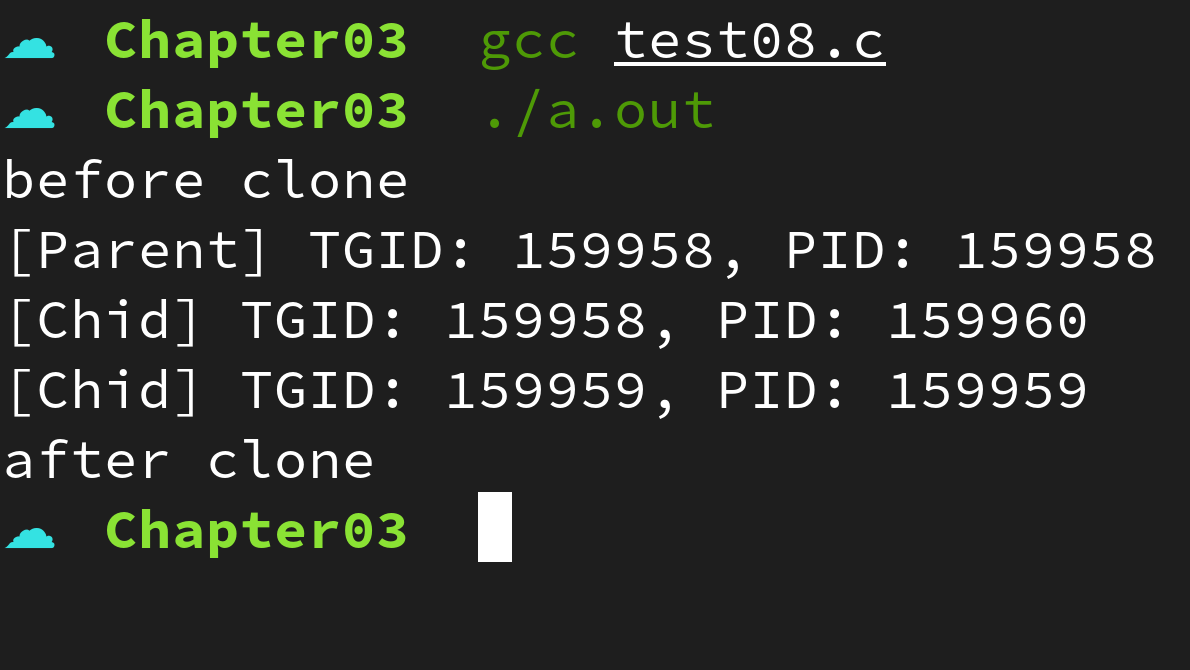
위 예제는 clone() 함수를 통해 쓰레드와 프로세스를 만드는 과정을 보여준다. clone() 함수의 인자로 CLONE_CHILD_CLEARID 와 CLONE_CHILD_SETTID 를 설정하면 커널은 자원공유가 이뤄지지 않는 태스크(우리는 이를 프로세스라 부른다)를 생성하고, CLONE_THREAD 를 설정하면 커널은 호출자 태스크의 자원을 공유하는 태스크(우리는 이를 쓰레드라 부른다)를 생성한다.
실행결과를 확인해보면 clone() 함수로 생성된 태스크 중 하나는 clone() 함수를 호출한 태스크와 동일한 TGID 를 가지지만, 반대는 다른 TGID 를 가진다. 그러나 역시 PID 는 세 태스크 모두 서로 다르다.
출처
[이미지] https://gabrieletolomei.wordpress.com/miscellanea/operating-systems/in-memory-layout/
[이미지] https://jinkyu.tistory.com/67
[이미지] http://jake.dothome.co.kr/do_fork/
[책] 리눅스 커널 내부구조 (백승제, 최종무 저)
[사이트] https://techdifferences.com/difference-between-fork-and-vfork.html
[이미지] https://www.semanticscholar.org/paper/The-Native-POSIX-Thread-Library-for-Linux-Drepper-Molnar/ffced47e5604b66736d365030bfe532d11285433
