선수지식
- NLP : Natural Language Processing 또는 자연어 처리. 우리가 일상적으로 쓰는 언어를 여기서는 자연어라고 표현한다. NLP는 딥러닝뿐만 아니라 컴퓨터로 언어를 처리하는 모든 과정을 일컬는다.
- MLP : Multi-Layer Perceptron 또는 다층 퍼셉트론. 심층 신경망(Deep Neural Network, DNN)의 가장 기본적인 모델로, 하나 이상의 은닉층이 있는 신경망을 의미한다. 본 문서에서는 RNN 등 다른 모델과 구분되는 바닐라 모델로 생각하면 쉽다. 딥러닝에 대한 자세한 내용은 위키독스 참조.
- GPT : Generative Pre-trained Transformer. 직역하면 사전학습된 생성형 트랜스포머지만 상표권도 있는 표현이라 학술용어로 보기는 어려울 듯 하다. 심지어 GPT-1, GPT-2, GPT-3.. 등등 구조가 모두 다르기 때문에 하나로 퉁치기도 어렵다. 그냥 ChatGPT, GPT-4같은 챗봇 서비스로 이해해도 좋을 것 같다.
딥러닝기반 NLP의 역사 (1990년대~)
RNN : Recurrent Neural Network
순환신경망이라고도 불리는 RNN은 NLP에서 가장 기본적인 모델로 알려져있다.
스팸 메일을 분류하는 문제가 있다고 생각해보자. 입력으로 들어갈 문장은 하나의 Sequence인데 기본적인 MLP는 문장의 순서를 고려하지 않기 때문에 성능이 떨어진다. 좋은 비유일지는 모르겠으나, 메일의 모든 단어를 섞는다면 내용을 이해하기 굉장히 어려워질 것이다.
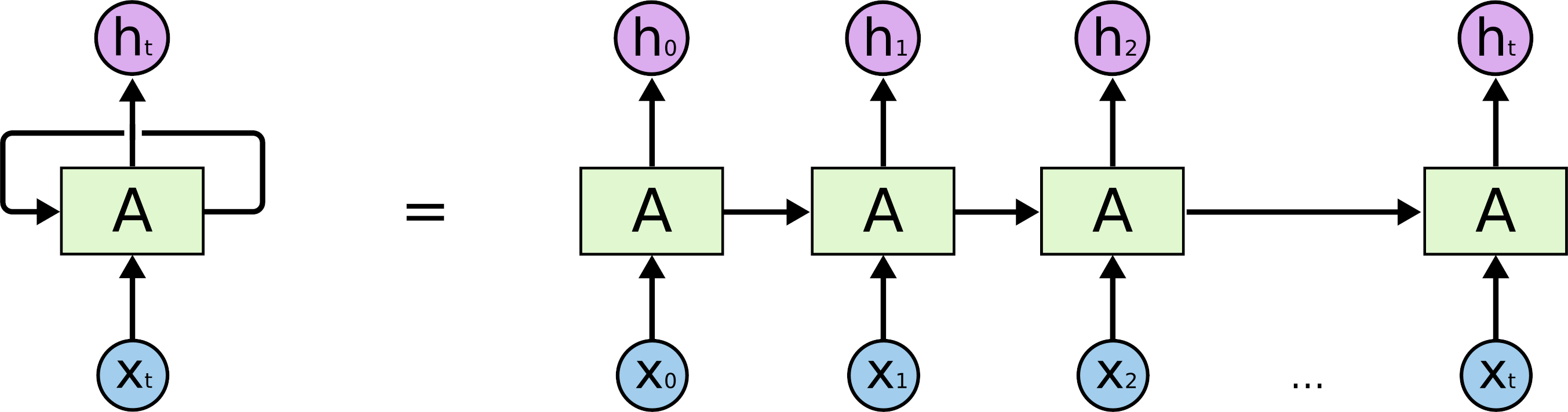
출처 : Understanding LSTM Networks
그림과 같이 이전 셀의 출력을 현재 셀의 입력으로 받는 구조가 반복되는 모습이다.
