5. 태스크 문맥
앞서 모든 프로세스와 쓰레드는 태스크로 관리되며 이는 구조체로 저장된다고 얘기했다. 그럼 위 구조체에는 오직 TID 와 TGID 만 존재할까? 아니다, 절대 그렇지 않다. 태스크를 관리하기 위해 필요한 정보는 이보다 훨씬 많다.
태스크는 실행 중 다양한 형태의 파일을 열 수 있고 이를 관리하기 위한 파일 서술자(file descriptor) 존재하며, 이는 태스크가 관리해야 하는 정보이다. 또한 태스크는 스케쥴링을 위한 우선순위(priority) 와 CPU 사용량 등의 정보, 태스크간 가족 관계(부모(Parent), 형제(sibling) 등의 정보까지 매우 매우 다양하다.
리눅스 커널의 struct task_struct 구조체는 include/linux/sched.h 파일에서 확인이 가능하다. 태스크가 관리하는 각 정보들은 살펴보려 하는데 그 내용이 매우 방대하여 다 설명하긴 어렵다.
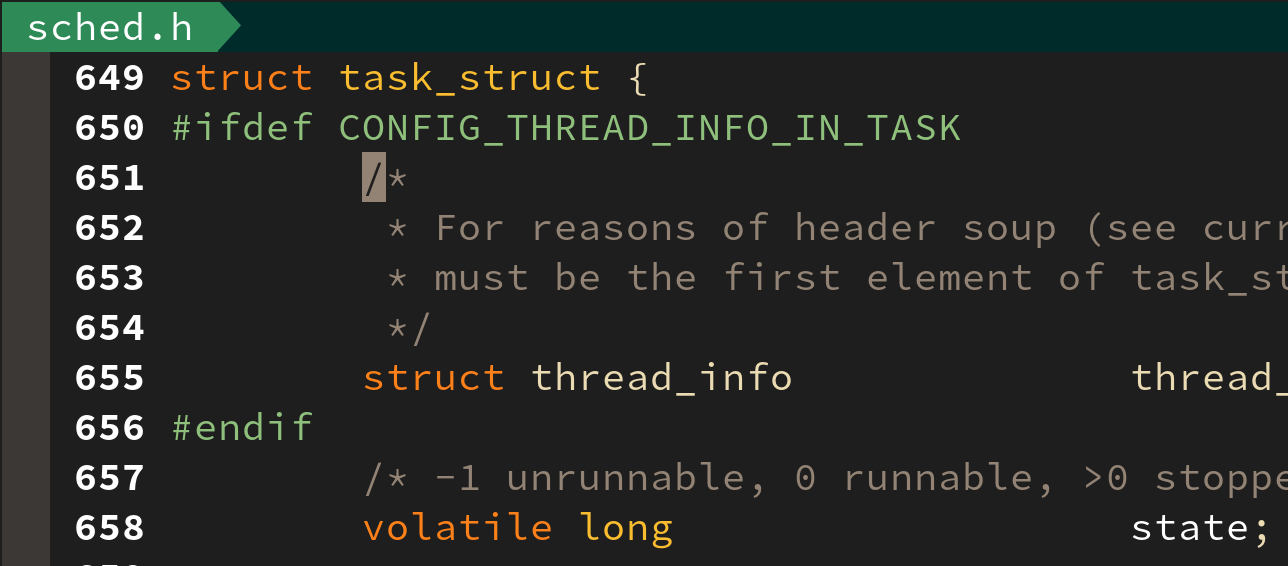
태스크 구조체(struct task_struct) 의 길이는 무려 740 줄(1389 - 649)에 달한다. 이를 모두 설명할 순 없고 중요한 일부 내용만 추려서 살펴보려 한다.
1. task identification
태스크를 인식하기 위한 변수들로 TID, TGID, 태스크 탐색을 위한 hash 등이 존재한다. 또한 태스크의 권한에 해당하는 UID, EUID, SUID, FSUID 등의 ID 또한 여기에 해당한다.


2. state
태스크는 생성부터 소멸까지 많은 상태(state)를 거치며 이를 관리하기 위한 변수가 존재한다. 이 변수에는 TASK_RUNNING, TASK_INTERRUPTIBLE, TASK_UNINITERRUPTIBLE, TASK_STOPPED, TASK_TRACED, EXIT_DEAD, EXIT_ZOMBIE 등의 값이 들어간다.
