1일차
크기 불변 특징과 SIFT 알고리즘
특징점(feature point, keypoint, interest point)
기술자, 특징 벡터(descriptor, feature vector)
SIFT 알고리즘
1. Scale-space extrema detection
Scale space는 여러 개의 Octave들로 이루어져 있다.
first octave는 원본 영상을 이용해 생성하고, 그 이후의 옥타브들은 원본 영상을 1/4(가로세로 절반)크기로 resize한 영상을 이용해 생성한다.
하나의 Octave를 살펴보면,
기준 영상을 n단계만큼 blur를 하게되는데 blur 단계 차이가 1인 이미지끼리의 뺀 이미지를 구하고 이를 Difference of Gaussian(DOG)이라 한다.
n번 blur를 진행하면 하나의 옥타브에 n-1장의 DOG를 얻는다.
2. Keypoint localization
"Scale-space theory"에 의하면 (LOG)의 최대, 최소점이 가장 안정적인 이미지 특징이고, 라플라시안을 구하는 대신 연산량이 적고 LOG와 유사한 DOG를 사용하게 된다.
-
같은 옥타브에 속한 DOG 영상에서 주변 8개 점과 이웃한 DOG영상의 18(9*2)개 점, 총 26개 점을 비교하여 지역 최대, 최소값을 판별한다.
-
각 옥타브마다 반복.
-
서브픽셀 정확도 기법 사용,
-
낮은 대비 극점 제거, 에지 제거를 통해 keypoint 수를 줄인다.
3. Orientation assignment
- keypoint 근방의 부분영상 추출.
- 부분영상의 모든 픽셀에서 gradient 계산해서 (360도를 36개로 나눠) 36개 bin을 가지는 방향 성분 히스토그램 생성.
- 히스토그램 최댓값 방향 및 최솟값*80%인 방향들을 모두 keypoint orientation으로 설정.
4. Keypoint description - 각 keypoint위치에서 3에서구한 scale, orientation을 고려해 사각형 영역을 선택.
- 사각형 영역을 4 by 4 구역으로 나누고 각 16개 구역에서 8 방향(45도) 성분 히스토그램을 구함.(float * 128(=4*4*8))
OpenCV 특징점 검출과 기술
keypoint detection
cv::Mat src = cv::imread("../images/lenna.bmp", cv::IMREAD_GRAYSCALE);
if(src.empty())
{
std::cerr << "Image load failed!" << std::endl;
return -1;
}
cv::Ptr<cv::Feature2D> detector = cv::SIFT::create(); // SIFT, KAZE, AKAZE, ORB..
std::vector<cv::KeyPoint> keypoints;
detector -> detect(src, keypoints);
std::cout << "keypoints.size(): " << keypoints.size() << std::endl;
cv::Mat dst;
cv::drawKeypoints(src, keypoints, dst, cv::Scalar::all(-1), cv::DrawMatchesFlags::DRAW_RICH_KEYPOINTS);
cv::imshow("dst", dst);
while(cv::waitKey(0) != 27) // ESC to escape
continue;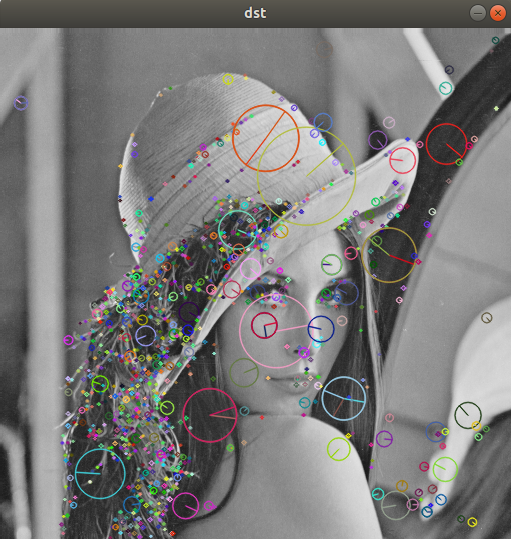
descriptor 구하기
cv::Mat src = cv::imread("../images/lenna.bmp",cv::IMREAD_GRAYSCALE);
if(src.empty())
{
std::cout << "Image load failed!" << std::endl;
return -1;
}
cv::Ptr<cv::Feature2D> feature = cv::SIFT::create(); // SIFT, KAZE, AKAZE, ORB..
