4. 가상 메모리 (Virtual memory)
가상 메모리(Virtual memory) 는 물리 메모리(Physical memory) 의 한계를 극복하기 위해 나온 기법이다.
가상 메모리는 실제 시스템에 존재하는 물리 메모리의 크기와 관계없이 가상적인 주소 공관을 사용자 태스크에게 제공한다.
-
32 bit의 경우: 일반적으로4 GiB() -
64 bit의 경우: 일반적으로16 EiB()실제 물리 메모리를
4 GiB모두 생성하는 것이 아닌 사용가자 사용하는 만큼만 동적으로 할당하여 가능한 많은 태스크가 물리 메모리를 사용할 수 있게 만들어준다.
5. 아키텍쳐, 물리 메모리의 구조
노드(Node) 를 설명하기 앞서 존(Zone) 을 설명하기 앞서 물리 메모리와 아키텍쳐의 구조에 대해 살펴본다.
SMP 시스템
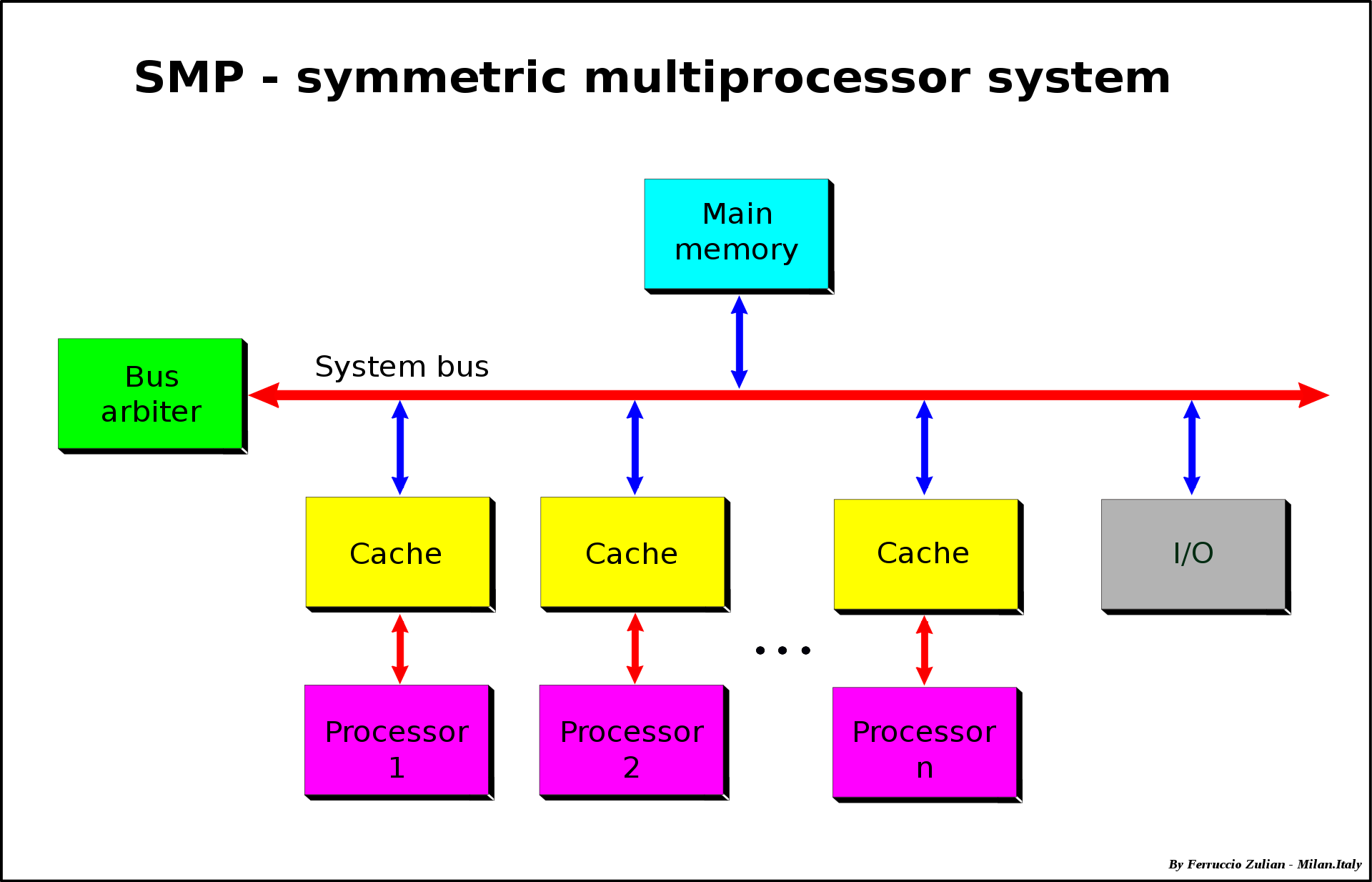
두 개 혹은 그 이상의 동일한 프로세서가 하나로 연결되며, 단일 공유 주 메모리(main memory, RAM) 를 사용하며, 모든 입/출력 장치에 대한 모든 접근(full access) 를 가지며, 모든 프로세서를 동일하게 다루는 단일 운영체제를 통해 제어되는 멀티 프로세서 컴퓨터 하드웨어와 소프트웨어 아키텍쳐를 의미한다.