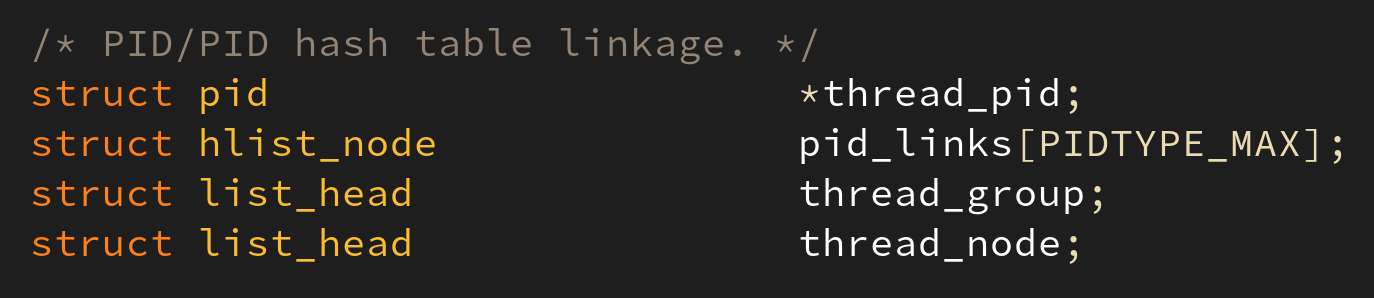
3. task relationship
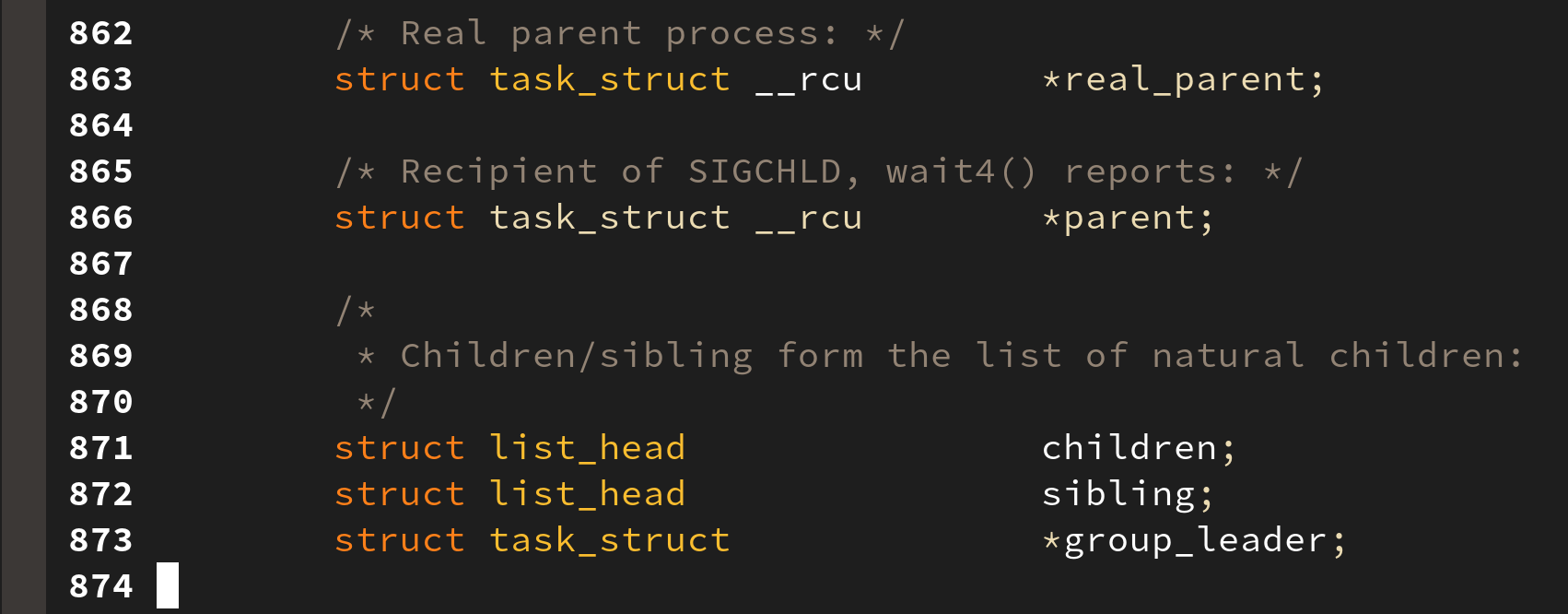
태스크는 생성되면서 가족 관계를 가진다. 부모(Parent) 와 자식(Child)부터 형제관계(Sibling) 까지 모두 기록된다:
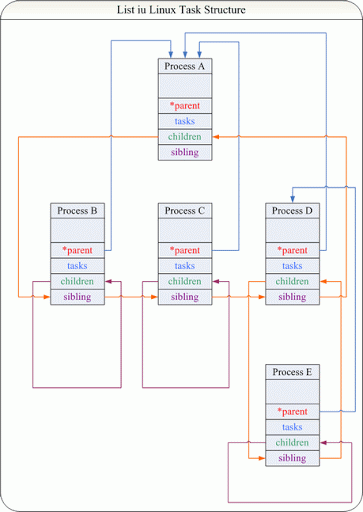
이들은 모두 이중 연결 리스트(Doubly Linked List) 로 관리되어지며 이들은 모두 init_task 로부터 시작된다:
4. scheduling information
task_struct 에서 스케쥴링과 관련된 변수는 우선순위(prio), 정책(policy), 허용되는 CPU (cpus_allowd), 할당시간(time_slice), 실시간 우선순위 (rt_priorty) 등이 여기에 해당한다.
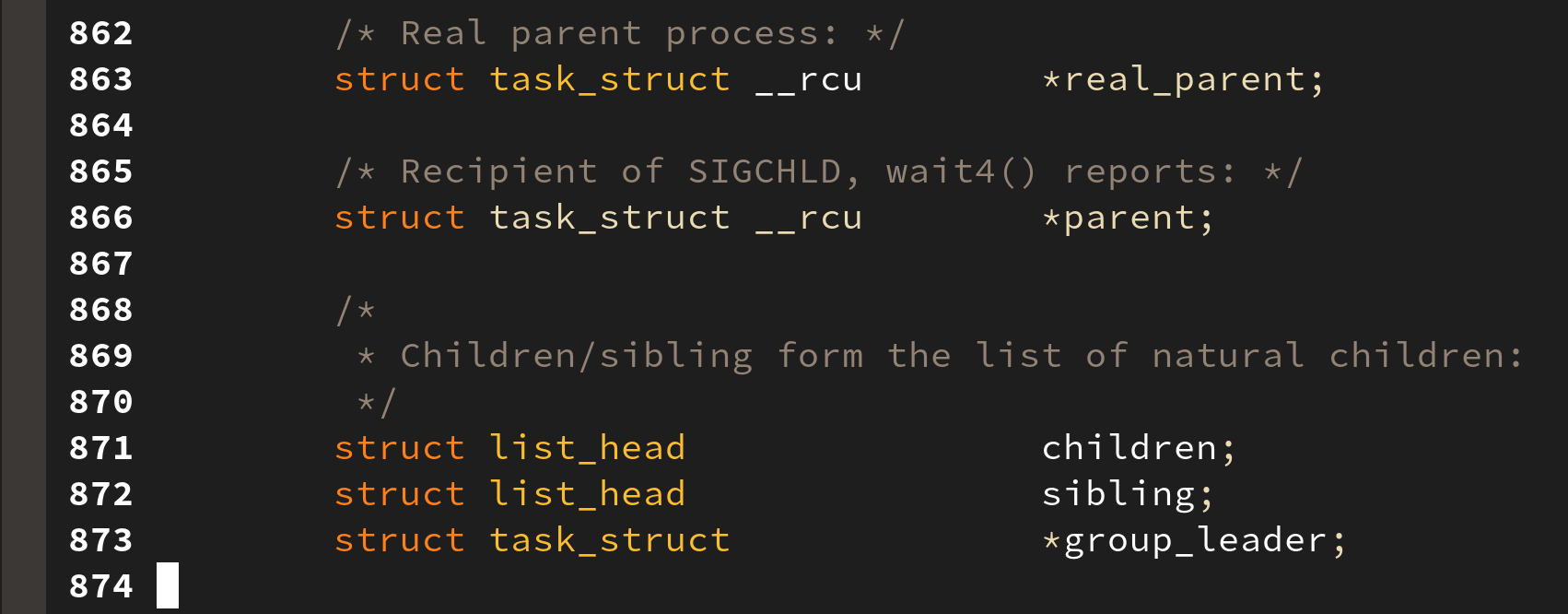
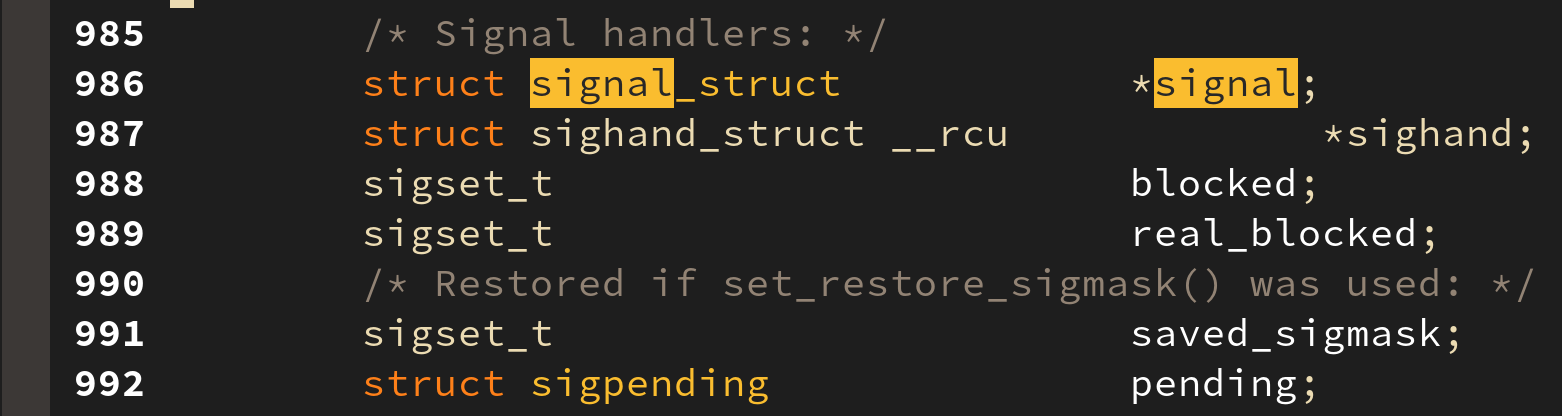
5. signal information
시그널은 태스크에게 비동기적인 사건(타이머, 키보드 입력 등)의 발생을 알리는 매커니즘으로 이와 관련된 변수(시그널 블럭 마스크, 시그널 펜딩 큐 등) 들 역시 저장되어 진다. 리눅스에서 네트워크 프로그래밍을 해보았다면 이러한 시그널 핸들링 경험이 있을 것이다.
