
2021년 06월 12일 15:00 ~ 22:00 스터디 진행 내용을 정리한 글입니다.
0. 스터디 공지사항
참석자
45 명
서기 및 공유
진행: 문영일님
서기: 김현우님, 김성원님
공유: 이민욱님
영상: 최영민님
정보: 류효은님
진도
리눅스 커널 내부구조 (백승재, 최종무 저)
1. 일반 태스크 스케쥴링 (CFS)
CFS 는 Completely Fair Scheduler) 의 약자로 정해진 시간 단위로 최대한의 CPU 리스소를 사용하여 모든 태스크에게 전체적으로 공평한 시간동안 실행되는 것을 목표로 함.
-
시간 단위가 길면? 반응성이 떨어짐. -
시간 단위가 짧으면? 문맥 교환(overhead) 으로 인한 오버헤드 증가예) 프로세스
A,B가 실행 중이라면,1초 동안A에게0.5초,B에게도0.5초씩 공평하게 분배하여 실행하는 정책이다.여기에서
1초가 시간 단위이다. 시간 단위는 적절하게 설정되어야 반응성과 성능을 모두 챙길 수 있다.
우선순위 (Priority)
우선순위가 높은 태스크에게 가중치를 두어 좀 더 긴 시간 CPU 를 사용하게 한다. 각 태스크는 vruntime 값을 가지고 이 값을 통해 다음 스케쥴링될 태스크를 결정함.
사용자 수준 우선 순위: -20 ~ 0 ~ 19 까지
커널 수준 우선순위: priority + 120 => 100 ~ 139 < 항상 실시간 태스크보다 작음(0 ~ 99)
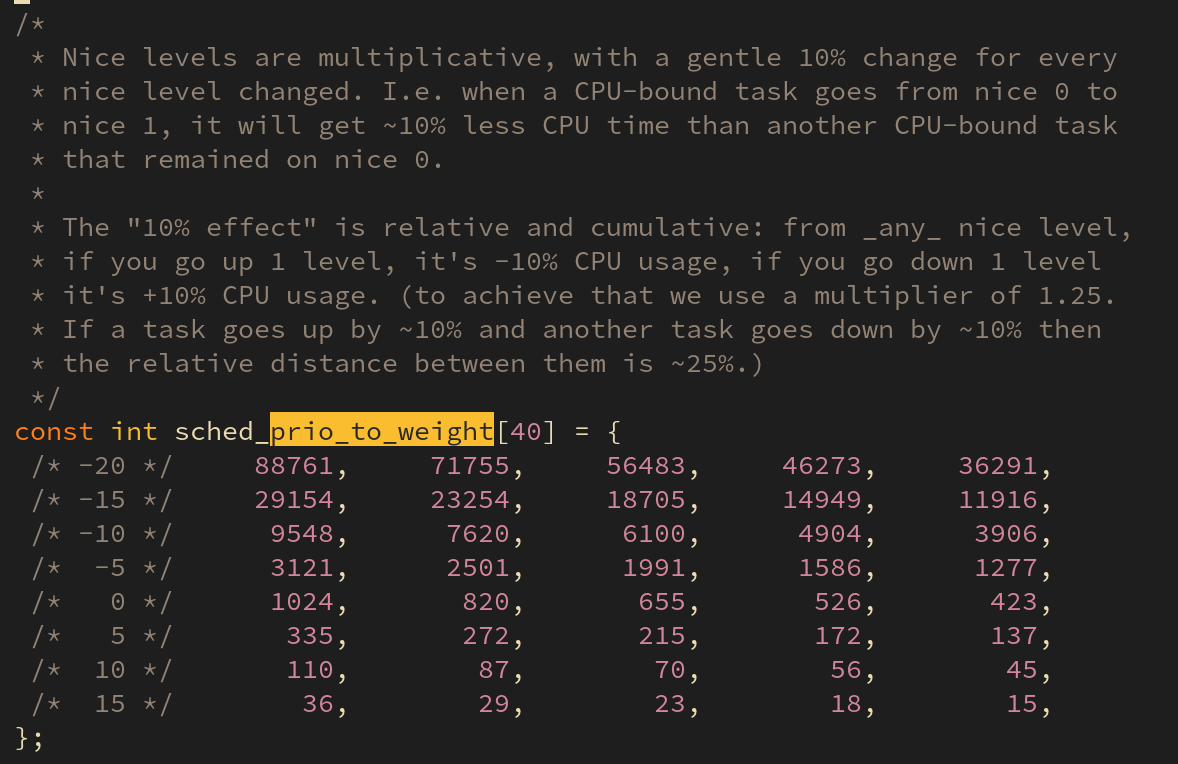
vruntime 은 priority 에 따라 서로 다른 가중치를 사용한다. (코드는 kernel/sched/core.c 에 저장되어 있다. 버전 5.10)
위 수식으로 vruntime 값이 계산된다. time 이 앞서 말한 시간 단위 이며, weight(0) 는 우선순위가 0 일 때의 가중치 값(위 그림 기준으로 보면 1024), weight(c) 는 현재 태스크의 가중치(만일 -15 라면 29154) 이다.