Vanishing gradient 문제
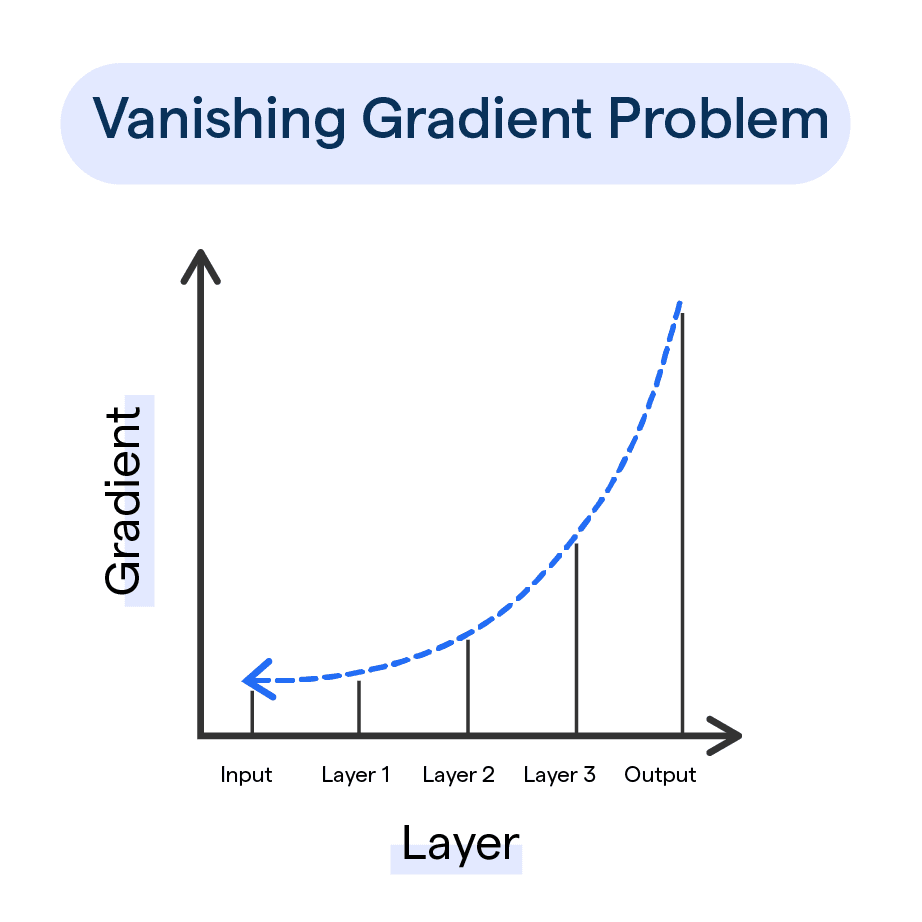
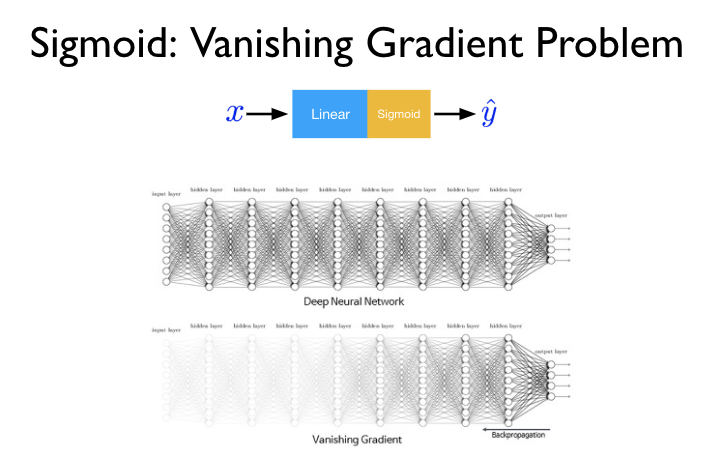
출처 : Vanishing Gradient Problem, Kaggle
RNN에서는 Long-term dependency 문제라고도 하는데, RNN의 고질적인 문제로 꼽힌다. 딥러닝 모델은 너무 깊어지면 역전파(Backpropagation)가 입력층까지 잘 닿지 않는 문제가 발생한다(블로그). 체인처럼 연결되는 RNN은 이런 문제에 취약하기 때문에 자연스럽게 입력 Sequence가 길어지면 성능이 떨어진다.