6. memory information
태스크는 자신의 명령어와 데이터를 텍스트, 데이터, 스택, 그리고 힙 공간 등에 저장한다. 이는 앞서 2. 사용자 입장에서 프로세스 구조 에서 확인해본 바가 있다. 이 공간에 대한 접근 제어 정보와 위치와 크기 등을 저장하는 변수들이 존재한다. 앞선 COW 역시 접근 제어 정보를 바탕으로 동작하게 된다.
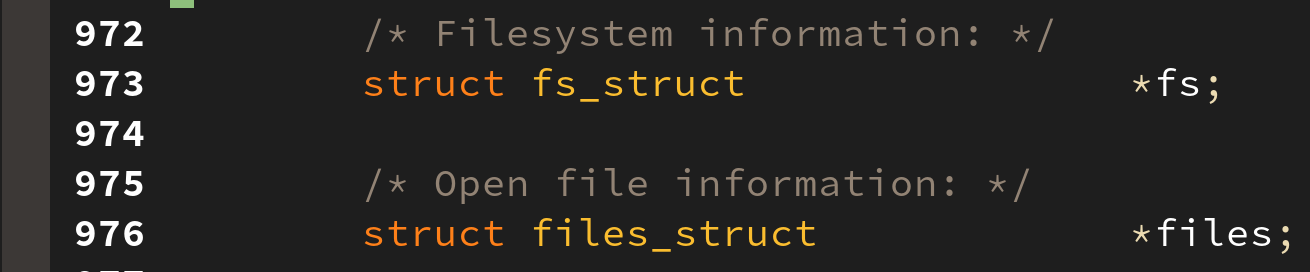
7. file information
파일 정보는 태스크와 관련이 없다고 생각할 수 있으나, 태스크가 동작 중에 파일을 열 수도 있으며, 이를 관리하기 위한 정보를 담고 있다:
8. format
리눅스는 Linux exec 도메인 뿐만 아니라 BSD(berkeley software distribution) 나 SVR4 (System V Release 4) 등의 도메인 또한 지원한다. 한마디로 BSD 나 SVR4 에서 컴파일된 실행파일 역시, 재컴파일 하지 않고 바로 실행이 가능하다는 뜻이다.

9. resource limits
태스크가 사용할 수 있는 자원의 한계를 저장한 변수이다. 알다시피 기본적으로 파일 서술자의 크기는 프로세스마다 제한되어 있다.