위 계산식을 통해 우선순위가 높은 태스크는 시간이 느리게 흐르고, 우선순위가 낮은 태스크는 시간이 빠르게 흐른다는 사실을 알 수 있다.
스케쥴링 (scheduling)
vruntime 이 가장 작은 태스크가 스케쥴링의 대상으로 선정되며 이는 RBTree 자료구조를 통해 관리되어 진다.
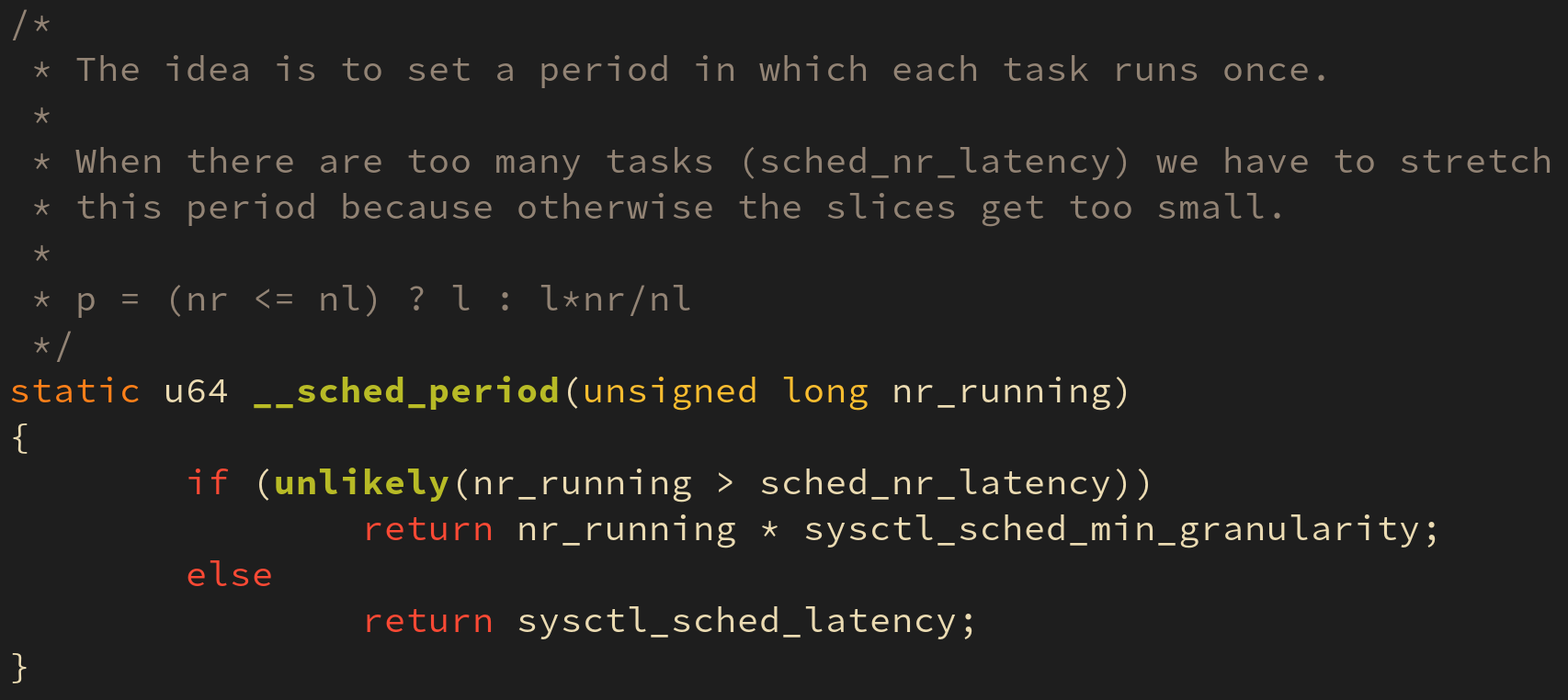
시간 단위는 너무 잦은 오버헤드를 최소하하기 위해 시스메에 존재하는 태스크의 개수를 고려하여 정해지며, 이는 커널의 __sched_period() 함수에서 계산된다.