이를 해결해기 위해 RNN의 변형인 LSTM, GRU이 나왔고 기본 RNN 모델보다는 이쪽이 많이 쓰이는 듯 하다.
Transformer
LLM의 시작인 Transformer는 2017년에 발표되었다. 논문 제목(Attention Is All You Need, 당신에게 필요한건 Attention뿐)에도 나와있는 Attention 메커니즘 자체는 2014년에 나왔다고 한다. 여기에 Self Attention, Multi-head Attention 개념이 추가되었다(16-01 트랜스포머(Transformer)).
개인적으로 Transformer가 LLM의 시작이라고 생각하는 이유는 다음과 같다
- Long-term dependency 문제 해결 → 입력을 늘릴 수 있음 → 정확도 측면에서 모델을 키울 수 있음
- RNN과 달리 병렬 처리 가능 → 학습/추론 비용 측면에서 모델을 키울 수 있음
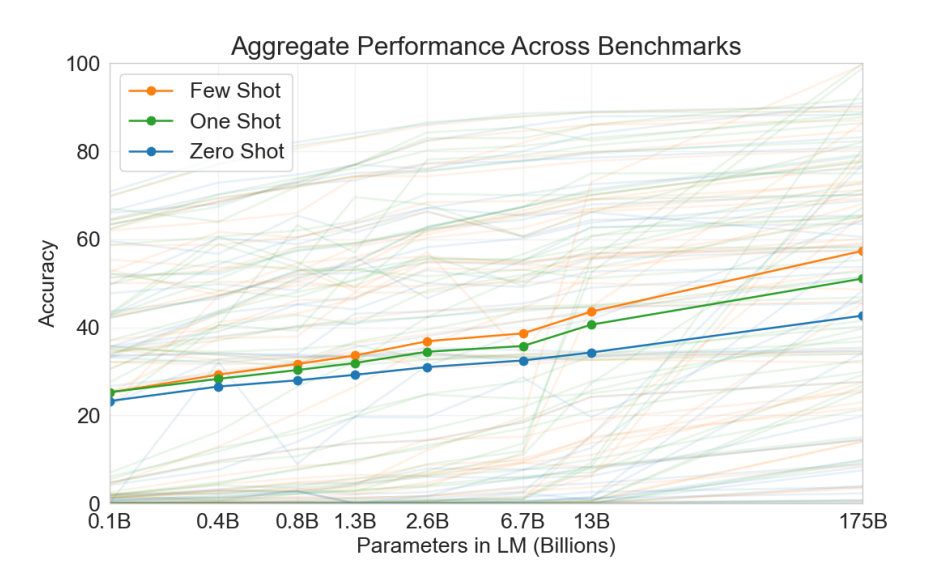 GPT3의 예시로, LLM은 일반적으로 모델의 크기가 커지면 정확도도 증가한다
GPT3의 예시로, LLM은 일반적으로 모델의 크기가 커지면 정확도도 증가한다
출처 : Language Models are Few-Shot Learners
LoRA : Low-Rank Adaptation
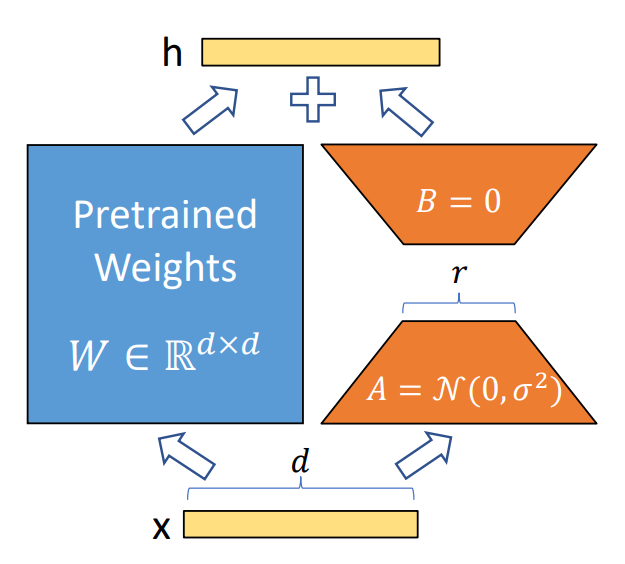
출처 : LoRA: Low-Rank Adaptation of Large Language Models