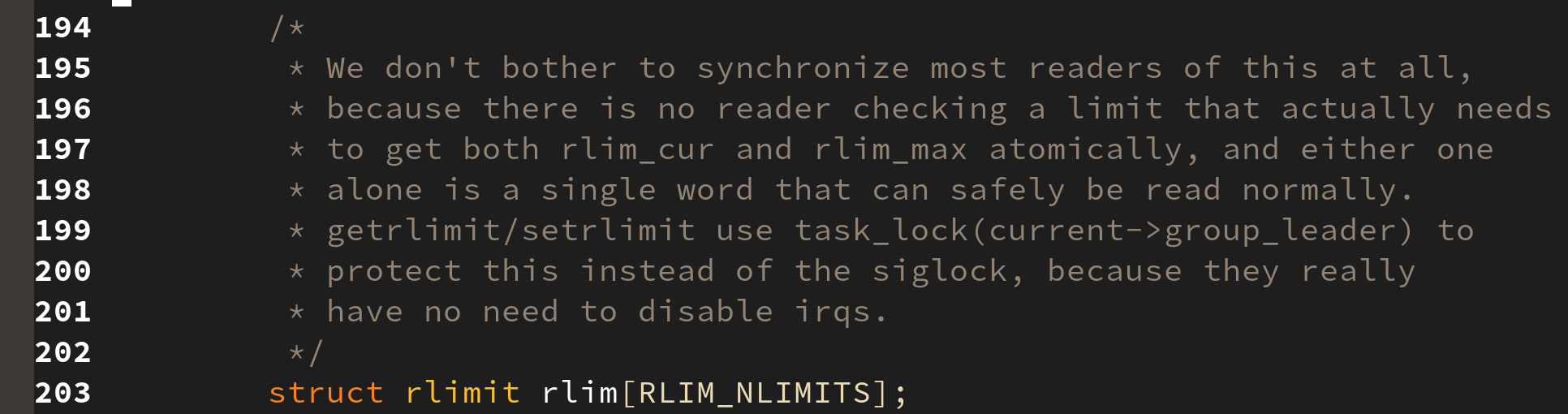

이는 task_struct 안의 signal 멤버 변수 안의 존재하며, 현재 리눅스의 한계는 16 으로 정해져 있다.
6. 상태 전이와 실행 수준의 변화
상태 전이(State Transition)
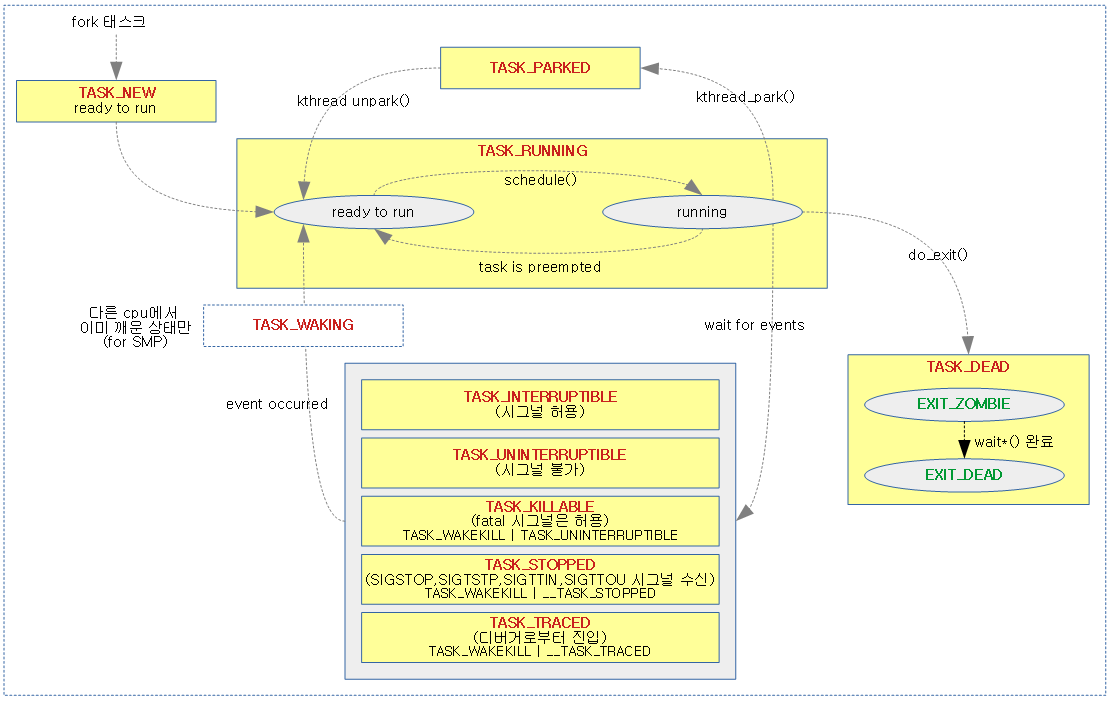
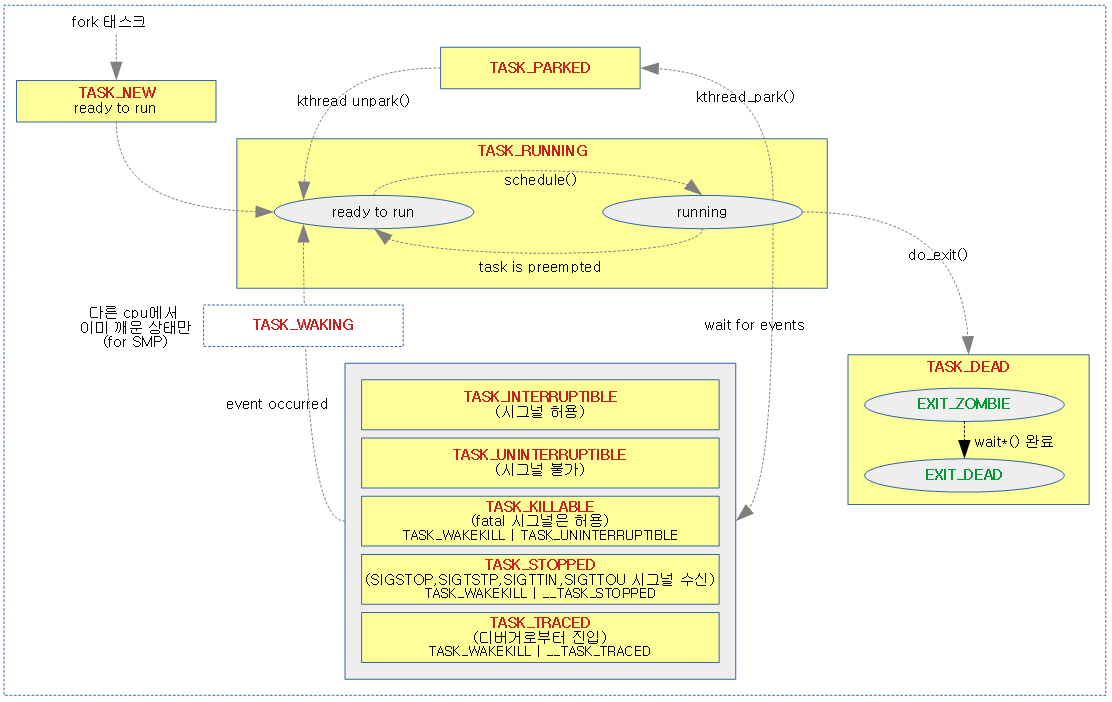
리눅스의 태스크는 생성부터 소멸될때까지 다양한 상태를 거치게 된다. 가장 먼저 태스크가 생성되면 태스크는 준비 상태(TASK_RUNNING) 가 된다. 스케쥴러는 준비 중인 여러 태스크 중 실행시킬 태스크를 선택하여 수행한다.