새로이 생성된 태스크는 vruntime 값이 가장 작은 값을 자신의 vruntime 값으로 설정.
스케쥴링 주기 (scheduling period)
스케쥴러는 언제(when) 그리고 어떻게(how) 호출지에 되는지로 나눠서 대답할 수 있다.
어떻게(how) ?
- 직접
schedule()함수를 호출 - 수행되고 있는 태스크의
thread_info구조체 내부의flags필드 중need_resched라는 필드를 설정했을 때
언제(when) ?
- 주기적으로 발생하는 타이머 인터럽트의 서비스 루틴이 종료되는 시점에 현재 태스크의
need_resched필드를 살펴보고 필요 시 호출 - 현재 수행 중인 태스크가 모든 타임 슬라이스를 소비
- 현재 수행 중인 태스크가 이벤트를 대기
- 태스크가 새로 생성
- 대기 상태의 태스크가 깨어남
- 현재 태스크가
sched_setscheduler()같은 스케쥴링 관련 시스템 콜을 호출
그룹 스케쥴링(group scheduling)
CFS 는 그룹 스케쥴링(group scheduling) 기법을 사용하여 스케쥴링에 대한 새로운 기준점을 제공한다.
ID 기반 그룹 스케쥴링
ID 기반 그룹 스케쥴링은 특정 사용자 간에 공평하게 CPU 를 배분하는 정책이다. 기본적으로 리눅스는 다중 사용자를 위한 운영체제이기 때문에 여러 사용자가 존재할 수 있다.
cgroup 기반 그룹 스케쥴링
cgroup 기반 가상 파일 시스템 기반 그룹 스케쥴링 기법은 사용자가 지정한 태스크들을 하나의 그룹으로 취급하며 그룹 간에 공평하게 CPU 를 배분하는 정책이다.
인터페이스 (interface)
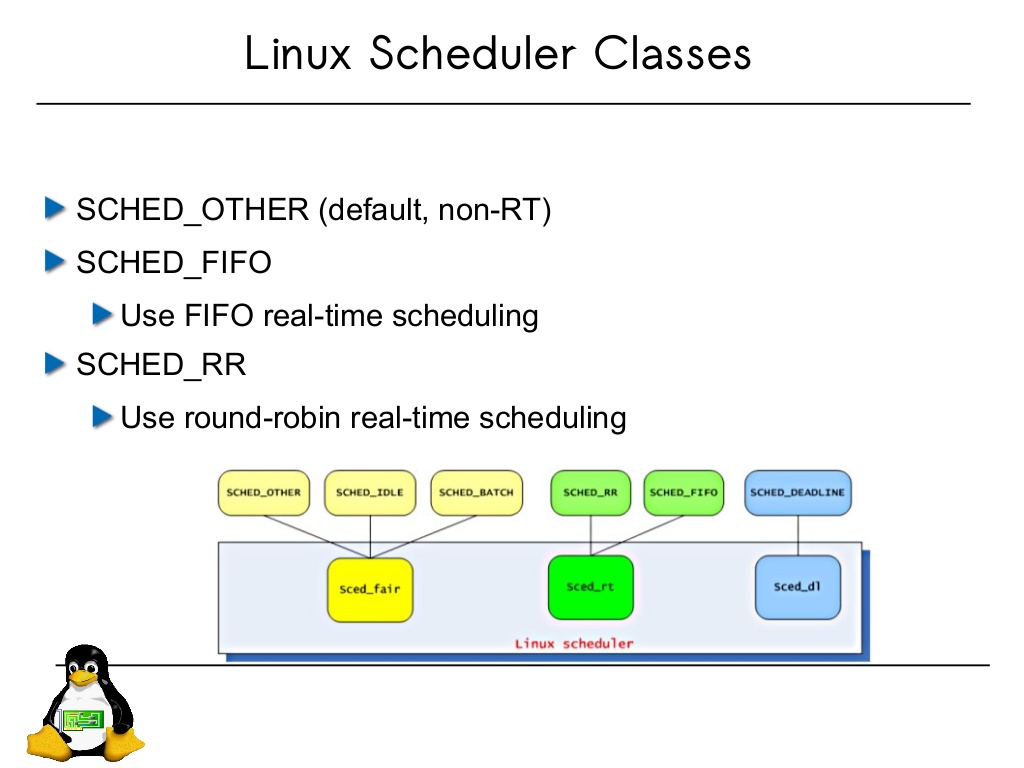
리눅스는 스케쥴링 클래스라는 개념을 도입하여 구현과 인터페이스 를 분리하였다. kernel/sched/fair.c 에는 CFS 를 kernel/sched/rt.c 에는 FIFO & RR), kernel/sched/deadline.c 에는 DEADLINE 에 대한 스케쥴링 클래스를 담았다. 이들 클래스는 각각의 스케쥴링 정책이 구현되어 있는 함수에 대한 포인터를 담고 있는 구조체이다. 따라서 임의의 시점에 스케쥴링 관련 함수를 호출해야 할 때에는 구체적인 함수의 이름이 아닌 이 구조체를 이용하여 일관된 인터페이스를 유지한다.