LoRA는 파인튜닝기법 중 하나이다. 정확히는 PEFT(Parameter-Efficient Fine-Tuning)이라고 하는데, 파라미터의 일부만 파인튜닝을 수행하는 기법이다. LLM의 등장 이후 모델의 크기가 너무 커져서 전체 파라미터를 조정하기 어려워졌고, 이런 방법들이 많이 발전하였다. 자세한 내용은 블로그와 깃허브를 참조
LoRA는 파인튜닝기법인데 굳이 NLP의 역사로 취급하는 이유는 LLM과 궁합이 잘 맞기 때문인데, 논문 제목부터 LLM에 쓰인다고 적혀있다. LLM에 파인튜닝이 필요한 이유와 LoRA의 의의를 나열해보면 다음과 같다.
파인튜닝이 필요한 이유
LLM은 무적인데 왜 파인튜닝이 필요할까? 유명한 LLM 중 하나인 Meta의 Llama2(7B)를 써보면 ChatGPT(175B)에 비해 성능이 매우 처참한데, 특히 한국어로는 일반적인 대화도 어렵다.

얘는 그냥 한글을 모름
성능이 안좋은 이유는 모델이 작아서 이기도 하지만, 애초의 한국어 학습량이 전체의 0.06%로 많이 부족하다.
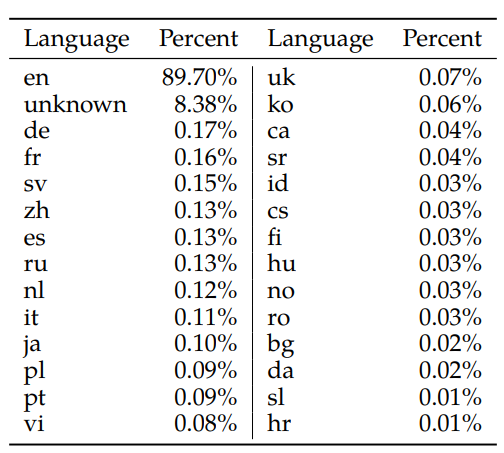 학습된 데이터의 90%가 영어로 구성되어있다.
학습된 데이터의 90%가 영어로 구성되어있다.
출처 : Llama 2: Open Foundation and Fine-Tuned Chat Models
모델의 크기가 충분하다면(ChatGPT 등) 프롬프트 엔지니어링으로 충분한 성능을 낼 수 있지만 개발자 입장에서는 매우 비싼 비용이 뒤따르기 때문에, 파인튜닝을 통해 본인이 원하는 분야에 특화하는 방법이 고려될 수 있다. 실제로 Alpaca라는 모델을 LoRA를 이용해서 각 나라별 언어로 파인튜닝해서 공유하는 깃허브repo가 있다.