따라서 TASK_RUNNING 상태는 언제든지 실행 가능한 준비 상태(ready to run) 과 현재 실행 중인, 다른 말로는 CPU 를 독점중인 (running) 두 가지 상태가 존재한다.
running 상태의 태스크는 발생하는 사건에 따라 다음과 같은 상태로 전이할 수 있다.
-
태스크가 자신이 해야 할 일을 다 끝내고
exit()를 호출하면 (혹은kill되거나)TASK_DEAD상태로 전이된다. 이 상태에서는 대부분의 자원을 모두 커널에게 반납하고 부모 프로세스에게 자신이 종료된 이유를 알리기 위한EXIT_STATUS(종지 상태) 와 종료된 이유(errno) 와 같은 기본적인 정보만 유지하다가, 부모 프로세스가 종지 상태를 거둬들이면 그제서야 최종적으로 모든 자원이 커널에 반환되어 태스크는 소멸한다.
만일 자식 프로세스가TASK_DEAD상태로 전이되기 전에 부모 프로세스가TASK_DEAD상태로 먼저 전이되어 진다면 어떻게 될까? 고아가 된 자식 프로세스의 정보가 계속EXIT_ZOMBIE상태로 남아 시스템에 자원을 갉아먹진 않을까? 라 생각할 수 있지만 다행히도 이러한 고아 태스크(Orphan task)는 최초의 프로세스(init) 프로세스로 인가되어 진다. 그래서 앞서 살펴봤듯 진짜 부모 프로세스와 현재 부모 프로세스가 따로 나뉘어 있는 것이다. -
실행(
TASK_RUNNING(running)) 상태에서 실제 수행되던 태스크가 자신에게 할당된CPU 시간, 다른 말로 타임 슬라이스(time slice) 를 모두 소진하거나, 보다 높은 우선순위를 가지는 태스크(rt task등) 로 인해 준비(TASK_RUNNING(ready)) 상태로 전이되는 경우이다. 이 경우에는 커널이 여러 태스크들이CPU를 공평하게 사용할 수 있도록 해주는 위함으로 일반 태스크의 경우CFS(Completeely Fair Scheduling)기법을 사용한다. -
SIGSTOP,SIGTSTP,SIGTTIN,SIGTOU등의 시그널을 받은 태스크는TASK_STOPPED상태로 전이되며, 추후SIGCONT시그널을 받아 다시TASK_RUNNING(ready)상태로 전환된다. 한편, 디버거의ptrace()함수 호출에 의해 디버깅되고 있는 태스크는TASK_TRACED()상태로 전이될 수 있다. -
실행(
TASK_RUNNING(running)) 상태에 있던 태스크가 특정한 사건을 기다려야 할 필요가 있다면 대기 상태(TASK_INTERRUPTIBLE,TASK_UNINTERRUPTIBLE,TASK_KILLABLE) 로 전이한다.
태스크가 디스크 같은 주변 장치에 요청을 보내고 그 요청이 완료되기까지 기다리거나, 사용 중인 시스템 자원 대기 등이 대표적인 예이다.TASK_INTERRUPTIBLE상태에서는 시그널에 반응하지만TASK_UNINTERRUPTIBLE은 시그널에 반응하지 않는다. 그러나 치명적 시그널(fatal signal) 등에는 반드시 반응해야 하는 태스크의 경우TASK_KILLABLE상태로 전이된다.대기 상태로 전이한 태스크는 큐에 삽입되어 스케쥴러가 부를 때까지 대기한다. 얼핏 생각해보면 큐에 삽입하는게 좋아 보이지 않는다. 왜냐하면 큐는 선입선출(
First-In First-Out) 구조이기 때문에 계속 비슷한 태스크만 실행될 수 있기 때문이다. 그러나 이는 이전에CPU를 선점했던 태스크가 다시CPU를 선점할 수 있도록 의도하여 설계된 것이다. 이렇게 되면 캐쉬에 이전 태스크의 데이터가 남아 있을 가능성이 높기 때문에 성능상의 이점(cache hit)을 가질 수 있다.
실행 수준(running-level)
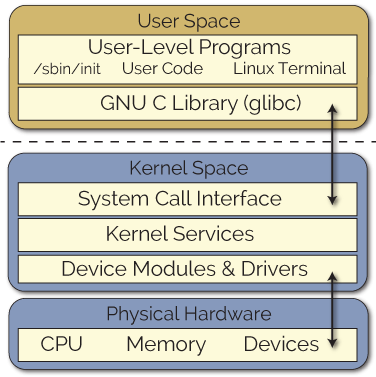
실행 중인 태스크는 두 가지 실행 권한을 가질 수 있다: 사용자 수준 실행(user-level running)과 커널 수준 실행(kernel-level running). 사용자 수준 실행 상태는 CPU 에서 유저가 제작한 응용 프로그램이나 라이브러리 코드를 실행하는 상태인 반면, 커널 수준 실행 상태는 CPU ㅇ에서 커널 코드의 일부분을 수행하는 상태이다. 이 경우 사용자 수준보다 더 높은 권한의 커널 권한으로 코드를 수행한다. 이때부턴 커널의 내부 자료 구조에 접근하거나 일반 유저에게는 사용이 금지되어 있는 특권 명령어를 수행할 수 있게 된다.