2. 문맥 교환 (Context Switching)
태스크 A 에서 태스크 B 로 전환하여 수행 중이던 태스크의 동작을 멈추고 다른 태스크로 전환하는 과정을 문맥 교환(Context Switching) 이라 한다.
리눅스 커널은 태스크가 문맥교환 시점에 어디까지 수행했는지, 현재 CPU 의 레지스터 값은 얼마인지 등을 저장해둔다. 이를 문맥 저장(Context Save) 이라 한다.
문맥 저장: thread_struct
thread_struct 구조체는 태스크가 실행하다가 중단되어야 할 때 태스크가 현재 어디까지 실행했는지 기억하는 공간이다. 아래의 삽화들은 ARM64 의 문맥 정보를 보여준다:
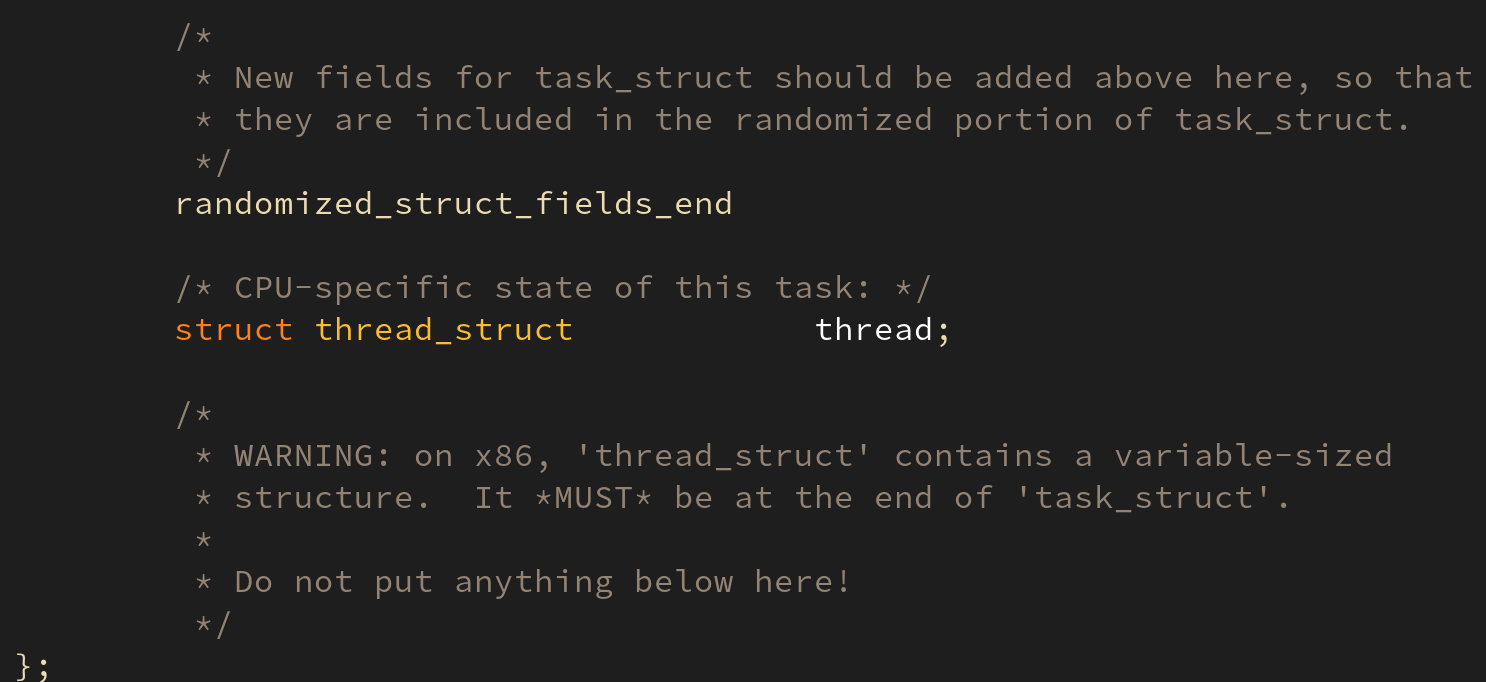
task_struct 구조체 내의 struct thread_struct thread; 가 선언되어 있다. thread 멤버 변수는 현재 태스크의 상태 정보를 저장한다.