// SIFT, SURF, KAZE -> floating-point descriptor
// AKAZE, ORB, BRIEF -> binary descriptor
std::vector<cv::KeyPoint> keypoints;
cv::Mat descriptors;
#if 1
feature -> detectAndCompute(src, cv::Mat(), keypoints, descriptors);
#else
feature -> detect(src, keypoints);
feature -> compute(src, keypoints, descriptors);
#endif
std::cout << "keypoints.size(): " << keypoints.size() << std::endl;
std::cout << "descriptors.size(): " << descriptors.size() << std::endl;
cv::Mat dst;
cv::drawKeypoints(src, keypoints, dst, cv::Scalar::all(-1), cv::DrawMatchesFlags::DRAW_RICH_KEYPOINTS);
cv::imshow("dst", dst);
while(cv::waitKey(0) != 27) // ESC to escape
continue;
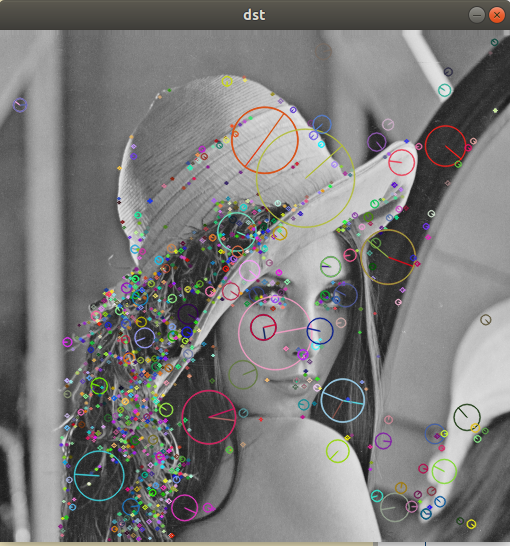
output:
keypoints.size(): 1098
descriptors.size(): [128 x 1098]특징점 매칭
- 두 영상에서 추출한 descriptor를 비교하여 유사한 descriptor끼리 매칭하는 작업.
cv::Mat src1 = cv::imread("../images/box.png",cv::IMREAD_GRAYSCALE);
cv::Mat src2 = cv::imread("../images/box_in_scene.png",cv::IMREAD_GRAYSCALE);
if(src1.empty() || src2.empty())
{
std::cerr << "Image load failed!" << std::endl;
}
cv::Ptr<cv::Feature2D> feature = cv::SIFT::create(); // SIFT, KAZE, AKAZE, ORB..
// SIFT, SURF, KAZE -> floating-point descriptor
// AKAZE, ORB, BRIEF -> binary descriptor
std::vector<cv::KeyPoint> kp1, kp2;
cv::Mat desc1, desc2;
// descriptor 구하기
feature -> detectAndCompute(src1, cv::Mat(), kp1, desc1);
feature -> detectAndCompute(src2, cv::Mat(), kp2, desc2);
std::cout << "kp1.size(): " << kp1.size() << std::endl;
std::cout << "kp2.size(): " << kp2.size() << std::endl;
// 특징점 매칭
// BFMatcher(Brute force), FlannBasedMatcher(K-D tree 사용)
cv::Ptr<cv::DescriptorMatcher> matcher = cv::BFMatcher::create(); // float point desc
//cv::Ptr<cv::DescriptorMatcher> matcher = cv::BFMatcher::create(cv::NORM_HAMMING); // binary desc
//매칭 후 좋은 매칭만을 추출.