사용자 수준 실행 상태에서 커널 수준 실행 상태로 전이할 수 있는 방법은 총 두 가지이다: 시스템 호출과 인터럽트의 발생. 유저 수준의 태스크가 시스템 호출을 요청하면 리눅스의 커널에 트랩(소프트웨어가 생성한 인터럽트)이 발생하여 태스크의 상태가 커널 수준 실행 상태로 전이되며 시스템 호출 처리 루틴으로 제어가 넘어간다.
두 번째 방법은 인터럽트(하드웨어에서 생성된 인터럽트) 의 발생이다. 이 경우에도 마찬가지로 실행 중이던 태스크가 사용자 수준에서 동작하더라도 커널 수준 실행 상태로 전이되어 커널의 인터럽트 처리 루틴을 제어가 넘어간다.
앞서 말했던 메모리 구조를 환기해보자. 32비트 리눅스 운영체제는 3 GiB 를 사용자 영역으로 남은 1 GiB 를 커널 영역으로 사용한다. 리눅스 커널 역시 실상은 C 로 작성된 프로그램이므로 실행을 위해선 메모리 공간을 필요로 한다. 함수가 호출되어 지역 변수를 저장하려면 스택이 필요하고 이러한 공간을 위해 4 GiB 중 1 GiB 를 사용하여 데이터를 저장한다.
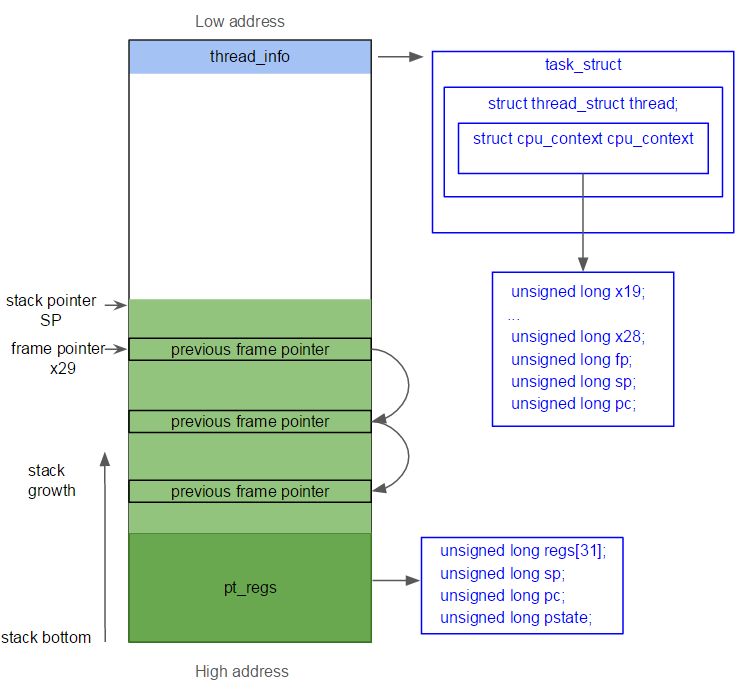
리눅스 커널은 태스크가 생성될 때마다 태스크 별로 8 KiB 혹은 16 KiB 의 스택(이 크기는 설정을 통해 변경할 수 있다) 을 할당하여 요청한 작업을 처리해준다. 결론적으로 리눅스 커널은 태스크가 생서오디면 struct task_struct 구조체와 커널 스택을 할당하게 된다.
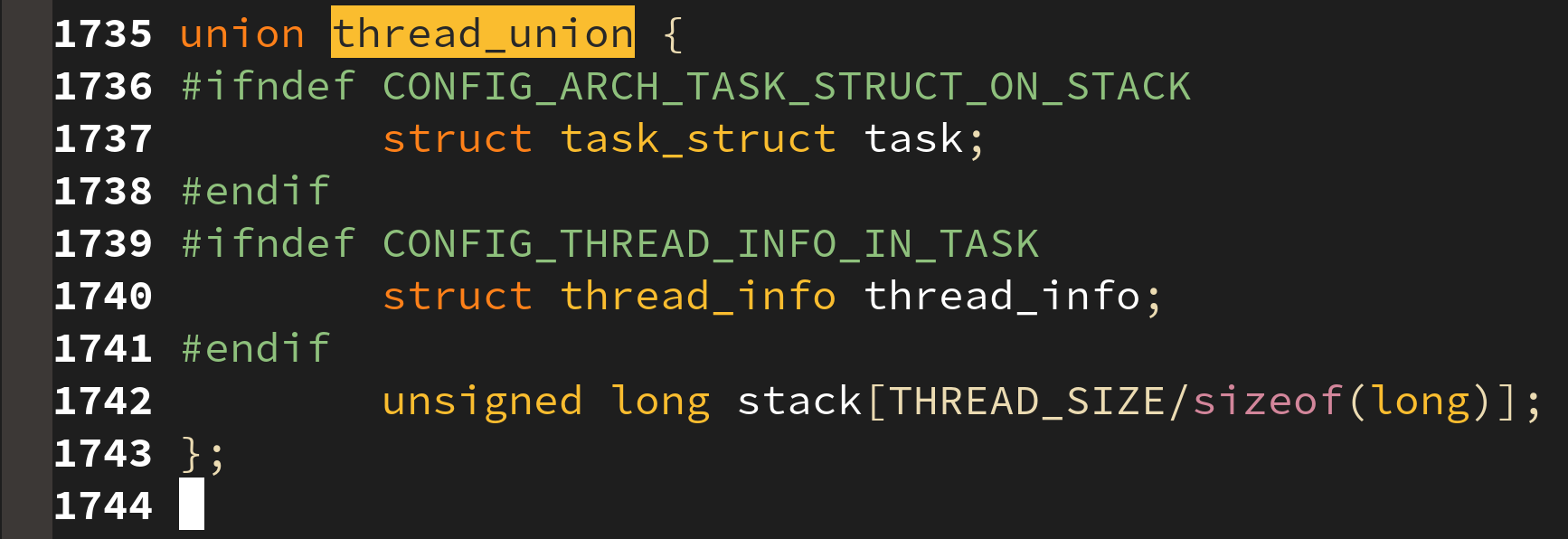
쓰레드당 할당되는 커널 스택은 thread_union 이라 불리며, thread_info 구조체를 포함하고 있다. thread_info 구조체는 task_struct 를 가리키는 포인터, 스케쥴링 플래그, 태스크의 포맷 등을 저장하고 있다.