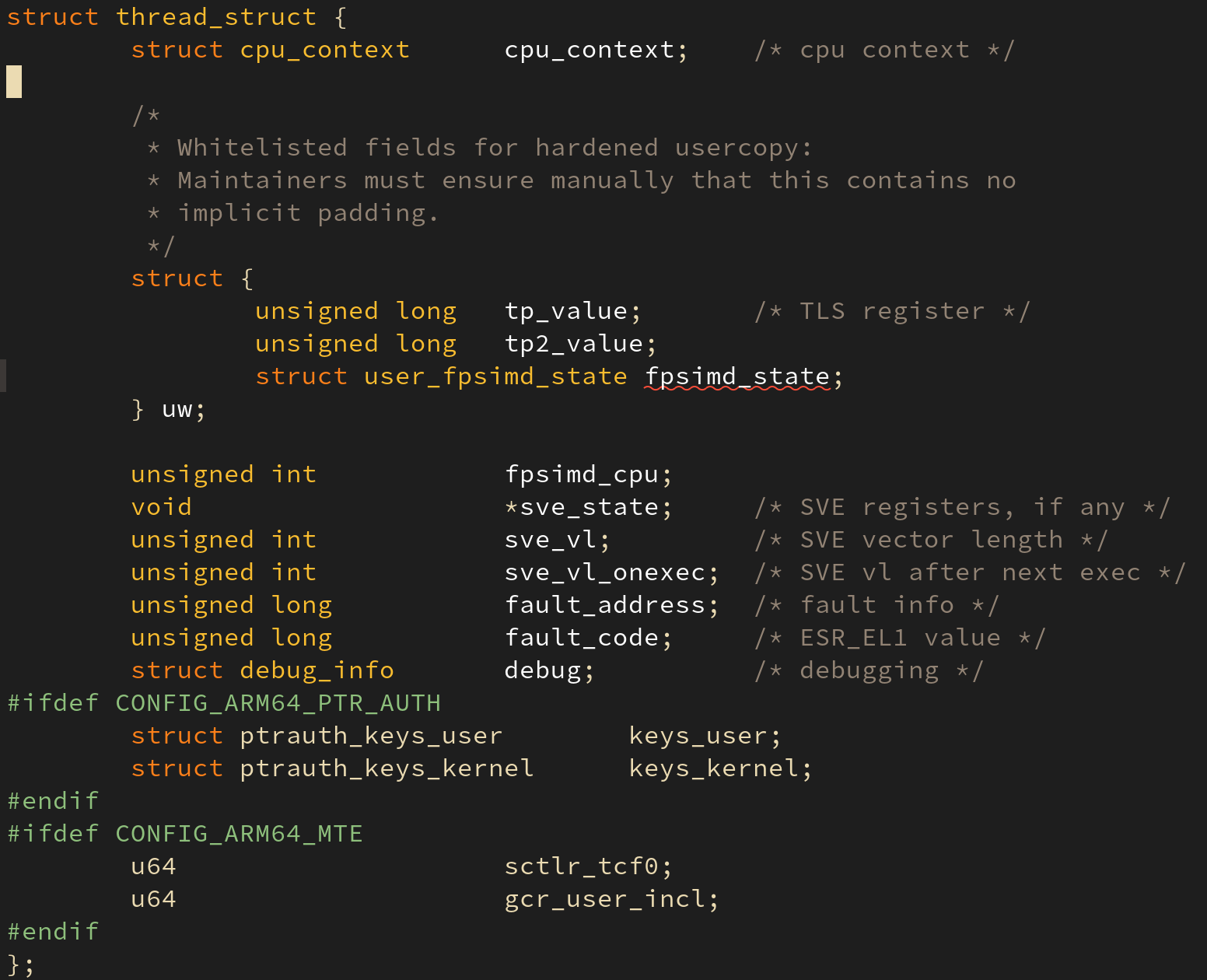
하드웨어 문맥 중 하나인 CPU 레지스터 역시 thread_struct 의 멤버인 cpu_context 에 저장된다.