#if 0
std::vector<cv::DMatch> matches;
matcher -> match(desc1, desc2, matches);
// distance 값을 기준으로 sorting
std::sort(matches.begin(), matches.end());
std::vector<cv::DMatch> good_matches(matches.begin(), matches.begin() + 80);
#else
std::vector<std::vector<cv::DMatch>> matches;
matcher -> knnMatch(desc1, desc2, matches, 2); // 2개의 matches를 반환
std::vector<cv::DMatch> good_matches;
// first matches와 second matches의 distance 값의 비율이 0.7보다 작으면 선택
for(const std::vector<cv::DMatch>& m : matches)
{
if(m[0].distance / m[1].distance < 0.7)
{
good_matches.push_back(m[0]);
}
}
#endif
cv::Mat dst;
cv::drawMatches(src1, kp1, src2, kp2, good_matches, dst);
cv::imshow("dst", dst);
while(cv::waitKey(0) != 27) // ESC to escape
continue;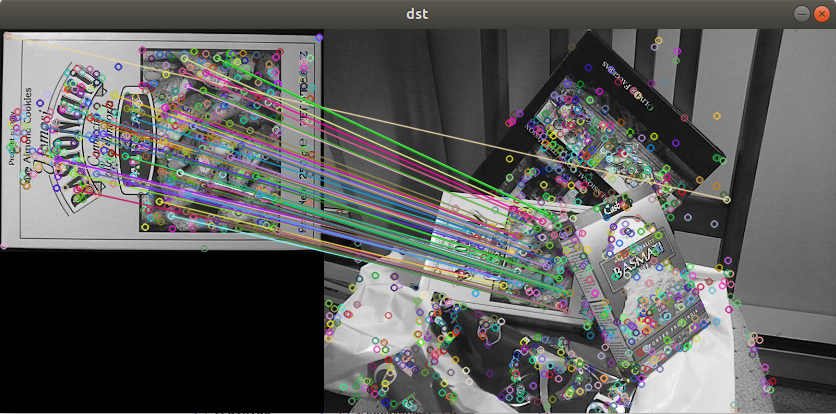
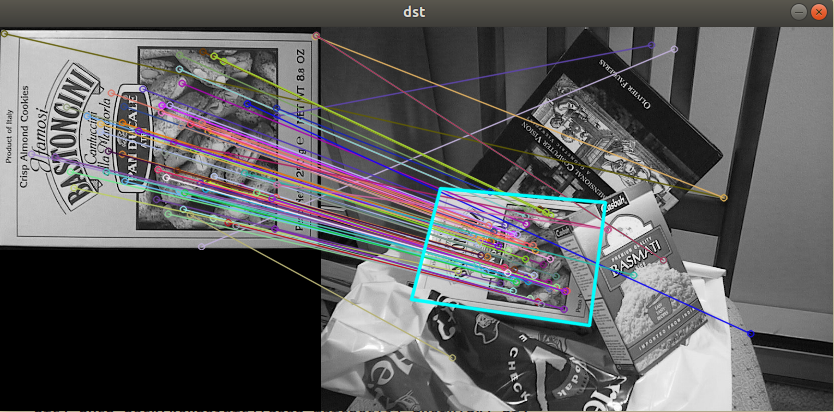
호모그래피와 영상 매칭
cv::findHomography(..)
- std::vector<cv::Point2f> srcPoints. (또는 CV_32FC2 행렬)
- std::vector<cv::Point2f> dstPoints.
- method: default=0(least square method), LMEDS, RANSAC, RHO
- ransacReprojThreshold: ransac, rho 사용 시 pixel threshold.
- cv::Mat mask: srcPoints 중 inlier를 1, outlier를 0으로 표현한 N by 1 행렬.
- 반환값: 3 by 3 homography 행렬.
영상 매칭 후 호모그래피 구하기
#if 0
cv::Mat src1 = cv::imread("../images/graf1.png",cv::IMREAD_GRAYSCALE);
cv::Mat src2 = cv::imread("../images/graf3.png",cv::IMREAD_GRAYSCALE);
#else
cv::Mat src1 = cv::imread("../images/box.png",cv::IMREAD_GRAYSCALE);
cv::Mat src2 = cv::imread("../images/box_in_scene.png",cv::IMREAD_GRAYSCALE);
#endif
if(src1.empty() || src2.empty())
{
std::cerr << "Image load failed!" << std::endl;
}
cv::Ptr<cv::Feature2D> feature = cv::SIFT::create(); // SIFT, KAZE, AKAZE, ORB..
// SIFT, SURF, KAZE -> floating-point descriptor
// AKAZE, ORB, BRIEF -> binary descriptor
std::vector<cv::KeyPoint> kp1, kp2;
cv::Mat desc1, desc2;
// descriptor 구하기
feature -> detectAndCompute(src1, cv::Mat(), kp1, desc1);
feature -> detectAndCompute(src2, cv::Mat(), kp2, desc2);
std::cout << "kp1.size(): " << kp1.size() << std::endl;
std::cout << "kp2.size(): " << kp2.size() << std::endl;
// 특징점 매칭
// BFMatcher(Brute force), FlannBasedMatcher(K-D tree 사용)
cv::Ptr<cv::DescriptorMatcher> matcher = cv::BFMatcher::create(); // float point desc
//cv::Ptr<cv::DescriptorMatcher> matcher = cv::BFMatcher::create(cv::NORM_HAMMING); // binary desc
//매칭 후 좋은 매칭만을 추출.