장점1. 높은 정확도
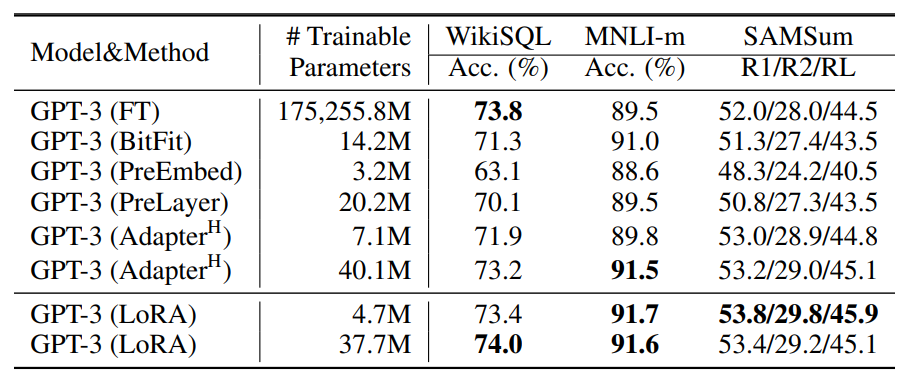
출처 : LoRA: Low-Rank Adaptation of Large Language Models
모든 파라미터를 파인튜닝하는 것과 비슷한(더 높은..?) 정확도를 보여준다. 물론 기본 모델 학습에 쓰인 데이터와 완전히 다른 방향으로는 정확도가 떨어지므로, 이런 경우는 전체 파라미터를 학습해야한다고 한다.
장점2. 어댑터처럼 교체할 수 있다.
- 예를 들어 '요약', '감정 분석', '번역'같은 대표적인 NLP Task를 위한 파인튜닝을 진행하고 각 어댑터를 얻었다고 생각해보자. 하나의 모델을 GPU에 로드해놓고 추론할 때에만 각 Task에 대한 어댑터를 적용시킬 수 있다.
- LLM이 메모리를 많이 먹긴 하지만, 모델 하나로 여러가지 일을 수행한다면 합의점을 찾을 수 있다는 뜻이다.
- 물론 서로 다른 어댑터를 동시에 쓸 수 없고 쓸 때마다 가중치를 적용해줘야한다(그래도 논문에는 다른 모델로 교체하는데에 많은 비용은 들지 않는다고 설명한다). 동시 추론이 가능한 PEFT 기법이 있는지는 리서치 필요..
장점3. 적은 리소스로 학습 가능하다
전체 파라미터의 0.01%만 학습해도 높은 정확도를 낼 수 있고, QLoRA를 쓰면 48GB 단일 GPU로 68B 모델을 파인튜닝할 수 있다고 한다.
장점4. 파인튜닝 결과물 또한 가볍다
적은 파라미터를 학습하는 만큼 가중치(weight) 용량도 적은데, 예를 들어 Alpaca-lora의 일본어 버전은 17MB밖에 하지 않는다. 물론 기본 모델은 있어야한다.
*여담으로 LoRA는 이미지 생성 모델인 Stable Diffusion에 응용하는 것으로 더 잘 알려져있다. 이쪽이 수?요가 더 많은 듯 하다.*
그래서 LLM이 뭐지?