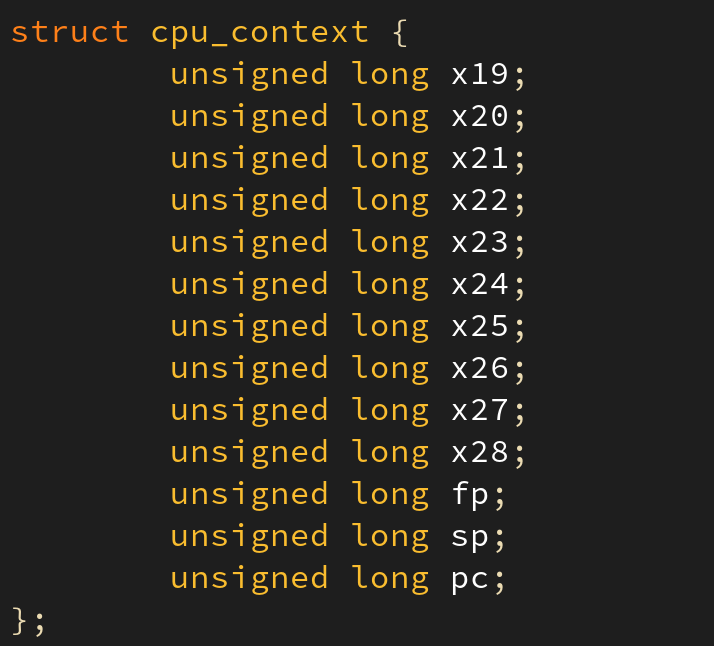
태스크 전이: Task A to B
태스크 A 수행 중 태스크 B 로 문맥 교환이 일어난다면 몇 번의 CPU 레지스터 정보 저장/복원이 필요할까? 앞서 말했듯이 커널 수준과 사용자 수준에서 사용하는 가상 메모리 공간은 서로 다르다. 커널은 독자적인 커널 스택을 사용하고 사용자는 사용자 수준의 커널 스택을 사용하므로 커널 수준에서 유저 수준으로 전이하기 위해서는 유저 수준의 스택 정보들을 저장하고 또 복원해야 한다.
따라서 두 태스크 간의 문맥 교환은, 실행 수준 변화(커널 > 유저 수준, 혹은 그 반대)에 따른 CPU 레지스터 정보 저장/복원 및 태스크 간의 문맥 교환에 따른 CPU 레지스터 정보 저장/복원이 필요하므로 총 4번의 CPU 레지스터 정보 저장/복원이 발생하게 된다.
3. 태스크와 시그널
시그널 (Signal) : 태스크에게 비동기적인 사건의 발생을 알리는 매커니즘
다음의 세 가지 조건이 만족되어야만 태스크가 시그널을 지원할 수 있다.
- 다른 태스크에게 시그널을 보낼 수 있어야 한다:
sys_kill(). - 시그널을 수신할 수 있어야 한다:
task_struct내의signal과pending. - 시그널을 처리할 수 있는 함수를 지정할 수 있어야 한다:
sys_signal().
리눅스는 시그널을 두 가지로 구분하는데 리눅스에서 기본적으로 지원하는 일반 시그널 32개와 POSIX 표준을 위해 도입한 실시간 시그널 32개로, 총 64 개의 시그널을 지원한다.
시그널 생성: sys_kill() 함수
$ kill PID
와 같은 명령은 프로세스를 종료시키는 시그널이므로 PID (커널에선 TGID) 를 공유하는 태스크에 모두에게 시그널을 전파해야 한다. 이렇게 여러 태스크들 간에 공유해야 하는 시그널은task_struct 구조체의 signal 필드에 저장한다.
반대로 특정 태스크에게 전달해야 하는 시그널은 pending 멤버에 저장한다. 이를 위해 sys_tkill() 과 같은 시스템 호출이 도입되었다.