#if 1
std::vector<cv::DMatch> matches;
matcher -> match(desc1, desc2, matches);
// distance 값을 기준으로 sorting
std::sort(matches.begin(), matches.end());
std::vector<cv::DMatch> good_matches(matches.begin(), matches.begin() + 80);
#else
std::vector<std::vector<cv::DMatch>> matches;
matcher -> knnMatch(desc1, desc2, matches, 2); // 2개의 matches를 반환
std::vector<cv::DMatch> good_matches;
// first matches와 second matches의 distance 값의 비율이 0.7보다 작으면 선택
for(const std::vector<cv::DMatch>& m : matches)
{
if(m[0].distance / m[1].distance < 0.7)
{
good_matches.push_back(m[0]);
}
}
#endif
cv::Mat dst;
cv::drawMatches(src1, kp1, src2, kp2, good_matches, dst, cv::Scalar::all(-1), cv::Scalar::all(-1),
std::vector<char>(), cv::DrawMatchesFlags::NOT_DRAW_SINGLE_POINTS);
// find homography
std::vector<cv::Point2f> pts1, pts2;
for(int i = 0; i < good_matches.size(); i++)
{
pts1.push_back(kp1[good_matches[i].queryIdx].pt);
pts2.push_back(kp2[good_matches[i].trainIdx].pt);
}
cv::Mat H = cv::findHomography(pts1, pts2, cv::RANSAC);
// graf1 을 graf3에 투영.
std::vector<cv::Point2f> corners1, corners2;
corners1.push_back(cv::Point2f(0 , 0));
corners1.push_back(cv::Point2f(src1.cols - 1.f, 0));
corners1.push_back(cv::Point2f(src1.cols - 1.f, src1.rows - 1.f));
corners1.push_back(cv::Point2f(0 , src1.rows - 1.f));
cv::perspectiveTransform(corners1, corners2, H);
// point2f에서 point로 변경
std::vector<cv::Point> corners_dst;
for(auto& pt : corners2)
{
corners_dst.push_back(cv::Point(cvRound(pt.x + src1.cols), cvRound(pt.y)));
}
cv::polylines(dst, corners_dst, true, cv::Scalar(255, 255, 0), 2, cv::LINE_AA);
cv::imshow("dst", dst);
while(cv::waitKey(0) != 27) // ESC to escape
continue;

2일차
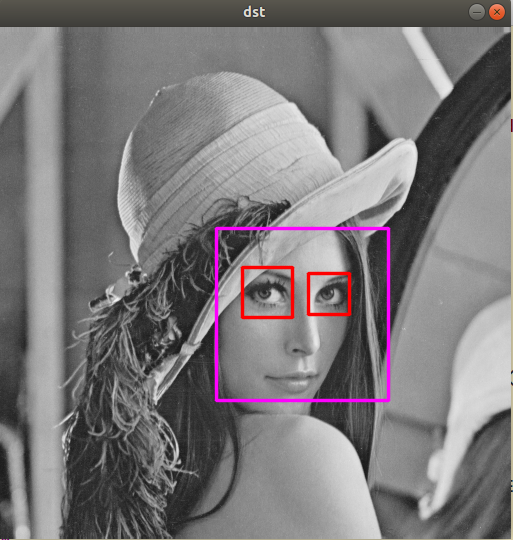
캐스케이드 분류기와 얼굴 검출
opencv/data/ 디렉토리 내부에 haarcascades xml파일이 존재한다.
detectMultiScale 함수에서 scaleFactor, minSize, maxSize 등을 조절해 실행속도를 줄일 수 있다.