만일 태스크가 시스템 호출으로 인해 커널 수준 실행 상태로 진입한 뒤, 모든 작업을 다 수행하고 다시 사용자 수준으로 복귀하여 수행하던 곳에서부터 다시 작업을 시작하기 위해서는 시스템 호출 전의 작업 상황을 어딘가에 저장해야 한다. 이러한 데이터는 커널 스택 안에 현재 레지스터의 값들을 저장하는 구조체인 struct cpu_context_save 에 저장되어 진다.
struct pt_regs {
unsigned long r0;
unsigned long r1;
unsigned long r2;
unsigned long r3;
unsigned long r4;
unsigned long r5;
unsigned long r6;
unsigned long r7;
unsigned long r8;
unsigned long r19;
unsigned long r20;
unsigned long r21;
unsigned long r22;
unsigned long r23;
unsigned long r24;
unsigned long r25;
unsigned long r26;
unsigned long r27;
unsigned long r28;
unsigned long hae;
/* JRP - These are the values provided to a0-a2 by PALcode */
unsigned long trap_a0;
unsigned long trap_a1;
unsigned long trap_a2;
/* These are saved by PAL-code: */
unsigned long ps;
unsigned long pc;
unsigned long gp;
unsigned long r16;
unsigned long r17;
unsigned long r18;
};
struct cpu_context_save {
__u32 r4;
__u32 r5;
__u32 r6;
__u32 r7;
__u32 r8;
__u32 r9;
__u32 sl;
__u32 fp;
__u32 sp;
__u32 pc;
__u32 extra[2]; /* Xscale 'acc' register, etc */
};
struct thread_info {
unsigned long flags; /* low level flags */
int preempt_count; /* 0 => preemptable, <0 => bug */
mm_segment_t addr_limit; /* address limit */
struct task_struct *task; /* main task structure */
__u32 cpu; /* cpu */
__u32 cpu_domain; /* cpu domain */
#ifdef CONFIG_STACKPROTECTOR_PER_TASK
unsigned long stack_canary;
#endif
struct cpu_context_save cpu_context; /* cpu context */
__u32 syscall; /* syscall number */
__u8 used_cp[16]; /* thread used copro */
unsigned long tp_value[2]; /* TLS registers */
#ifdef CONFIG_CRUNCH
struct crunch_state crunchstate;
#endif
union fp_state fpstate __attribute__((aligned(8)));
union vfp_state vfpstate;
#ifdef CONFIG_ARM_THUMBEE
unsigned long thumbee_state; /* ThumbEE Handler Base register */
#endif
};커널이 시스템 호출의 서비스를 완료하거나 인터럽트 처리를 완료하면 사용자 수준 실행 상태로 전이하며 이때 아래의 일들을 처리한다:
- 커널은 현재 실행 중인 태스크가 시그널을 받았는지 확인하고, 받았다면 거기에 대한 적절한 처리를 진행한다. (프로그램 강제 종료, 시그널 핸들러 호출 등)
- 다시 스케쥴링해야 할 필요가 있다면 스케쥴러를 호출한다.
- 커널 내 연기된 루틴들이 존재하면 이들을 수행한다.
7. 런큐와 스케쥴링
여러 개의 태스크들 중 다음 번에 수행시킬 태스크를 선택하여 CPU 자원을 할당하는 과정을 스케쥴링(Scheduling)이라 한다. 리눅스의 태스크는 두 개로 나뉜다: 실시간 태스크(real-time task) 와 일반 태스크. 리눅스는 140 단계의 우선순위 중 실시간 태스크를 위해 0 ~ 99 까지의 단계를 제공(숫자가 낮을수록 높은 우선순위)하며 일반 태스크를 위해 100 ~ 139 까지의 단계를 제공한다.
런큐(Runqueue)
리눅스는 스케쥴링 작업 수행을 위해 수행 가능한 상태의 태스크를 런큐(Runqueue) 라는 자료구조로 관리한다.
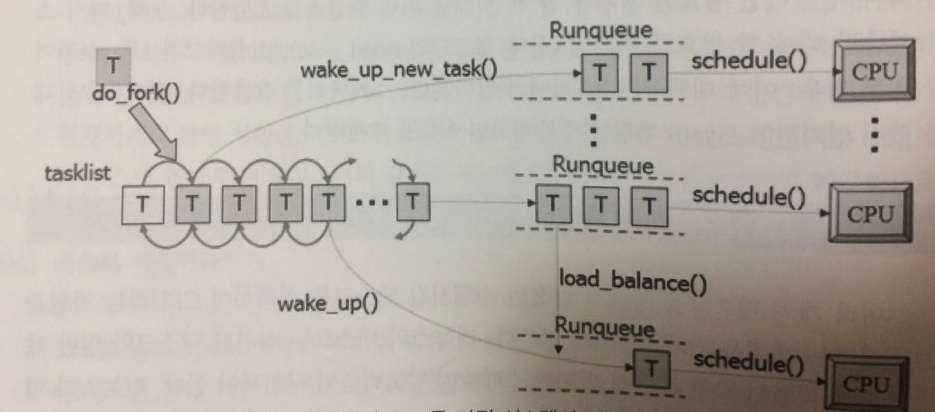
TASK_RUNNING상태의 태스크는 시스템에 존재하는 런큐 중 하나에 소속된다.- 새로 생성되는 태스크는 부모 태스크가 존재하던 런큐로 삽입된다. (캐쉬 친화력(
cache affinity) 때문에) - 대기 상태에서 깨어난 태스크는 대기 전에 수행되던
CPU의 런큐로 삽입된다. (역시 캐쉬 친화력) - 스케쥴러가 수행되면 두 가지 사항을 고려하여 런큐에서 다음에 수행시킬 태스크를 선택한다:
- 어떤 태스크를 선택할 것인가? 일반 태스크는
CFS(Completely Fair Scheduler)를 사용하고, 실시간 태스크는FIFO,RR,DEADLINE정책을 제공한다. - 부하가 균등하지 않은 경우엔 어떻게 할 것인가? 부하 균등(
load balancing) 기법을 사용하여 바쁜CPU의 작업을 한가한CPU로 이주(migration) 시킨다.CPU이주에는 동일한 캐쉬 라인을 공유하는CPU를 우선적으로 선택한다. 하이퍼 쓰레딩 중이라면 같은CPU의 같은 캐시라인을 공유하는 옆CPU로 이주할 가능성이 높다.