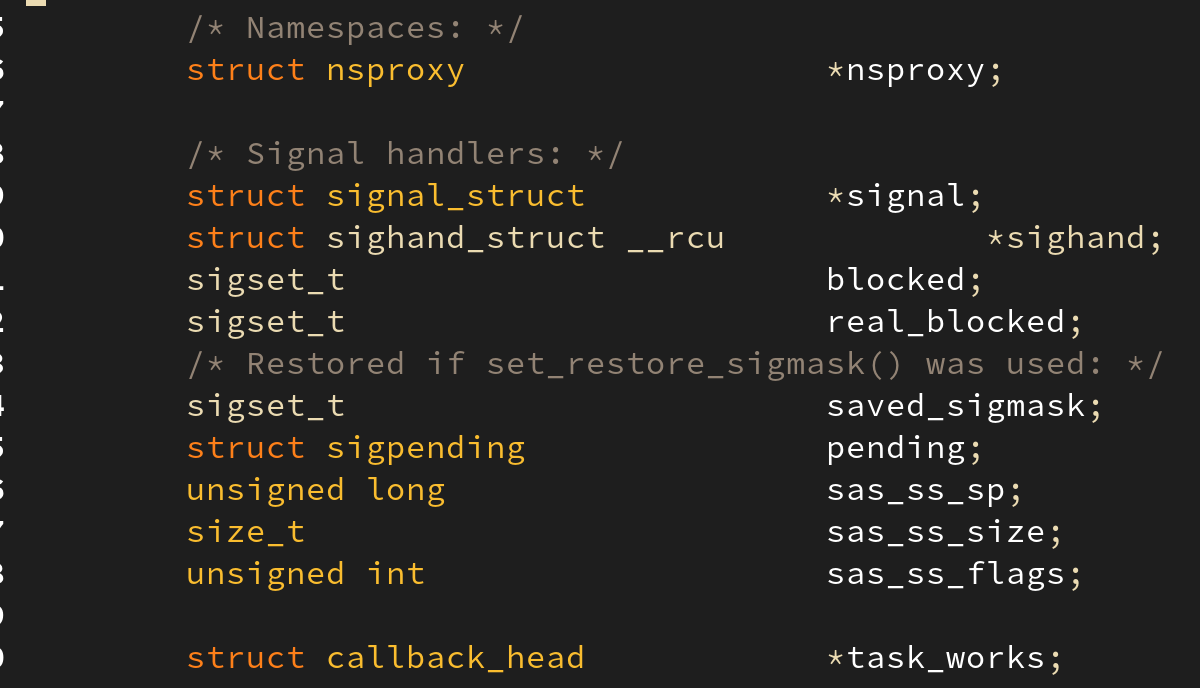
위 사진은 task_struct 내의 시그널을 처리하는 멤버 변수 signal 과 pending 을 보여준다. 이들은 시그널을 큐(Queue) 에 매달아 두는 구조를 채택했다.
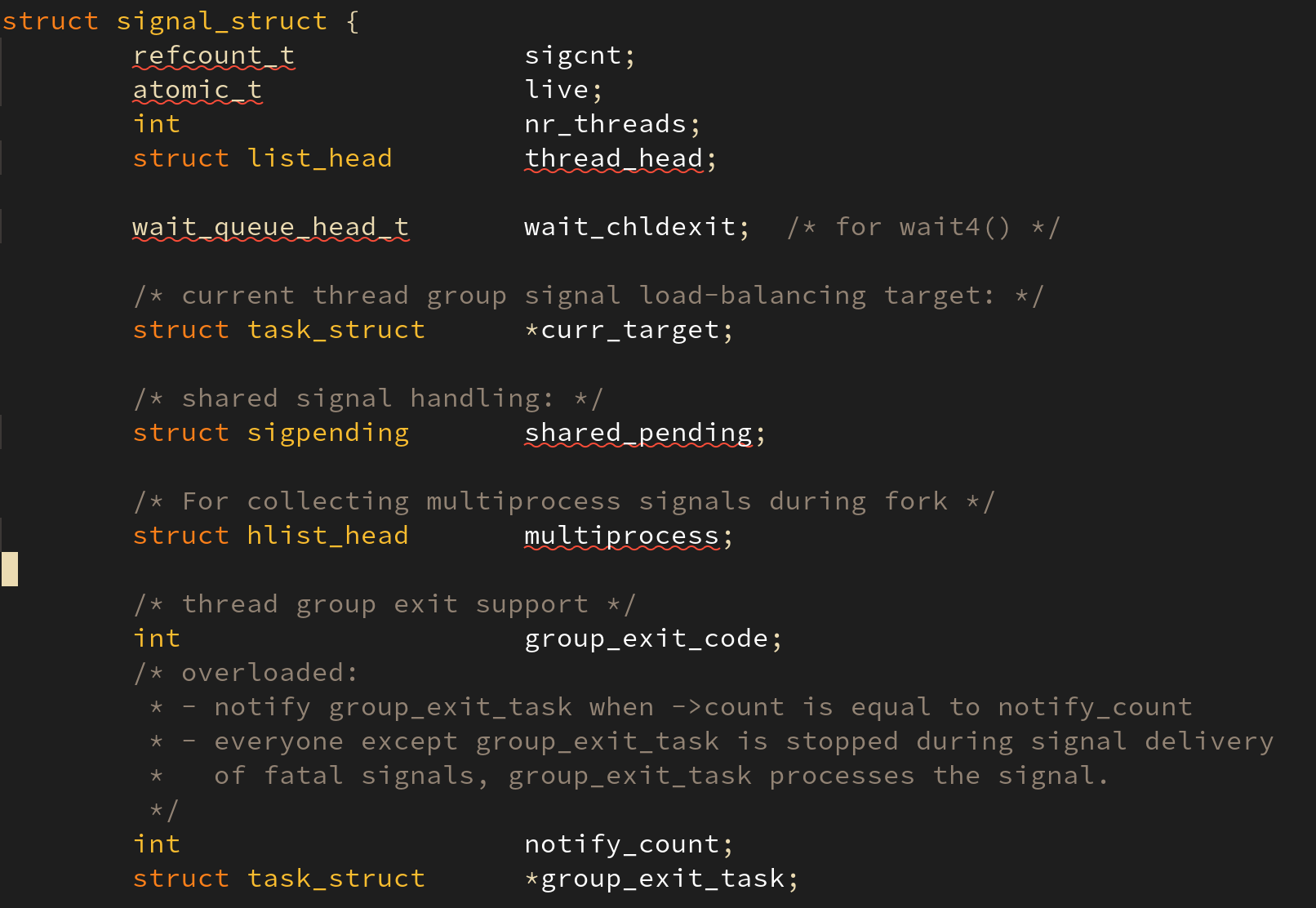
signal_struct 구조체는 shared_pending 이라는 struct sigpending 구조체를 포함하는데 이는 signal 이 같은 TGID 를 가지는 태스크들에게 전달되는 시그널이기 때문에 이러한 멤버를 가지는 것이다.