// face cascade
cv::Mat src = cv::imread("lenna.bmp", cv::IMREAD_GRAYSCALE);
if(src.empty())
{
std::cerr << "Image load failed" << std::endl;
return -1;
}
cv::CascadeClassifier face_cascade("../data/haarcascades/haarcascade_frontalface_default.xml");
if(face_cascade.empty())
{
std::cerr << "Failed to open xml file" << std::endl;
return -1;
}
std::vector<cv::Rect> faces;
face_cascade.detectMultiScale(src, faces);
std::cout << "faces.size(): " << faces.size() << std::endl;
cv::Mat dst;
cv::cvtColor(src, dst, cv::COLOR_GRAY2BGR);
for(int i = 0; i < faces.size(); i++)
{
cv::rectangle(dst, faces[i], cv::Scalar(255, 0, 255), 2, cv::LINE_AA);
}
// eye cascade
#if 1
cv::CascadeClassifier eyes_cascade("../data/haarcascades/haarcascade_eye.xml");
if(eyes_cascade.empty())
{
std::cerr << "Failed to open xml file" << std::endl;
return -1;
}
for(int i = 0; i < faces.size(); i++)
{
cv::Mat faceROI = dst(faces[i]);
std::vector<cv::Rect> eyes;
// 검출된 face의 부분영상에서 eye 검출.
eyes_cascade.detectMultiScale(faceROI, eyes);
std::cout << "eyes.size(): " << eyes.size() << std::endl;
for(int j = 0; j < eyes.size(); j++)
{
cv::rectangle(faceROI, eyes[j], cv::Scalar(0, 0, 255), 2, cv::LINE_AA);
}
}
#endif
cv::imshow("dst", dst);
while(cv::waitKey(0) != 27) // ESC to escape
continue;
머신러닝과 필기체 숫자 인식
SVM 알고리즘 예제
cv::Mat train = cv::Mat_<float>({8, 2},
{
150, 200, 200, 250, 100, 250, 150, 300,
350, 100, 400, 200, 400, 300, 350, 400
});
cv::Mat label = cv::Mat_<int>({8, 1},
{
0, 0, 0, 0, 1, 1, 1, 1
});
// train
cv::Ptr<cv::ml::SVM> svm = cv::ml::SVM::create();
svm -> setType(cv::ml::SVM::C_SVC); // C_SVC, NU_SVC, ONE_CLASS, EPS_SVR, NU_SVR
svm -> setKernel(cv::ml::SVM::RBF); // LINEAR, POLY, RBF, SIGMOID, CHI2, INTER
svm -> trainAuto(train, cv::ml::ROW_SAMPLE, label); // C, gamma등도 hyperparameter tuning도 함께 해줌.
// hyperparameters
// C : 크면 오분류 에러도 작아지지만 마진이 작아짐. 작으면 마진이 커지지만 오분류에러가 커짐.
// gamma : RBF 등을 선택 시 필요함.
// test
cv::Mat img = cv::Mat::zeros(cv::Size(500, 500), CV_8UC3);
for(int y = 0; y < img.rows; y++)
{
for(int x = 0; x < img.cols; x++)
{
cv::Mat test = cv::Mat_<float>({1, 2}, {(float)x, (float)y});
int res = cvRound(svm -> predict(test));
if(res == 0)
img.at<cv::Vec3b>(y, x) = cv::Vec3b(128, 128, 255);
else
img.at<cv::Vec3b>(y, x) = cv::Vec3b(128, 255, 128);
}
}
for(int i = 0; i < train.rows; i++)
{
int x = cvRound(train.at<float>(i, 0));
int y = cvRound(train.at<float>(i, 1));
int l = label.at<int>(i, 0);
if(l == 0)
cv::circle(img, cv::Point(x, y), 5, cv::Scalar(0, 0, 128), -1, cv::LINE_AA);
else
cv::circle(img, cv::Point(x, y), 5, cv::Scalar(0, 128, 0), -1, cv::LINE_AA);
}
cv::imshow("svm", img);
while(cv::waitKey(0) != 27) // ESC to escape
continue;
HOG 알고리즘
Histogram of Oriented Gradients.
- 전체 영상에서 다양한 크기의 window를 이용해 영상을 스캔하면서 부분 영상을 추출.
- 부분 영상을 64 x 128 크기로 resize하고 8x8 셀로 나눔(셀의 개수는 8 x 16개)
- 각 셀에서 그래디언트(dir, mag) 계산.
- 0부터 160도까지 20도 단위로 9개 방향 bin을 가지는 히스토그램을 구함.
- 그래디언트의 dir에 속하는 히스토그램 성분의 값을 mag만큼 더해줌.(두 bin의 사이인 경우 mag 값을 나눠서 각각 더해줌)
- 결과적으로 각 셀마다 9개 bin의 히스토그램이 존재하게 됨.