- 어떤 태스크를 선택할 것인가? 일반 태스크는
+ 추가: 하이퍼 쓰레딩(Hyper threading) 이란?
인텔에서 개발한 기술로 한 개의 물리적 장치에 두 개의 가상 실행 장치를 할당하여 성능을 높이려는 기술이다. 코어 하나 당 두 개의 쓰레드가 추가되어 싱글 코어는 듀얼 코어, 듀얼 코어는 쿼드 코어 식으로 늘어난다. 하이퍼 쓰레딩을 사용한다고 반드시 성능이 향상되진 않고 하이퍼 쓰레딩을 고려하고 설계한 프로그램의 경우 성능의 향상을 보인다고 한다. 하이퍼 쓰레딩과 맞지 않는 설계의 프로그램은 오히려 성능이 저하될 수도 있다.
실시간 태스크 스케쥴링(FIFO, RR, DEADLINE 정책)
리눅스는 CPU 를 효율적으로, 그리고 공평하게 사용하기 위해 다양한 스케쥴링 기법을 사용한다. 이를 위해task_struct 에는 policy prio, rt_priority 등의 필드가 존재한다. 리눅스는 실시간 태스크를 위해 3개, 일반 태스크를 위해 3개의 총 6 개의 스케쥴링 정책을 제공한다:
-
실시간 태스크:
SCHED_FIFO,SCHED_RR,SCHED_DEADLINE -
일반 태스크:
SCHED_NORMAL,SCHEDL_IDLE,SCHED_BATCH실시간 태스크는 0 ~ 99 사이의 우선순위를 가질 수 있으며 태스크가 수행을 종료하거나, 스스로 중지하거나, 자인의 타임 슬라이스를 다 쓸 때(이는
SCHED_RR정책에만 해당) 까지CPU를 사용한다. 또한, 실시간 정책을 사용하는 태슼크는 고정 우선순위를 가지기 때문에 우선순위가 높은 태스크가 항상 우선 순위가 낮은 태스크보다 먼저 수행됨을 보장한다.
RR을 사용하는 동일 우선순위를 가지는 태스크가 복수개인 경우, 타임 슬라이스를 기반으로 스케쥴링 된다. 동일 우선 순위의 태스크가 없다면FIFO와 동일하게 동작한다.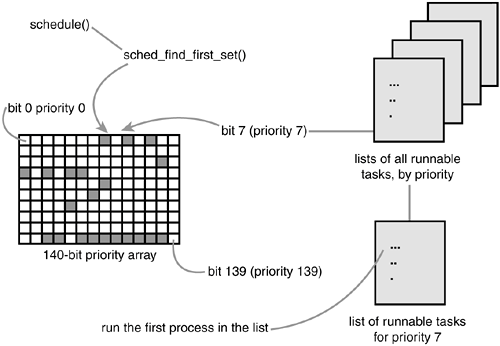
리눅스 커널은 우선 순위 탐색을 위해 모든 태스크를 전수조사하진 않고 우선 순위 레벨 비트맵을 생성하여 이를 탐색한다.
- 태스크가 생성되면 비트맵에 그 태스크의 우선순위에 해당하는 비트를 켠다.
- 스케쥴링 시 순차적으로 켜져 있는 비트를 찾아낸다.
- 비트를 찾았다면 그 우선순위 큐에 매달려 있는 태스크를 선택하여 스케쥴한다.
DEADLINE 정책은 가장 급한 태스크를 스케쥴링 대상을 선정한다. 영상 재생과 같이 초당 정해진 횟수의 작업(예를 들어 초당 30 프레임이라면 최소 1초에 30번은 화면을 새로고침해야 한다) 을 수행해야 하는 일을 가지고 있다면, 이는 DEADLINE 정책을 통해 구현되어 질 수 있다.
리눅스의 DEADLINE 정책에서 완료시간 을 deadline, 작업량 을 runtime, 주기성 을 period 라 부른다.
DEADLINE 정책을 사용하는 각 태스크들은 RBTree (Red-black Tree) 를 통해 관리되며 가장 가까운 deadline 을 가지는 태스크를 스케쥴링 대상을 선정한다.
출처
[이미지] https://hwchen18546.wordpress.com/2014/04/10/linux-trace-task_struct/
[이미지] http://jake.dothome.co.kr/wp-content/uploads/2017/04/task-state-1.png
[이미지] http://derekmolloy.ie/writing-a-linux-kernel-module-part-1-introduction/
[사이트] https://medium.com/pocs/리눅스-커널-운영체제-강의노트-1-d36d6c961566
[사이트] https://wenboshen.org/posts/2015-12-18-kernel-stack.html
[이미지] http://ps-2.kev009.com/wisclibrary/aix52/usr/share/man/info/en_US/a_doc_lib/aixbman/prftungd/2365c21.htm
[책] 리눅스 커널 내부구조 (백승제, 최종무 저)
[사이트] https://ko.wikipedia.org/wiki/하이퍼스레딩
[이미지] http://books.gigatux.nl/mirror/kerneldevelopment/0672327201/ch04lev1sec2.html
[이미지] http://jake.dothome.co.kr/scheduler-core/
{kind=link}