일반적인 데스크탑 컴퓨터가 SMP 시스템를 가진다.
AMP 시스템
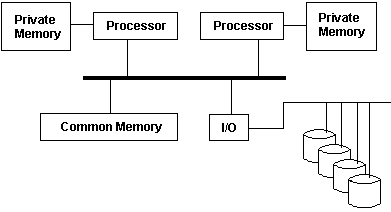
AMP (Asymmetric Multiprocessing) 시스템은 서로 연결되어 있지 않은 모든 중앙 처리 장치들(CPUs, 보통 이기종 CPU)이 동일하게 취급되는 멀티 프로세서 컴퓨터 시스템이다. 예를 들자면 시스템은 오직 하나의 CPU 만이 운영체제 코드를 실행시키는 것을 허용하거나 혹은 오직 하나의 CPU 만이 I/O 연산 수행을 허용하는 것을 의미한다.
일반적으로 임베디드 장치들이 이러한 AMP 시스템를 가진다.
HMP 시스템
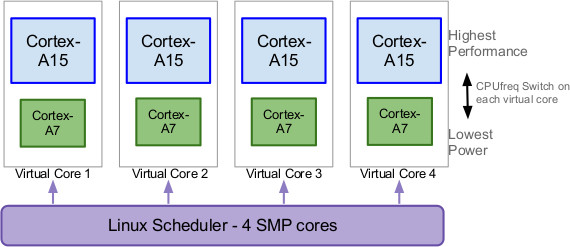
HMP (Heterogeneous Multi-Processing) 는 상대적으로 전력 소모가 적은 저성능 코어(LITTLE) 들과 전력 소모가 많은 고성능 프로세서 코어(big)들을 함께 탑재하는 시스템 말한다.
이러한 모델은 현재 Samsung Exynos 5 Octa 시리즈와 Apple A 시리즈에 구현되어 있다.
UMA 구조
UMA (Uniform memory access) 는 모든 프로세서들이 상호간에 연결되어 하나의 메모리를 공유하는 기술이다. UMA 모델의 모든 프로새서는 물리 메모리를 균일하게 공유한다. UMA 아키텍쳐에서 메모리 위치에 대한 접근 시간은 어떤 프로세서가 요청했는지와 어떤 메모리 칩이 데이터를 포함하고 있는지와 무관하다.
UMA 구조는 단순하지만 여러 프로세서가 동시에 메모리에 접근하면 대역폭이 감소하여 속도가 떨어지며, 거짓 공유 (false sharing) 문제로 인한 구조적 한계가 존재한다.
NUMA 구조
NUMA (Non-Uniform memory access) 는 메모리 접근 시간이 메모리와 연관된 프로세서에 의존적인, 멀티 프로세싱에서 사용되는 컴퓨터 메모리 디자인이다.
NUMA 구조 아래에서, 프로세서는 본인의 비-지역 메모리 (non-local memory, 프로세서들 사이에서 공유하는 메모리 혹은 다른 프로세서의 지역 메모리) 보다 고유의 지역 메모리에 더 빠르게 접근할 수 있다.