- 4개의 셀을 하나의 블록으로 지정. 블록의 히스토그램 bin 개수는(9*4개)
- 결과적으로 부분영상 1개에 7*15*36=3780개의 bin(float)이 존재.
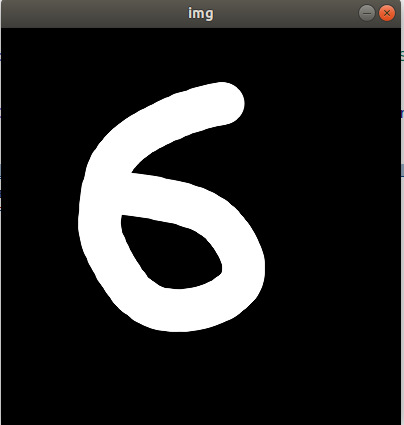
HOG & SVM 필기체 숫자 인식
cv::Mat img;
cv::Point ptPrev(-1, -1);
void on_mouse(int event, int x, int y, int flags, void*);
cv::Mat norm_digit(cv::Mat& src);
int main()
{
cv::Mat digits = cv::imread("../images/digits.png", cv::IMREAD_GRAYSCALE);
if(digits.empty())
{
std::cerr << "Image load failed" << std::endl;
return -1;
}
cv::HOGDescriptor hog(cv::Size(20, 20), // window size
cv::Size(10, 10), // block size
cv::Size(5, 5), // block stride
cv::Size(5, 5), // cell size
9 // nbins
);
std::cout << "Descriptor Size : " << hog.getDescriptorSize() << std::endl;
cv::Mat train_hog, train_labels;
for(int Y = 0; Y < 50; Y++)
{
for(int X = 0; X < 100; X++)
{
cv::Mat roi = digits(cv::Rect(X * 20, Y * 20, 20, 20)).clone();
std::vector<float> desc;
hog.compute(norm_digit(roi), desc);
// vector<float> -> Mat
cv::Mat desc_mat(desc, true);
train_hog.push_back(desc_mat.t()); // transpose 후 pushback
train_labels.push_back(Y / 5);
}
}
// SVM
cv::Ptr<cv::ml::SVM> svm = cv::ml::SVM::create();
// cv::Ptr<cv::ml::SVM> svm = cv::ml::SVM::load("svmmodel.yml");
svm -> setType(cv::ml::SVM::C_SVC);
svm -> setKernel(cv::ml::SVM::RBF);
#if 1
svm -> setGamma(0.50625); // 미리 구해놓은 값.
svm -> setC(2.5);
svm -> train(train_hog, cv::ml::ROW_SAMPLE, train_labels);
#else
svm -> trainAuto(train_hog, cv::ml::ROW_SAMPLE, train_labels);
#endif
// svm -> save("svmmodel.yml")
img = cv::Mat::zeros(400, 400, CV_8U);
cv::imshow("img", img);
cv::setMouseCallback("img", on_mouse);
while(true)
{
int c = cv::waitKey(0);
if(c == 27) // ESC
break;
else if(c == ' ')
{
cv::Mat img_blur, img_resize;
cv::GaussianBlur(img, img_blur, cv::Size(), 1);
cv::resize(img_blur, img_resize, cv::Size(20, 20), 0, 0, cv::INTER_AREA);
std::vector<float> desc;
hog.compute(norm_digit(img_resize), desc);
cv::Mat desc_mat(desc, true);
float res = svm -> predict(desc_mat.t());
std::cout << cvRound(res) << std::endl;
img.setTo(0);
cv::imshow("img", img);
}
else if(c == 'c')
{
img.setTo(0);
cv::imshow("img", img);
}
}
return 0;
}
void on_mouse(int event, int x, int y, int flags, void*)
{
if(x < 0 || x >= img.cols || y < 0 || y >= img.rows)
return;
if(event == cv::EVENT_LBUTTONUP || !(flags & cv::EVENT_FLAG_LBUTTON))
ptPrev = cv::Point(-1, -1);
else if(event == cv::EVENT_LBUTTONDOWN)
ptPrev = cv::Point(x, y);
else if(event == cv::EVENT_MOUSEMOVE && (flags & cv::EVENT_FLAG_LBUTTON))
{
cv::Point pt(x, y);
if (ptPrev.x < 0)
ptPrev = pt;
cv::line(img, ptPrev, pt, cv::Scalar::all(255), 40, cv::LINE_AA, 0);
ptPrev = pt;
cv::imshow("img", img);
}
}
// 숫자를 센터에 위치하도록 정규화.