시그널 핸들러: sys_signal() 함수
각 태스크는 특정 시그널이 발생했을 때 수행될 함수(이를 시그널 핸들러(signal handler) 라 부른다)를 등록할 수 있다. 이를 지정하는 함수가 sys_signal() 함수이다. 태스크가 지정한 시그널 핸들러는 task_struct 구조체 내의 sighand 필드에 저장된다:
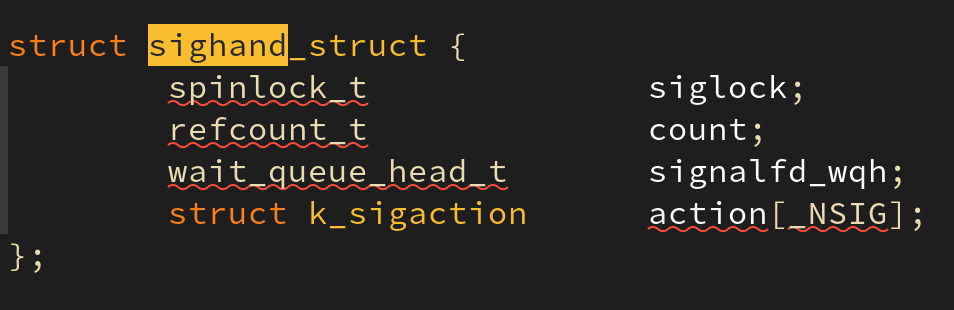
또한 태스크는 특정 시그널을 받지 않도록 설정할 수 있는데 이는 task_struct 내의 blocked 필드를 통해 이뤄진다. 다만 모든 시그널을 무시할 수 있는 것은 아니고 일부 치명적 시그널(fatal signal) 등(SIGKILL, SIGSTOP, 등)은 핸들러로 등록하거나 무시할 수 없다.
시그널 전달과 처리
태스크가 A 가 태스크 B 에게 시그널을 전달할 때 어떠한 일이 벌어질까?
시그널의 전달
시그널의 전달은 아래의 순서로 이뤄진다.
- 전달하려는 태스크의
task_struct를 탐색한다. siginfo자료구조를 초기화한다.blocked필드를 검사한다.signal혹은pending필드에 시그널을 매달아 둔다. (큐 자료구조)
시그널의 처리
시그널의 처리는 태스크가 커널 수준에서 사용자 수준으로 전이할 때 확인하여 처리한다. 시그널의 처리는 아래의 순서로 이뤄진다:
pending과signal멤버를 확인하여count가 0 이 아닌지 확인한다.- 처리를 대기하고 있는 시그널이 있다면 어떤 시그널인지 검사한다.
- 블록되어 있지 않다면 시그널 번호에 해당하는 시그널 핸들러를 찾아서 수행시킨다.
- 시그널 핸들러가 등록되어 있지 않다면 디폴트 액션(시그널 무시, 태스크 종료, 태스크 중지 등)을 수행한다.
인터럽트와 트랩은 커널에게 사건의 발생을 알리는 기법이었다면, 이번 장에서 설명한 시그널은 태스크에게 사건의 발생을 알리는 기법이다.
출처
[책] 리눅스 커널 내부구조 (백승제, 최종무 저)
[사이트] https://en.wikipedia.org/wiki/Completely_Fair_Scheduler
[사이트] https://elixir.bootlin.com/
[이미지] https://www.slideshare.net/jserv/realtime-linux