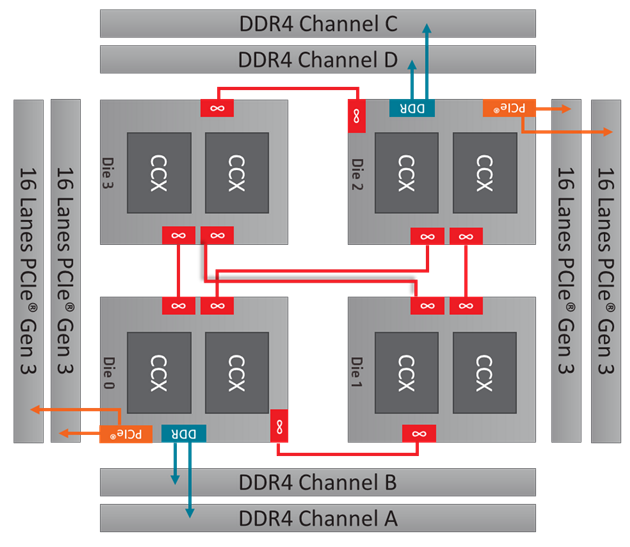
위 사진은 NUMA 구조를 가진 AMD Ryzen™ Threadripper WX Series Processors 프로세서이다. 우상단의 Die 2 프로세스의 DDR4 C, D 채널과 연결되어 있는데 이들 하나만 보자면 UMA 이다. Die 3 기준에서 보면 DDR4 Channel C, D 에 접근하기 위해 빨간색 브릿지를 건너가야 하기 때문에 Die 2 에 비해 접근 속도가 느리다. 따라서 Die 2 와 Die 3 를 묶어서 DDR4 Channel C, D 와 비교하면 이는 NUMA 구조라 생각할 수 있다.
이렇게 메모리에 직접적으로 연결되지 않은 (브릿지를 타고 넘어가야 하는) Die 1, 3 을 memoryless node 라 부른다.
6. 노드 (Node)
리눅스에선 접근 속도가 같은 메모리의 집합을 뱅크(bank) 라 부른다. UMA 구조라면 한 개의 뱅크가 존재하고, 반대로 NUMA 라면 여러 개의 뱅크를 가진다. (이해 안되면 다시 위 삽화 참고)
리눅스는 이러한 뱅크를 노드라는 자료로 관리(~/include/linux/mmzone.h)한다.

UMA 구조라서 단일 노드를 contig_page_data 변수가 가리키던, NUMA 구조라서 pgdat_list 라는 자료구조가 가리키고 있던지에 관계없이 하나의 노드는 pg_data_t 구조체를 통해 표현된다.
만일 리눅스가 물리 메모리의 할당 요청을 받게 되면 되도록 할당을 요청한 태스크가 수행되고 있는 CPU 와 가까운 노드에서 메모리를 할당하려 한다.
7. 존 (Zone)
ISA 버스 기반 디바이스의 경우 정상적인 동작을 위해서 물리 메모리 중 16 MiB 이하 부분을 할당해줘야 하는 경우가 있다. 따라서 이를 위해 node 의 일부분을 따로 관리할 수 있도록 자료구조로 만들어 놓았다.
다시 말해 zone 은 동일한 속성을 가지며, 이를 zone 의 메모리와는 별도로 관리되어야 하는 메모리 집합이다.
1 GiB 물리 메모리의 존 배치
-
16 MiB아래:ZONE_DMAorZONE_DMA32 -
16 ~ 896 MiB:ZONE_NORMAL -
896 MiB이상:ZONE_HIGHMEM반드시 세 개의
zone이 존재하는 것은 아니고 필요에 따라 하나의zone만 존재할 수도 있다.
zone 분리 관리
각 존을 분리하여 명칭을 붙인데에는 그만한 이유가 있다. 각각의 존이 어떠한 이유로 분리되어 있는지 알아본다.
ZONE_DMA
DMA (Direct Memory Access) 를 사용하는 디바이스 장치가 제한된 24 비트 주소만을 지원하므로 관련 메모리 할당을 ZONE_DMA 영역에서 할당받아 사용한다.
ZONE_NORMAL
NORMAL 과 DMA 는 커널이 관리한다. 32 bit 시스템에서 커널이 실제 사용 가능한 물리 주소는 800 MiB 정도 밖에 안된다.
ZONE_HIGHMEM
HIGHMEM 은 애플리케이션이 사용하는 메모리로 커널 조차 사용이 불가하다. 64 bit 운영체제는 (가상) 메모리가 넉넉하므로 ZONE_HIGHMEM 을 사용하지 않을 수도 있다.