cv::Mat norm_digit(cv::Mat& src)
{
CV_Assert(!src.empty() && src.type() == CV_8UC1);
cv::Mat src_bin;
cv::threshold(src, src_bin, 0, 255, cv::THRESH_BINARY | cv::THRESH_OTSU);
cv::Mat labels, stats, centroids;
int n = cv::connectedComponentsWithStats(src_bin, labels, stats, centroids);
cv::Mat dst = cv::Mat::zeros(src.rows, src.cols, src.type());
for(int i = 1; i < n; i++)
{
if(stats.at<int>(i, 4) < 10)
continue;
int cx = cvRound(centroids.at<double>(i, 0));
int cy = cvRound(centroids.at<double>(i, 1));
double dx = 10 - cx;
double dy = 10 - cy;
cv::Mat warpMat = (cv::Mat_<double>(2, 3) << 1, 0, dx, 0, 1, dy);
cv::warpAffine(src, dst, warpMat, dst.size());
}
return dst;
}
output:
Descriptor Size : 324
6직접 쓴 숫자를 잘 인식하는 것을 확인하였다.
딥러닝 학습과 모델 파일 사용
사용환경
Ubuntu 18.04 / kernel 6.0.7
nvidia driver 515.86.01 / CUDA 11.7
python 3.8.16 / pytorch 1.13.0
LeNet5 train
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print("device is: ", device)
# hyper parameters
num_epochs = 10
num_classes = 10
batch_size = 100
learning_rate = 0.001
# MNIST dataset
train_dataset = torchvision.datasets.MNIST(root='./MNIST_data/',
train=True,
transform=transforms.ToTensor(),
download=True)
test_dataset = torchvision.datasets.MNIST(root='./MNIST_data/',
train=False,
transform=transforms.ToTensor())
# Data loader
train_loader = DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
test_loader = DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=False)
# LeNet5
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv_layer1 = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5, padding=2),
nn.ReLU()
)
self.pool_layer1 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv_layer2 = nn.Sequential(
nn.Conv2d(6, 16, kernel_size=5),
nn.ReLU()
)
self.pool_layer2 = nn.MaxPool2d(kernel_size=2, stride=2)
self.C5_layer = nn.Sequential(
nn.Linear(5*5*16, 120),
nn.ReLU()
)
self.fc_layer1 = nn.Sequential(
nn.Linear(120, 84),
nn.ReLU()
)
self.fc_layer2 = nn.Linear(84, 10)
def forward(self, x):
output = self.conv_layer1(x)
output = self.pool_layer1(output)
output = self.conv_layer2(output)
output = self.pool_layer2(output)
output = output.view(-1,5*5*16)
output = self.C5_layer(output)
output = self.fc_layer1(output)
output = self.fc_layer2(output)
return output
model = LeNet().to(device)
loss_function = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=5e-2)
# train model
for i in range(num_epochs):
print(f"{i}th epoch starting")
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
train_loss = loss_function(model(images), labels)
train_loss.backward()
optimizer.step()
# test model
model.eval()
with torch.no_grad():
test_loss, correct, total = 0, 0, 0
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
output = model(images)
test_loss += loss_function(output, labels).item()
pred = output.max(1, keepdim=True)[1]
correct += pred.eq(labels.view_as(pred)).sum().item()
total += labels.size(0)
print('[Test set] Average loss: {:.4f}, Accuracy: {}/{} ({:.2f}%)\n'.format(
test_loss /total, correct, total,
100. * correct / total))
# save model
torch.save(model.state_dict(), 'model.ckpt')
# onnx export
import torch.onnx
dummy_input = torch.randn(1, 1, 28, 28).to(device)
torch.onnx.export(model, dummy_input, "mnist.onnx")
output:
device is: cuda:0
0th epoch starting
1th epoch starting
2th epoch starting
3th epoch starting
4th epoch starting
5th epoch starting
6th epoch starting
7th epoch starting
8th epoch starting
9th epoch starting
[Test set] Average loss: 0.0003, Accuracy: 9882/10000 (98.82%)