Large Language Model. 말 그대로 큰 언어 모델들을 통틀어서 의미할 수도 있겠지만 일반적으로는 GPT같은 챗봇을 떠올릴 것 같다. 이 글에서는 언어 모델을 다 포함하는 것처럼 얘기하는데, 개인적으로는 본격적인 스케일링이 가능한(무식하게 크기를 키울 수 있는) 트랜스포머 기반 모델부터 LLM으로 취급하는 것이 좋은 것 같다. (BERT 등)
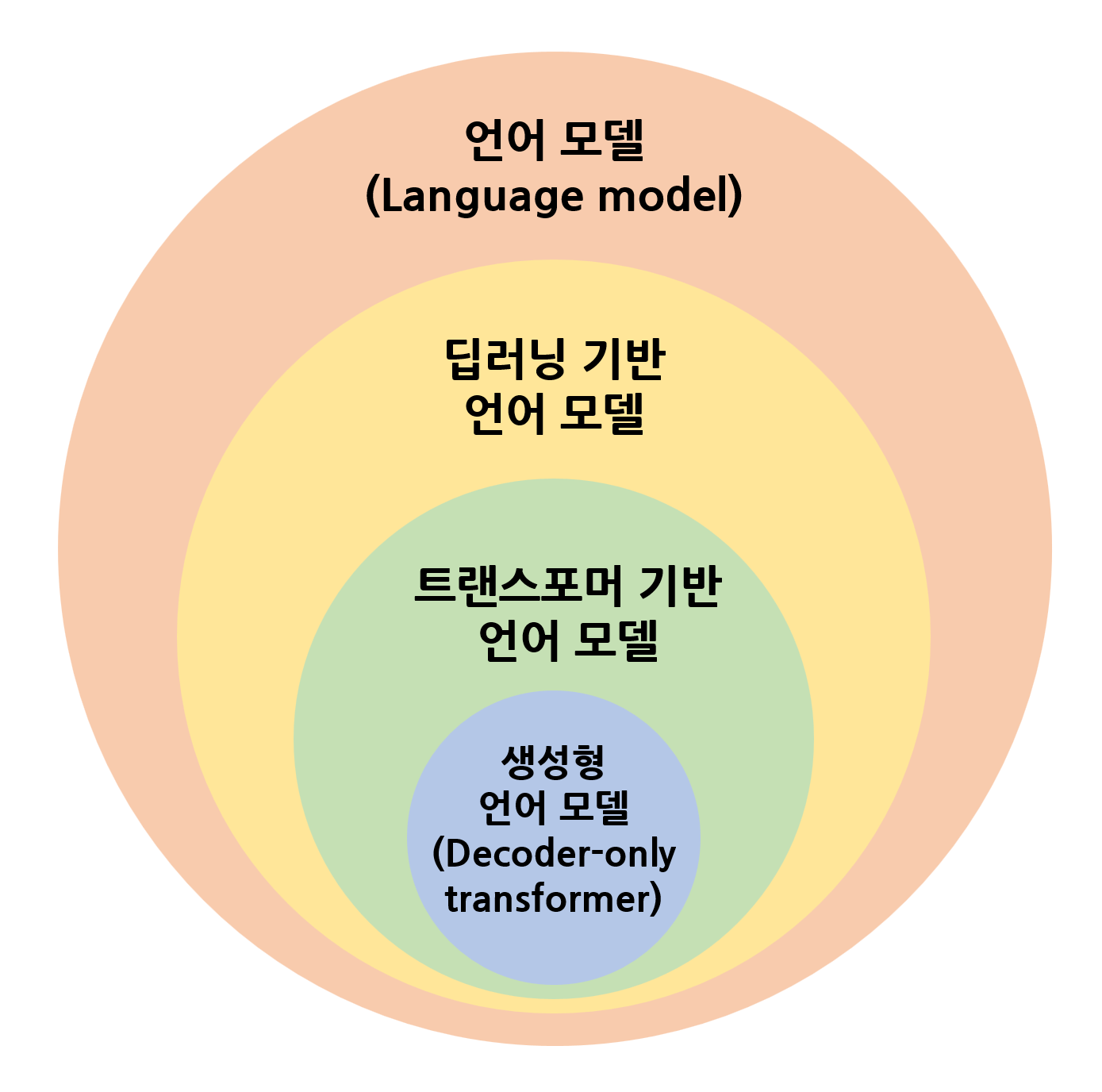 출처 : 뇌피셜
출처 : 뇌피셜
요약 : LLM은 넓게는 큰 언어 모델들을, 좁게는 GPT같은 챗봇을 의미한다.
참고