ZONE_MOVABLE
- 단편화 방지
- 핫 플러그 메모리 지원
가상 머신이나 메모리 사용이 많은 서버 등에서 사용하는 zone
ZONE_DEVICE
persistent memory deviceheterogeneous memory device
등에서 사용하는 zone
현재 리눅스에서 사용하는 zone 에 대한 정보는
cat /proc/zoneinfo
명령어를 통해 확인 가능하다:
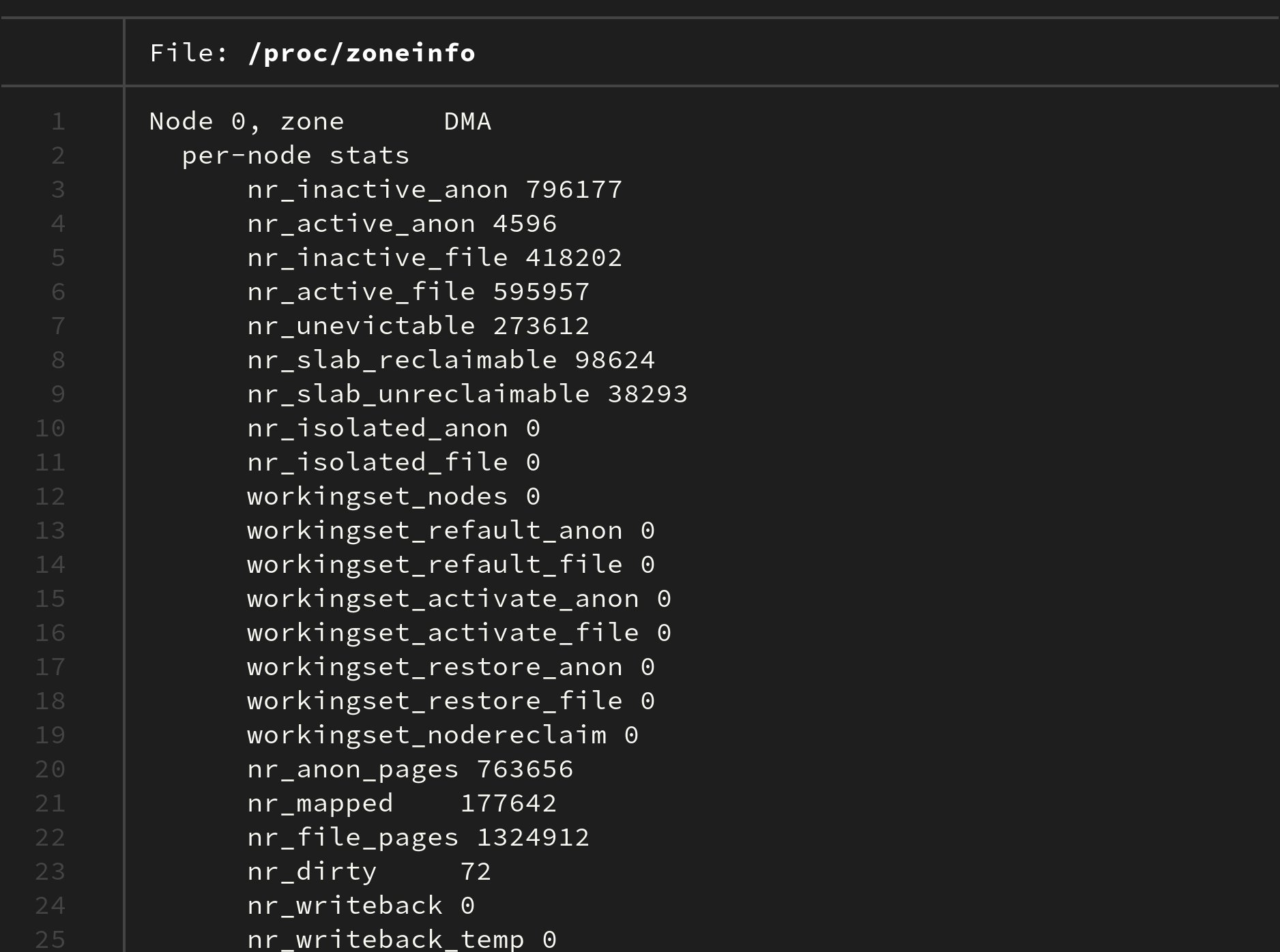
필자의 운영체제는 DMA, DMA32, Normal 로만 이뤄져 있다. (HIGHMEM 은 없다)
출처
[사이트] https://en.wikipedia.org/wiki/Symmetric_multiprocessing
[책] 리눅스 커널 내부구조 (백승제, 최종무 저)
[이미지] https://en.wikipedia.org/wiki/Symmetric_multiprocessing#/media/File:SMP_-_Symmetric_Multiprocessor_System.svg
[이미지] https://raptor-hw.net/xe/know/128489
[사이트] https://en.wikipedia.org/wiki/Asymmetric_multiprocessing
[이미지] https://community.amd.com/t5/blogs/previewing-dynamic-local-mode-for-the-amd-ryzen-threadripper-wx/ba-p/416216
[사이트] https://ko.wikipedia.org/wiki/Big.LITTLE
[사이트] https://en.wikipedia.org/wiki/ARM_big.LITTLE
[사이트] https://en.wikipedia.org/wiki/Uniform_memory_access
[사이트] https://en.wikipedia.org/wiki/Non-uniform_memory_access
{kind=link}
