라마?
 DALL·E로 그린 라마
DALL·E로 그린 라마
Meta(Facebook)에서 개발된 LLM인 Llama는 23년 3월에 유출되면서 세상에 알려졌다. (기사)
Llama2는 23년 9월에 정식으로 공개되었는데 라이센스를 읽어보면 상업적 사용까지 허용되었다. 물론 월 사용자 7억명 이상의 서비스는 별도의 계약이 필요한데, 대부분 해당사항이 없을 것이다. chat.lmsys.org에서 직접 써볼 수 있는데 70B-chat (파라미터 700억개) 모델은 바로 상용화 가능할 정도로 성능도 좋고 출력도 길다. 물론 한국어는 약한 편이므로 프롬프트는 영어로 작성하는 것을 권한다.
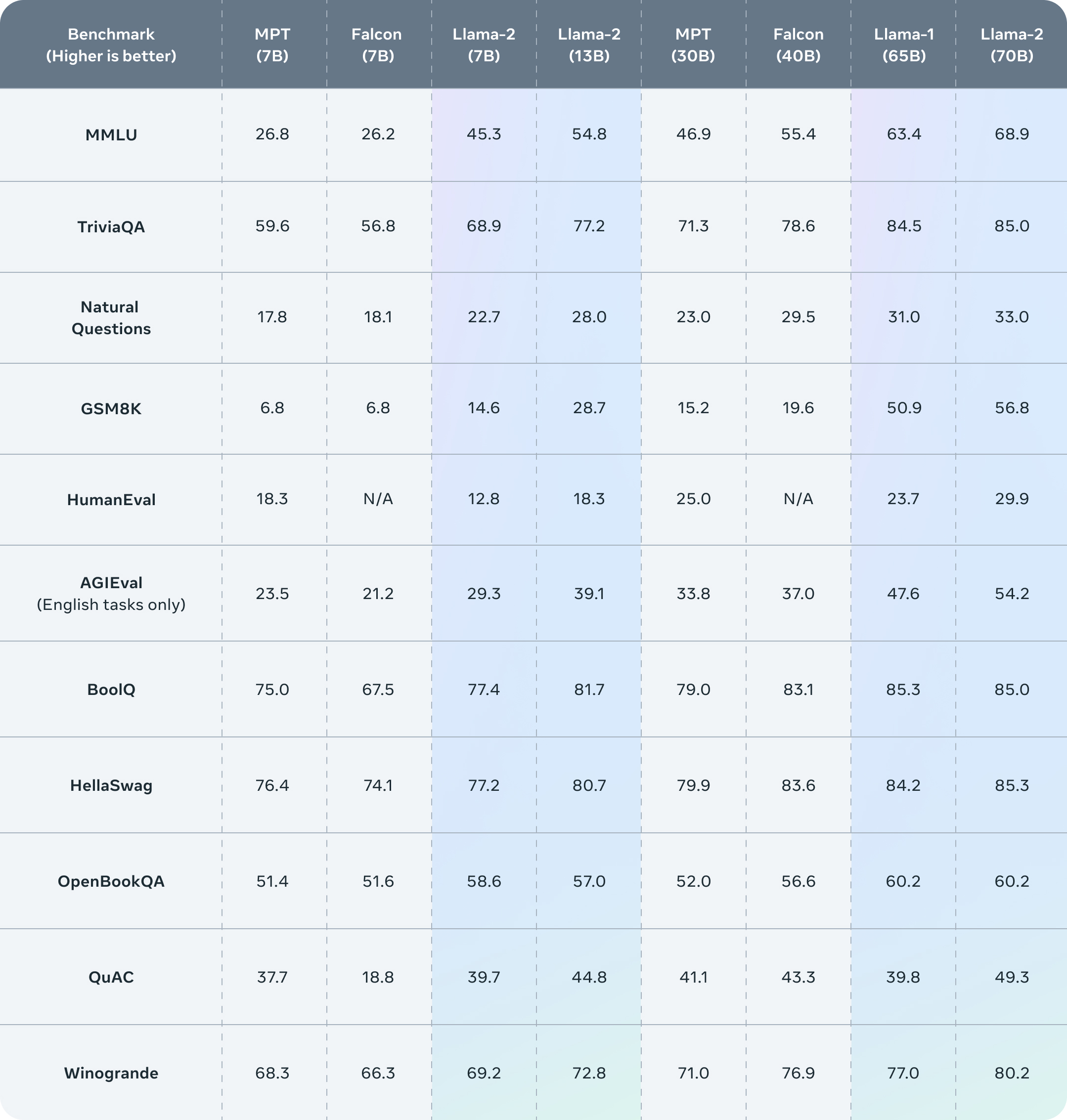
Llama2 벤치마크 결과. 출처 : Meta
요약 : 라마는 상업적 사용이 가능하고 성능도 준수하다!
1. LLaMA.C++ 준비하기
사전환경
- OS : Windows 10
- cmake : 3.26.4
- python : 3.9
(1) 소스코드 내려받기
Git이 없다면 여기에서 x64용 Installer(.exe)를 받아 설치하자
이제 cmd창에서 git 명령어가 작동할 것이므로, 적당한 위치에 llama.cpp 소스코드를 내려받을 수 있다
git clone https://github.com/ggerganov/llama.cpp.git(2) 빌드
Case 1. Visual Studio 등 C++ 컴파일러가 있는 경우
CMake는 보통 없으므로 여기에서 x64용 Installer(.msi)를 받아 설치하자
이제 cmd창에서 cmake 명령어가 작동할 것이므로, 소스코드를 받은 위치에서 cmake 명령어로 빌드하자
(cmake가 안된다면 재부팅해서 환경변수를 갱신하자)
mkdir build
cd build
cmake ..
cmake --build . --config Release -j 8Case 2. 그 외의 경우
귀찮지만 w64devkit라는 Windows용 C/C++ 개발키트를 받아서 실행하자, 이 글에서는 1.22.0버전을 사용했다
실행 후 소스코드를 받은 위치로 이동해서 make 명령어로 빌드하자
(cd 명령어의 경로 구분이 Windows의 \가 아닌 / 또는 \\임에 유의하자)
$ make -j 8
2. Llama2 모델 준비하기
llama.cpp는 별도의 GGUF 포맷을 변환이 필요한데, 이 글에서는 미리 변환 및 양자화된 모델을 사용할 것이다
(혹시 공식 저장소에서 직접 받았다면 Prepare and Quantize 항목를 참고해서 변환을 따로 진행해주어야 한다)
TheBloke/Llama-2-7B-Chat-GGUF에서 적당한 모델을 골라서 소스코드 폴더에 넣어주자
여기서는 llama-2-7b-chat.Q4_K_M.gguf를 받았다
3. 결과 확인하기
LLaMA.C++ 프로젝트를 빌드하고 모델까지 내려받았다면
아래와 같이 chat-with-bob.txt를 불러와서 밥과 채팅을 할 수 있다
llama-cpp -m llama-2-7b-chat.Q4_K_M.gguf -n 256 --repeat_penalty 1.0 --color -i -r "User:" -f prompts/chat-with-bob.txt※ CMake의 경우 빌드 산출물은 build\bin\Release\llama-cpp일 것이다

물론 프롬프트도 수정가능한데, 더 자세한 활용법은 깃허브의 Interactive mode 항목나 다른 프롬프트 템플릿을 참고하면 된다!
